01-黑马程序员大数据开发
一. ?Hadoop概述
1. 什么是大数据
- 狭义上:对海量数据进行处理的软件技术体系
- 广义上:数字化、信息化时代的基础支撑,以数据为生活赋
2. 大数据的核心工作:
- 存储:妥善保存海量待处理数据;Apache KUDU、云平台存储:阿里云OSS、UCloud的US3、AWS的S3、金山云的KS3等等
- 计算:完成海量数据的价值挖掘;Apache Hadoop - MapReduce;ApacheHive是一款以SQL为要开发语言的分布式计算框架;Apache Spark;ApacheFlink
- 传输:协助各个环节的数据传输;Apache Kafka是一款分布式的消息系统,可以完成海量规模的数据传输工作;Apache PULSAR; Apache Flume是一款流失数据采集工具;Apache Sqoop是一款ETL工具,可以协助大数据体系和关系型数据库之间进行数据传输。
3. ?Hadoop是Apache软件基金会下的顶级开源项目,用以提供:
- 分布式数据存储
- 分布式数据计算
- 分布式资源调度
为一体的整体解决方案。是典型的分布式软件框架,可以部署在1台乃至成千上万台服务器节点上协同工作。Hadoop是开源的技术框架,提供分布式存储、计算、资源调度的解决方案。个人或企业可以借助Hadoop构建大规模服务器集群,完成海量数据的存储和计算。
4.?Hadoop是一个整体,其内部还会细分为三个功能组件,分别是:
? ? ? ? HDFS组件:HDFS是Hadoop内的分布式存储组件,可以构建分布式文件系统用于数据存储
????????MapReduce组件:NapReduce是Hadoop内分布式计算组件,提供编程接口供用户开发分布式计算程序
????????YARN组件:YARN是Hadoop内分布式资源调度组件。 可供用户整体调度大规模集群的资源使用。
二. ?HDFS组件
2.1 为什么需要分布式存储
- 数据量太大,单机存储能力有上限,需要靠数量来解决问题
- 数量的提升带来的是网络传输、磁密读写(多倍的网络传输效率、多倍的磁盘写入效率)、CPU、内存等各方面的综合提升。分布式组合在一起可以达到1+1>2的效果
2.2 分布式的基础架构分析
1. ?分布式系统常见的组织形式?大数据体系中,分布式的调度主要有2类架构模式:
- 去中心化模式:没有明确的中心,众多服务器之间基于特定规则进行同步协调;如区块链
- 中心化模式:以一个节点(1台服务器)作为中心,去统一调度其他的节点
2. 大数据框架,大多数的基础架构上,都是符合:中心化模式的(一主多从模式,简称主从模式(MasterAndSlaves))。
即:有一个中心节点(服务器)来统筹其它服务器的工作,统一指挥,统一调派,避免混乱。在现实生活中很常见:公司企业管理、组织管理、行政管理
3. ?Hadoop是哪种模式?
????????主从模式(中心化模式)的架构
2.3 HDFS的基础架构
1. ?HDFS是Hadoop三大组件(HDFS、MapReduce、YARN)之一
- 全称是:Hadoop Distributed File System (Hadoop分布式文件系统)
- 是Hadoop技术栈内提供的分布式数据存储解决方案
- 功能:可以在多台服务器上构建存储集群,存储海量的数据
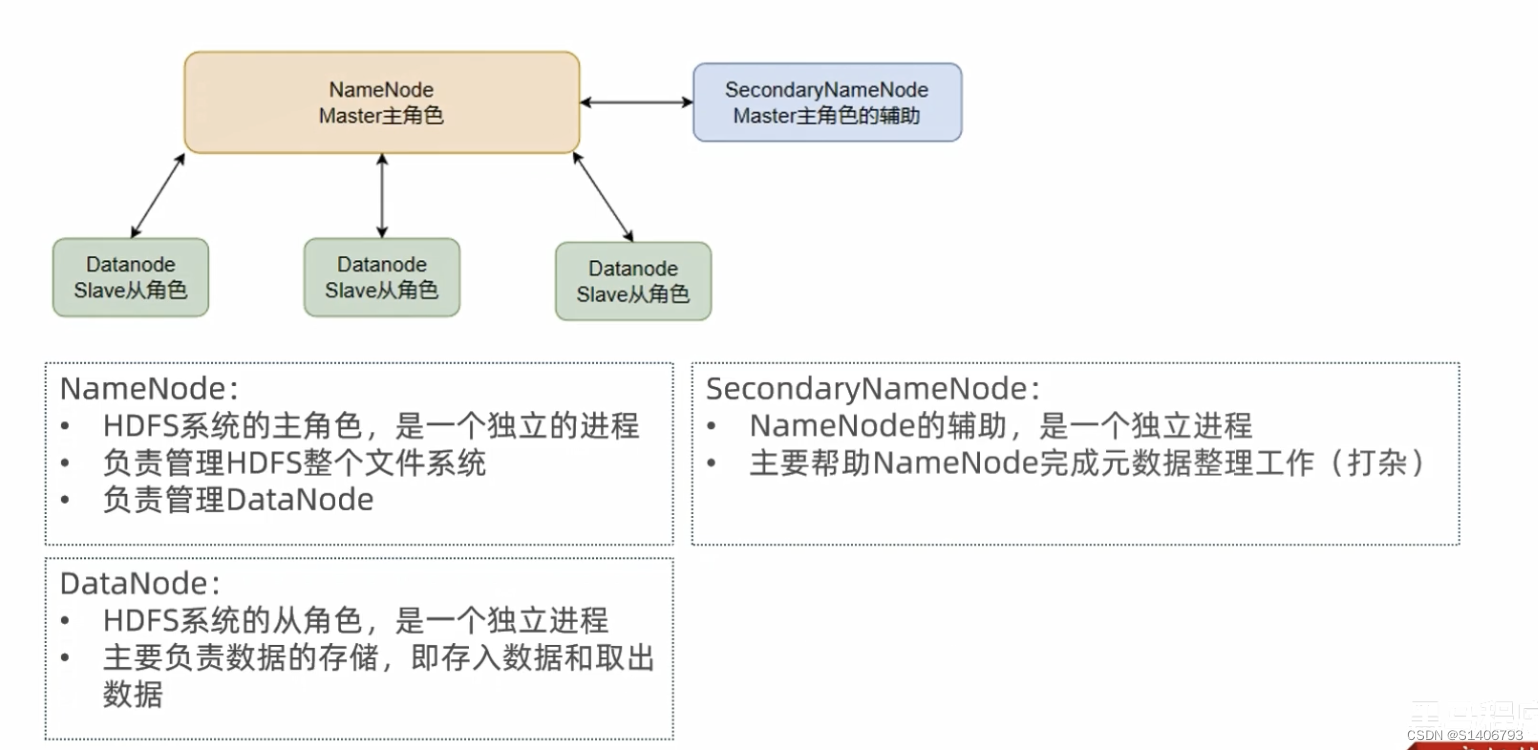
?2. ??HDFS中的架构角色有哪些?
- NameNode:主角色,管理HDFS集群和DataNode角色
- DataNode:从角色,负责数据的存储
- SecondaryNameNode:辅助角色,协助NameNode整理元数据
3. HDFS的基础架构
2.4 HDFS集群环境部署
2.4.1 VMware虚拟机中的部署
第二章-04-[实操]VMware虚拟机部署HDFS集群_哔哩哔哩_bilibili

1. 上传和解压到/export/server,配置软链接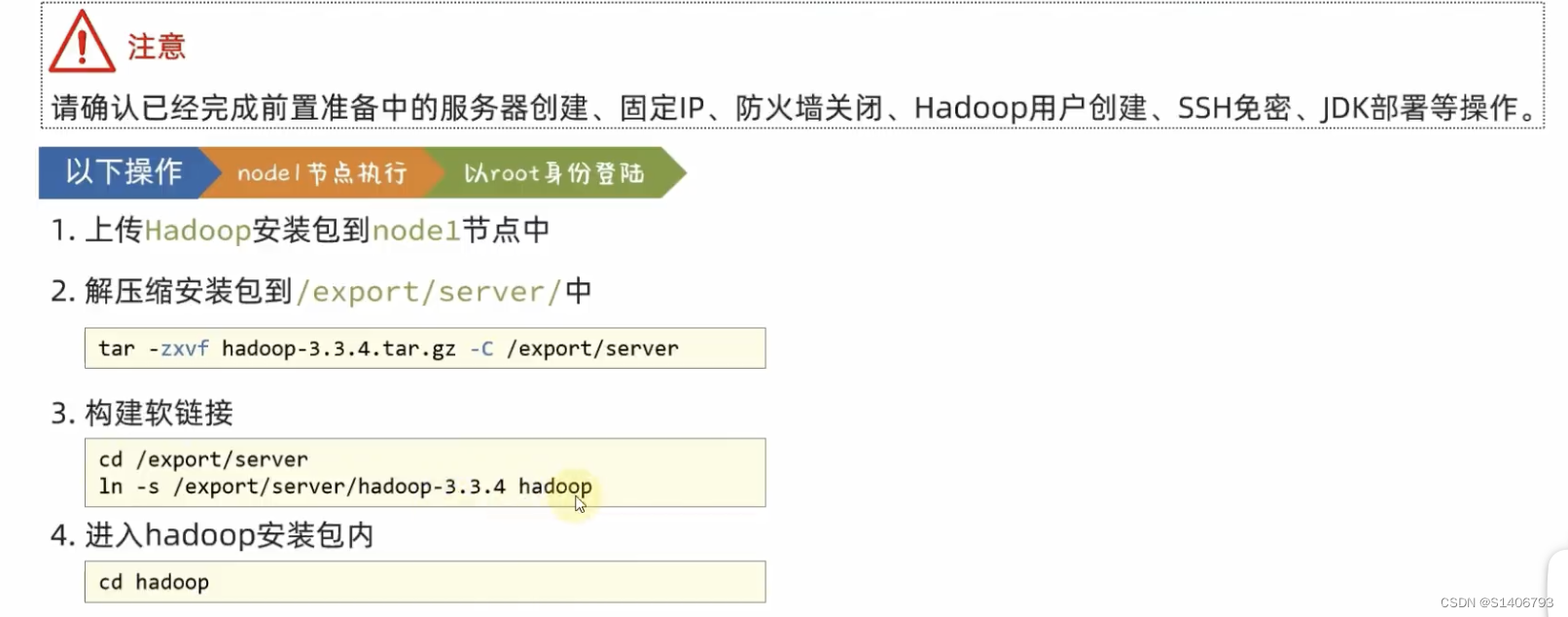
hadoop安装包目录结构
2. ?修改4份配置文件,应用自定义设置:找到etc配置文件中的以下4个文件,对其进行修改。




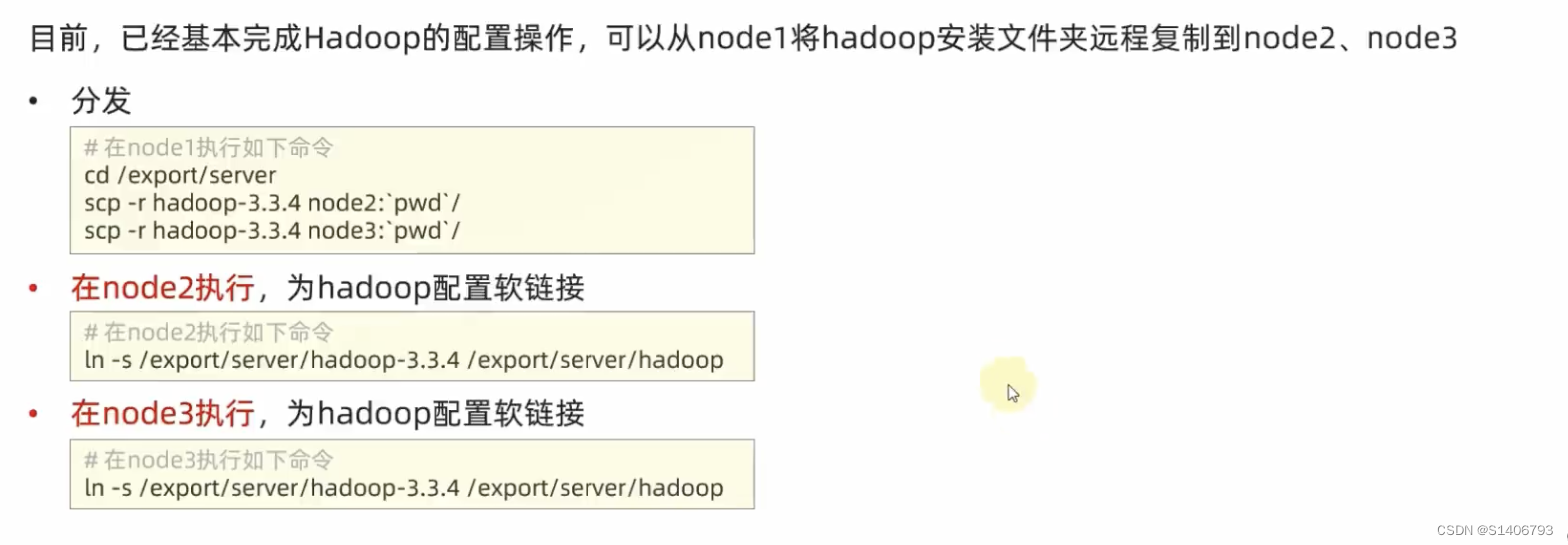
四个文件配置完成。继续:分发到node2、node3,并设置环境变量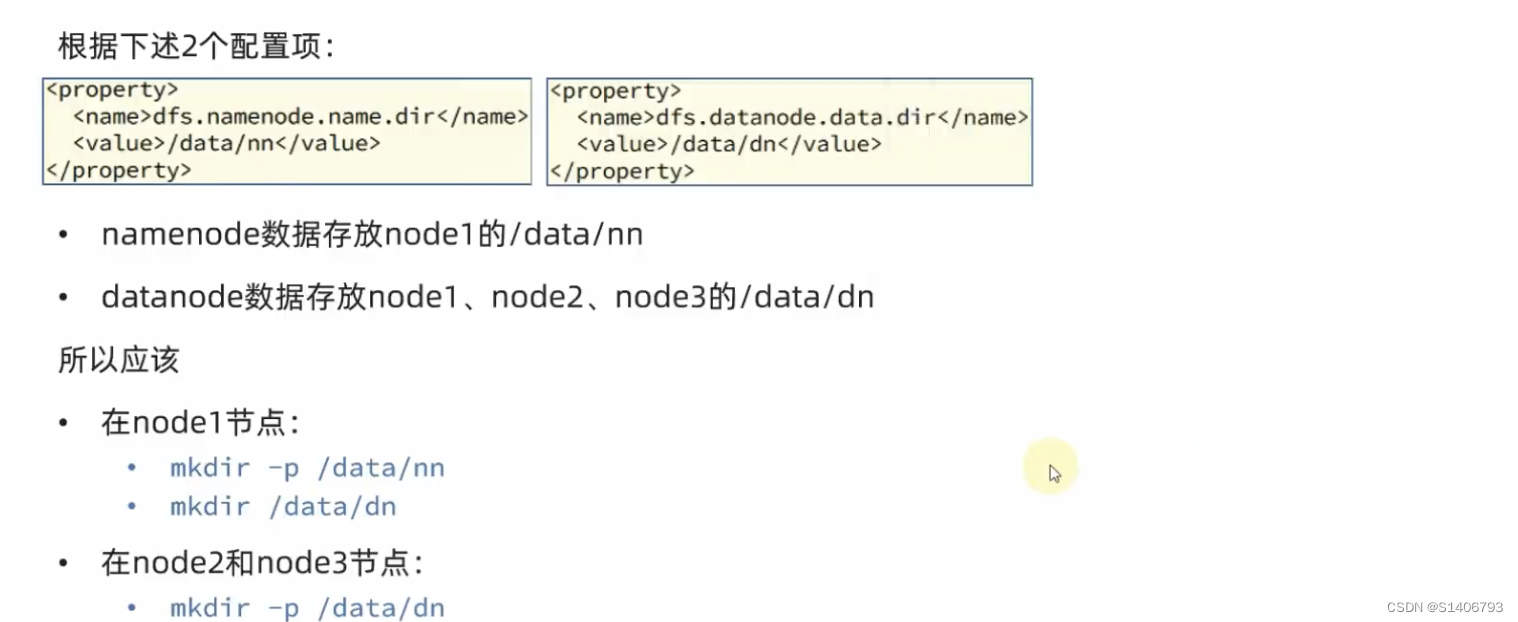

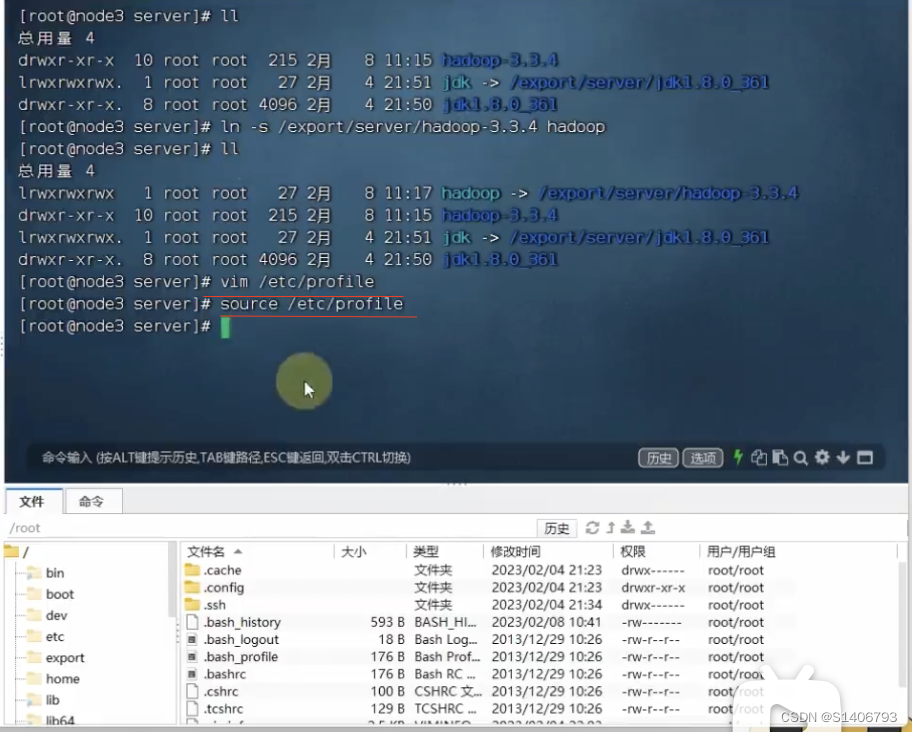
4. 创建数据目录,并修改文件权限归属hadoop账户。此时三台机器就配置完成了。还剩下至关重要的一步:授权hadoop用户。也就是将\data和\export文件的root用户变成hadoop用户。
前置准备工作全部完成,下一步开始去执行相关的命令并启动它。首先格式化整个文件系统。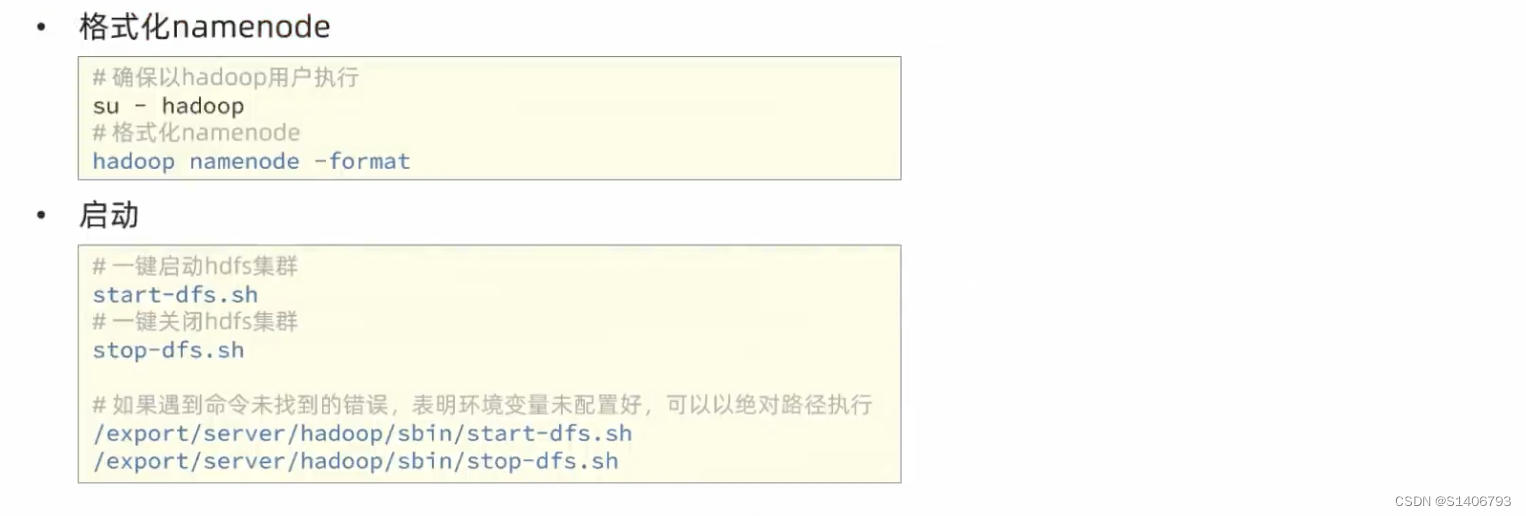
5. 启动,并查看WEB UI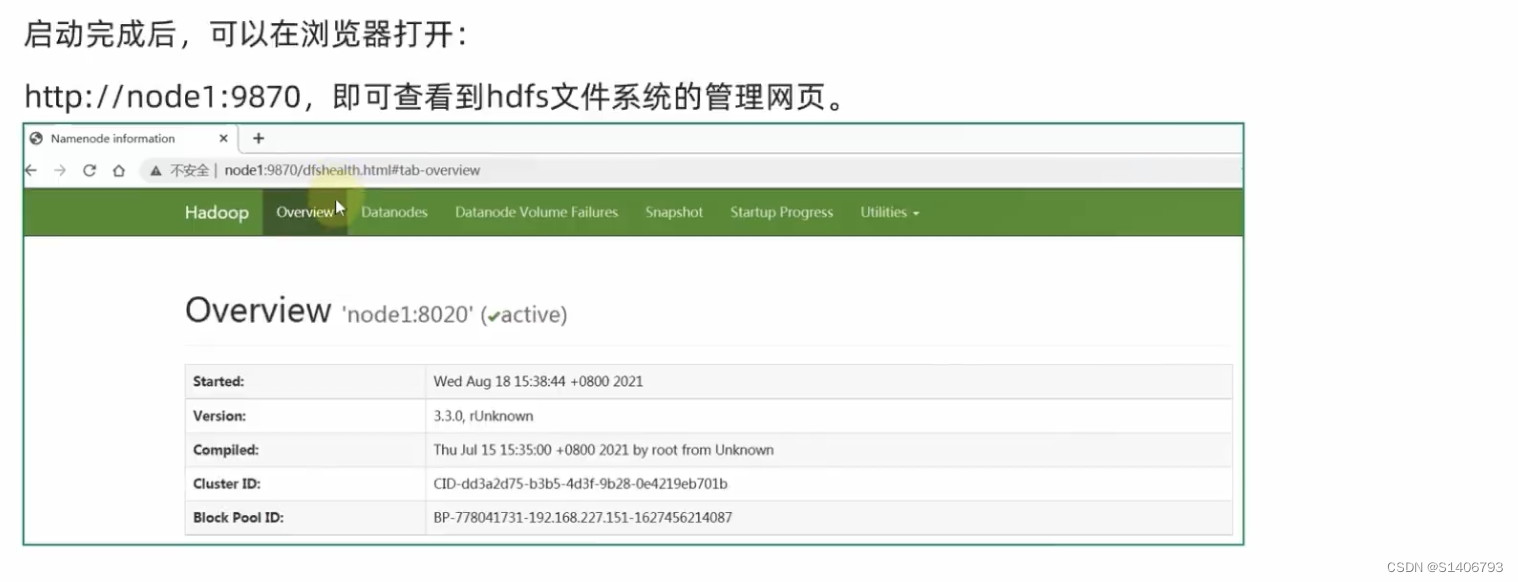
回收站的配置:
????????vim core-site.xml
集群部署常见问题解决:
1. 千辛万苦部署好了Hadoop的HDFS集群,如果中间出现误操作导致集群出现问题了怎么办?有没有什么方便的办法保存刚刚部署好的状态?
答:在虚拟机里面部署好hadoop之后,记得打(虚拟机)快照,当出现问题之后,可以恢复到快照即可。
打快照之前要将hdfs集群关闭【在hadoop权限下操作,不能在root权限下】—— 关闭整个服务器—— 退回root账户 —— init 0 关机(node1、node2、node3都关机) —— 打快照。
- 是否遗漏了前置准备章节的相关操作?
包括服务器的创建、SSH免密、Hadoop用户的创建、防火墙的关闭、固定IP主机名映射、JDK部署等。 - 是否遗漏的将文件夹(Hadoop安装文件夹、/data数据文件夹)chown授权到hadoop用户这一操作。
从root授权到hadoop用户,将导致hadoop用户没有权限,此时集群无法启动成功。? - 是否遗忘了格式化hadoop这一步 (hadoop namenode -format)
- 是否是以root用户格式化的hadoop。
此时再以hadoop用户去启动集群时会遇到没有权限的问题。 - 是否以root启动过hadoop,后续以hadoop用户启动出错。
只要以root操作过一次,那么相关的一些目录权限都归root了,后续再以hadoop启动,就会没有权限。 - 是否确认workers文件内,配置了node1、node2、node3三个节点
如果没有配置三个节点,后续在执行start dfs.sh这个脚本文件启动脚本文件时,只有node1启动了,node2和node3没有反应。 - 是否在/etc /profile内配置了HADOOP_ HOME环境变量,并将$HADOOP_HOME/bin和$HADOOP_HOME/sbin加入PATH变量
如果没有配置,后续在执行start dfs.sh脚本或stop dfs.sh脚本时,会出现“命令不存在”;或者hadoop namenode -format时,也会出现hadoop命令不存在,因为hadoop命令来自bin文件夹相关脚本,start 来自sbin文件夹中的相关脚本。 - 是否遗忘了软链接,但环境变量的配置的HADOOP_HOME却是:/export/server/hadoop
环境配置时用的是简写hadoop,如果没有软链接,就会出现问题 - 是否确认配置文件内容的准确(一个字符都不错),并确保三台机器的配置文件都OK。
详细细节版:第二章-06-[了解]集群部署常见问题-2_哔哩哔哩_bilibili
常见出错点:权限未正确设置、配置文件错误、未格式化。要细心,查日志看出错原因。
2.4.2 云服务器中的部署:阿里云、Ucloud两种,操作步骤一样。
第二章-07-[可选]云服务器上部署hdfs集群_哔哩哔哩_bilibili
1. 云服务器如何保存服务器状态、或者说出错了怎么快速恢复状态呢?
- 云服务器快照服务(可能收费,不推荐)
- 打包配置好的Hadoop安装包留存(推荐)
2.5?HDFS的Shell操作
2.5.1 HDFS相关进程的启停管理命令
1. Hadoop HDFS组件内置了HDFS集群的一键启停脚本。
- $HADOOP_HOME/sbin/ start-dfs.sh?,一键启动HDF
- $HADOOP_HOME/sbin/stop-dfs.sh ,一键关闭HD
2.?除了一键启停外,也可以单独控制进程的启停。
- $HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器(node1 or node2)的进程的启停;
- $HADOOP_HOME/bin/hdfs,此程序也可以用以单独控制所在机器的进程的启停
hadoop -daemon.sh(start|status|stop)(namenode|secondarynamenode|datanode);
hdfs --daemon(start|status|stop)(namenode|secondarynamenode|datanode)
2.5.2 HDFS文件系统的基础操作命令
1. ?HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。
? ? HDFS同Linux系统一样,均是以/作为根目录的组织形式,例如:
????????Linux: ? ? ? ? /usr/local/hello.txt,如路径:file:///usr/local/hello.txt
?? ? ? ?HDFS:????????/usr/local/hello.txt,如路径:hdfs://node1:8020/usr/local/hello.txt
那么怎么区分命令操作的事Linux还是HDFS? 可以通过协议头file:// 或者hdfs://namenode:port(可以省略,需要提供LinuX路径的参数,会自动识别为file://,需要提供HDFS路径的也会自动识别)。
2.?关于HDFS文件系统的操作命令,Hadoop提供了2套命令体系:用法完全一致
???????????????? 老版本:hadoop?fs [generic options]
????????? 新版本:hdfs?dfs [generic options]
# 1. 创建文件夹
# hadoop fs -mkdir [-p] <path> ...
# hdfs dfs -mkdir [-p] <path> ...
hadoop fs -mkdir -p /itcast/bigdata #创建在hadoop文件系统里
hdfs dfs -ls / #查看hadoop文件系统根目录下的文件:有itcast文件夹
hdfs dfs -ls /itcast #查看hadoop文件系统根目录下的文件:有bigdata文件夹
# 2. 查看置顶目录下内容
# hdfs dfs -ls [-h] [-R] <path> ...
# 3. 从本地Linux向HDFS上传文件,到HDFS指定目录下
# pdfs dfs -put [-f] [-p] <localsrc> ... <dst>
# -f:强制覆盖目标文件;-p:保留文件信息、访问和修改时间、所有权和权限; localscr:Linux本地的文件; dst:上传到HDFS的位置
vim test.txt #在Linux中新建一个文件
vim test2.txt
hadoop fs -put file:///home/hadoop/test.txt hdfs://node1:8020/ #上传到hdfs文件体统的根目录
hdfs dfs -put /home/hadoop/test2.txt /
# 4.查看HDFS文件内容
# hdfs dfs -cat <src> ...
hadoop fs -cat /test.txt
# hdfs dfs -cat <src> | more
# 读取大文件时,防止可以使用 管道符配合more 进行翻页查看。
hadoop fs -cat /test2.txt | more
# 5.从HDFS中向Linux中下载文件
# hdfs dfs -get [-f] [-p] <src> ... <localdst>
hdfs dfs -get /test.txt . #.代表Linux的当前目录,将test文件下载到Linux当前目录
hdfs dfs -get -f /test.txt .
# 6. 拷贝HDFS文件/改名
# hdfs dfs -cp [-f] <src> ... <dst> #两个路径都是HDFS文件系统中的路径
# <src>是被复制的路径。<dst>是目标路径
hdfs dfs -cp /test.txt /home/
hdfs dfs -cp /test.txt /home/abc.txt
# 7. 追加数据到HDFS文件中:HDFS文件系统中文件的修改仅支持 删除文件 和 追加内容 两种,不能修改其中的内容。
vim append.txt #在Linux本地创建文件append.txt
hadoop fs -appendToFile append.txt /test.txt #将本地的文件追加到HDFS文件系统的test文件末尾
# 8. HDFS数据移动操作/重命名
hadoop fs -mv /test.txt /itheima/ #将test文件移动到itheima文件夹下
hadoop fs -mv /test2.txt /itheima/abc.txt. #完成移动文件的同时对文件进行改名
# 9. HDFS数据删除操作:删除文件-rm or文件夹-rm -r
# hadoop fs -rm -r [-skipTrash] URI [URI ...]
# -skipTrash 跳过回收站,直接删除;回收站默认是关闭的,如果要开启需要在core-site.xml内配置(在那个机器里配置,那个机器即时生效,不需要重启集群)
hadoop fs -rm -r /home
hadoop fs -rm /test.txt
?命令官方指导文档
Hadoop文档
除了写命令,也可以在HDFS WEBUI网页端上进行操作(有些操作没有权限,但是可以授予权限,进行以下配置)。
| mkdir | 创建文件夹 |
| ls、cat | 列出内容、查看内容 |
| cp、mv、rm | 复制、移动、删除 |
| put、get | 上传、下载 |
| appendToFile | 向文件追加内容 |
Permission denied:遇到这种体型,其实是因为在HDFS之上没有权限。在整个HDFS文件系统中,也是有文件的权限控制的,它的逻辑和Linux文件系统完全一致。既然有权限控制,那么就存在超级用户,HDFS与Linux之间的不同之处在于超级用户的不同,Linux的超级用户是root,HDFS文件系统的超级用户是(也就是课程的hadoop用户)。因此,如果在遇到这个问题,大概率是因为操作HDFS时没有以Hadoop用户执行,而是以root用户执行。
# 在HDFS中,可以使用和Linux一样的授权语句,即:chown和chmod
# 修改所属用户和组:
hadoop fs -chown [-R] root:root /xxx.txt
hdfs dfs -chown [-R] root:root /xxx.txt
hdfs dfs -chown root:supergroup /test.txt
# 修改权限
hadoop fs -chmod [-R] 777 /xxx.txt
hdfs dfs -chmod [-R] 777 /xxx.txt
hdfs dfs -chmod -R 777 /data
# -R:对子目录也会生效,将文件xxx.txt的权限改成777# 课后练习
hadoop fs -mkdir -p /itcast/itheima
hadoop fs -put /etc/hosts /itcast/itheima/
hadoop fs -ls /itcast/itheima
hadoop fs -cat /itcast/itheima/hosts
vim append.txt #(要追加的内容:itheima)
hadoop fs -appendToFile append.txt /itcast/itheima/hosts
hadoop fs -cat /itcast/itheima/hosts
hadoop fs -get /itcast/itheima/hosts .
hadoop fs -mkdir /itcast/bigdata
hadoop fs -cp /itcast/itheima/hosts /itcast/bigdata/
hadoop fs -ls /itcast/bigdata
hadoop fs -cat /itcast/bigdata/hosts
hadoop fs -mv /itcast/itheima/hosts /itcast/itheima/myhost
hodoop fs -ls /itcast/itheima/
hadoop fs -rm -r /itcast
2.5.3 HDFS客户端 -?Jetbrians产品插件
了解在JetBrains产品中(IntelliJ IDEA、PyCharm、DataGrip)安装使用Big Data Tools插件,去对HDFS的文件系统进行相关的操作。以DataGrip为例。
设置 -> Plugins(插件) -> Marketplace(市场)-> 搜索Big Data Tools,点击Install安装即可。完整配置过程见视频:windows
第二章-11-[实操]HDFS客户端-Big Data Tools插件_哔哩哔哩_bilibili
2.5.4 HDFS客户端-NFS
目标:使用NFS网关功能将HDFS文件系统挂载到我们windows本地系统中。
将HDFS挂载到类似于C盘D盘的位置。
配置NFS:
1. core-site.xml,新增配置项;hdfs-site.xml,新增配置项;
2.?开启portmap、nfs3两个进程。

课程设置的允许192.168.88.1以rw链接(这个IP是电脑虚拟网卡VMnet8的IP,连接虚拟机就走这个网卡)?
cd /export/server/hadoop/etc/hadoop/
vim core-site.xml
# 配置相应内容
vim hdfs-site.xml
配置好这些功能之后,启用NFS功能:
# 1.将配置好的core-site.xml和hdfs-site.xml分发到node2和node3
scp core-site.xml hdfs-site.xml node2:'pwd'/
scp core-site.xml hdfs-site.xml node3:'pwd'/
# 2.重启HadoopHDFS集群(先stop-dfs.sh,后start-afs.sh)
stop-dfs.sh
# 3.停止系统的NFS相关进程(hadoop没有权限,需要退回root用户)
# a.systemctl stop nfs;systemctl disable nfs关闭系统nfs并关闭其开机自启
# b.yum remove-y rpcbind卸载系统自带rpcbind
exit
systemctl stop nfs
systemctl disable nfs
yum remove-y rpcbind(我们需要用hdfs系统自带的portmap)
# 4.启动portmap(HDFS自带的rpcbind功能)(必须以root执行):
hdfs--daemon start portmap
# 5.启动nfs(HDFS自带的nfs功能)(必须以hadoop用户执行):
hdfs--daemon start nfs3
检查NFS是否正常:
?1. 在node-2和node-3中执行:rpcinfo -p node1,正常输出有mountd和nfs出现。
2. 执行 showmount -e node1,可以看到 /192.168.88.1
在windows挂载HDFS文件系统
第二章-12-[可选]HDFS客户端-NFS挂载到Windows本地_哔哩哔哩_bilibili
2.6 HDFS的存储原理?
2.6.1 存储原理??
目标:了解数据是如何在HDFS中进行存储的;了解数据在HDFS中是如何保证安全的
????????1. 设定统一的管理单位——block块:是HDFS最小存储单位,每个256MB(可以修改)。
????????2. 通过多个副本(备份)解决,每个副本都复制到其他服务器1份,安全性极大提高;
总结:数据存入HDFS是分布式存储,即每一个服务器节点,负责数据的一部分;数据在HDFS上是划分为一个个Block块进行存储;在HDFS上,数据Block块都可以有多个副本,副本也会分发到其他服务器上,提高数据安全性。
2.6.2 fsck命令
目标:了解如何配置HDFS数据块的副本数量;掌握fsck命令查看文件系统状态及验证文件的副本数量
方法1: ?默认是3副本数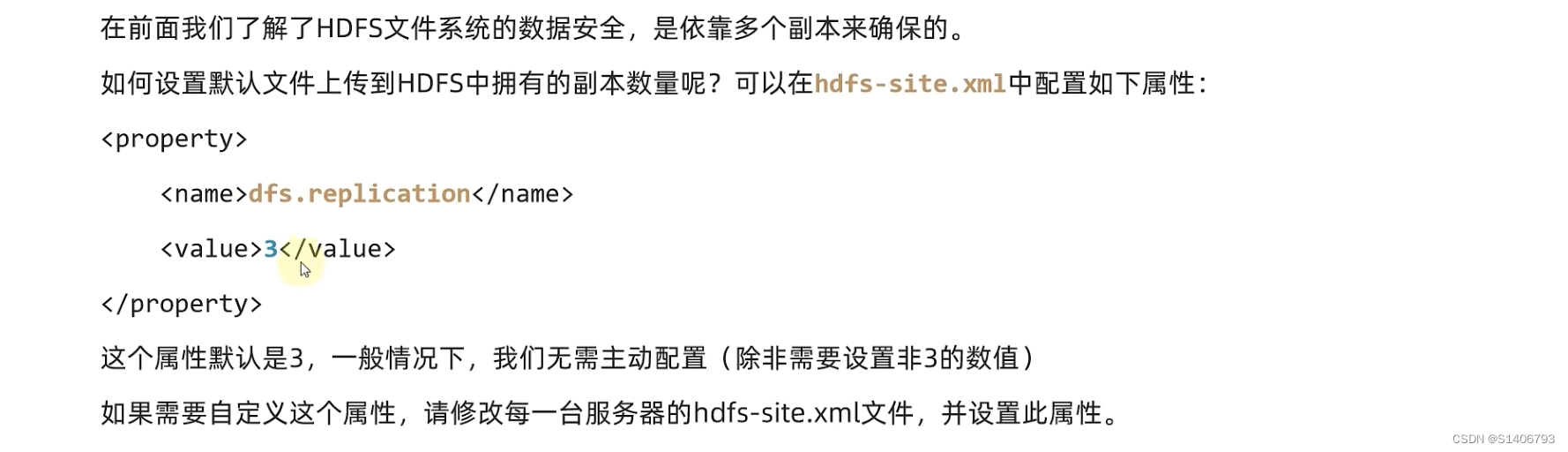
方法2: ?除了配置文件外,我们还可以在上传文件的时候,临时决定被上传文件以多少个副本存储。只针对本次生效
方法3: ?对于已经存在HDFS的文件,修改dis.replication屆性不会生效,如果要修政已存在文件可以通过命令
使用fsck命令去检查文件的副本数、blocks数、位置:
hadoop fs -D dfs.replication=2 -put test.txt /tmp/ #方法2
hadoop fs -setrep [-R] 2 path #方法3
# hdfs fsck path [-files [-blocks [-locations]]] #检查副本数
hdfs fsck /test.txt -files -blocks -locations
2.6.3 NameNode元数据
目标:掌握NameNode是如何管理Block块的
????????edits文件:是一个流水账文件,记录了hdfs中的每一次操作,以及本次操作影响的文件其对应的block
?? ? ? ?fsimage文件:將全部的edits文件,合并为最终结果,即可得到一个FSimage文件
NameNode基于edits和FSimage的配合,完成整个文件系统文件的管理(维护整个文件系统元数据)
- edits记录每次操作
- fsimage,记录某一个时间节点的当前文件系统全部文件的状态和信息
????????1.每次对HDFS的操作,均被edits文件记录
????????2.edits达到大小上线后,开启新的edits记录
????????3. 定期进行edits的合并操作(元数据合并参数可以修改)
? ? ? ? ? ? ? ? a.?如当前没有fsimage文件,将全部edits合并为第一个fsimase
? ? ? ? ? ? ? ? b.?如当前己存在fsimage文件,将全部edits和己存在的fsimage进行合并,形成新的fsimage
??:NameNode是写edits文件,合并操作是又SecondaryNameNode做的,合并完成再提供给NameNode文件使用。
???????2.6.4?HDFS数据的读写流程
目标:理解客户端在HDFS上读、写数据的流程
写入流程: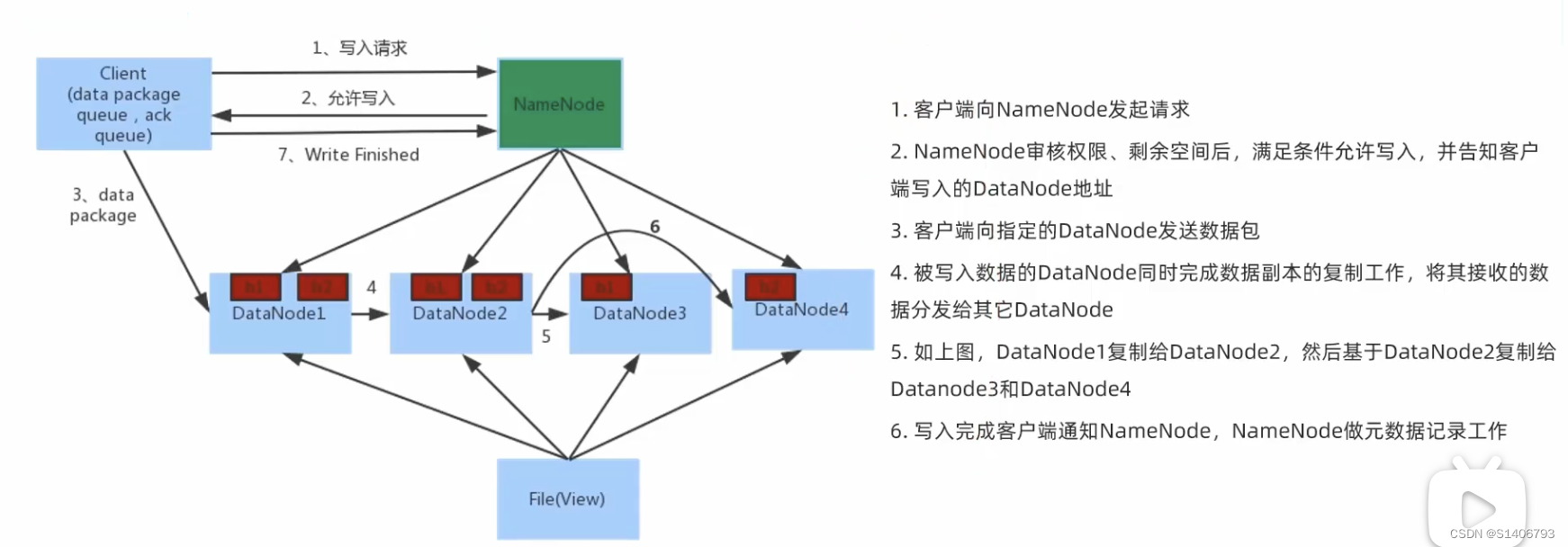
1. NameNode不接收数据,不负责数据写入,只负责元数据记录和权限审批
2.?客户端直接向1台DataNode写数据。这个DataNode一般是离客户端最近(网络距离)的那个
3. 数据块副本的复制工作,由DataNode之间自行完成(构成一个PipLine,按顺序复制分发,如图1给2,2给3和4)
读取流程: ???????
???????
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- STM32 看门狗多线程状态监护 - 基于RT-Thread应用 - 源码
- 一套系统搞定办公用品管理,行政工作省事不少!
- 第五章 存储管理【操作系统】
- idea快捷键
- ROS USB_cam功能包
- springboot 拦截器 interceptorRegistration excludePathPatterns的url该怎么写?
- 三、POD详解
- Python + RobotFramework 测试框架分享三(Web项目实践)
- 202312 青少年软件编程等级考试Scratch一级真题(电子学会)
- Eureka的自我保护机制