万字长文 详细讲述 计算机网络层
网络层
网络层的几个重要概念
网络层要设计得尽量简单,向其上层只提供简单灵活的无连接的、尽最大努力交付的数据报服务。
IP 数据报和 IP 分组是同义词,可以混用。
虚电路服务与数据报服务的对比
| 对比的方面 | 虚电路服务 | 数据报服务 |
|---|---|---|
| 思路 | 可靠通信由网络保证 | 可靠通信用户主机保证 |
| 连接建立 | 必须有 | 不需要 |
| 终点地址 | 仅在连接时使用,每个分组使用短的虚拟电路 | 每个分组都要有完整的地址 |
| 分组的转发 | 属于同一条虚拟电路的分组均按照同一路由进行转发 | ; 每个分组查找转发表进行转发 |
| 节点出故障时 | 所有通过故障节点的虚拟电路均不能工作 | 出故障的节点可能会丢失分组,一些路由可能会发生变化 |
网络层的两个层面
第一类是转发源主机和目的主机之间所传送的数据
第二类则是传送路由信息

在传统的互联网中,每一个路由器中,既有转发表义有路由选择软件,因此既有数据层面也有控制层面。
软件定义网络 SDN (Software Defined Network)
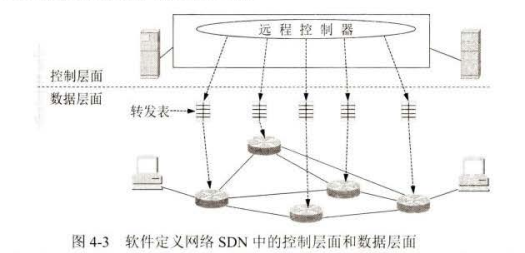
但路由器中的路由选择软件都不存在了,因此路由器之间不再相互交换路由信息。在网络的控制层面有一个在逻辑上集中的远程控制器(但在物理上可以巾不同地点的多个服务器组成)。
网际协议 IP
与协议 TP 配套仗用的还有三个协议:
? 地址解析协议 ARP (Address Resolution Protocol)
? 网际控制报文协议 ICMP (Internet Control Message Protocol)
? 网际组管理协议 IGMP (Internet Group Management Protocol)

虚拟互连网络
从一般的概念来讲,将网络互相连接起来要使用一些中间设备。根据中间设备所在的层次,可以有以下四种不同的中间设备:
(I) 物理层使用的中间设备叫作转发器(repeater)
(2) 数踞链路层使用的中间设备叫作网桥或桥接器(bridge), 以及交换机(switch)
(3) 网络层使用的中间设备叫作路由器(router) 了。
(4) 在网络层以上使用的中间设备叫作网关(getway)。
IP 地址
IP 地址及其表示方法
-
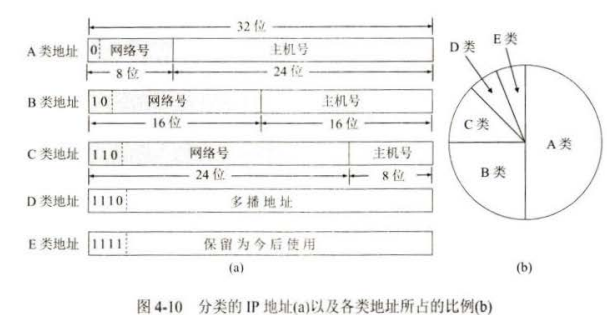
分类的 IP 地址
整个的互联网就是一个单一的、抽象的网络。 IP 地址就是给连接到互联网上的每一台中机(或路由器)的每一个接口,分配一个在全世界范围内是唯一的 32 位的标识符。
IP 地址 ::= { <网络号>,<主机号>}
-
无分类编址 CIDR
是无分类域间路由选择 CIDR (Classless Inter-Doma in Routing, CIDR 的读音是 “s der")
(1) 网络前缀
网络号改称为“网络前缀" network-prefix) (或简称为“前缀")
用来指明网络,剩下的后面部分仍然是主机号,用来指明主机。
IP 地址 ::= { <网络前缀>,<主机号>}
CIDR 使用"斜线记法 ”(slash no ti on), 或称为 CIDR 记法,即在地址后面加上斜线”/”,斜线后面是网络前缀所占的位数。例如, CIDR 表示的一个 IP 地址 128.14.35.7/20,二进制 IP 地址的前 20 位是网络前缀,剩下后面 12 位是主机号。
(2) 地址掩码
计算机看不见斜线记法,而是使用二进制来进行各种计算时就必须使用 32 位的地址掩码(address mask) 能够从IP地址迅速算出网络地址。
地址掩码(常简称为掩码)由一连串0和接着的一连串1组成,而1的个数就是网络前缀的长度。地址掩码又称为子网掩码兜在 CIDR 记法中,斜线后面的数字就是地址掩码的个数。例如, /20 地址块的地址掩码是: 111111 I 1 1111111 I I 11 I 0000 00000000 (20连续的 和接着的 12 个连续的 0) 。这个掩码用 CIDR 记法表示就是 255.255.240.0/20把二进制的 IP 地址和地址掩码进行按位 AND 运算,即可得出网络地址 -
IP 地址的特点
lP 地址具有以下一些重要特点。
(I) 每一个 IP 地址都由网络前缀和主机号两部分组成。从这个意义上说, IP 地址是一种分等级的地址结构。分两个等级的好处是:第一,IP地址管理机构在分配 IP 地址时只分配网络前缀(第一级),而剩下的主机号(第二级)则由得到该网络前缀的单位自行分配。第二,路由器根据目的主机所连接的网络前缀(即地址块)来转发分组(而不考虑目的主机号),这样就可以使转发表中的项目数大幅度减少。
(2) 实际上 IP 地址是标志一台主机(或路由器)和一条链路的接口。当一台中机同时迕接到两个网络上时,该主机就必须同时具有两个相应的 IP 地址,其网络前缀必须是不同的。这种主机称为多归属主机(mul ti homed host)。由由于一个路由器至少应当连接到两个网络,因此一个路由器至少应当有两个不同的 IP 地址。
(4) IP 地址中,所有分配到网络前缀的网络都是平等的。
IP 地址与 MAC 地址
MAC 地址是数据链路层使用的地址,而 IP 地址是网络层和以上各层使用的地址,是一种逻辑地址。

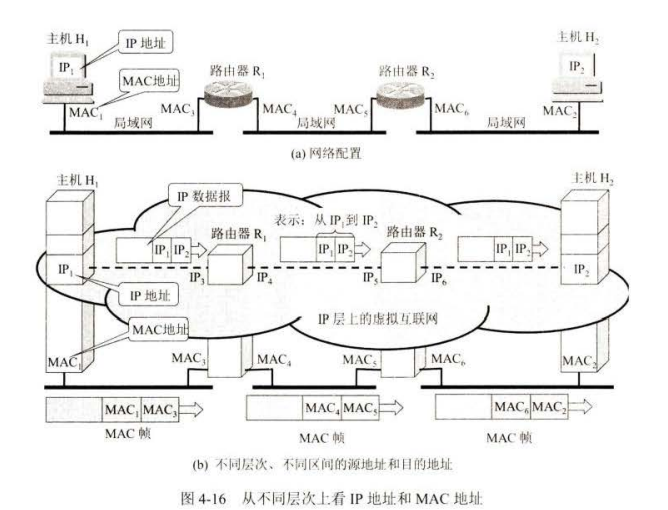
(I) IP 层抽象的互联网上只能看到 IP 数据报。
(2) 虽然在 IP 数据报首部有源站 IP 地址,但路由器只根据目的站的 IP 地址进行转发。
(3) 在局域网的链路层,只能看见 MAC 帧。 IP 数据报攸封装竹· MAC 帧中。
(4) 尽管互连在一起的网络的 MAC 地址体系各不相回,但 IP 层抽象的互联网却屏蔽了下层这些很复杂的细节
地址解析协议 ARP

网络层使用的是 IP 地址,但在实际网络的链路上传送数据帧时,最终还是必须使用链路层的 MAC 地址。
解析协议 ARP 解决这个问题的方法是在主机的 ARP 高速缓存中存放一个从 IP 地址到 MAC地址的映射表,并且这个映射表还经常动态更新(新增或超时删除)。
每一台主机都设有一个 ARP 高速缓存(ARP cache), 里面存有本局域网上的各主机和路由器的 IP 地址到 MAC 地址的映射表,映射表存在生存时间,为了处理映射变动。
arp工作
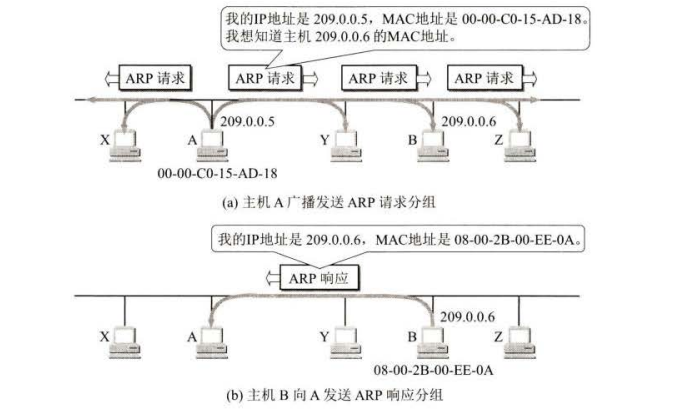
ARP 用于解决同一个局域网上的主机或路由器的 IP 地址和 MAC 地址的映射间题。
IP 数据报的格式
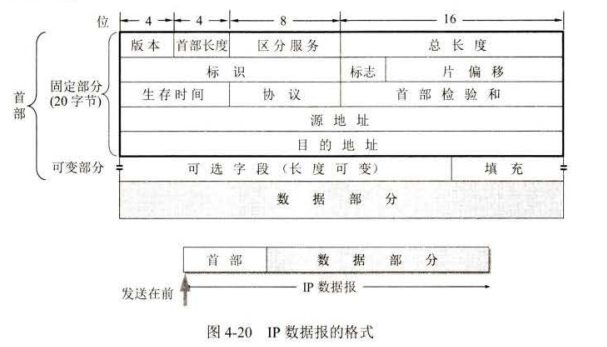
IP 数据报首部的固定部分中的各字段
(I) 版本 4位(即 IPv4) 。关于IPv6 (即版本的协议 lP),
(2) 首部长度 4位,可表示的最大十进制数值是 15 。首部长度字段所表示数的单位是 32 位字长( 32 位字长是 字节)。因为 IP 首部的固定部分是 20 字节,因此首部长度字段的最小值是 (即二进制表示的首部长度是 0101) 。
(3) 区分服务 8位,用来获得更好的服务。
(4) 总长度 总长度指首部和数据之和的长度,单位为字节。总长度字段为 16 位,IP协议下面的每一种数据链路层协议都规定了一个数据帧中的数据字段的最大长度,这称为最大传送单元 MTU (Maximum Transfer Unit)。
(5) 标识 (identification)16 位。 IP软件在存储器中维持一个计数器,每产生一个
数据报,计数器就加1, 并将此值赋给标识字段。当数据报由于长度超过网络的 MTU 而必须分片时,这个标识字段的值就被复制到所有的数据报片的标识字段中。相同的标识字段的值使分片后的各数报片最后能止确地平装成为原来的数据报。
(6) 标志(flag) 3位,但目前只有两位有意义。
? 标志字段中的最低位记为 MF (More Fragment)。 MF= 即表示后面”还有分片”的数据报。 MF=0 表示这已是若干数据报片中的最后一个。
? 标忐字段中间的一位记为 DF (Don’t Fragment),意思是“不能分片”。只有当 DF = 0时才允许分片。
(7)片偏移 13 位。片偏移指出:较长的分组在分片后,某片在原分组中的相对位置.
(8) 生存时间 8位,生存时间字段常用的英文缩写是 TTL (Time To Live), 表明这是数据报在网络中的寿命。由发出数据报的源点设置这个字段。其目的是防止无法交付的数据报无限制地在互联网中圈子。
(9) 协议 8位,协议字段指出此数据报携带的数据使用何种协议,以便使目的主机的 IP 层知道应将数据部分上交给哪个协议进行处理。
(10) 首部检验 16 位。这个字段只检验数据报的首部,但不包括数据
(11) 源地址
(12) 目的地址
IP层转发分组过程
基于终点的转发
先查找目的网络(网络前缀),在找到了目的网络之后,就把分组在这个网络上直按交付目的主机。
最长前缀匹配
减少转跳次数,更精准的转跳
机路由(host route) 又叫作特定主机路由,这是对特定目的主机的 IP 地址专门指明的一个路由。采用特定主机路由可使网络管理人员更方便地控制网络和测试网络,同时也可在需要考虑某种安全问题时采用这种特定主机路由。
还有一种特殊路由是默认路由(defaul rou e) 。这就是不管分组的最终目的网络在哪里,都由指定的路由器 来处理。
网际控制报文协议 ICMP
为了更有效地转发 IP 数据报和提高交付成功的机会,在网际层使用了网际控制报文协ICMP (Internet Control Message Protocol) ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告。

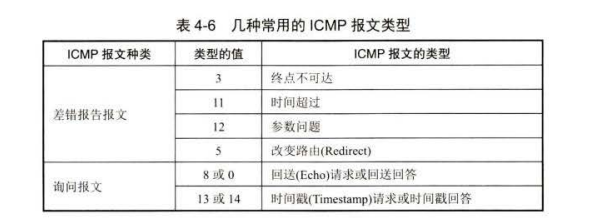
ICMP 报文的种类
ICMP 报文有两种,即 ICMP 差错报告报文和 lCMP 询间报文。
ICMP 报文的前 字节是统一的格式,共有三个字段:类型、代码和检验和。
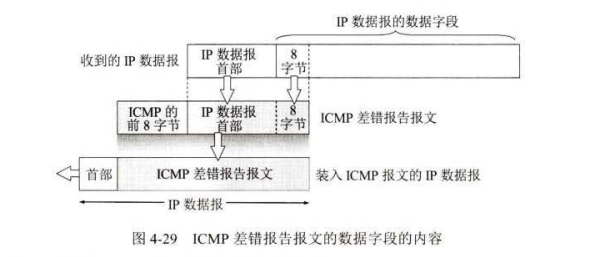
下面是不应发送 ICMP 差错报告报文的几种情况:
? ICMP 差错报告报文,不再发送 ICMP 差错报告报文。
? 对第一个分片的数据报片的所有后续数据报片,都不发送 ICMP 差错报告报文。
? 对具有多播地址的数据报,都不发送 ICMP 差错报告报文。
? 对具有特殊地址(如 127.0.0.0 0.0.0.0) 的数据报,不发送 ICMP 差错报告报文。
ICMP 的应用举例
ICMP 的一个重要应用就是分组网间探测 PING (Packet ln terNe t Gro er), 用来测试两台主机之间的连通性。PING 使用了 ICMP 回送诮求与回送回答报文。 PlNG 是应用层直接使用网络层ICMP 的一个例子。它没有通过运输层的 TCP UDP
IPv6 的基本首部
(1) 更大的地址空间。
(2) 扩展的地址层次结构。 IPv6 由于地址空间很大,因此可以划分为更多的层次。
(3) 灵活的首部格式。 IPv6 数据报的首部和 IPv4 的并不兼容。 IPv6 定义了许多可选的扩展首部,不仅可提供比 IPv4 史多的功能,而且还可提高路由器的处理效率,这是因为路由器对扩展首部不进行处理(除逐跳扩展首部外).
(4) 改进的选项。IPv6 允许数据报包含有选项的控制信息,因而可以包含一些新的选项。IPv6 的首部长度是固定的,其选项放在有效载荷中。
(5) 允许协议继续扩充。
(6) 支持即插即用(即自动配置)。因此 IPv6 不衙要使用 DHCP
(7) 支持资源的预分配。
(8) IPv6 首部改为8字节对齐


(1) 版本(version) 4位
(2) 通信量类(traffic class)8位。这是为了区分不同的 IPv6 数据报的类别或优先级。
(3) 流标号(flow label) 20 位。 IPv6 的一个新的机制是支待资源预分配,并且允许路由器把每一个数据报与一个给定的资源分配相联系。 IPv6 提出流(flow) 的抽象概念。所谓“流”就是互联网络上从特定源点到特定终点(单播或多播)的一系列数据报(如实时音频或视频传输),而在这个“流”所经过的路径上的路由器都保证指明的服务质量。所有属于同一个流的数据报都具有同样的流标号。
(4) 有效载荷长度(payload length) 16 位。它指明 IPv6 数据报除基本首部以外的字节数(所有扩展首部都算在有效载荷之内)。
(5) 下一个首部(next header) 位。它。它相当千 IPv4 的协议字段或可选字段。
? IPv6 数据报没有扩展首部时,下一个首部字段的作用和 1Pv4 的协议字段一样,它的值指出了基本首部后面的数据应交付 IP 层上面的哪一个高层协议
? 当出现扩展首部时,下一个首部字段的值就标识后面第一个扩展首部的类型。
(6) 跳数限制(hop limit) 位。用来防止数据报在网络中无限期地存在。
(7) 源地址 128 位。是数拟报的发送端的 IP 地址。
(8) 目的地址 128 付。是数据报的接收端的 IP 地址。下六种扩展首部: (1)逐跳选项; (2) 路由选择: (3) 分片: (4) 鉴别; (5) 封装安全有效载荷: (6) 目的站选项。
IPv6 的地址
(1) 单播(unicast) 单播就是传统的点对点通信。 视躲讲梢
(2) 多播(multicast) 多播是一点对多点的通信,数据报发送到一组计算机中的每一个。
1Pv6 没有采用广播的术语,而是将「播行作多播的一个特例。
(3) 任播(anycast) 这是 IPv6 增加的一种类型。任播的终点是一组计箕机,但数据报只交付其中的一个,通常是按照路由符法得出的距离最近的一个。
IPv4 向IPv6 过渡
-
双协议栈
双协议栈(dual stack) 是指在完全过渡到 IPv6 之前,使一部分主机(或路由器)同时装IPv4 1Pv6 这两种协议栈。因此双协议栈生机(或路由器)既能够和 IPv6 的系统通信,又能够和 1Pv4 的系统通信。 -
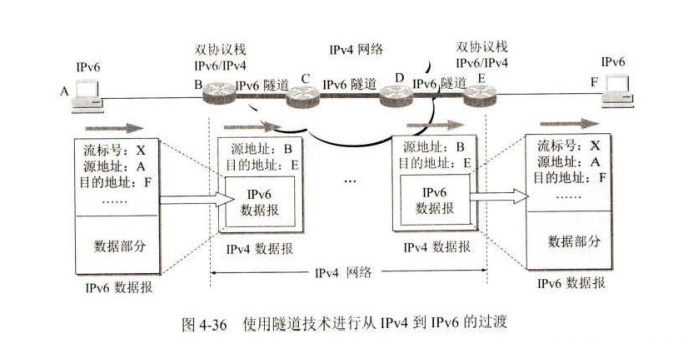
隧道技术
IPv6 过渡的另一种方法是隧道技术(tunneling)。
这种方法的要点就是在 IPv6 数据报要进入 1Pv4 网络时,把 IPv6 数据报封装成为 lPv4 数据
ICMPv6
IPv4 一样, IPv6 也不保证数据报的可靠交付,因为互联网中的路由器可能会丢弃数据报。因此 IPv6 也需要使用 ICMP 来反馈一些差铅信息。新的版本称为 ICMPv6, 它比ICMPv4 要复杂得多。地址解析协议 ARP 和网际组管理协议 IGMP 的功能都已被合并到 ICMPv6中。
互联网的路由选择协议
有关路由选择协议的几个基本概念
理想的路由算法
路由选择协议的核心就是路由算法,即需要何种算法来获得路由表中的各项目。一个理想的路由算法应具有如下的一些特点(BELL86):
(1) 算法必须是正确的和完整的。这里,“正确"的含义是:沿若各路由表所指引的路由,分组一定能够最终到达目的网络和目的主机。
(2) 算法在计算上应简单。路由选择的计算不应使网络通信垃增加太多的额外开销。
(3) 算法应能适应通信量和网络拓扑的变化,这就是说,要有自适应性。当网络中的通信量发生变化时,算法能自适应地改变路由以均衡各链路的负载。当某个或某些节点、链路发生故障不能工作,或者修理好了再投入运行时,算法也能及时地改变路由。有时称这种自适应性为"稳健性 ”(robusttness)
(4) 算法应具有稳定性。在网络通信量和网络拓扑相对稳定的情况下,路由算法应收敛于一个可以接受的解,而不应使得出的路由不停地变化。
(5) 算法应是公平的。
(6) 算法应是最佳的。路由选择算法应当能够找出最好的路由,使得分组平均时延最小而网络的吞吐量最大。
- 分层次的路由选择协议
互联网采用分层次的路由选择协议
(1) 互联网的规模非常大。
(2) 许多单位不愿意外界了解自己单位网络的布局细节和本部门所采川的路由选择协议,但同时还希望连接到凡联网 .
为此,可以把整个互联网划分为许多较小的自治系统(autonomous em), 一般都记为AS 。自治系统 AS 是在单一技术管理卜的许多网络、 IP 地址以及路由器,而这些路由器使用一种自治系统内部的路由选择协议和共同的度量。符一个 AS 对其他 AS 表现出的是一个单一的和一致的路由选择策略。这样,互联网就把路由选抒协议划分为两大类。
(1) 内部网关协议 IGP (Interior Gateway Protocol) 即在个自治系统内部使用的路由选择协议,
(2) 外部网关协议 EGP (External Gateway Protocol) 若源主机和 目的的主机处在不同的自治系统中(这曲个自治系统可能仗川个问的内部网关协,那么在不同自治系统 AS间的路由选择,就要使用外部网关协议 EGP 。自治系统之间的路由选择也叫作域间路由选择(interdomain routing),而在自治系统内部的路由选择叫作域内路由选择(intradomain routing)。
内部网关协议 RIP
- 协议 RIP 的工作原理
RIP (Routing lnfonnation Pro ocol) 是内部网关协议 IGP 中最先得到广泛使用的协议, 它的中文译名是路由信息协议。 RIP 是一种分布式 的基于距离向量的路由选择协议,是互联网的标准协议,其最大优点就是简单。
RIP 协议要求网络中的每一个路由器都要维护从它自己到其他每一个目的网络的距离记录(“距离向缢")。协议 RIP 将“距离“定义如下:
从一路由器到自接连接的网络的距离定义为 。从一主机到非直接连接的网络的距离定义为所经过的路由器数加 。协议 RlP 的("距离”'也称为“跳数”。),并且每经过一个网络,跳数就加1,最大为15协议 RIP 的特点是:
(1) 仅和相邻路由器交换信息。如果两个路由器之间的通信不需要经过另一个路由器,那么这两个路由器就是相邻的。
(2) 路由器交换的信息是当前本路由器所知道的全部信息,即自己现在的路由表。也就是说,交换的信息是:“我到本自治系统中所有网络的(最短)距离,以及到每个网络应经过的下一跳路由器”。
(3) 按固定的时间间隔交换路由信息,
2. 距离向量算法
对每一个相邻路由器发送过来的 RlP 报文,执行以下步骤:
(1) 对地址为X的相邻路由器发来的 RIP 报文,先修改此报文中的所有项目:把“下一跳”字段中的地址都改为 X, 并把所有的"距离”字段的值加1。每一个项目都有个三关键数据,即:到目的网络 Net,距离是 d, 下一跳路由器是X。
(2) 对修改后的 RTP 报文中的每一个项目,进行以下步骤:若原来的路由表中没有目的网络 Net,则把该项目添加到路由表中否则(即在路由表中有目的网络 Net,这时就再查看 一跳路由器地址)。若下一跳路由器地址是X,则把收到的项目替换原路由表中的项目否则(即这个项目是:到目的网络 Net,但下一跳路由器不是 X),若收到的项目中的距离 小于路由表中的距离,则进行更新,否则什么也不。
(3) 分钟还没有收到相邻路由器的更新路由表,则把此相邻路由器记为不可达的路由器,即把距离置为 16 (距离为 16 表示不可达)。
(4) 返回。上而给出的距离向量算法的基础就是 Bellman-Ford 算法(或 Ford-Fulkerson 算法)。
3. 坏消息传播得慢
好消息传播得快,而坏消息传播得慢
内部网关协议 OSPF
- 协议 OSPF 的基本特点
这个协议的名字是开放最短路径优先 OSPF (Open Shortest Path Frst)。
OSPF 最主要的特征就是使用链路状态协议(link state protocol), 协议 OSPF 的特点是:
(1) 向本自治系统中所有路由器发送信息。这里使用的方法是洪泛法(flooding),这就是路由器通过所有输出端口向所有相邻的路由器发送伯息。而每一个相邻路由器又再将此信息发往具所有的相邻路由器(但不再发送给刚刚发来信息的那个路由器)。
(2) 发送的信息就是与本路由器相邻的所有路由器的链路状态,但这只是路由器所知道的部分信息。所谓“链路状态”就是说明本路由器都和哪些路由器相邻“,以及该链路的,"度量 ”(metric) OSPF 将这个"度拉“用来表示费用、距离、时延、带宽,等等。
(3) 当链路状态发生变化或每隔一段时间(如 30 分钟),路山器向所有路由器用洪泛法发送链路状态信息。
为了使 OSPF 能够用于规模很大的网络, OSPF 将一个自治系统再划分为若干个更小的范围,叫作区域(area) 。
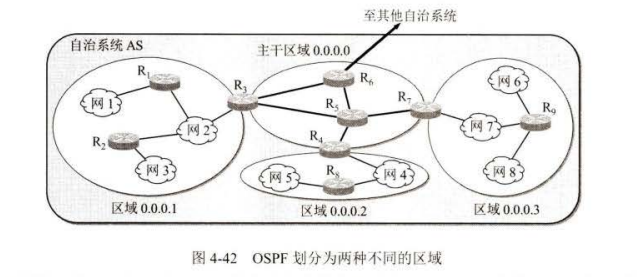
OSPF 还具有下列的一些特点:
(1) OSPF 允许管理员给每条路由指派不同的代价。因此,OSPF 对于不同类型的业务可计算出不同的路由。链路的代价可以是 65535 中的任何一个无位纲的数,因此十分灵活。商用的网络在使用 OSPF 时,通常根据链路带宽来计算链路的代价。这种灵活性是 RIP 所没有的。
(2) 如果到同一个目的网络有多条相同代价的路径,那么可以将通信量分配给这几条路径。这叫作多路径间的负载均衡(load balanc g)。
(3) 所有在 OSPF 路由器之间交换的分组(例如,链路状态更新分组)都具有鉴别的功能,因而保证了仅在可信赖的路由器之间交换链路状态信息。
(4) OSPF 支持可变长度的子网划分和无分类的编址 CIDR
(5) 由于网络中的链路状态可能经常发生变化,因此 OSPF 让每一个链路状态都带上一32 位的序号,序号越大状态就越新。
2. OSPF 的五种分组类型
OSPF 共有以下五种分组类型:
(1) 问候(Hello)分组,用来发现和维持邻站的可达性。
(2) 数据库描述(Databasc Descript) 分组,向邻站给出自己的链路状态数据库中的所有链路状态项目的摘要信息。
(3) *链路状态请求(Link State Request)*分组,向对方请求发送某些链路状态项目的详细信息。
(4) 链路状态更新(Link State Update) 分组,用洪泛法对全网更新链路状态。
(5) *链路状态确认(Link State Acknowledgment)*分组,对链路更新分组的确认。
外部网关协议 BGP
- 协议 BGP 的主要特点
第一,互联网的规模太大,使得自治系统 AS 之间路由选择非常困难。
第二,自治系统 AS 之间的路由选择必须考虑有关策略。例如:不能去外网 - BGP 路由
在一个自治系统 AS 中有两种不同功能的路由器,即边界路由器(或边界网关)和内部路由器。
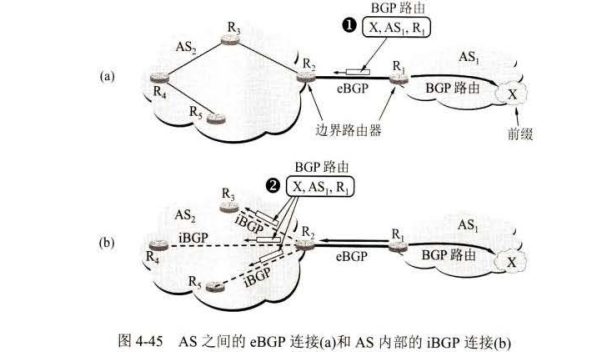
当两个边界路由器 进行通信时,必须先建立 TCP 连接,这种 TCP 连接又称为半永久性连接(即双方交换完信息后仍然保持着连接状态)。
BGP 路由=“前缀,BGP属性”=“前缀,AS-PATH, NEXT-HOP" 前缀的意思很明确,就是通告的 BGP 路由终点(子网前缀)。
BGP属性有好几种类型但最重要两个就是这里列出的 AS-PATH NEXT-HOP.
BGP 路由每经过一AS, 就将其自治系统号 ASN 加入到 AS-PATH 中 “BGP 路由“必须指出通过哪些自治系统 AS, 但不指出路由中途要通过哪些路由器。
NEXT-HOP (下一跳)是通告的 BGP 路由起点。
-
三种不同的自治系统 AS
可以把 AS 划分为中所示的三大类,即末梢 AS (stub AS) 、穿越 AS (transit AS) 和对等AS(peering AS)

-
BGP 的路由选择
但如果到前缀 有两条或更多的 BGP 路由可供选择,那么就应当根据以下的原则,按照这里给出的先后顺序,选择一条较好的 BGP 路由.
假如从一个 AS 到另外 AS 中的前缀 只有一条 BGP 路由,那么就不存在选择
? 本地偏好 LOCAL-PREF (LOCAL PREFerence)值极高的路由要首先选择。
BGP 路由中的屈件里面有一个选项叫作本地偏好,在属性中记为LOCAL-PREF 。本地偏好也就是本地优先,“本地”的意思是指,从本 AS 开始的、到同一个前缀的不问 BGP路由中,挑选一个较好的(路由。这可由路由器管理员或网络管理员根据政治上或经济上的策略来设置。
? 选择具有 AS 跳数最少的路由。
? 使用热土豆路由选择算法。
看那个端口空闲
? 选择路由器 BGP 标识符的数值最小的路由。
当以上几种方法都无法找出最好的 BGP 路由时,就可使用 BGP 标识符来选择路由。
5. BGP 的四种报文
(1) OPEN (打开)报文,用来与 BGP 连接对等端建立关系。
(2) UPDATE (更新)报文,用来通告某一路由的信息,以及列出要撤销的路由。
(3) KEEPALIVE (保活)报文,用来周期性地证实与对等端的连通性。
(4) NOTIFICATION (通知)报文,用来发送检测到的差错。
OPEN 报文足两个路由器之间建立了 TCP 连接后接浩就必须发送的报文。 OPEN 报文的作用是相互识别对方,协商-些协议参数(如计时器的时间)。收到 OPEN 报文的路由器,就发问 KEEPALIVE 报文表示接受建立 BGP 连接。
路由器的构成
- 路由器结构
路由器是一种具有多个输入端口和多个输出端口的专用计算机,其任务是转发分组。从路由器某个输入端口收到的分组,按照分组要去的目的地(即目的网络),把该分组从路由器的某个合适的输出端口转发给下一跳路由器。下一跳路由器也按照这种方法处理分组,直到该分组到达终点为止。路由器的转发分组正是网络层的主要工作。

整个的路由器结构可划分为两大部分:路由选择部分和分组转发部分。
路由选择部分也叫作控制部分,或控制层面,其核心构件是路由选择处理机。路由选择处理机的任务是根据所选定的路由选择协议构造出路由表,同时经常或定期地和相邻路由器交换路由信息而不断地更新和维护路由表。
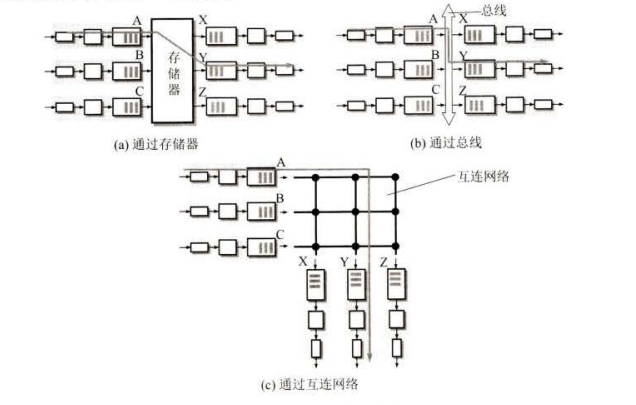
分组转发它由三部分组成:交换结构、一组输入端口和一组输出端口。小型路由器的端口只有几个。
交换结构(switch fabric) 又称为交换组织,它的作用就是根据转发表(forward table) 对分组进行处理,将某个输入端口进入的分组从一个合适的输出端目转发出去。
2. 交换结构
交换结构是路由器的关键构件正是这个交换结构把分组从一个输入端口转移到某个合适的输出端口。
IP 多播
IP 多播的基本概念
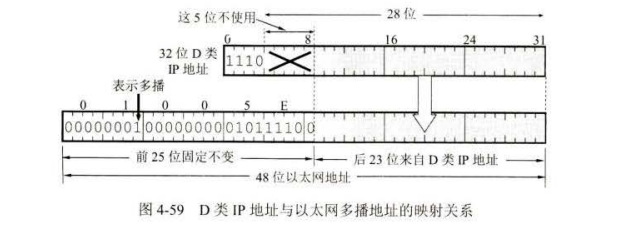
在互联网上进行多播就叫做 IP 多播。 IP 多播所传送的分组需要使用多播 IP 地址。。在多播数据报的目的地址写入的是多捅组的标识符,然后设法让加入到这个多播组的主机的 IP 地址与多播组的标识符关联起来。

多播地址只能用于目的地址,面不能用于源地址。此外,对多播数据报不产生ICMP 差错报文。因此,若在 PTNG 命令后面键入多播地址,将永远不会收到响应。其实多播组的标识符就是 IP 地址中的D类地址。
在局域网上进行硬件多播
网际组管理协议 IGMP 和多播路由选择协议
- IP 多播需要两种协议

IGMP 并非在互联网范围内对所有多播组成员进行管理的协议。 IGMP 不知道 IP 多播组包含的成员数,也不知道这些成员都分布在哪些网上。 lGMP 协议是让连接在本地局域网上的多播路由器知道本局域网上是否有
主机参加或退出了某个多播组。
多播转发必须动态地适应多播组成员的变化(这时网络拓扑并未发生变化)
多播路由器在转发多播数据报时,不能仅仅根据多播数据报中的目的地址,而是还要考虑这个多播数据报从什么地方来和要到什么地方去。
多播数据报可以由没有加入多播组的主机发出,也可以通过没有组成员接入的网络
2. 网际组管理协议 IGMP
第一阶段:当某台主机加入新的多播组时,该主机应向多播组的多播地址发送一个IGMP 报文,声明自己要成为该组的成员。本地的多播路由器收到 IGMP 报文后,还要利用多播路由选择协议把这种组成员关系转发给互联网上的其他多播路由器。
第二阶段:组成员关系是动态的。本地多播路由器要周期性地探询本地局域网上的主机,以便知道这些主机是否还继续是组的成员。只要有一台主机对某个组响应,那么多播路由器就认为这个组是活跃的。
IGMP 设计得很仔细,避免了多播控制信息给网络增加大批的开销。 IGMP 采用的一些具体措施如下:
(1) 在主机和多播路由器之间的所有通信都使用 IP 多播。只要有可能,携带 IGMP文的数据报都用硬件多播来传送。因此在支持硬件多播的网络上,没有参加 IP 多播的主机不会收到 IGMP 报文。
(2) 多播路由器在探询组成员关系时,只需要对所有的组发送一个请求信息的询问报文。
(3) 当同一个网络上连接有几个多播路由器时,它们能够迅速和有效地选择其中的一个来探询主机的成员关系。因
(4) IGMP 的询问报文中有一个数值 N, 它指明一个最长响应时间
(5) 同一个组内的每一台主机都要监听响应,只要有本组的具他主机先发送了响应,自己就可以不再发送响应了。
- 多播路由选择协议
多播路由选择实际上就是要找出以源主机为根节点的多播转发树。
(1) 洪泛与剪除。这种方法适合于较小的多播组,而所有的组成员接入的局域网也是相邻接的。
(2) 隧道技术(tunneling)。隧道技术适用于多播组的位值在地理上很分散的情况。

(3) 基于核心的发现技术。这这种方法是对每一个多播组 指定一个核心(core) 路由器,给出它的 IP 单播地址。核心路由器创建出对应于多播组的转发树。
虚拟专用网 VPN 和网络地址转换 NAT
在互联网中的所有路由器,对目的地址是专用地址的数据报一律不进行转发。全面地给出了所有特殊用途的 1Pv4 1Pv6 地址,但三个 IPv4 专用地址块的指派并无变化,即
(I) 10.0.0.0/8, 即从 10.0.0.0 0.255.255.255
(2) 172.16.0.0/1 2, 即从 172.16.0.0 172.31.255.255
(3) 192.168.0.0/1 6, 即从 192.168.0.0 192 .1 68.255.255
采用这样的专用 IP 地址的互连网络称为专用互联网或本地互联网,或更简单些,就叫作专用网。

网络地址转换
网络地址转换 NAT (Network Address Translation)这种方法要在专用网连接到互联网的路由器上安装 NAT 软件。装有 NAT 软件的路由器叫作 NAT路由器,它至少有一个有效的外部全球 IP 地址。这样,所有使用本地地址的主机在和外界通信时,都要在 NAT 路由器上将其本地地址转换成全球 IP 地址,才能和互联网连接。

设想如果有专用网上外面的主机要发起通信,当 IP 数据报到达 NAT 路由器时, NAT 路由器就不知道应当把目的 TP地址转换成专用网内的哪一个本地 IP 地址。这就表明,专用网内部的主机不能直接充当服务器用。
使用端口号的 NAT 也叫作网络地址与端口号转换 NAPT (Network Address and Port Translation), 而不使用端口号的 NAT 就叫作传统的 NAT (trad onal NAT) 。
NAPT 地址转换表举例
| 方向 | 字段 | 原先的 IP 地址和端口号 | 转换后的 IP 地址和端口号 |
|---|---|---|---|
| 从专用网发往互联网 | IP 地址:TCP 源端口 | 192.168 0.3:30000 | 172.38.1.5:40001 |
| 从专用网发往互联网 | IP 地址.TCP 源端口 | 192.168.0.4:30000 | 172.38 l. 5·40002 |
| 从互联网发往专用网 | 目的 IP 地址TCP 日的端口 | 172.38.1.5:40001 | 192 168.0 3:30000 |
| 从互联网发往专用网 | 目的 IP 地址TCP 目的的端口 | 172.38.1.5:40002 | I92.168.0.4:30000 |
多协议标签交换 MPLS
MPLS 利用面向连接技术,使每个分组携带一个叫作标签(label)的小整数。当分组到达交换机(即标签交换路由器)时,交换机读取分组的标签,并用标签来检索分组转发表。
人们经常把 MPLS 与异步传递方式 ATM (Asynchronous Transfer Mode)联系起来,MPLS 并没有取代 IP,
而是作为一种 IP 增强技术,被广泛地应用在互联网中。
MPLS 具有以下三个方面的特点: (1) 支待面向连接的服务质械。 (2) 支持流量工程,均衡网络负载。(3) 有效地支持虚拟专用网 VPN
MPLS 的工作原理
- 基本过程
在传统的 IP 网络中,分组每到达一个路由器,都必须查找转发表,并
按照“最长前缀匹配"的原则找到下一跳的 IP 地址。当网络很大时,查找含有大量项目的转发表要花费很多的时间。
MPLS 的一个重要特点就是在 MPLS 域的入口处,给每一个 IP 数据报打上固定长度”标签“,然后对打上标签的 IP 数据报用硬件进行转发,表示在转发时不再上升到第三层查找转发表,而是根据标签在第二层(链路层)用硬件进行转发。 MPLS 可使用多种链路层协议,如 PPP 、以太网、 ATM 以及帧中继等。
MPLS (MPLS doma n) 是指该域中有许多彼此相邻的路由器,并且所有的路由器都是支持 MPLS 技术的标签交换路由器 LSR (Label Switching Router) LSR 同时具有标签交换和路由选择这两种功能,标签交换功能是为了快速转发,但在这之前 LSR 需要使用路由选择功能构造转发表
(1) MPLS 域中的各 LSR 使用专门的标签分配协议 LDP (Label Distribution Protocol) 交换报文,并找出和特定标签相对应的路径,即标签交换路径 LSP (Label Switched Path) 。
(2) 当一个 IP 数据报进入到 MPLS 域时, MPLS 入口节点(ingress node)就给它打上标签,井按照转发表把它转发给下一个LSR。以后的所打 LSR 都按照标签进行转发。
IP 数据报打标签的过程叫作分类(classificaon) 。严格的第三层(网络层)分类只使用IP 首部中的字段,如源 IP 地址和 IP 地址等。大多数运营商实现了第四层(运输层)分类(除了要检杏 IP 首部外,运输层还要检查 TCP或UDP 首部中的协议端口号),而有些运背商则实现了第五层(应用层)分类(更进一步地检查数据报的内部并若虑其有效载荷)。
(3) 由于在全网内统一分配全局标签数值是非常困难的,因此此一个标签仅仅在两个标签交换路由器 LSR 之间才有意义。分组每经过一个 LSR, LSR 就要做两件事:一处转发,二.是更换新的标签,即把入标签更换成为出标签。这就叫作标签对换(label swapping)
(4) IP 数据报离开 MPLS 域时, MPLS 出口节点(egress node)就把 MPLS 的标签去除,IP 数据报交付非 MPLS 的主机或路由器,以后就按照普通的转发方法进行转发。
- 转发等价类 FEC
MPLS 有个很正要的概念就是转发等价类 FEC (Forward ing Equivalence Class) 。所谓"转发等价类”就是路由器按照同样方式对待的 IP 数据报的集合。
MPLS 首部的位置与格式
在把 IP 数据报封装成以太网帧之前,先要插入 MPLS部。从层次的角度看, MPLS 首部就处在第二层和第三层之间.


MPLS 首部共包括以下四个字段:
(l) 标签值 20 位。由
(2) 试验 3位,目前保留用千试验。
(3) S 1位, (Stack)表示栈,在有“标签栈”时使用。
(4) 生存时间 TTL 8位,用来防止兜圈子
新一代的 MPLS
在 SDN 中,数据层面中的交换机是由控制层面进行控制的,这种控制是通过协议 OpenFlow 来实现的。 SDN 不是协议,更不是一种产品。 SDN 是一个体系结构,是一种设计、构建和管理网络的新方法或新概念,其要点就是把网络的控制层面和数据层面分离,而让控制层面利用软件来控制数据层面中的许多设备。可以把协议 OpenFlow 看成是在 SDN体系结构中控制层面和数据层面之间的通信接口,它使得控制层面的控制器可以对数据层面中的物理设备或虚拟设备,进行直接访问和纵。这种控制在逻辑上是集中式的,是基于流的控制。
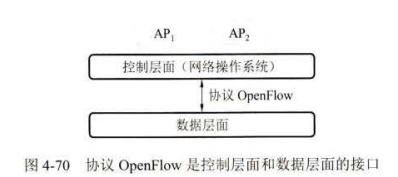
传统意义上的数据层面的任务就是根据转发表来转发分组。。实际上这里有两个步骤。第一个步骤是"匹配",即查找转发表中的网络前缀,进行最长前缀匹配。第二个步骤是“动作“,即把分组从指明的接口转发出去。
SDN 的广义转发中,"匹配“能够对不同层次(链路层、网络层、运输层)的首部中的字段进行匹配,而“动作”则不仅是转发分组,而且可以把具有同样目的地址的分组从不同的接口转发出去(为了负载均衡)。还可以重写 IP 首部(如同在 NAT 路由器中的地址转换),或者可以人为地阻挡或丢弃一些分组。
在 SDN 中,取代传统转发表的是“流表”(flow able) 。因此,流表就是"匹配+动作”的转发表。
强调了一个重要概念: OpenFlow 交换机中的流表是由远程控制器来管理的,而远程控制器通过一个安全信道,使用 OpenFlow 协议来管理 n交换机中的流表。
另一方面, OpenFlow 又是网络交换功能的逻辑结构的规约。我们还应注意到,尽管网络设备可以由不同厂商来生产,同时也可以使用在不同类型的网络中,但从 SDN 远程控制器器到的,则是统一的逻辑交换功能。
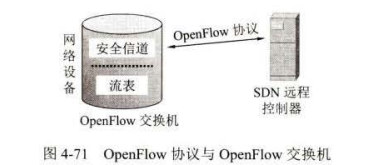
其实从 OpenFlow 交换机的角度来看,一个流就是穿过网络的一种分组序列,而在此序列中的分组都共享分组首部某些字段的值。

首部字段值:这是一组字段,用来使入分组(incom packet)的对应首部与之相匹配,因此又称为匹配字段。匹配不上的分组就被丢弃,或发送到远程控制器做更多的处理。所示的匹配字段有 11 个项目涉及三个层次的首部。
计数器:这是一组计数器,可包括已经与该表项匹配的分组数量,以及从该表项上次更新到现在经历的时间。
动作:这是一组动作,例如,当分组匹配某个流表项时把分组转发到指明的端口,或丢弃该分组,或把分组进行复制后再从多个端口转发出去,或重写分组的首部字段(第二、三和四层的首部字段)。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Vue原理解析】之插件系统
- 1. 两数之和(Java)
- 【Arduino】无法上传程序到开发板,报错 avrdude: ser_open(): can‘t set com-state for “\\.\COM6“
- Orchestrator源码解读4-计划内切换
- Linux 输入输出重定向 2>/dev/null和>/dev/null 2>&1和2>&1>/dev/nul
- AI训练师常用的ChatGPT通用提示词模板
- 免 费 搭 建 小程序商城,打造多商家入驻的b2b2c、o2o、直播带货商城
- MACD技术指标交易策略:
- Linux命令-ack命令(比grep好用的文本搜索工具)
- 提高支撑座效率的重要性