CQ 社区版 2.8.0 | 支持TiDB、StarRocks,新增列过滤算法、导出模式设置等
Hello,CloudQuery 社区版 2.8.0 已发布,本文将带大家详细解析本次更新的功能~(完整的讲解视频可点击 👉🏻 CloudQuery 社区版2.8.0 功能讲解演示
本期亮点更新
- 新增支持数据源 TiDB、StarRocks
- 数据保护新增列过滤脱敏
- 手动授权优化,针对不同层级的差异化权限控制进行提示优化
- 数据变更可自定义流程设计
- 宽松拦截模式可控制到连接级
- ……
一起来看看具体的更新内容吧!
新增数据源 TiDB、StarRocks
本次 2.8.0 更新,我们新增了 ++TiDB、StarRcoks++ 两个数据源的支持,对这些数据源支持权限管控、数据保护、审计分析等。目前支持的 TiDB 版本为 7.x,支持的 StarRocks 版本为 2.5.12。
同时,本次更新再次对OceanBaese、Hive、impala、MariaDB、MongoDB、Phoenix、Redis、Trino、Vertica 等数据源新增了 ++20+++ 个版本的适配。
目前,CloudQuery 的数据源支持情况可查看:🔗 CloudQuery支持的数据库列表
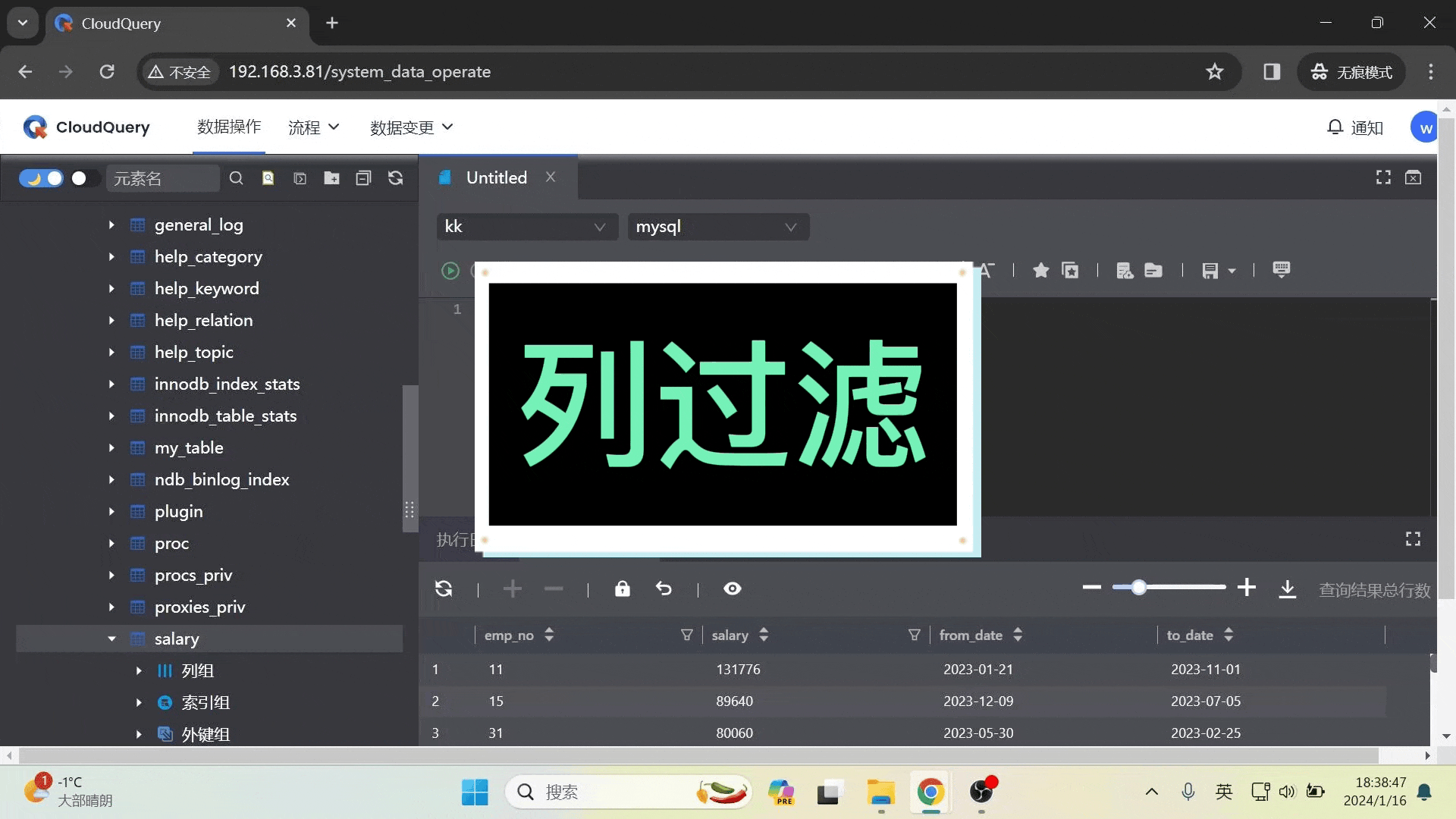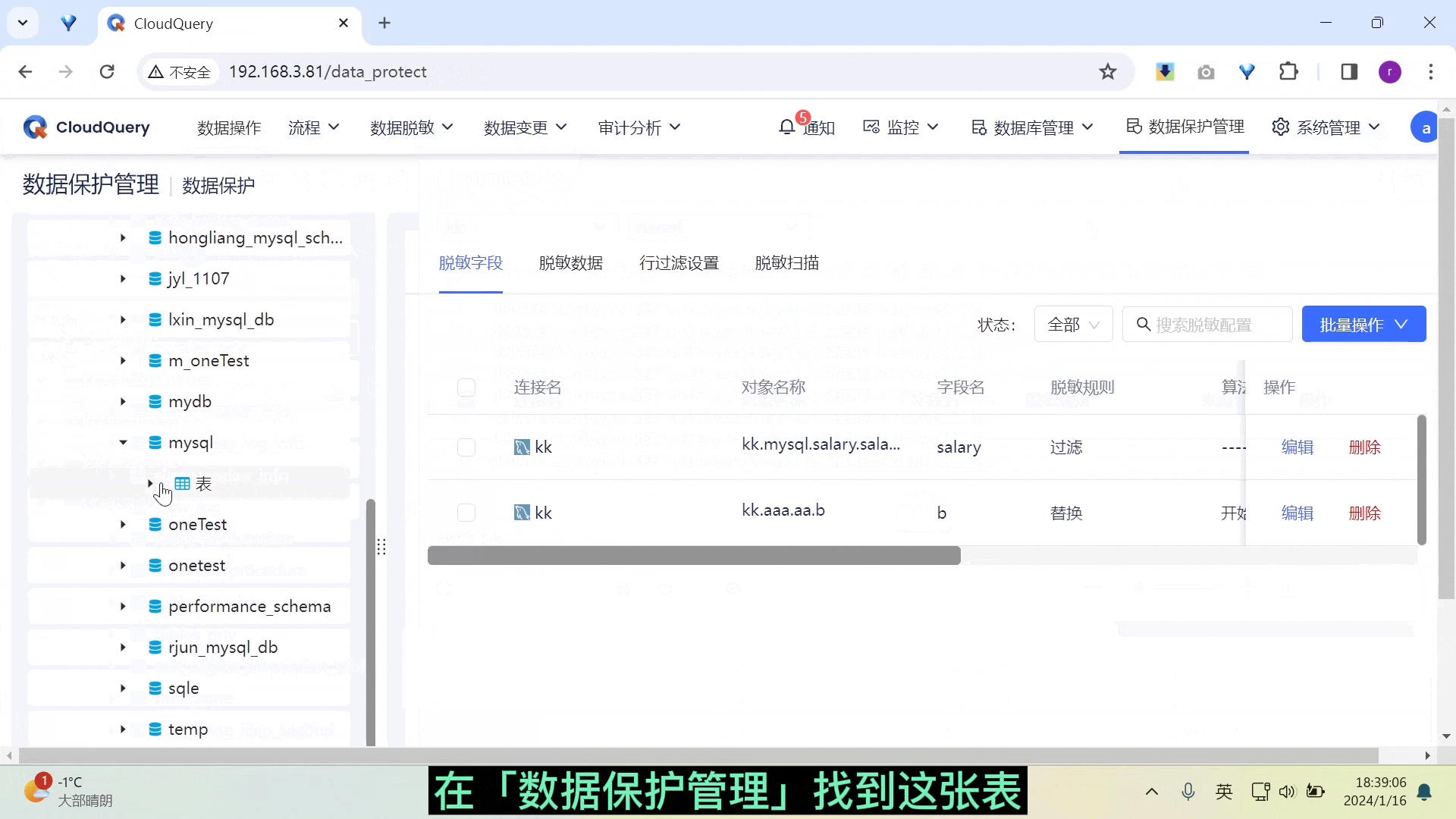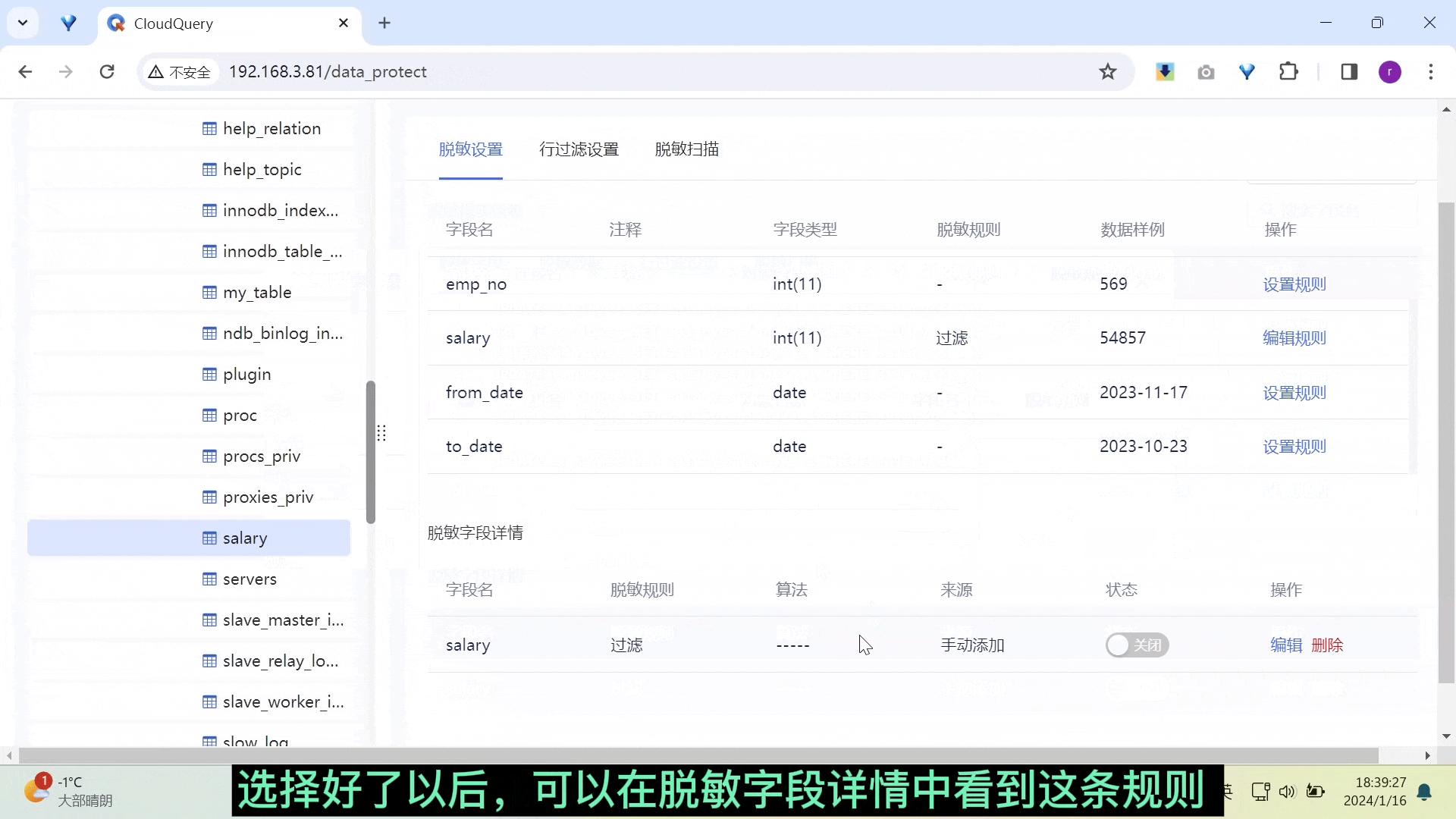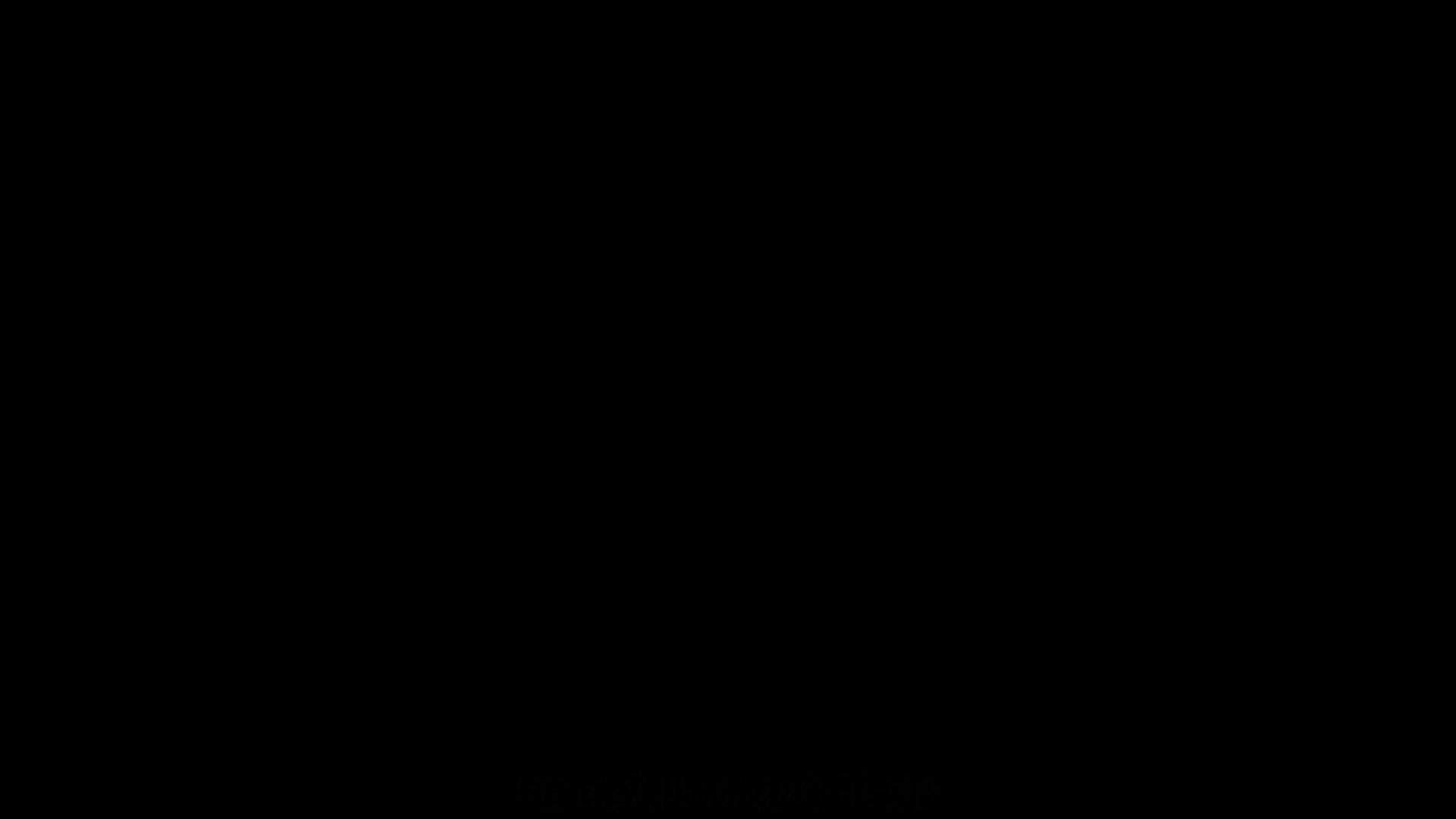
新增列过滤脱敏算法
在数据保护模块,本次更新针对字段脱敏算法增加了「列过滤算法」,用户完成列过滤算法设置后,在查询数据时可以过滤掉特定的列,从而实现对敏感信息更加灵活和精确的保护。
安全设置新增导出设置
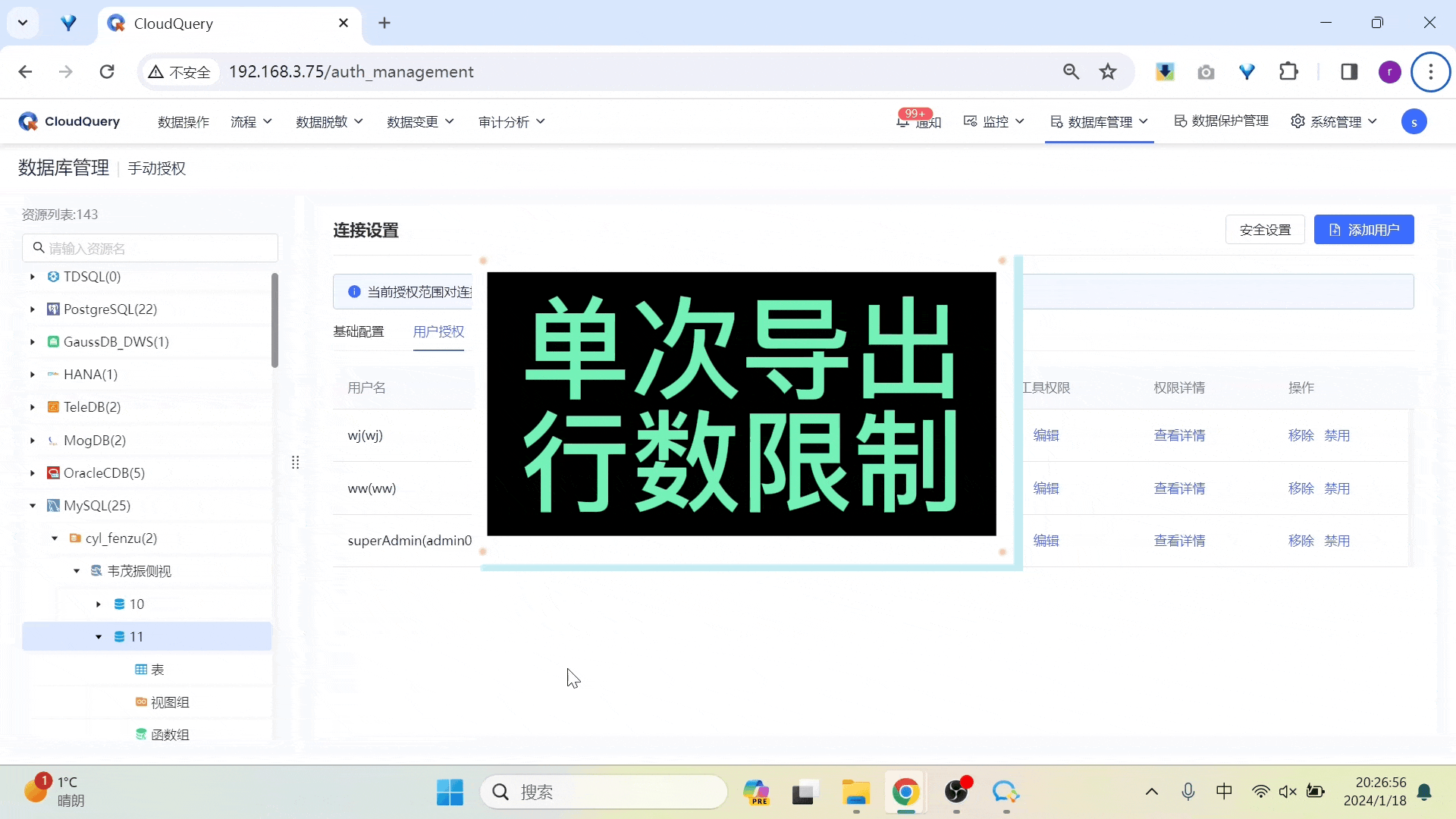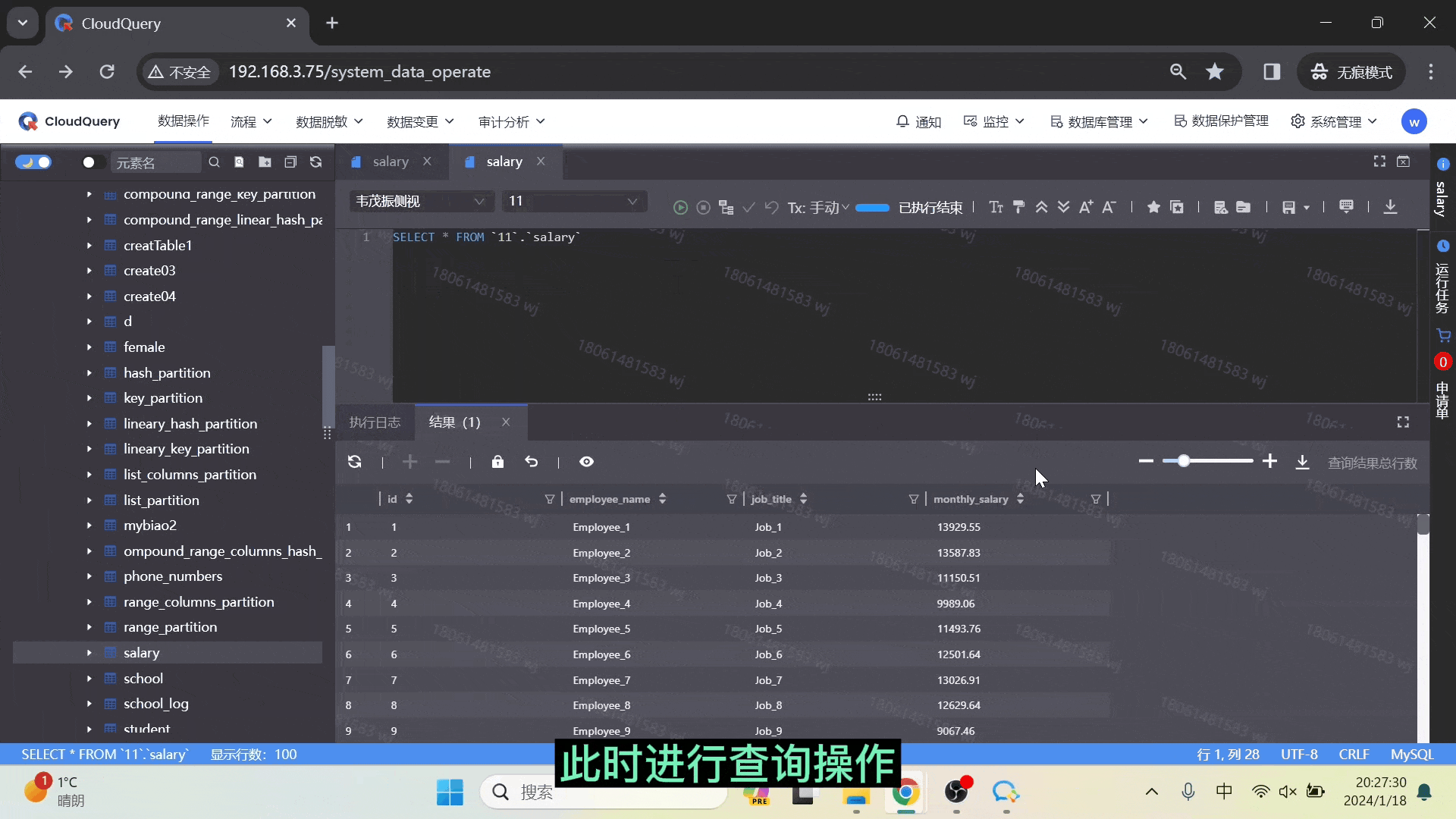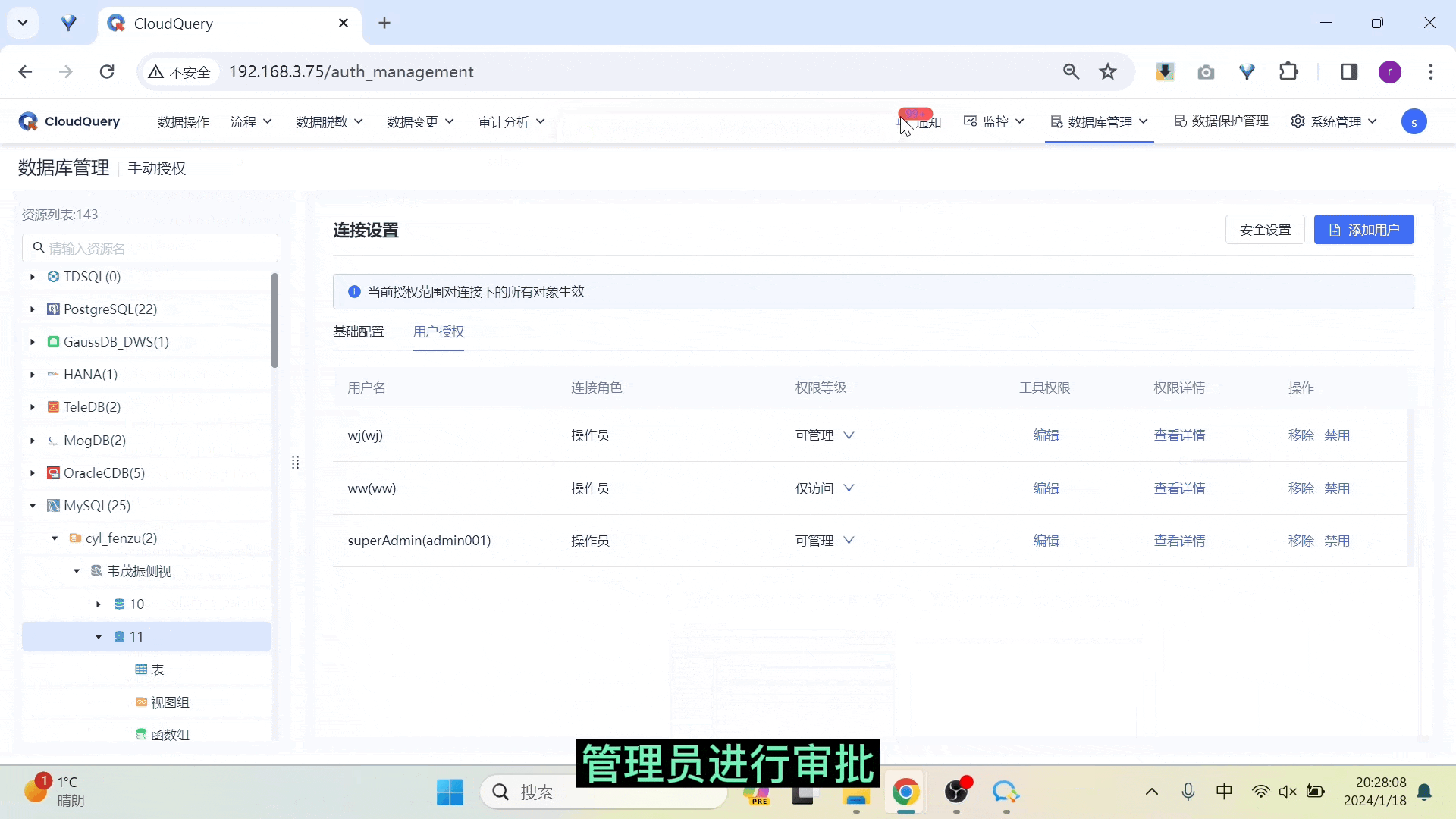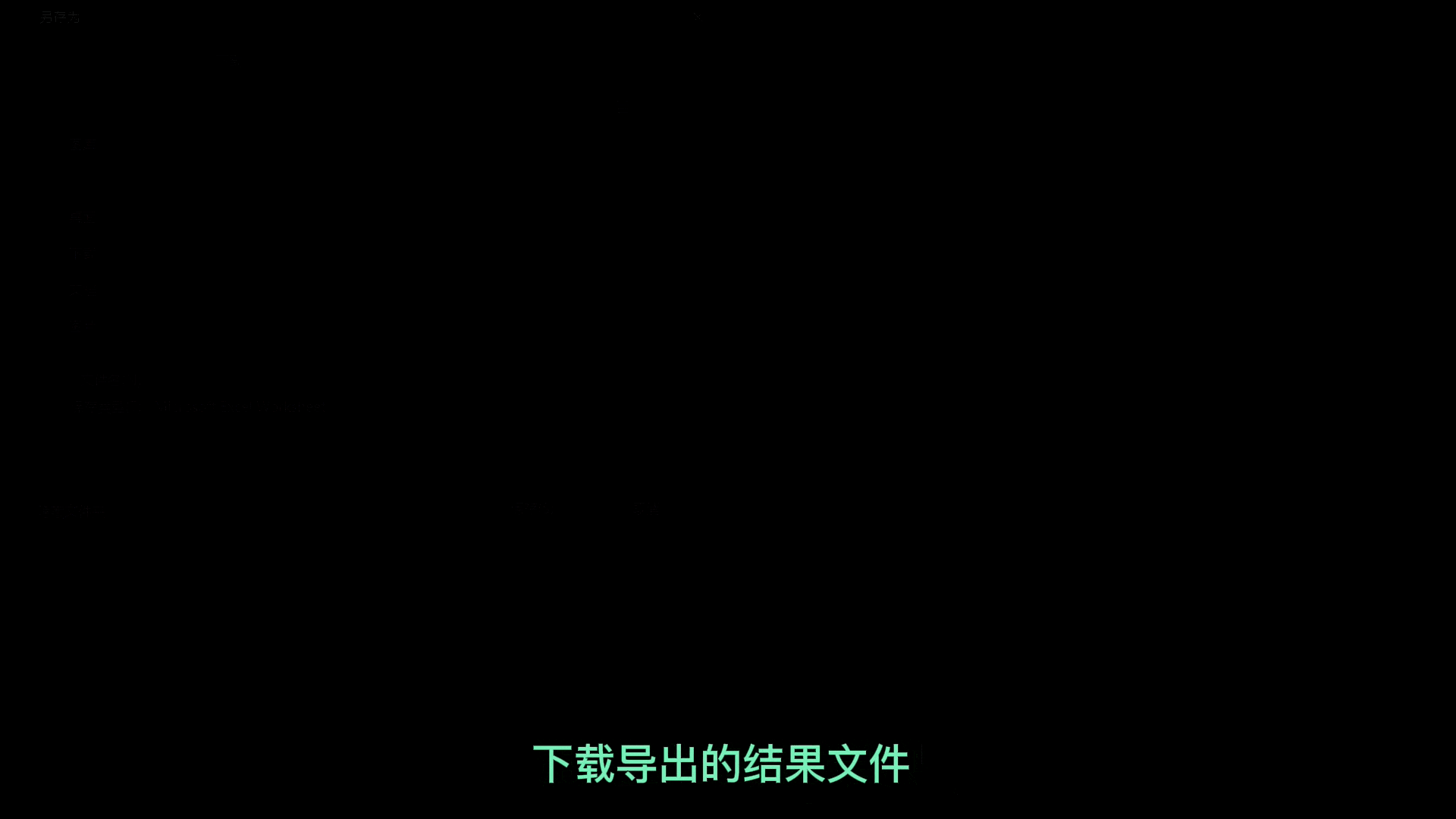
从企业数据安全角度出发,「数据导出」易存在数据泄露风险和漏洞,譬如:很多产品都有“单次导出行数限制”的功能,但用户只要在每次导出时保证行数小于设定值,进行多次导出可绕过规则。
基于此,CloudQuery 针对导出设置,新增了两种导出模式:单次导出行数限制(超过行数阈值就会强制走审批)、每次导出走审批。
● 单次导出行数限制
单次导出行数不超过设定的阈值,若超过设定的阈值,则用户无法直接创建导出任务,进入申请页面,申请通过后导出任务才创建成功。
● 每次导出走审批
用户进行导出操作时,每次都需要走申请,申请通过后才可进行导出。
以「单次导出行数限制」操作为例,可参考下方视频操作示例 👇🏻👇🏻
适用场景:
● 针对敏感数据安全考虑,可通过「单次导出行数限制」设置导出行数阈值,如导出数量超过1000条需要单次走审批,有效控制导出数据量,规避小数据量多次导出的漏洞,避免信息泄露。
● 对导出次数敏感的用户,通过设置「每次导出走审批」,实现导出与工单流程的交互,有效控制导出次数。
手动授权优化不同层级权限提示、回显
在手动授权模块,本次更新我们对不同层级之间的权限设置,进行了回显和提示优化。
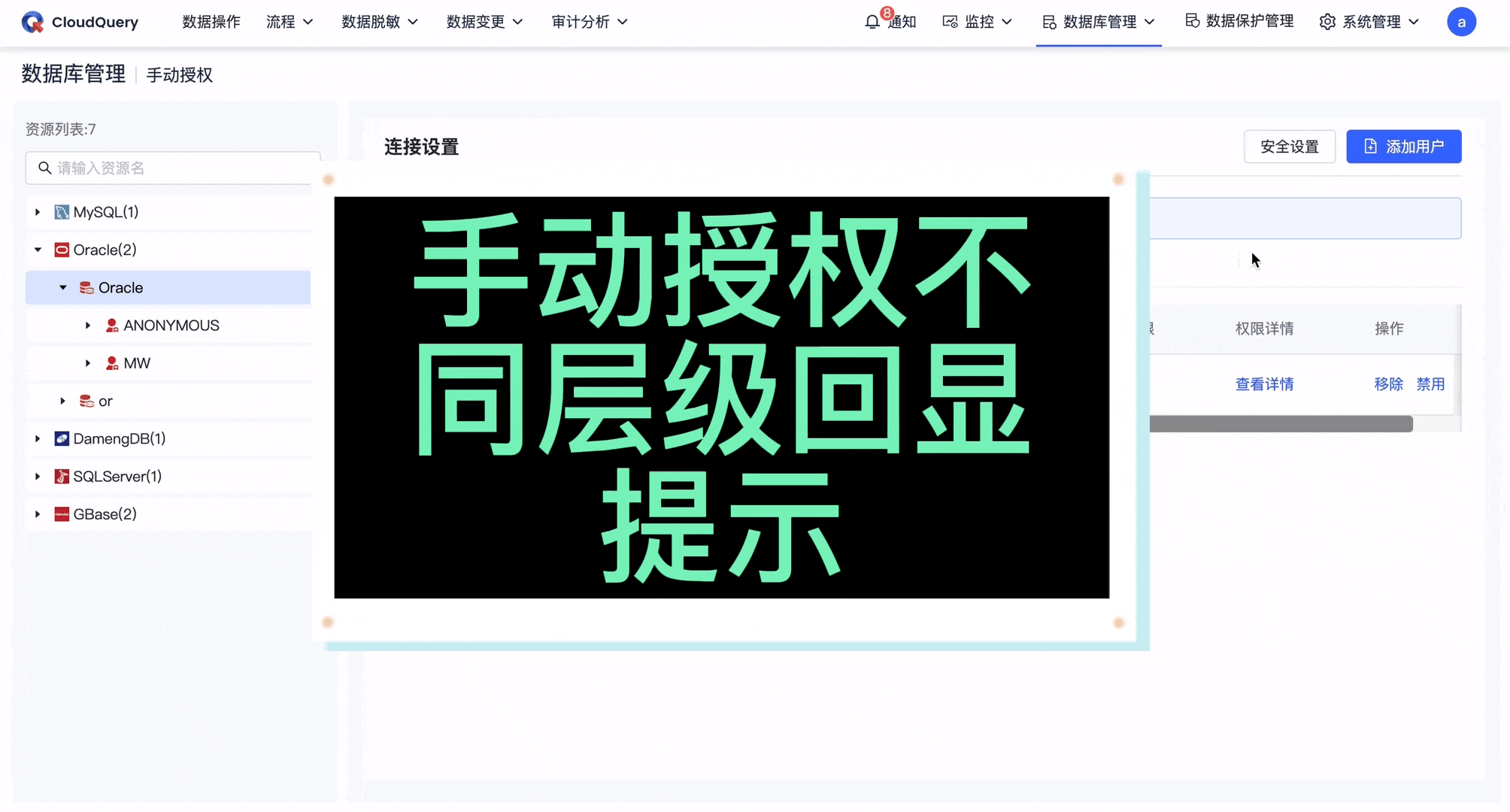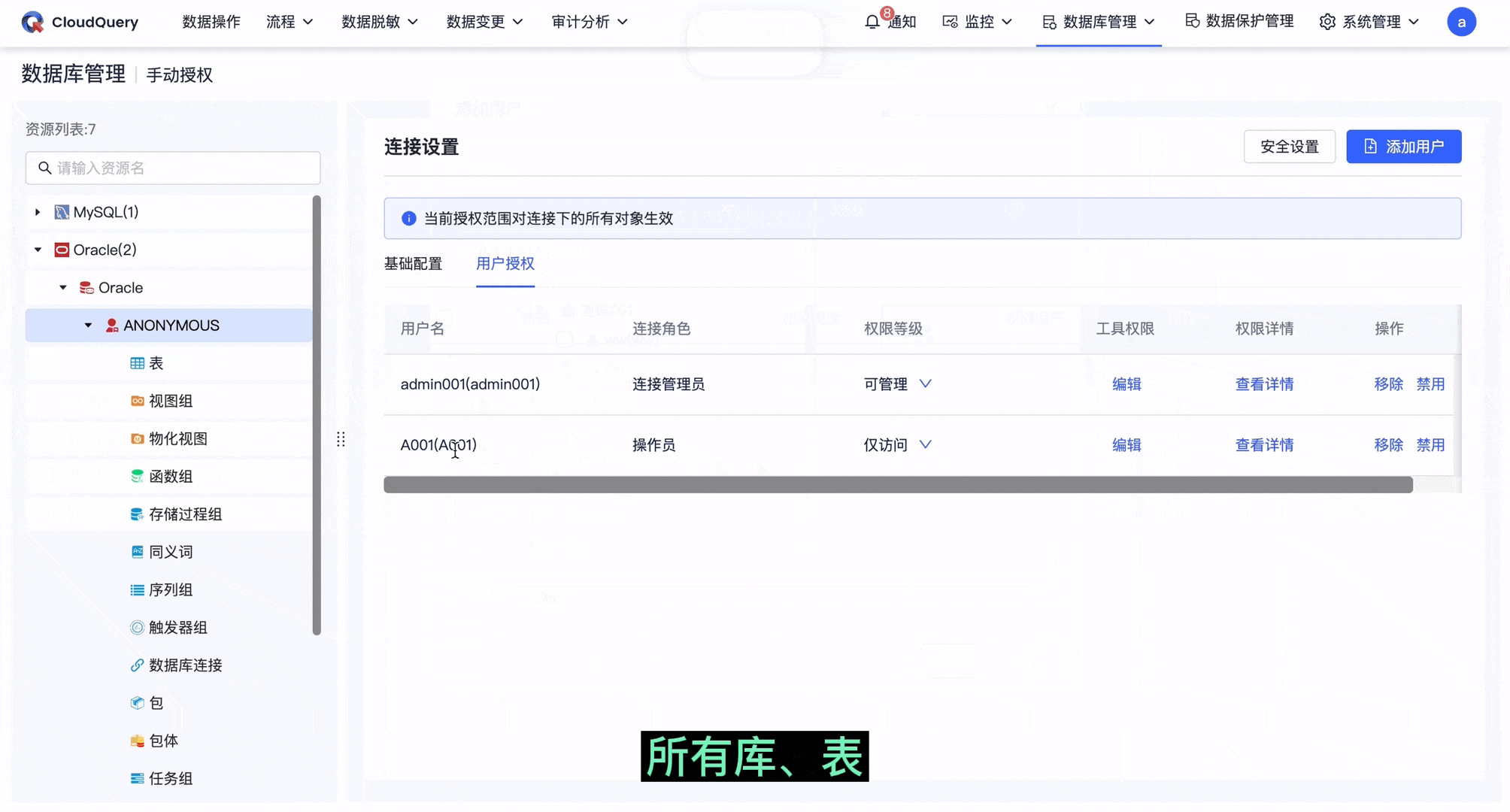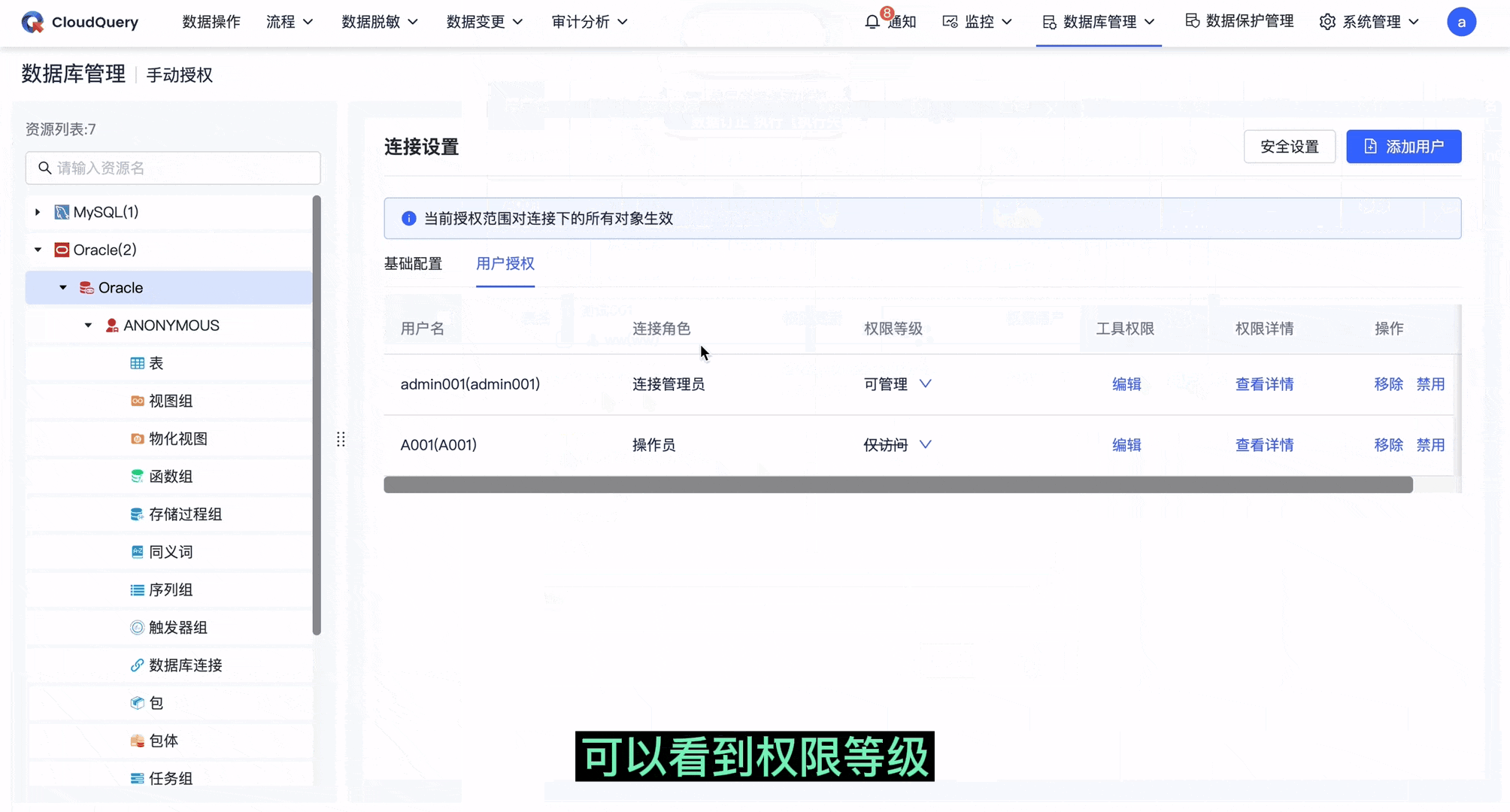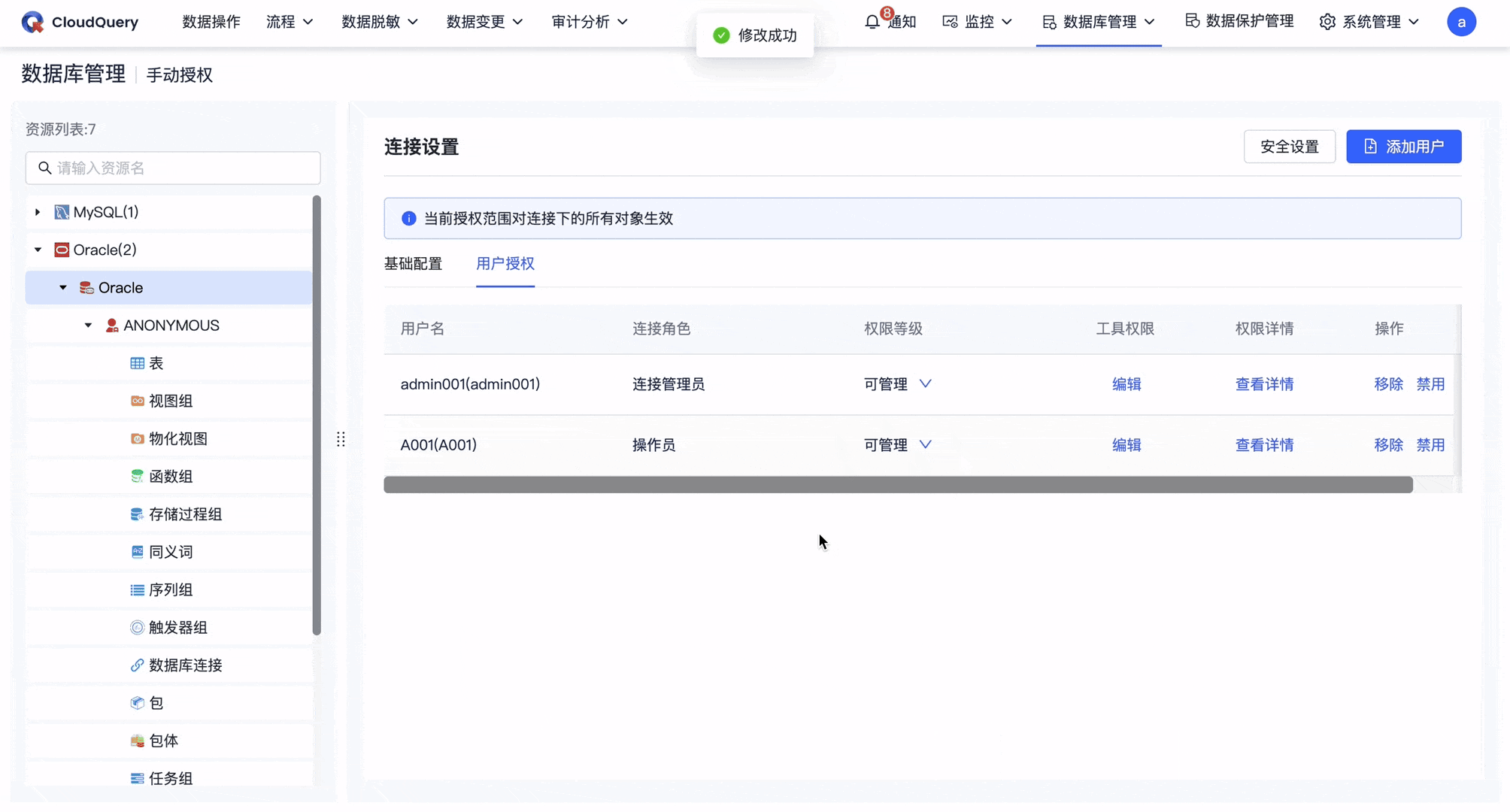
● 粗粒度权限可回显至表层级
当我们在 schema 层级进行粗粒度授权操作时可以认为是对当前层级下所有数据库对象进行批量操作,因此在下层级会回显上一层级的设置。
● 细粒度授权回显至上一层级
当我们在表中对某一用户进行权限调整后,则在上一层级中,该用户的权限等级会给出相应提示。
示例
在 schema 层级赋予 A 用户「仅访问」的权限等级,则此 schema 下所有库、表、视图等数据库对象会自动展示 A 用户的 SELECT 权限,无需再次手动添加 A 用户。
此时在具体表中增加A用户的新增、删除权限,再回到粗粒度授权页面,可以看到该用户的「权限等级」字段上出现删除线,同时出现提示此用户在此层级下存在其它权限设置。如果此时在该层级对 A 用户更改权限等级,会再次给出更改确认提示。
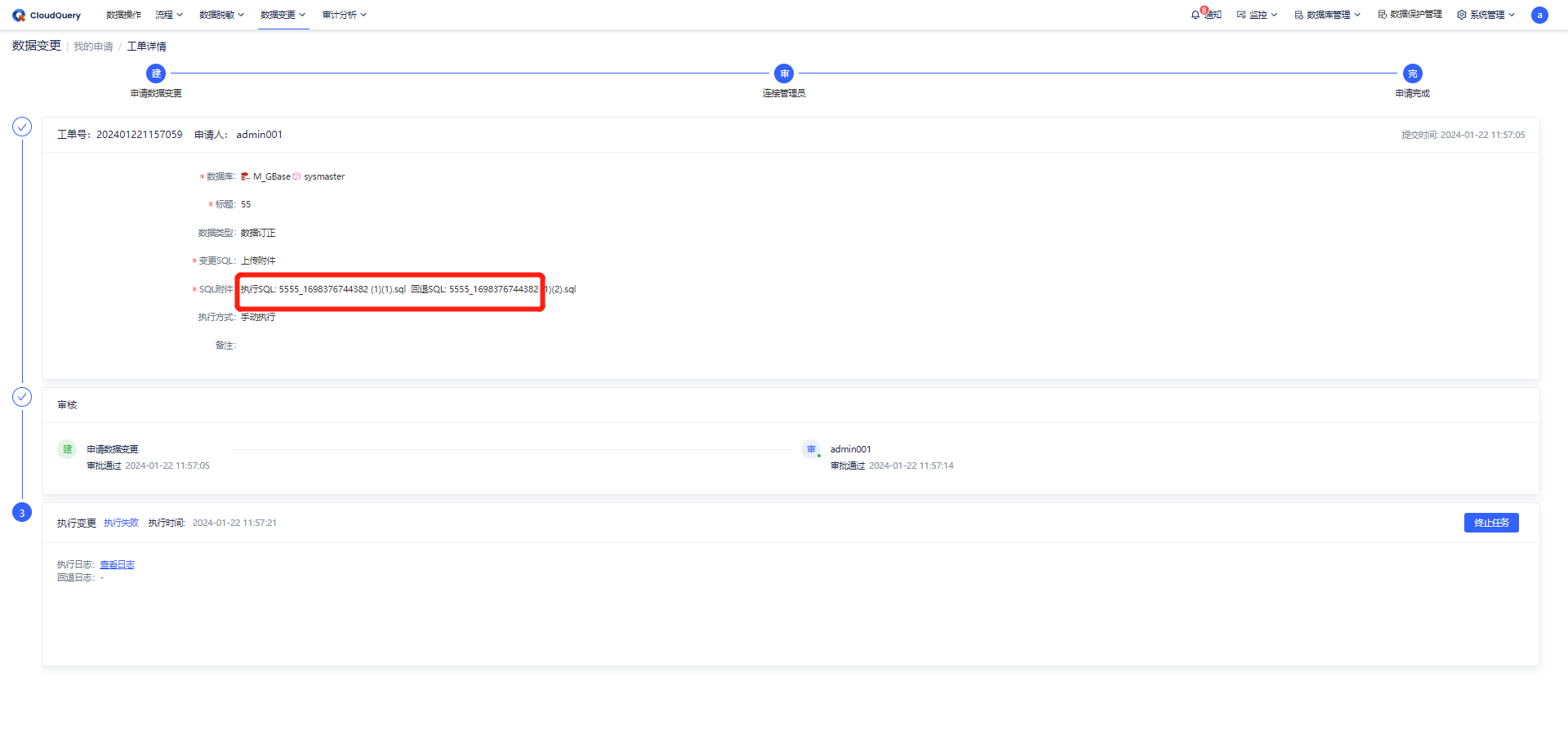
数据变更新增自定义流程设计
在数据变更模块,2.8.0 新增了「自定义流程设计」。
用户可以根据实际使用的场景,来进行数据变更审批流程的设计,增加任意节点作为审批链上的一环。
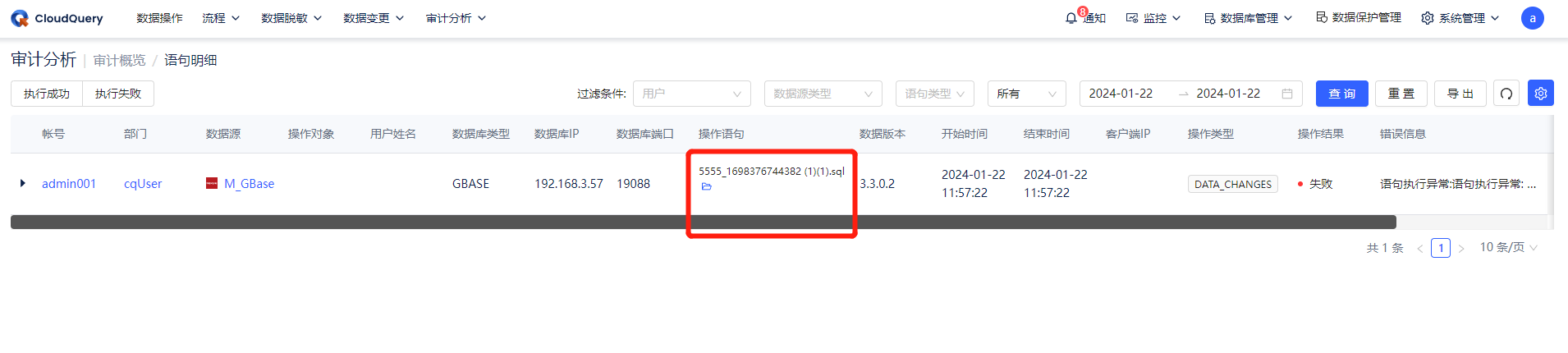
宽松拦截模式可控制到连接级
在宽松模式设置上,2.8.0可以控制到链接级别的数据库。
通过「系统管理」-「系统设置」 -「解析配置」,在「宽松拦截模式」中选择需要配置的数据库类型 ,选择后即表示对该数据库类型进行了全局的宽松拦截模式配置。
打开「宽松拦截模式」后,还能在「数据库管理」针对具体某一个数据库选择是否开启「宽松拦截模式」。
本期更新
新增功能
- 新增支持数据源TiDB(7.x)、StarRocks(2.5.12)
- 已支持数据源新增 20+ 版本适配
- 安全设置中新增导出设置,支持三种导出模式设置:权限控制(已有)、单次导出行数限制(超过行数阈值就会强制走审批)、每次导出走审批
- 数据保护新增列过滤脱敏算法
- 数据变更新增自定义流程设计
- 宽松拦截模式可控制到连接级
优化
- 高危操作设置优化,update、delete、insert 操作允许设置行数阈值
- 编辑器快捷键提示优化,增加「快速查找替换」 ——Ctrl+F、 「多行编辑」 —— Alt+鼠标左键上/下拖动提示
- 手动授权对不同层级之间的权限设置,进行了回显和提示优化
- 数据备份位置优化,用户可以自由选择数据备份的位置
- 数据变更执行的 SQL 计入审计
- 资源管理批量操作优化,可手动选择任意多个资源去做批量的启用或禁用
- SDT 树节点展开速度优化
Bugfix
- 解决密码设置「报错提示」引导不清晰的问题
- 解决了 2.7.0 新增用户时提示“服务器内部异常”的问题
新版本下载
下载地址:https://www.cloudquery.club/download
帮助文档:https://bintools.yuque.com/org-wiki-bintools-xniowl/do4ums
问题反馈
可通过 CloudQuery 官网工单系统进行问题反馈。
工单入口:https://www.cloudquery.club/login
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python通过Keep-Alive保持IP不变,向多个页面发出请求,通过多线程实现并发控制
- TS 36.213 V12.0.0-PUSCH相关过程(7)-调制阶数,冗余版本和TB size确定
- AIGC带给开发者的冲击
- 关于差分晶振的LVDS、LVPECL、HCSL、CML模式介绍及其相互转换
- 什么是有机搜索引擎优化以及如何入门
- 第32集《佛法修学概要》
- trunk与access配置,在新华三与华为中的区别
- 小米汽车的占用网络是什么
- 压缩技术(续集)(洛谷)
- 服务器执行rm命令时自动记录到审计日志中