Python 网络爬虫入门详解
发布时间:2024年01月14日
什么是网络爬虫
网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。
优先申明:我们使用的python编译环境为PyCharm
一、首先一个网络爬虫的组成结构:
爬虫调度程序(程序的入口,用于启动整个程序)
url管理器(用于管理未爬取得url及已经爬取过的url)
网页下载器(用于下载网页内容用于分析)
网页解析器(用于解析下载的网页,获取新的url和所需内容)
网页输出器(用于把获取到的内容以文件的形式输出)
二、编写网络爬虫
(1)准备所需库
我们需要准备一款名为BeautifulSoup(网页解析)的开源库,用于对下载的网页进行解析,我们是用的是PyCharm编译环境所以可以直接下载该开源库。
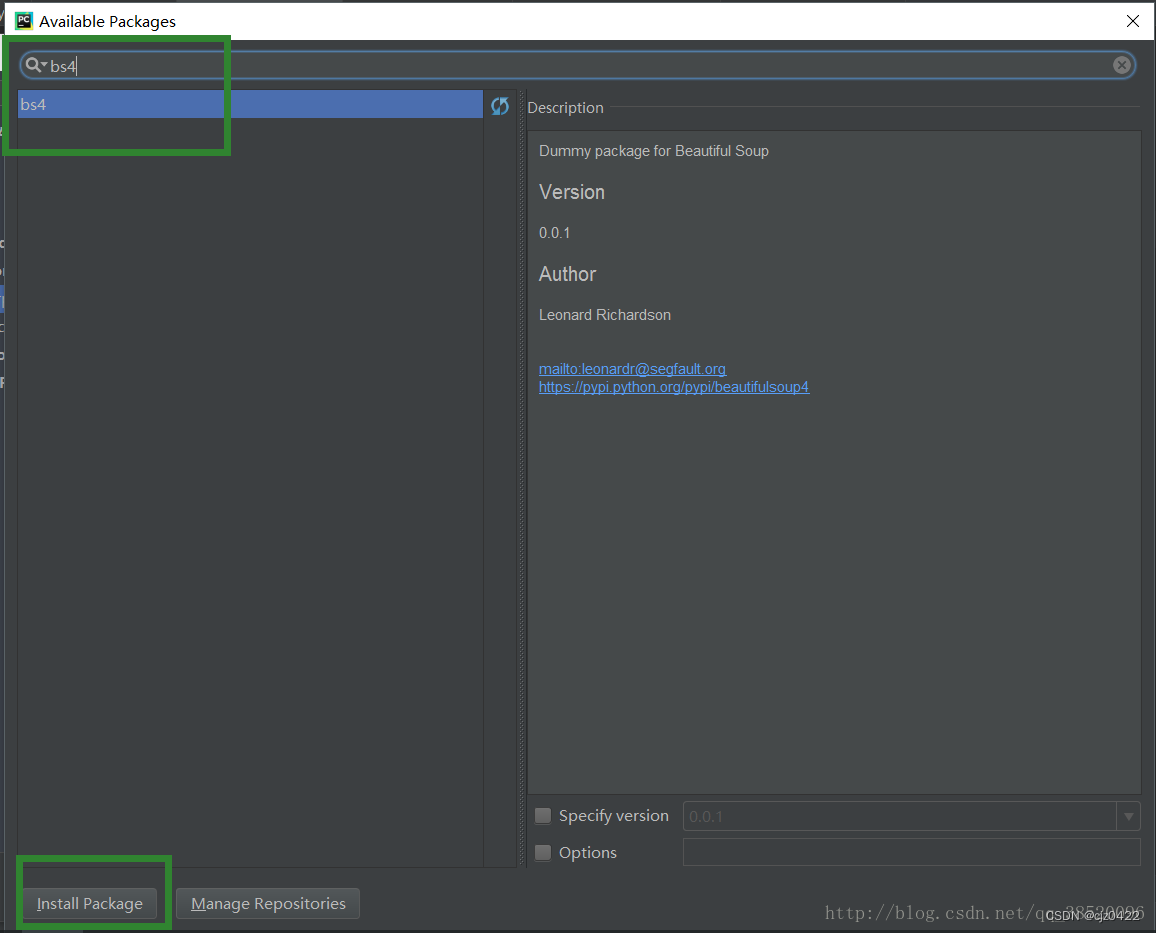
步骤如下:
选择File->Settings

打开Project:PythonProject下的Project interpreter

点击加号添加新的库

输入bs4选择bs4点击Install Packge进行下载
(2)编写爬虫调度程序
这里的bike_spider是
文章来源:https://blog.csdn.net/cjz0422/article/details/135579703
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- OpenCV-Python的版本介绍及区别
- Java(TM) Platform SE binary (Process Id: 4412)
- 2024年四川省两化融合贯标申报条件流程和各地区奖励补贴
- Python装饰器案例
- LeetCode 50. Pow(x, n)
- 数据预处理:标准化和归一化
- K8S如何扩展副本集
- 补题与周总结:leetcode第 376 场周赛
- uniapp 使用wx.getFuzzyLocation获取当前的模糊地理位置
- Jetpack Compose -> 分包 & 自定义Composable