PyTorch官网demo解读——第一个神经网络(3)
上一篇:PyTorch官网demo解读——第一个神经网络(2)-CSDN博客
上一篇文章我们讲解了第一个神经网络的模型,这一篇我们来聊聊梯度下降。
大佬说梯度下降是深度学习的灵魂;梯度是损失函数(代价函数)的导数,而下降的目的是让我们的损失不断减少,达到模型收敛的效果,最终拟合出最优的参数w。
所以,我们要先从损失函数(代价函数)说起。
-
损失函数
从上一篇我们知道这个神经网络的模型是:y = wx + b
对于单一个样本(x, y),它的损失值就是:loss = wx + b - y
为了简单好理解,我们先把b去掉,那么 loss = wx - y,这个误差值可能是负数,而我们衡量一个误差值使用负数好像有点奇怪,于是我们使用均方差,那么单个样本的损失就变成这样:
loss = (wx - y) ^2
假定我们有n个样本【(x1, y1), (x2, y2) …… (xn, yn)】,那么我们的损失函数就是:

这个损失函数实际上是一个开口向上的抛物线,我随机取了5个样本值,手搓了一下,画出来如下图:

-
梯度下降
梯度实际上就是损失函数的导数,即抛物线上某个点的变化率
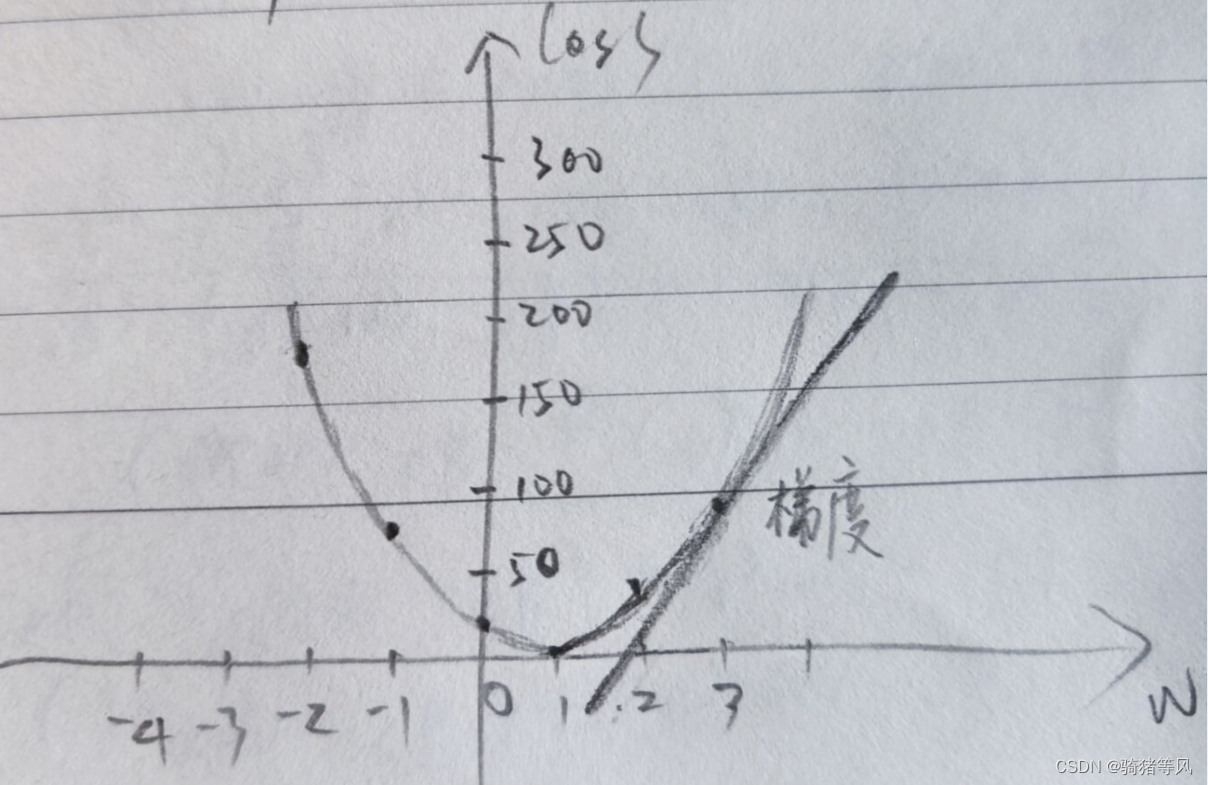
所以梯度函数是:
t = 2aw + b
下降就是每次迭代,将当前的权重减去 梯度值乘以学习率,即:
w = w - t * lr
其中 lr 表示学习率,学习率可以理解为我们每次迈的步伐大小,如果迈的步伐太大,会导致在逼近最优参数时难以收敛,步伐太大跨过去了,在最优参数左右摇摆。所以通常学习率会设置比较小的值。
-
代码
上面我们万般无奈地使用了一堆数学公式...,但有时候数学是最好的抽象方式,就像程序员喜欢说 read the f**king source code 一样。语言是对事物的抽象,而数学是对语言的进一步抽象吧,语言无法表达某些自然的规律,所以需要通过数学来表达,哈哈!
好啦,回顾第一篇的demo代码,关于损失函数,pytorch demo的代码极为精简:
# 丢失函数 loss function
def nll(input, target):
return -input[range(target.shape[0]), target].mean()
loss_func = nll而梯度下降就更为精简了,梯度是自动推导的,只需设置一个标志:
weights.requires_grad_()没错,只需上面这行代码,在每次训练迭代后调用?loss.backward(),梯度就被计算出来啦,而我们只需在每次迭代中减去梯度值就好,如下:
pred = model(xb) # 通过模型预测
loss = loss_func(pred, yb) # 通过与实际结果比对,计算丢失值
loss.backward() # 反向传播
with torch.no_grad():
weights -= weights.grad * lr # 调整权重值
bias -= bias.grad * lr # 调整偏差值
weights.grad.zero_()
bias.grad.zero_()weights.grad.zero_()的作用是将每次迭代的梯度清零,不然下次计算梯度的时候会进行叠加。
关于梯度下降,就聊到这里吧!有问题可以留言探讨,共同学习!
未有知而不行者,知而不行,只是未知!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 重构第十二章:大型重构 and结语
- 图文证明 等价无穷小替换
- js(JavaScript)数据结构之栈(Stack)
- 基于学生心理学优化算法求解单目标优化问题(含Matlab源码)
- 117基于matlab的短时傅里叶变换(STFT)、小波变换(WT)、同步压缩变换(SST)、瞬态提取变换(TET)进行时频分析
- 说说TCP 3次握?和4次握手
- 软件测试/测试开发丨Web自动化测试策略
- Docker可视化界面【Portainer】安装
- 腾讯云2024年最新优惠活动整理汇总
- transbigdata笔记:清理研究区域内的轨迹漂移