激发大规模ClickHouse数据加载(3/3)确保加载大规模数据的可靠性

本文字数:7016;估计阅读时间:18?分钟
作者:Tom Schreiber
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

本文是“激发大规模ClickHouse数据加载”系列文章的最后一篇:
简介
在将应用迁移到ClickHouse时,经常需要加载大量初始化数据,尤其是从一个其他系统迁移过来。从零开始加载数十亿或数万亿行数据可能会具有很大的挑战,因为这类数据加载需要一定的时间。加载时间越长,网络中断,导致数据加载中断的可能性就越高。我们将展示如何解决这些挑战,避免数据加载的中断。
在我们的有关如何加速大规模ClickHouse数据加载的系列博客的第三部分中,我们将为您提供有关可靠性且高效大规模数据加载的最佳实践。
为此,我们将简要介绍一种新的托管解决方案,用于将大批量数据从外部系统加载到ClickHouse中,并具有内置的弹性。然后,我们将深入研究源自我们出色的支持团队的脚本,该团队帮助一些客户成功的迁移多达数万亿行的数据集。如果您的外部数据源尚未受到我们内置托管解决方案的支持,在此期间您可以使用此脚本,阶段性、可靠地在较长的时间内加载大型数据集。
弹性数据加载
从外部系统将数十亿甚至数万亿行的数据,首次加载到ClickHouse的表中需要一定的时间。例如,假设基本的传输吞吐量为每秒1000万行,那么每小时可以加载360亿行,每天可以加载8640亿行。加载数万亿行需要很多天的时间。
所谓夜长梦多,短暂的错误是难免的?- 例如,可能会发生网络连接的闪断问题,导致数据加载中断并失败。如果没有使用具有:内置弹性且可以自动的重试的有状态数据传输编排的托管解决方案,用户通常会选择截断ClickHouse目标表,并重新从头开始加载整个数据。这进一步增加了加载数据所需的总时间,最重要的是,可能会再次失败。或者,您可以尝试识别:已成功写入到ClickHouse目标表中的哪些数据,然后尝试仅加载缺失的子集。如果您的数据中没有唯一的序号,这可能会很棘手,需要手动干预和额外处理的时间。
ClickPipes
ClickPipes是ClickHouse Cloud中提供的完全托管的集成解决方案,支持从外部系统进行连续、快速、弹性和可伸缩的数据摄取:
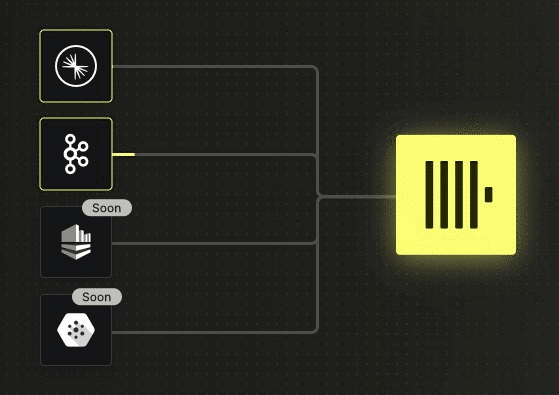
ClickPipes是在今年9月刚刚发布的,当前支持Apache Kafka的多种版本:OSS Apache Kafka、Confluent Cloud和AWS MSK。其他事件管道和对象存储(S3、GCS等)将很快支持,并且随着时间的推移,还将直接集成其他数据库系统。
请注意,ClickPipes将在发生故障时自动重试数据传输,目前提供至少一次语义。我们还为从Kafka加载数据并需要精确一次语义的用户提供Kafka Connect连接器。
ClickLoad
如果您的外部数据源尚未得到ClickPipes的支持,或者如果您没有使用ClickHouse Cloud,我们建议采用下图所示的方法:

① 首先将数据导出到对象存储桶中(例如Amazon AWS S3、Google GCP Cloud Storage或Microsoft Azure Blob Storage),最好将其导出为大小适中的Parquet文件,大小在50到150MB之间,但其他格式也可以。这些建议是基于以下几个原因:
-
当前大多数的数据库系统和外部数据源,都支持将大量数据高效可靠地导出到(相对便宜的)对象存储中。
-
Parquet已经成为几乎无处不在的文件交换格式,具有高效的存储和检索功能。
ClickHouse内置极快的Parquet支持。
-
ClickHouse服务器可以将高度的并行性处理,用于插入来自存储在对象存储中的文件的数据,充分利用到所有可用的CPU核心。
② 然后,您可以使用我们的ClickLoad脚本,下面将对其进行更详细的描述,该脚本通过利用我们的对象存储集成表功能之一(例如s3、GCS或AzureBlobStorage)对数据进行可靠而具有弹性的传输到ClickHouse目标表中。
我们在此提供了使用ClickLoad的逐步示例(https://github.com/ClickHouse/examples/blob/main/large_data_loads/examples/pypi/README.md#example-for-resiliently-loading-a-large-data-set)。
核心方法
ClickLoad的基本思想起源于我们的支持团队,他们指导了ClickHouse Cloud的一些客户成功的迁移了数万亿行的数据。
按照传统的分而治之的方式,ClickLoad将要加载的整个数据分为文件,形成可重复且可重试的任务。这些任务用于将所有数据从对象存储中逐步的加载到ClickHouse表中,并在发生故障时自动重试。
为了方便的实现扩展,我们采用了另一篇博客中介绍的队列-工作程序方法。无状态的ClickLoad工作程序可靠地通过KeeperMap表引擎支持的任务表中索取文件加载任务,然后协调数据加载。每个任务可能包含多个要处理的文件,KeeperMap表确保每个任务(因此是文件)只能分配给一个工作程序。这样我们就可以通过启动额外的工作程序,增加总体摄取吞吐量,并行化文件加载过程。
作为前提条件,任务表使用ClickLoad工作程序填充了文件加载任务:
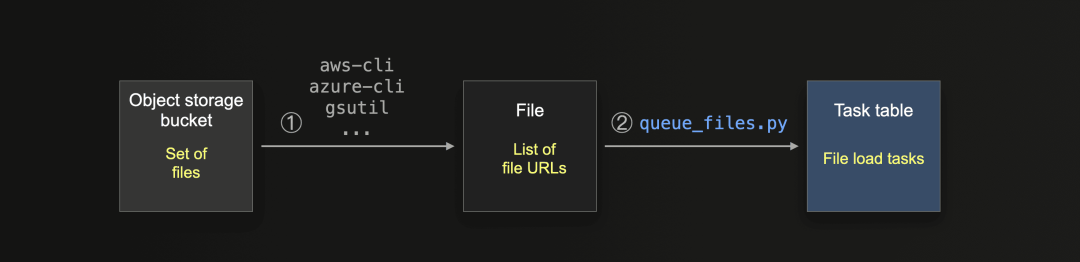
① 用户可以利用相应的对象存储命令行接口工具(例如Amazon aws-cli、Microsoft azure-cli或Google gsutil)创建包含要加载的文件的对象存储URL的本地文件。
② 我们提供了说明文档和一个名为queue_files.py的单独脚本,该脚本将来自步骤①中文件的条目拆分成文件URL的块,并将这些块作为文件加载任务加载到任务表中。
下图显示了任务表中的这些文件加载任务,是怎样由ClickLoad工作程序协调数据加载:
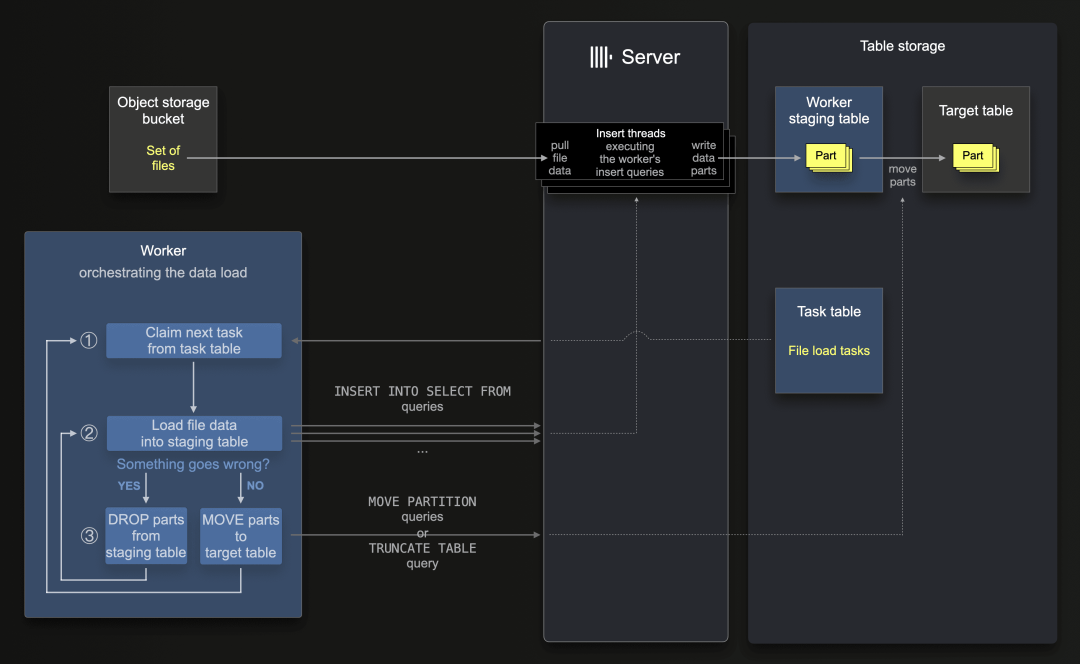
为了在发生故障时轻松的实现重试,首先,每个ClickLoad工作程序将所有文件数据加载到(每个工作程序不同的)staging table中:在①索取下一个任务后,工作程序会遍历任务的文件URL列表,然后在②(顺序地)指示ClickHouse服务器通过使用INSERT INTO SELECT FROM查询将任务中的每个文件加载到staging table中(其中ClickHouse服务器自己从对象存储中拉取文件数据)。这就实现了高度的并行性文件数据插入,并在staging table中创建数据Part。
假设当前任务正在执行的插入查询的过程中被中断,状态失败了,并且在临时表中已经导入了一些Part形式的数据。在这种情况下,工作程序首先会③指示ClickHouse服务器截断临时表(删除所有Part),然后②从头开始重试其当前文件加载任务。在成功完成任务后,工作程序③使用特定的查询和命令,导致ClickHouse服务器将所有Part(来自所有分区)从临时表移动到目标表。然后,工作程序①索取并处理任务表中的下一个任务。
在ClickHouse Cloud中,所有数据都存储在与ClickHouse服务器分开的共享对象存储中。因此,移动Part是一项轻量级操作,仅更改Part的元数据但不会物理移动Part。
请注意,每个工作程序在启动时都会创建自己的临时表,然后在无新任务可用时执行无休止的循环,间歇性的休眠。我们为SIGINT(Ctrl+C)和SIGTERM(Unix进程终止信号)信号注册了一个信号处理程序,用于在关闭工作程序时清理(删除)工作程序的临时表。
还要注意,工作程序处理的是文件的原子块,而不是单个文件,以减少在使用复制表时对Keeper的争用。后者会创建(更多)由Keeper在复制的集群中协调的MOVE PARTITION调用。此外,我们随机化文件块的大小,以防止多个并行工作程序运行时Keeper的争用。?
临时表确保加载数据的单次存储
ClickLoad工作程序使用的INSERT INTO SELECT FROM查询,可以直接将文件数据插入目标表。但是,当插入查询无论如何都失败时,为了在重试任务时并不会导致数据重复,我们需要删除先前失败任务的所有数据。与将数据插入目标表相比,将数据插入临时表后,删除数据要容易得多,因为临时表可以简单地被截断。
例如,仅在目标表中删除Part是不可能的,因为最初插入的Part将在后台自动合并( 它可能会与先前成功插入的Part一起合并)。
依赖“自动插入去重”通常也不可能,因为(1)插入线程非常不太可能重新创建完全相同的插入块,并且(2)在运行中的工作程序数量众多时,ClickHouse中表的默认去重窗口可能是不够用的。
最后,使用OPTIMIZE DEDUPLICATE语句显性的去重所有行可能会(1)随着目标表的增大,而变得非常繁重和操作的越来越缓慢,(2)可能会意外地去重源数据文件中本应该数据相同的行。
在重试插入之前,可靠地从目标表中删除插入失败的数据,唯一方法是使用ALTER TABLE DELETE、轻量级DELETE或轻量级UPDATE语句。所有这些操作,最终都会以表的增大,而变得更昂贵的重型的突变(mutation)操作来实现。
相反,通过临时表的绕道方式,使我们的工作程序能够通过高效地删除或移动Part,来确保每一行从加载的文件中都只存储在目标表中一次,具体取决于任务成功与否。
轻量的工作程序(Worker)
ClickLoad的工作脚本仅负责编排数据加载,而不实际加载任何数据。相反,ClickHouse服务器及其硬件资源被用于从对象存储中提取数据并将其写入ClickHouse表中。
请注意,需要一台单独的机器运行ClickLoad,该机器可以访问源对象存储桶和目标ClickHouse实例。由于工作程序的轻量级工作方式,一台适中的机器就可以并行的运行数百个工作程序实例。
插入吞吐量可以轻松扩展
可以利用多个工作程序和多个ClickHouse服务器(在ClickHouse Cloud中使用负载均衡器)来扩展摄取吞吐量:
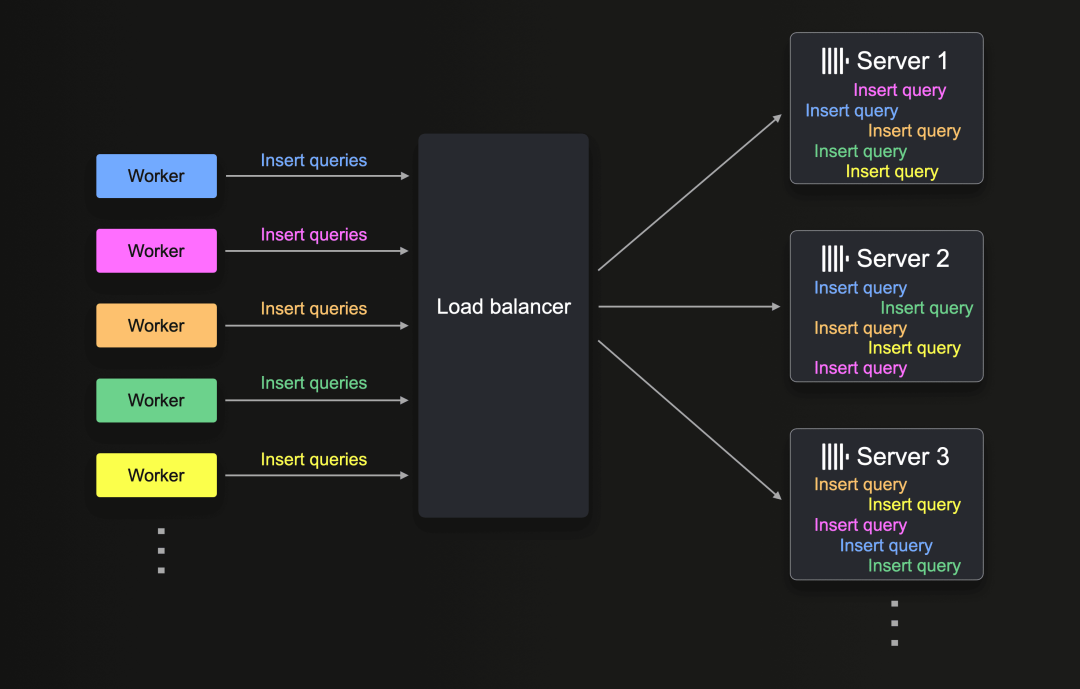
所有工作程序的INSERT INTO SELECT FROM查询都均匀分布到各个可用ClickHouse服务器,然后并行执行。请注意,每个工作程序都有自己的临时表。
将工作程序的数量翻倍就可以把摄取吞吐量提高一倍,前提是执行插入查询的ClickHouse服务器具有足够的资源。
类似地,将ClickHouse服务器的数量翻倍也可以将摄取吞吐量提高一倍。在我们的测试中,当加载6000多亿行数据集(使用100个并行工作程序)时,将ClickHouse Cloud服务中的ClickHouse服务器数量从3个增加到6个,就准确地将摄取吞吐量提高了一倍(从每秒400万行增加到每秒800万行)。
连续数据写入是可能的
如上所述,每个工作程序都执行一个无限循环,检查任务表中未处理的任务,如果没有找到新任务,则休眠。这样就可以在检测到对象存储桶中有新文件时,向任务表中添加新的文件加载任务,从而轻松实现连续数据摄取流程。运行中的工作程序将自动声明这些新调度的任务。我们在这里描述了一个具体的示例,但将此实现留给读者。
支持任何分区键
ClickLoad工作程序的文件加载机制独立于目标表的任何分区方案。工作程序不会自己创建任何分区。我们也不要求每个加载的文件都属于特定分区。相反,目标表可以具有任何(或没有)自定义分区键,我们将其复制到临时表中(它是目标表的DDL级别克隆)。
在每次文件块传输成功之后,我们只需将从当前处理的文件的数据摄取中自然创建的所有(part所属的)分区的都移到目标表中。这意味着总体上,与将所有数据直接插入目标表相比(不使用我们的ClickLoad脚本),目标表将创建完全相同数量的分区。
您可以在这里(https://github.com/ClickHouse/examples/tree/main/large_data_loads/internals#support-for-arbitrary-partitioning-keys)找到更详细的解释。
支持投影(projections?)和物化视图
可靠地将数万亿行加载到目标表是一个良好的开始。然而,通过允许表具有自动增量聚合和具有额外主索引的多行顺序的投影和物化视图,可以提高查询性能。
在初始化加载了数万亿行之后,创建投影或物化视图将需要昂贵的投影物化视图,或ClickHouse端表到表的重新加载以触发物化视图。这两者都需要很长的时间,也会有发生故障的风险。因此,在初始数据加载之前,就创建投影和物化视图是最有效的选择。ClickLoad在这方面完全(且透明地)支持。
支持投影(projections?)
我们的ClickLoad工作程序脚本所创建的临时表是目标表的完整DDL级别克隆,包括所有定义的投影。由于投影的数据Part存储在投影主表的part directiory 内的子目录中,因此在每个文件加载任务之后,它们会自动从临时表移到目标表。
支持物化视图
下图显示了ClickLoad对物化视图支持的基本逻辑:
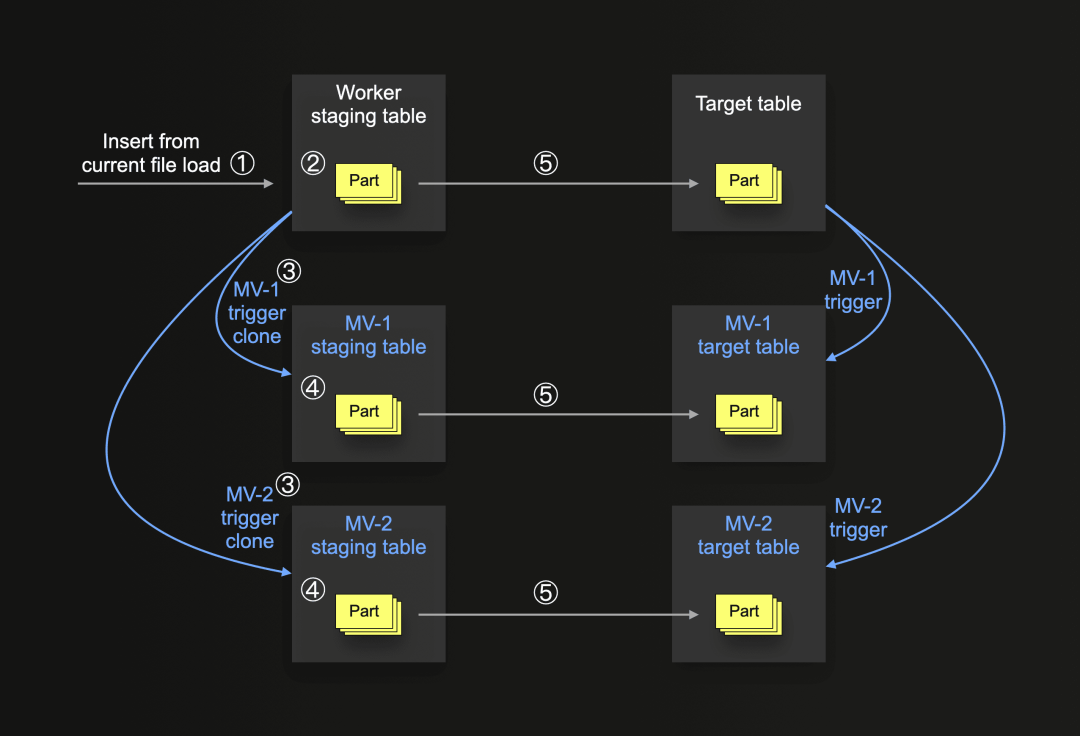
在上图中,目标表有两个连接的物化视图(MV-1和MV-2),它们将在新数据直接插入目标表并将数据(以变换形式)存储在它们自己的目标表里时触发。
我们的ClickLoad工作脚本通过自动为主目标表创建临时表,以及为所有物化视图(mv)目标表创建临时表的方式来复制此行为。与附加的临时表一起,我们自动创建物化视图触发器的克隆,但配置它们以对临时表上的插入作出反应,然后将它们定位到相应的目标临时表。
当①数据插入目标表的临时表(和②以Part形式存储)时,此插入③将自动触发mv副本,④导致插入到临时mv的目标表中。如果整个插入成功,我们将从所有临时表的所有part(分区)移动到它们的对应目标表。如果出现问题,例如,其中一个物化视图在当前数据上有问题,我们只需删除所有临时表的所有part并重试插入。如果超过最大重试次数,则跳过(并log记录)当前文件,并继续下一个文件。通过此机制,我们确保插入是原子的,并且数据在主目标表和所有连接的物化视图之间始终保持一致。
请注意,在步骤⑤中将part移到目标表中不会触发任何连接的原始物化视图。
有关失败的物化视图的详细错误信息,请参阅query_views_log系统表(https://clickhouse.com/docs/en/operations/system-tables/query_views_log)。
此外,如上所述,物化视图的目标表可以具有任何(或没有)自定义分区键。我们的编排逻辑与此无关。
我们的ClickLoad工作脚本目前仅支持使用?TO target_table?子句创建的物化视图,不支持级联的物化视图。
ClickLoad与中等文件大小最搭配
工作程序的处理单元是一个完整的文件。如果在加载文件时发生故障,我们将重新加载整个文件。因此,我们建议使用中等大小的文件,每个文件有数百万行,而不是数万亿行,压缩后大约为100到150MB。这样就可确保有效的重试机制。
欢迎提交PR
如上所述,我们ClickLoad脚本的起源于客户支持,它已经帮助了很多ClickHouse Cloud客户迁移其大量数据。因此,该脚本目前依赖于云上的特定功能,例如将MOVE PARTITION作为SharedMergeTree引擎的轻量级操作。此引擎还允许用增加ClickHouse服务器数量的方式,轻松的提高摄取吞吐量。我们尚未有机会在其他设置上测试这个脚本,但我们欢迎社区贡献。原则上,它应该可以在最小调整的情况下在其他设置上运行。MOVE PARTITION操作必须在分片集群的所有分片上运行,例如,通过使用ON CLUSTER子句。另请注意,在使用零拷贝复制时,MOVE PARTITION目前无法并发运行。我们希望该脚本作为一个良好的基础,并欢迎社区在更多用例和场景中使用它,让我们共同改进!
在未来,我们期望在ClickPipes中为从对象存储摄取文件提供支持时考虑此脚本的机制。敬请关注更新!
总结
加载数万亿行的大型数据集通常会很有挑战。为了克服这一难题,ClickHouse Cloud提供了ClickPipes - 这是一种内置的托管集成解决方案,能支持大数据量鲁棒性加载,以及自动重试等强大功能。如果您的外部数据源尚未受到支持,我们还探讨了ClickLoad的实现机制,请参考这个可以长时间、分批次且可靠地加载大型数据集的脚本。
到此,我们完成了《激发大规模ClickHouse数据加载》的三部曲博客系列。前两篇如下:
Meetup 活动报名通知
好消息:ClickHouse Shenzhen?User Group第1届 Meetup 已经开放报名了,将于2024年1月6日在深圳南山区海天二路33号腾讯滨海大厦举行,扫码免费报名
?

??联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Multimodal Multitask Learning with a Unified Transformer
- redis集群部署
- Wish防关联是什么?如何避免Wish违规封店?
- 要参加微软官方 Copilot 智能编程训练营了
- 002计算机中各个硬件的工作原理
- 从编程到售前:一个程序员的转型之旅
- 【Python_PyQtGraph 学习笔记(目录)】
- Leetcode 724. Find Pivot Index
- python异常之assert语句
- 生信技能34 - 通过UCSC单条染色体Fasta序列构建hg19参考序列及其索引