JAVA基础学习笔记-day14-数据结构与集合源码2
JAVA基础学习笔记-day14-数据结构与集合源码2
博文主要是自己学习JAVA基础中的笔记,供自己以后复习使用,参考的主要教程是B站的
尚硅谷宋红康2023大数据教程
君以此始,亦必以终。—左丘明《左传·宣公十二年》
7. List接口分析
7.1 List接口特点
- List集合所有的元素是以一种
线性方式进行存储的,例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)。 - 它是一个元素
存取有序的集合。即元素的存入顺序和取出顺序有保证。 - 它是一个
带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。 - 集合中可以有
重复的元素,通过元素的equals方法,来比较是否为重复的元素。
注意:
List集合关心元素是否有序,而不关心是否重复,请大家记住这个原则。例如“张三”可以领取两个号。
- List接口的主要实现类
- ArrayList:动态数组
- Vector:动态数组
- LinkedList:双向链表
- Stack:栈
7.2 动态数组ArrayList与Vector
Java的List接口的实现类中有两个动态数组的实现:ArrayList 和 Vector。
7.2.1 ArrayList与Vector的区别
它们的底层物理结构都是数组,我们称为动态数组。
- ArrayList是新版的动态数组,线程不安全,效率高,Vector是旧版的动态数组,线程安全,效率低。
- 动态数组的扩容机制不同,ArrayList默认扩容为原来的1.5倍,Vector默认扩容增加为原来的2倍。
- 数组的初始化容量,如果在构建ArrayList与Vector的集合对象时,没有显式指定初始化容量,那么Vector的内部数组的初始容量默认为10,而ArrayList在JDK 6.0 及之前的版本也是10,JDK8.0 之后的版本ArrayList初始化为长度为0的空数组,之后在添加第一个元素时,再创建长度为10的数组。原因:
- 用的时候,再创建数组,避免浪费。因为很多方法的返回值是ArrayList类型,需要返回一个ArrayList的对象,例如:后期从数据库查询对象的方法,返回值很多就是ArrayList。有可能你要查询的数据不存在,要么返回null,要么返回一个没有元素的ArrayList对象。
7.3 链表LinkedList
Java中有双链表的实现:LinkedList,它是List接口的实现类。
LinkedList是一个双向链表,如图所示:

7.3.1 链表与动态数组的区别
动态数组底层的物理结构是数组,因此根据索引访问的效率非常高。但是非末尾位置的插入和删除效率不高,因为涉及到移动元素。另外添加操作时涉及到扩容问题,就会增加时空消耗。
链表底层的物理结构是链表,因此根据索引访问的效率不高,即查找元素慢。但是插入和删除不需要移动元素,只需要修改前后元素的指向关系即可,所以插入、删除元素快。而且链表的添加不会涉及到扩容问题。
8. Map接口分析
8.1 哈希表的物理结构
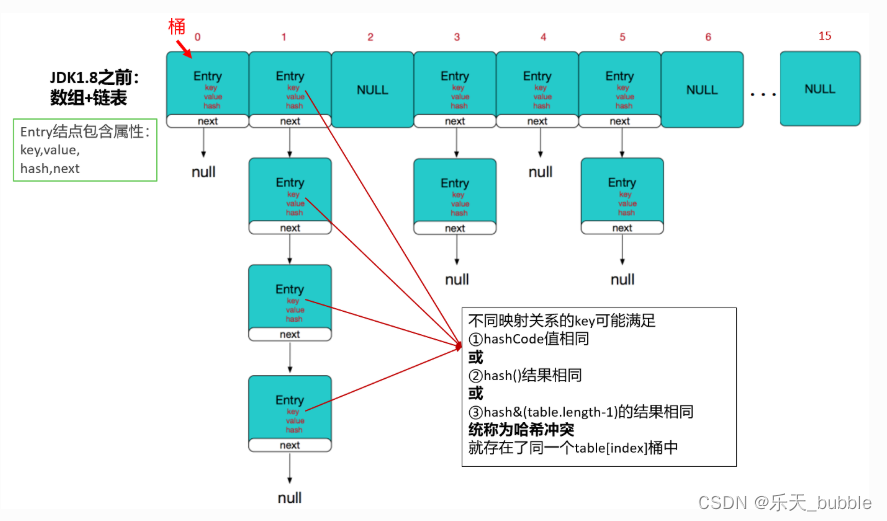
HashMap和Hashtable底层都是哈希表(也称散列表),其中维护了一个长度为2的幂次方的Entry类型的数组table,数组的每一个索引位置被称为一个桶(bucket),你添加的映射关系(key,value)最终都被封装为一个Map.Entry类型的对象,放到某个table[index]桶中。
使用数组的目的是查询和添加的效率高,可以根据索引直接定位到某个table[index]。
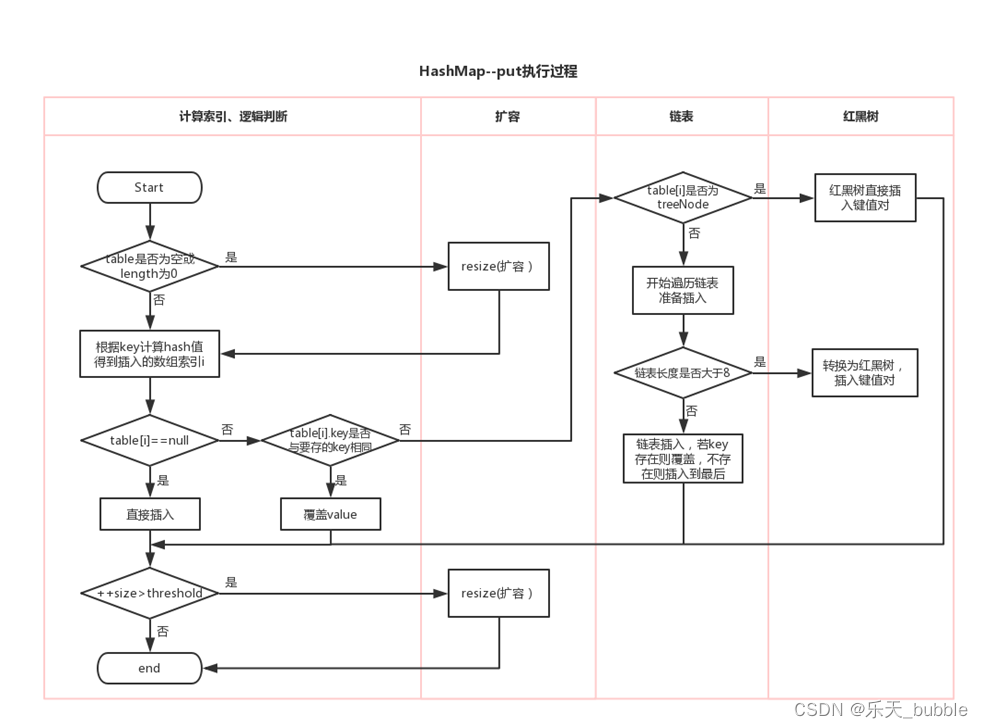
8.2 HashMap中数据添加过程
8.2.1 JDK7中过程分析
// 在底层创建了长度为16的Entry[] table的数组
HashMap map = new HashMap();
map.put(key1,value1);
/*
分析过程如下:
将(key1,value1)添加到当前hashmap的对象中。首先会调用key1所在类的hashCode()方法,计算key1的哈希值1,
此哈希值1再经过某种运算(hash()),得到哈希值2。此哈希值2再经过某种运算(indexFor()),确定在底层table数组中的索引位置i。
(1)如果数组索引为i上的数据为空,则(key1,value1)直接添加成功 ------位置1
(2)如果数组索引为i上的数据不为空,有(key2,value2),则需要进一步判断:
判断key1的哈希值2与key2的哈希值是否相同:
(3) 如果哈希值不同,则(key1,value1)直接添加成功 ------位置2
如果哈希值相同,则需要继续调用key1所在类的equals()方法,将key2放入equals()形参进行判断
(4) equals方法返回false : 则(key1,value1)直接添加成功 ------位置3
equals方法返回true : 默认情况下,value1会覆盖value2。
位置1:直接将(key1,value1)以Entry对象的方式存放到table数组索引i的位置。
位置2、位置3:(key1,value1) 与现有的元素以链表的方式存储在table数组索引i的位置,新添加的元素指向旧添加的元素。
...
在不断的添加的情况下,满足如下条件的情况下,会进行扩容:
if ((size >= threshold) && (null != table[bucketIndex])) :
默认情况下,当要添加的元素个数超过12(即:数组的长度 * loadFactor得到的结果)时,就要考虑扩容。
补充:jdk7源码中定义的:
static class Entry<K,V> implements Map.Entry<K,V>
*/
map.get(key1);
/*
① 计算key1的hash值,用这个方法hash(key1)
② 找index = table.length-1 & hash;
③ 如果table[index]不为空,那么就挨个比较哪个Entry的key与它相同,就返回它的value
*/
map.remove(key1);
/*
① 计算key1的hash值,用这个方法hash(key1)
② 找index = table.length-1 & hash;
③ 如果table[index]不为空,那么就挨个比较哪个Entry的key与它相同,就删除它,把它前面的Entry的next的值修改为被删除Entry的next
*/
8.2.2 JDK8中过程分析
下面说明是JDK8相较于JDK7的不同之处:
/*
①
使用HashMap()的构造器创建对象时,并没有在底层初始化长度为16的table数组。
②
jdk8中添加的key,value封装到了HashMap.Node类的对象中。而非jdk7中的HashMap.Entry。
③
jdk8中新增的元素所在的索引位置如果有其他元素。在经过一系列判断后,如果能添加,则是旧的元素指向新的元素。而非jdk7中的新的元素指向旧的元素。“七上八下”
④
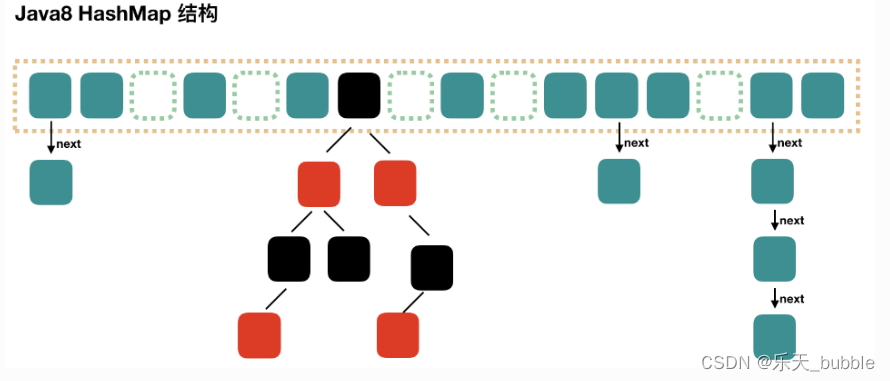
jdk7时底层的数据结构是:数组+单向链表。 而jdk8时,底层的数据结构是:数组+单向链表+红黑树。
红黑树出现的时机:当某个索引位置i上的链表的长度达到8,且数组的长度超过64时,此索引位置上的元素要从单向链表改为红黑树。
如果索引i位置是红黑树的结构,当不断删除元素的情况下,当前索引i位置上的元素的个数低于6时,要从红黑树改为单向链表。
*/
8.3 HashMap源码剖析
8.3.1 JDK1.7.0_07中源码
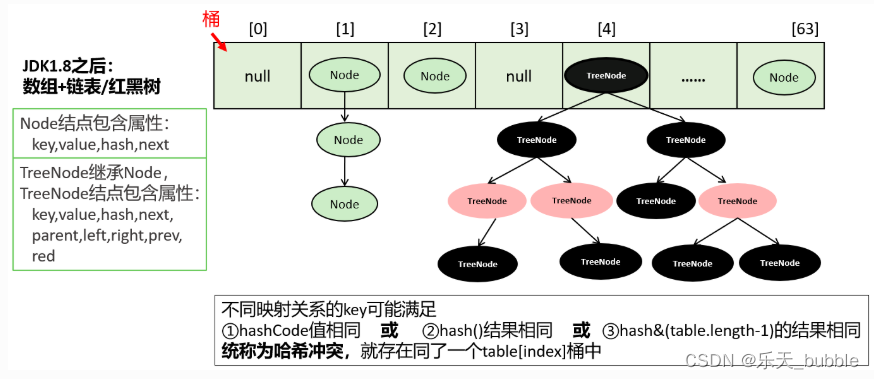
8.3.2 JDK1.8.0_271中源码
1、Node
key-value被封装为HashMap.Node类型或HashMap.TreeNode类型,它俩都直接或间接的实现了Map.Entry接口。
存储到table数组的可能是Node结点对象,也可能是TreeNode结点对象,它们也是Map.Entry接口的实现类。即table[index]下的映射关系可能串起来一个链表或一棵红黑树。
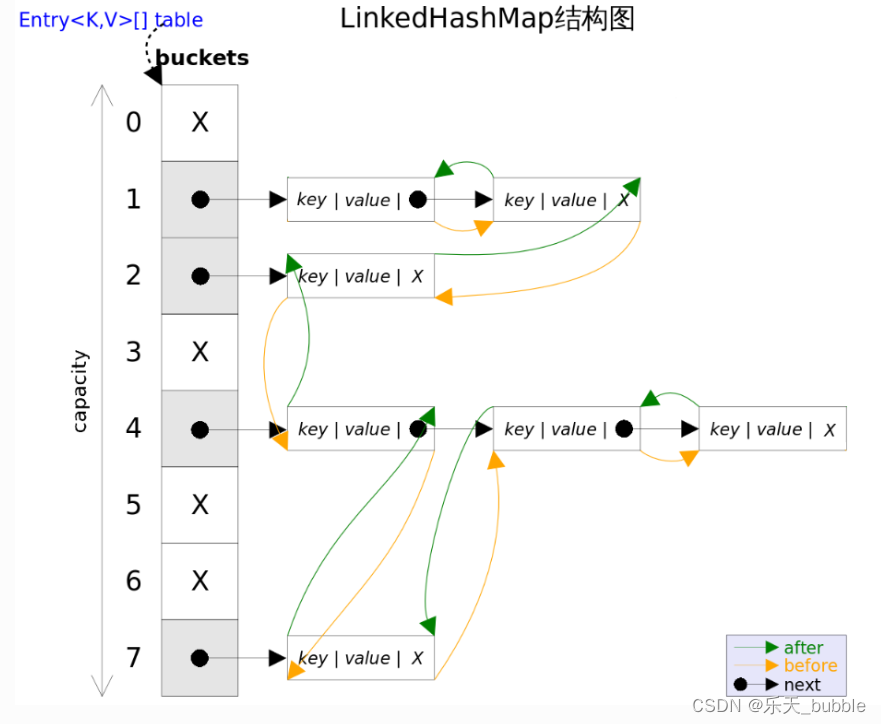
8.4 LinkedHashMap源码剖析
8.4.1 源码
内部定义的Entry如下:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
LinkedHashMap重写了HashMap中的newNode()方法:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
}
8.4.2 图示
9. Set接口分析
9.1 Set集合与Map集合的关系
Set的内部实现其实是一个Map,Set中的元素,存储在HashMap的key中。即HashSet的内部实现是一个HashMap,TreeSet的内部实现是一个TreeMap,LinkedHashSet的内部实现是一个LinkedHashMap。
10. 【拓展】HashMap的相关问题
1、说说你理解的哈希算法
hash算法是一种可以从任何数据中提取出其“指纹”的数据摘要算法,它将任意大小的数据映射到一个固定大小的序列上,这个序列被称为hash code、数据摘要或者指纹。比较出名的hash算法有MD5、SHA。hash是具有唯一性且不可逆的,唯一性是指相同的“对象”产生的hash code永远是一样的。
2、Entry中的hash属性为什么不直接使用key的hashCode()返回值呢?
不管是JDK1.7还是JDK1.8中,都不是直接用key的hashCode值直接与table.length-1计算求下标的,而是先对key的hashCode值进行了一个运算,JDK1.7和JDK1.8关于hash()的实现代码不一样,但是不管怎么样都是为了提高hash code值与 (table.length-1)的按位与完的结果,尽量的均匀分布。

JDK1.7:
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
JDK1.8:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
虽然算法不同,但是思路都是将hashCode值的高位二进制与低位二进制值进行了异或,然高位二进制参与到index的计算中。
为什么要hashCode值的二进制的高位参与到index计算呢?
因为一个HashMap的table数组一般不会特别大,至少在不断扩容之前,那么table.length-1的大部分高位都是0,直接用hashCode和table.length-1进行&运算的话,就会导致总是只有最低的几位是有效的,那么就算你的hashCode()实现的再好也难以避免发生碰撞,这时让高位参与进来的意义就体现出来了。它对hashcode的低位添加了随机性并且混合了高位的部分特征,显著减少了碰撞冲突的发生。
3、HashMap是如何决定某个key-value存在哪个桶的呢?
因为hash值是一个整数,而数组的长度也是一个整数,有两种思路:
①hash 值 % table.length会得到一个[0,table.length-1]范围的值,正好是下标范围,但是用%运算效率没有位运算符&高。
②hash 值 & (table.length-1),任何数 & (table.length-1)的结果也一定在[0, table.length-1]范围。
JDK1.7:
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1); //此处h就是hash
}
JDK1.8:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // i = (n - 1) & hash
tab[i] = newNode(hash, key, value, null);
//....省略大量代码
}
4、为什么要保持table数组一直是2的n次幂呢?
因为如果数组的长度为2的n次幂,那么table.length-1的二进制就是一个高位全是0,低位全是1的数字,这样才能保证每一个下标位置都有机会被用到。
举例1:
hashCode值是 ?
table.length是10
table.length-1是9
? ????????
9 00001001
&_____________
00000000 [0]
00000001 [1]
00001000 [8]
00001001 [9]
一定[0]~[9]
5、解决[index]冲突问题
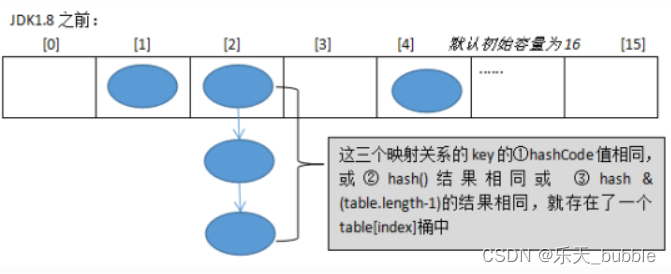
虽然从设计hashCode()到上面HashMap的hash()函数,都尽量减少冲突,但是仍然存在两个不同的对象返回的hashCode值相同,或者hashCode值就算不同,通过hash()函数计算后,得到的index也会存在大量的相同,因此key分布完全均匀的情况是不存在的。那么发生碰撞冲突时怎么办?
JDK1.8之间使用:数组+链表的结构。
JDK1.8之后使用:数组+链表/红黑树的结构。
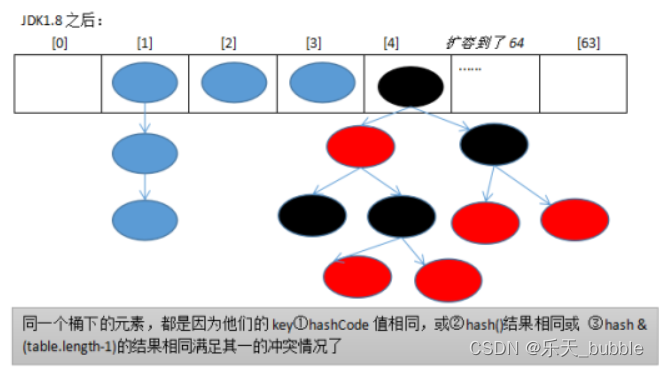
即hash相同或hash&(table.lengt-1)的值相同,那么就存入同一个“桶”table[index]中,使用链表或红黑树连接起来。
6、为什么JDK1.8会出现红黑树和链表共存呢?
因为当冲突比较严重时,table[index]下面的链表就会很长,那么会导致查找效率大大降低,而如果此时选用二叉树可以大大提高查询效率。
但是二叉树的结构又过于复杂,占用内存也较多,如果结点个数比较少的时候,那么选择链表反而更简单。所以会出现红黑树和链表共存。
7、加载因子的值大小有什么关系?
如果太大,threshold就会很大,那么如果冲突比较严重的话,就会导致table[index]下面的结点个数很多,影响效率。
如果太小,threshold就会很小,那么数组扩容的频率就会提高,数组的使用率也会降低,那么会造成空间的浪费。
8、什么时候树化?什么时候反树化?
static final int TREEIFY_THRESHOLD = 8;//树化阈值
static final int UNTREEIFY_THRESHOLD = 6;//反树化阈值
static final int MIN_TREEIFY_CAPACITY = 64;//最小树化容量
-
当某table[index]下的链表的结点个数达到8,并且table.length>=64,那么如果新Entry对象还添加到该table[index]中,那么就会将table[index]的链表进行树化。
-
当某table[index]下的红黑树结点个数少于6个,此时,
- 当继续删除table[index]下的树结点,最后这个根结点的左右结点有null,或根结点的左结点的左结点为null,会反树化
- 当重新添加新的映射关系到map中,导致了map重新扩容了,这个时候如果table[index]下面还是小于等于6的个数,那么会反树化
package com.atguigu.map;
public class MyKey{
int num;
public MyKey(int num) {
super();
this.num = num;
}
@Override
public int hashCode() {
if(num<=20){
return 1;
}else{
final int prime = 31;
int result = 1;
result = prime * result + num;
return result;
}
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
MyKey other = (MyKey) obj;
if (num != other.num)
return false;
return true;
}
}
package com.atguigu.map;
import org.junit.Test;
import java.util.HashMap;
public class TestHashMapMyKey {
@Test
public void test1(){
//这里为了演示的效果,我们造一个特殊的类,这个类的hashCode()方法返回固定值1
//因为这样就可以造成冲突问题,使得它们都存到table[1]中
HashMap<MyKey, String> map = new HashMap<>();
for (int i = 1; i <= 11; i++) {
map.put(new MyKey(i), "value"+i);//树化演示
}
}
@Test
public void test2(){
HashMap<MyKey, String> map = new HashMap<>();
for (int i = 1; i <= 11; i++) {
map.put(new MyKey(i), "value"+i);
}
for (int i = 1; i <=11; i++) {
map.remove(new MyKey(i));//反树化演示
}
}
@Test
public void test3(){
HashMap<MyKey, String> map = new HashMap<>();
for (int i = 1; i <= 11; i++) {
map.put(new MyKey(i), "value"+i);
}
for (int i = 1; i <=5; i++) {
map.remove(new MyKey(i));
}//table[1]下剩余6个结点
for (int i = 21; i <= 100; i++) {
map.put(new MyKey(i), "value"+i);//添加到扩容时,反树化
}
}
}
9、key-value中的key是否可以修改?
key-value存储到HashMap中会存储key的hash值,这样就不用在每次查找时重新计算每一个Entry或Node(TreeNode)的hash值了,因此如果已经put到Map中的key-value,再修改key的属性,而这个属性又参与hashcode值的计算,那么会导致匹配不上。
这个规则也同样适用于LinkedHashMap、HashSet、LinkedHashSet、Hashtable等所有散列存储结构的集合。
10、JDK1.7中HashMap的循环链表是怎么回事?如何解决?
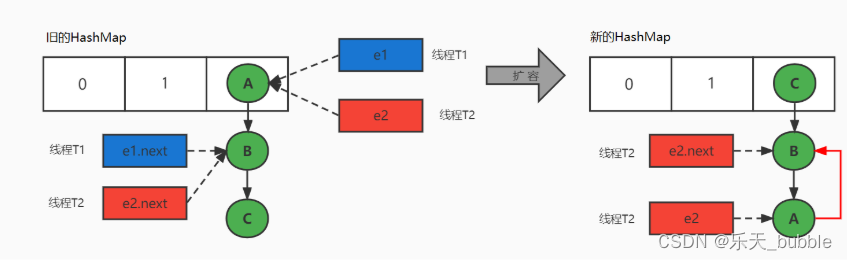
避免HashMap发生死循环的常用解决方案:
- 多线程环境下,使用线程安全的ConcurrentHashMap替代HashMap,推荐
- 多线程环境下,使用synchronized或Lock加锁,但会影响性能,不推荐
- 多线程环境下,使用线程安全的Hashtable替代,性能低,不推荐
HashMap死循环只会发生在JDK1.7版本中,主要原因:头插法+链表+多线程并发+扩容。
在JDK1.8中,HashMap改用尾插法,解决了链表死循环的问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 逸学Docker【java工程师基础】2.Docker镜像容器基本操作+安装MySQL镜像运行
- QT工具栏开始,退出
- K-th Beautiful String
- KANDINSKY 3.0 TECHNICAL REPORT
- Git舍弃本地修改,git checkout -- . 或者 git restore .
- Repo命令与git的关系
- 在Linux中tomcat出现乱码
- 力扣hot100 颜色分类 双指针 滚动赋值
- 【Leetcode】2788. 按分隔符拆分字符串
- 代码随想录算法训练营第45天|● 139.单词拆分 ● 关于多重背包,你该了解这些! ● 背包问题总结篇!