AI快速构建中文文本蕴含深度学习模型-NeuronBlocks(一)
案例介绍
随着自然语言处理(NLP)领域研究的不断深入,如何让机器能够真正地理解自然语言,而不是仅简单地处理语句的表层信息,渐渐成为了许多学者面临的问题。实现对文本深层次理解,是自然语言处理研究最主要也是最重要的目的之一。
在获取了文本的语义后,一旦获得了它们之间的推理关系,这些文本便不再互相孤立,而是彼此联系起来,构成一张语义推理网络,从而促使机器能够真正理解并应用文本的语义信息。文本间的推理关系,又称为文本蕴含关系。作为一种基本的文本间语义联系,广泛存在于自然语言文本中。
简单的来说文本蕴含关系描述的是两个文本之间的推理关系,其中一个文本作为前提,另一个文本作为假设,如果根据前提能够推理得出假设,那么就说两者之间存在蕴含关系。
正如以下两个句子,我们可以轻松地判断出两者之间存在蕴含关系,但如果用机器该如何进行判断呢?
- 阿尔卑斯山的景色看上去像是从奥地利或瑞士直接出来的。
- 阿尔卑斯山的地貌看起来与奥地利或瑞士相似。
本案例将会给大家介绍如何使用NeuronBlocks进行文本蕴含关系的分析
案例价值
- 可以了解中文文本蕴含(NLI)的基础内容
- 可以学会使用微软开源项目NeuronBlocks的使用方法
- 能利用NeuronBlocks快速构建、训练、测试你的NLI深度学习模型
使用场景
文本蕴含技术在众多语义相关的自然语言处理(NLP)任务和日常生活中有着广泛的应用。
- 在问答系统中,文本蕴含技术可以生成候选答案,或对用其他方法生成的候选答案进行筛选排序
- 在机器翻译评价领域,可以利用机器译文和标准译文的互相蕴含程度来对机器翻译系统的性能进行评估
- 在学生作业评分任务中,学生的作答与标准答案之间的蕴含关系也可以指示学生答案的完善程度等等。
神经元块
为了提升构建自然语言理解深度学习模型的效率,微软推出了NeuronBlocks——自然语言处理任务的模块化深度学习建模工具包。
目前,微软在GitHub上拥有3.9k个开源项目,是世界上最大的开源项目支持者。从底层的协议、编程语言,到各种框架、类库,再到应用工具,微软的开源贡献一直在持续。微软开源项目入口
作为微软的开源项目之一,NeuronBlocks可帮助工程师、研究者们快速构建用于NLP任务的神经网络模型训练的端到端管道。该工具包的主要目标是将NLP深度神经网络模型构建的开发成本降到最低,包括训练阶段和推断阶段。NeuronBlocks由两个主要组件组成:Block Zoo和Model Zoo。Block Zoo提供常用的神经网络组件作为模型架构设计的构建模块,如BiLSTM、BiGRU、Transformer、CNN等;在Model Zoo中,针对常见的NLP分类任务,如情感分析、文本分类、序列标注、机器阅读理解等,以JSON配置文件的形式为其提供了一套NLP模型。更多详细信息,请查看GitHub项目地址。
本案例中,中文文本蕴含任务本质也是一种分类任务,所以我们选择Model Zoo来快速构建中文文本蕴含(NLI)深度学习算法模型。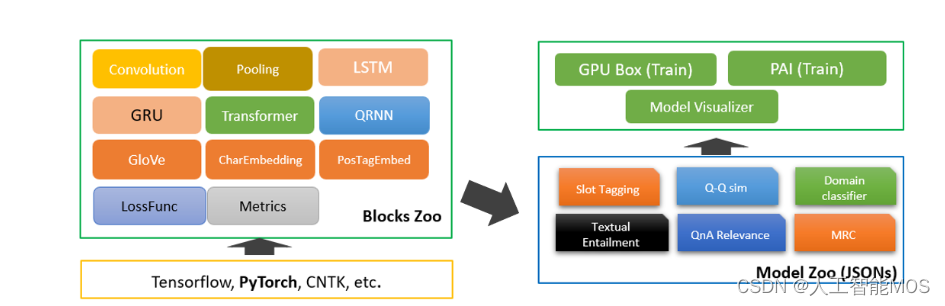
先修知识
- 了解微软开源项目Neuronblocks
参考链接:?NeuronBlocks - 了解主流深度学习框架
参考链接:?Pytorch
案例大纲与核心知识点
| 序号 | 内容 | 关键知识点 | 收获实战技能 |
|---|---|---|---|
| 1 | 配置环境与工具 | 虚拟环境与Pytorch | 使用虚拟环境安装Pytorch |
| 2 | 数据获取 | Python数据处理 | 使用Python对数据集处理 |
| 3 | 模型构建 | 神经元块 / BiGRU | 使用Neuronblocks与BiGRU构建中文文本蕴含深度学习模型 |
| 4 | 模型训练 | 神经元块 | 使用Neuronblocks进行模型训练 |
| 5 | 模型测试 | 神经元块 | 使用Neuronblocks进行模型测试 |
| 6 | 模型推理 | 神经元块 | 使用Neuronblocks进行模型推理 |
推荐学习时长
- 初次学习的实战者:5~8 小时
- 有一定经验学习者:3~5 小时
- 模型训练时间:6~24小时
案例详解
环境与工具
本案列运行具有CPU的计算机上,系统可以是Windows / Macos / Linux 需要的软件环境如下:
- 蟒蛇 3.7
如果您有Nvidia的显卡,可以根据以下的Nvidia显卡算力表来查询您显卡的算力 Nvidia显卡算力
表:?CUDA GPU
根据您显卡算力的不同,模型训练时间可以加快50-100倍。在后续的流程中,显卡流程将被折叠起来,请您根据折叠部分的提示,打开对应的折叠内容。
实现流程
配置环境与工具
-
打开终端并选择合适的路径
# 将YOUR_LIKE_PATH替换为你常用或合适的路径 # Windows pwsh / Mac / Linux bash cd YOUR_LIKE_PATH
-
将Microsoft开源项目NeuronBlocks Clone至本地,并进入该目录:
git clone https://github.com/microsoft/NeuronBlocks.git cd NeuronBlocks
如果您有Nvidia的显卡,请点击此处折叠CPU流程
-
创建虚拟环境(可选),安装Python依赖包
# 可以选择你喜欢的虚拟环境管理方式 # pipenv > pipenv shell --python 3.7 > pip install nltk==3.5 gensim==3.8.3 tqdm==4.59.0 numpy==1.20.1 scikit-learn==0.24.1 ftfy==5.9 jieba==0.42.1 > pip install torch==1.8.0+cpu torchvision==0.9.0+cpu -f https://download.pytorch.org/whl/torch_stable.html # conda (Windows) > conda create -n YOUR_ENV_NAME python=3.7 > activate YOUR_ENV_NAME > pip install nltk==3.5 gensim==3.8.3 tqdm==4.59.0 numpy==1.20.1 scikit-learn==0.24.1 ftfy==5.9 jieba==0.42.1 > pip install torch==1.8.0+cpu torchvision==0.9.0+cpu -f https://download.pytorch.org/whl/torch_stable.html # pip (无虚拟环境) > pip install nltk==3.5 gensim==3.8.3 tqdm==4.59.0 numpy==1.20.1 scikit-learn==0.24.1 ftfy==5.9 jieba==0.42.1 > pip install torch==1.8.0+cpu torchvision==0.9.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
-
在安装后,我们的环境应该如下
>pip list nltk==3.5 gensim==3.8.3 tqdm==4.59.0 numpy==1.20.1 scikit-learn==0.24.1 ftfy==5.9 jieba==0.42.1 torch==1.8.0+cpu torchvision==0.9.0+cpu
如果您有Nvidia显卡,且算力大于3.5,请打开此折叠部分
如果您有Nvidia显卡,且算力小于等于3.5,请打开此折叠部分
数据获取
我们利用的是开源的中文文本蕴含数据集,数据集train.txt主要包含三种文本蕴含关系:entailment、contradiction、 neutral, 数据示例如下所示,第一个文本句子为为前提(premise),第二个文本句子为假设(hypothesis),其次是前提和假设的蕴含关系,每一行代表一个样本,以\t分隔。数据量级在42万左右,类别比例entailment:contradiction:neutral = 1:1:1,不存在数据类别不平衡问题。
| 一个年轻人在呼啦圈。 | 这位老人正在呼啦圈。 | 矛盾 |
| 两个人正在大教堂或清真寺里交谈。 | 两个人在谈话 | 蕴涵 |
| 穿着黑色外套的妇女边看报纸边等着洗衣服。 | 一个女人在洗衣店。 | 中性 |
数据下载并处理
首先,我们先将数据集克隆到本地并启动python
git clone https://github.com/liuhuanyong/ChineseTextualInference.git
中文文本蕴含数据集只提供了train.txt,为了方便测试验证我们的模型,我们将该据集划分训练集、验证集、测试集。
# 新建一个split_data.py,输入以下代码并运行即可划分好并放置在指定目录
import random
import os
dirs = "./dataset/chinese_nli/"
def split_data():
samples = {"neutral": [], "contradiction": [], "entailment": []}
with open("./ChineseTextualInference/data/train.txt", "r", encoding="utf-8") as fout:
for line in fout:
contents = line.strip().split("\t")
if len(contents) < 3:
continue
samples[contents[-1]].append(line)
print(
f'neutral:{len(samples["neutral"])}, contradiction:{len (samples["contradiction"])}, entailment: {le(samples ["entailment"])}')
def split_hepler(data):
# 根据data的6:2:2划分train, dev, test
length = len(data)
train = data[: int(length * 0.6)]
dev = data[int(length * 0.6): int(length * 0.8)]
test = data[int(length * 0.8):]
return train, dev, test
def save_data(data, filename):
with open(filename, "w", encoding="utf-8") as fout:
for line in data:
fout.write(line)
# 数据按比例分开
neu_train, neu_dev, neu_test = split_hepler(samples["neutral"])
cont_train, cont_dev, cont_test = split_hepler(
samples["contradiction"])
ent_train, ent_dev, ent_test = split_hepler(samples["entailment"])
# 将数据合并
train = neu_train + cont_train + ent_train
dev = neu_dev + cont_dev + ent_dev
test = neu_test + cont_test + ent_test
# 打乱数据
random.shuffle(train)
random.shuffle(dev)
random.shuffle(test)
# 保存需要测试的数据
save_data(train, f"{dirs}cnli_train.txt")
save_data(dev, f"{dirs}cnli_dev.txt")
save_data(test, f"{dirs}cnli_test.txt")
if not os.path.exists(dirs):
os.makedirs(dirs)
# 读取数据并处理统计
split_data()
下载中文预训练词向量
运用已在大规模语料上预训练得到的中文词向量初始化词向量参数,提升模型的性能。我们此处选用的搜狗新闻语料预训练的Word300的词向量,下载并解压缩获得词向量文件sgns.sogou.word,词向量下载地址。https://github.com/Embedding/Chinese-Word-Vectors#pre-trained-chinese-word-vectors
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!