SpringBoot使用druid
发布时间:2024年01月24日
一、前言
Java程序很大一部分要操作数据库,为了提高性能操作数据库的时候,又不得不使用数据库连接池。
Druid 是阿里巴巴开源平台上一个数据库连接池实现,结合了 C3P0、DBCP 等 DB 池的优点,同时加入了日志监控。
Druid 可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的 DB 连接池。
Druid已经在阿里巴巴部署了超过600个应用,经过一年多生产环境大规模部署的严苛考验。
Spring Boot 2.0 以上默认使用 Hikari 数据源,可以说 Hikari 与 Driud 都是当前 Java Web 上最优秀的数据源,我们来重点介绍 Spring Boot 如何集成 Druid 数据源,如何实现数据库监控。
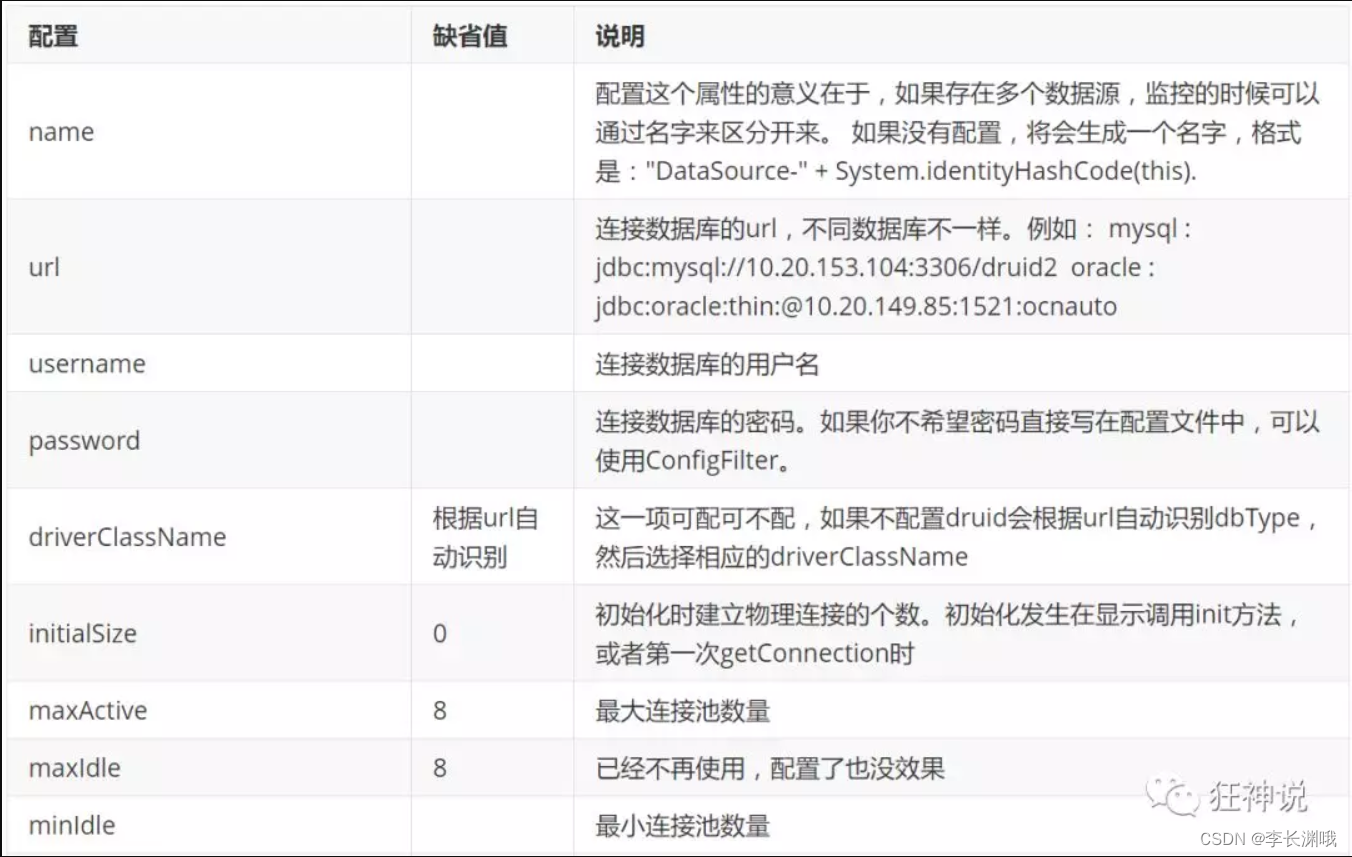
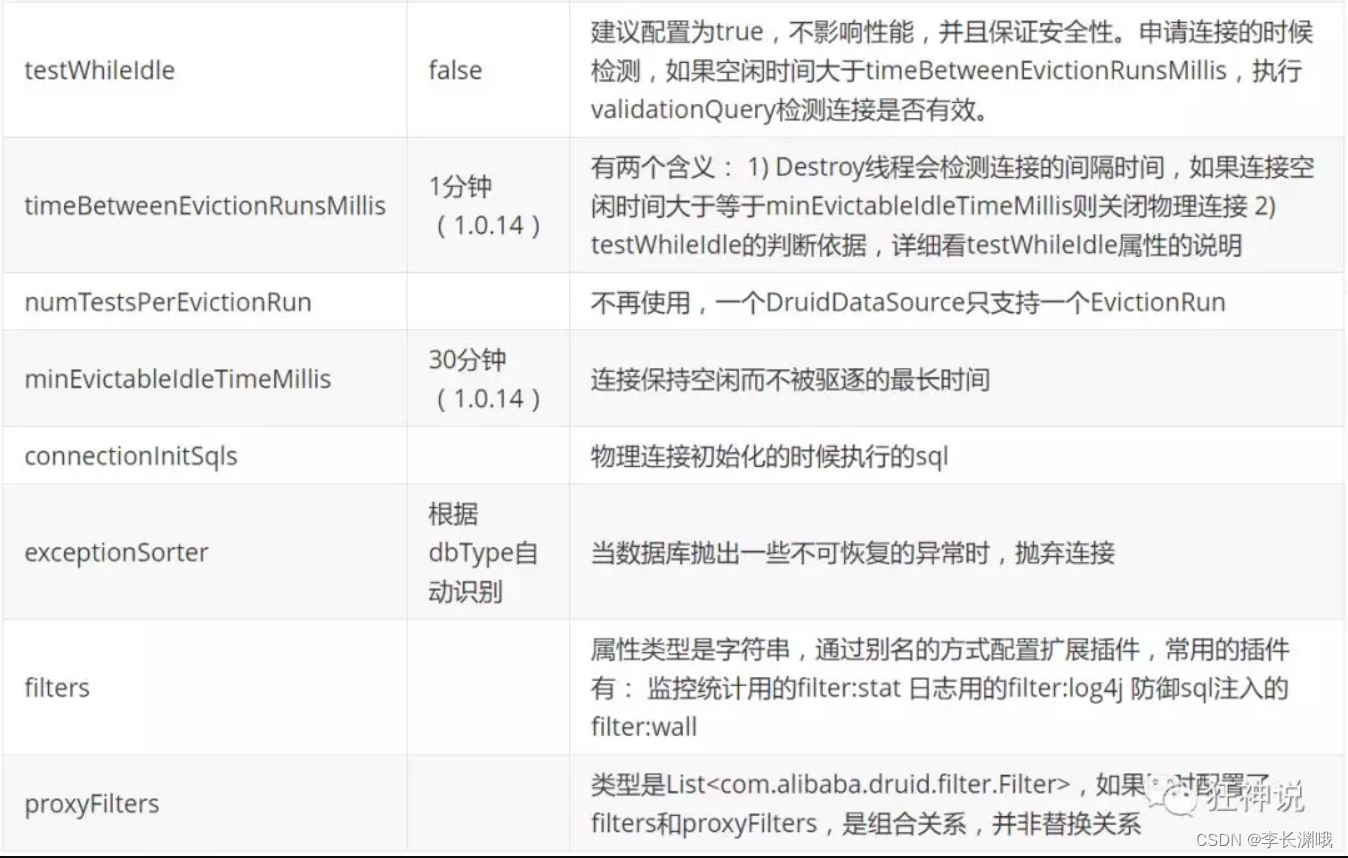
二、配置
1、pom依赖
<!--引入Druid数据源-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.12</version>
</dependency>
<!--日志依赖-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
2、配置文件yml
#数据库配置
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/library?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8&characterSetResults=utf8&useSSL=false&allowMultiQueries=true
username: root
password: 123456
# 连接池类型druid
type: com.alibaba.druid.pool.DruidDataSource
#Spring Boot 默认是不注入这些属性值的,需要自己绑定
#druid 数据源专有配置
# 配置Druid的其他参数,以下配置必须增加一个配置文件才能有效
# 初始化大小,最小,最大
initialSize: 5
minIdle: 5
maxActive: 20
# 获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat, wall
# 打开PSCache,并且指定每个连接上PSCache的大小
maxPoolPreparedStatementPerConnectionSize: 20
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
# 合并多个DruidDataSource的监控数据
useGlobalDataSourceStat: true
3、配置类
第一段:
由于DruidDataSource需要使用上述的配置,在添加到容器中,就不能使用springboot自动生成,这时需要我们自己添加 DruidDataSource 组件到容器中,并绑定属性;
第二段:
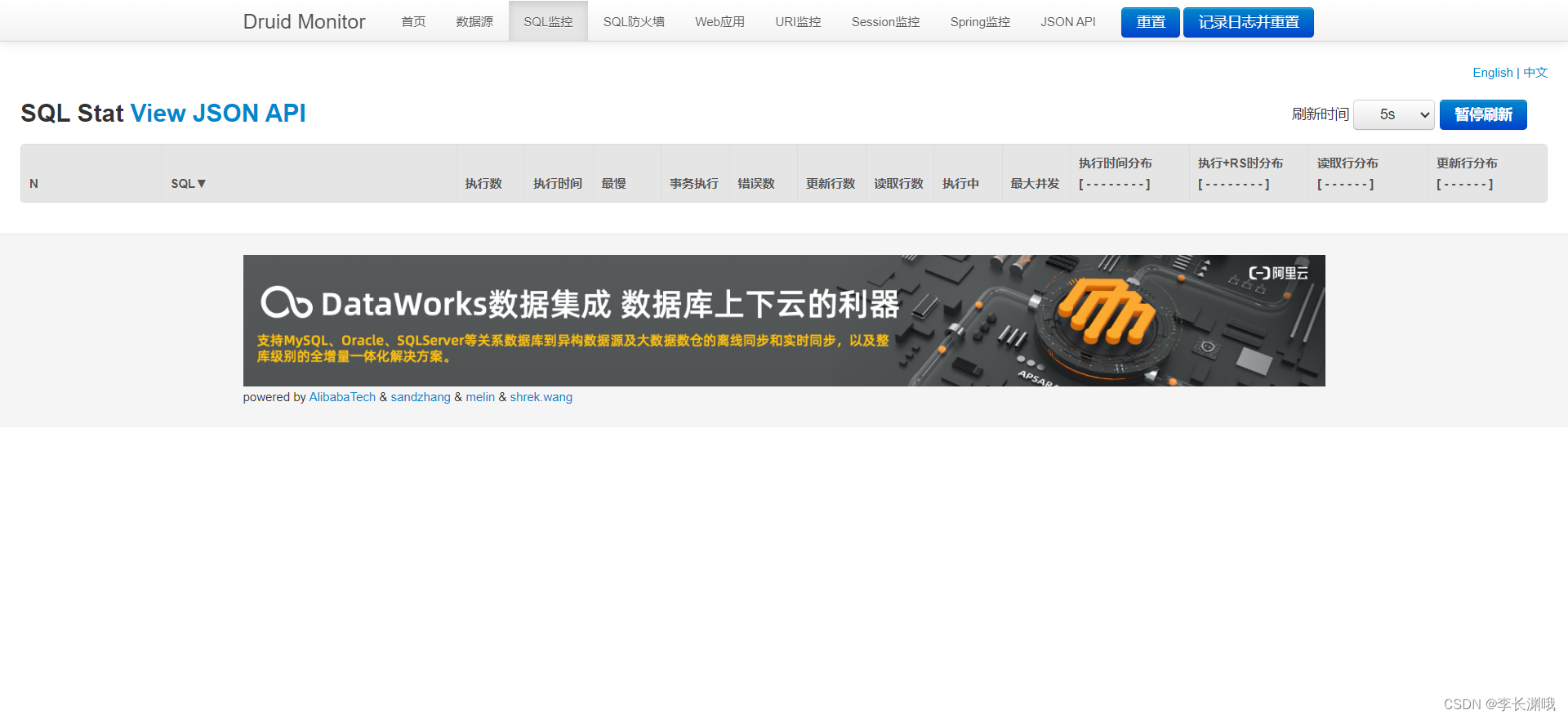
Druid 数据源具有监控的功能,并提供了一个 web 界面方便用户查看,类似安装 路由器 时,人家也提供了一个默认的 web 页面。
所以第一步需要设置 Druid 的后台管理页面,比如 登录账号、密码 等;配置后台管理;
这里只是注册了一个servlet,同时表明/druid/* 这个请求会走到这个servlet,而druid内置了这个请求的接收,同时需要给这个请求添加用户密码等参数
第三段:
配置过滤请求,需要统计哪些sql的信息
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
/**
* 表示一个配置文件
*/
@Configuration
public class DruidConfig {
/**
* 加入到Spring容器中,并扫描spring.datasource前缀的配置
*
* @return
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druid() {
return new DruidDataSource();
}
//配置 Druid 监控管理后台的Servlet;
//内置 Servlet 容器时没有web.xml文件,所以使用 Spring Boot 的注册 Servlet 方式
@Bean
public ServletRegistrationBean a() {
ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
Map<String, String> initParameters = new HashMap<>();
initParameters.put("loginUsername", "admin");
initParameters.put("loginPassword", "admin");
bean.setInitParameters(initParameters);
return bean;
}
//配置 Druid 监控 之 web 监控的 filter
//WebStatFilter:用于配置Web和Druid数据源之间的管理关联监控统计
@Bean
public FilterRegistrationBean webStatFilter() {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
//exclusions:设置哪些请求进行过滤排除掉,从而不进行统计
Map<String, String> initParams = new HashMap<>();
initParams.put("exclusions", "*.js,*.css,/druid/*,/jdbc/*");
bean.setInitParameters(initParams);
//"/*" 表示过滤所有请求
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}
配置完毕后,我们可以选择访问 :http://localhost:8080/druid/login.html
文章来源:https://blog.csdn.net/weixin_46146718/article/details/135821420
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Nacos注册为windows服务详解
- 河南:女子一家八口住酒店223天,每天房费1000块,决定住一辈子
- AI时代系列丛书(由北京大学出版社出版)
- kali_linux换源教程
- TS 36.213 V12.0.0-PUSCH相关过程(1)-传输PUSCH的UE过程
- 【Vue】vue3创建组件时,自带margin:8px。
- 一种适合企业的大体量数据迁移方式
- MySQL数据库主从复制和读写分离
- Chromedriver 下载和安装指南
- PDA智能巡检系统