用Linux的视角来理解缓冲区概念

缓冲区的认识
缓冲区(buffer)是存储数据的临时存储区域。当我们用C语言向文件中写入数据时,数据并不会直接的写到文件中,中途还经过了缓冲区,而我们需要对缓冲区的数据进行刷新,那么数据才算写到文件当中。而缓冲区通常是一块内存区域,可以是数组、队列、链表等数据结构。
代码举例
int main()
{
//C接口
FILE* fp=fopen("log.txt","w");//创建文件
const char* buffer = "hello buffer\n";
fwrite(buffer,strlen(buffer),1,fp);//文件写入
//系统接口
close(fp->_fileno);
return 0;
}

此时的数据其实就是写进了缓冲区中,但是我们此时的调用接口是不一样的,关闭文件调用的是系统调用接口,而且FILE结构体中是封装了文件描述符的。先认识后续会讲述原因。
其实我们是可以将我们缓冲区中的数据给刷新出来:
int main()
{
FILE* fp=fopen("log.txt","w");
const char* buffer = "hello buffer\n";
fwrite(buffer,strlen(buffer),1,fp);
fflush(fp);//刷新缓冲区
close(fp->_fileno);
return 0;
}
?
?为什么要有缓冲区的存在
其实缓冲区的存在就是为了减少对数据的访问次数,当我们输入输出数据的时候,其实就是对文件信息进行交互的(一切皆文件)。我们为了避免每一次的文件访问IO操作,从而会降低效率,所以说可以建立一个像缓冲区这样的中转站,将数据与缓冲区交互,然后将所有的数据都接收处理好了以后再交给文件。
缓冲区的刷新方式
- 立即刷新(无缓冲)
- 行刷新(行缓冲)
- 缓冲区满了刷新(全缓冲)
- 强制刷新
一般对于显示器文件的刷新方式是行刷新(\n也是进行行刷新),而一般磁盘上的文件的刷新方式就是缓冲区满了再刷新。?我们也可以通过fflush函数强制的进行刷新缓冲区。
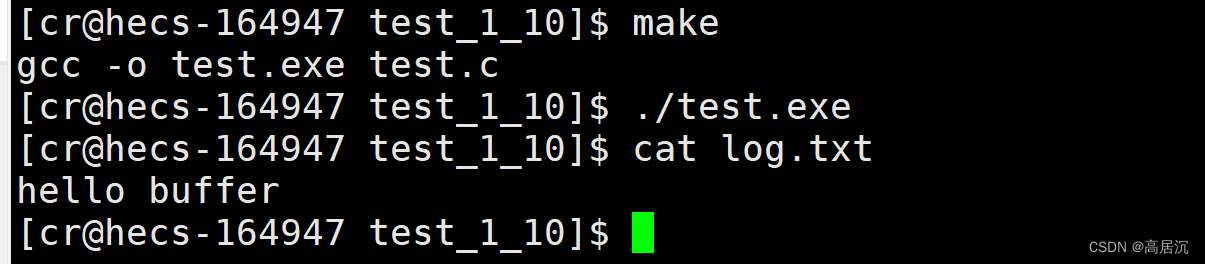
此时就可以浅浅的解释我们开始写的代码的,因为我们的一般文件的刷新策略是缓冲区满了才刷新的,这正是因为我们向log.txt这个文件里写的数据没有写满缓冲区,所以导致缓冲区没有刷新,从而该文件中并没有数据。其实如果你多写一些数据进去的话其实是可以写满的。
?
缓冲区与操作系统无关
?结论:我们写代码时的缓冲区其实是属于C语言的,与操作系统并无关系。
int main() { FILE* fp=fopen("log.txt","w"); const char* buffer = "helllo buffer\n"; fwrite(buffer,strlen(buffer),1,fp); fclose(fp);//C语言接口 return 0; }
?该段代码的区别就是用了C语言接口关闭文件。而我们开头的那段代码是系统调用关闭文件。仅仅换了一种关闭方式就导致了文件中一个有数据一个没数据。所以说可以知道,C语言中的fclose其实是封装了系统调用的close,但是还多了一个步骤:刷新缓冲区。
也可以说明系统调用接口其实是没有缓冲区这个概念的,缓冲区其实是我们C语言库中后期封装好的。

?
?经典样例
代码一:
int main() { printf("C:printf\n"); fprintf(stdout,"C:fprintf\n"); fputs("C:fputs\n",stdout); const char* arr = "system:write\n"; write(1,arr,strlen(arr)); return 0; }
代码二:
int main() { printf("C:printf\n"); fprintf(stdout,"C:fprintf\n"); fputs("C:fputs\n",stdout); const char* arr = "system:write\n"; write(1,arr,strlen(arr)); fork();//创建子进程 return 0; }
就上面的两段代码唯一的区别就是在程序结束之前是否创建了子进程。
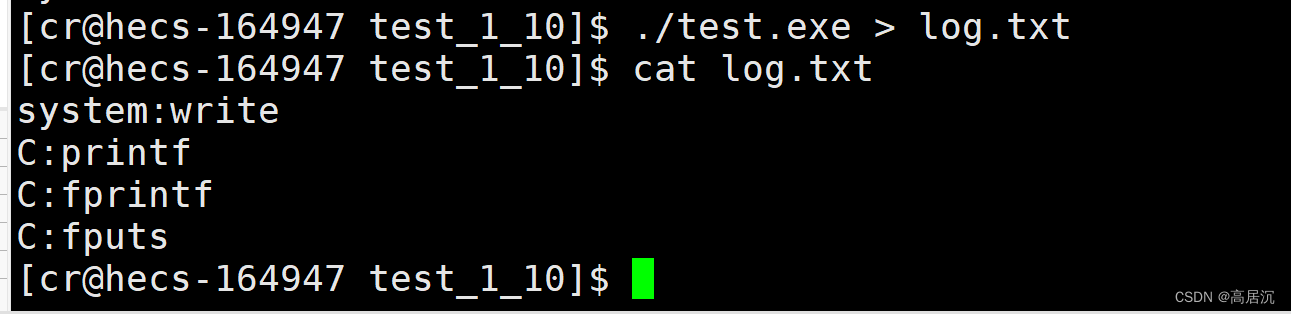
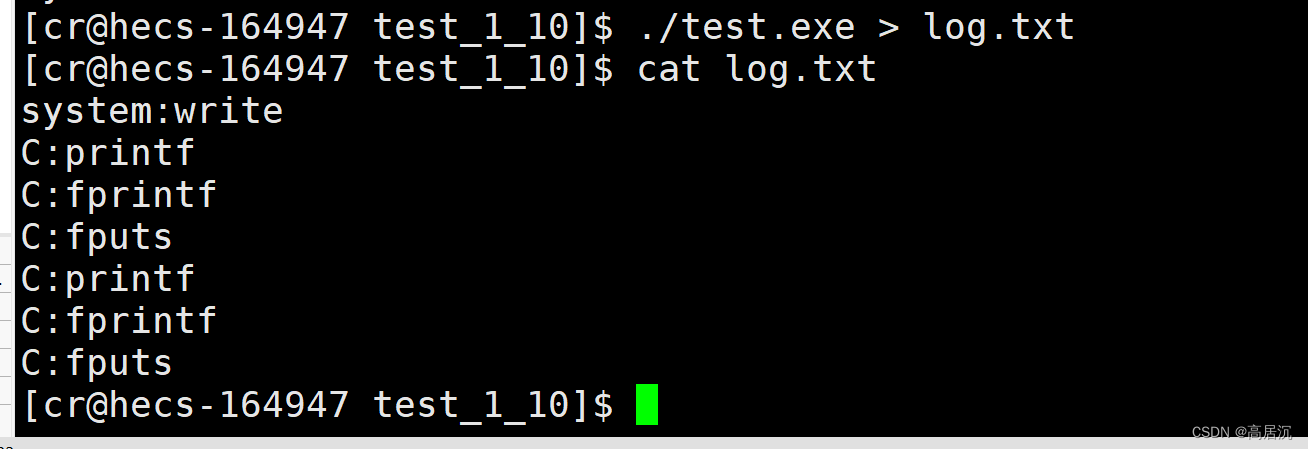
现象就是:代码一没有创建子进程,而且就如我们意想的结果一样正常打印数据到log.txt文件当中,而代码二在打印结束的时候创建了子进程,最终log.txt文件中的数据打印了两份,除了系统调用write函数之外。
其实在我们./test.exe > log.txt 将本应该打印到显示器文件的数据重定向到log.txt文件当中时,就改变了缓冲区的刷新策略,从原先的行数新变成了缓冲区满了再刷新。所以在执行fork函数创建子进程之前的所有数据依旧还是存在缓冲区当中,而创建子进程后,父子进程代码共享,数据采用写时拷贝的方式存在着。当假设父进程先结束退出以后,此时父进程的缓冲区就会被强制刷新(也就是相当于清空缓冲区数据),而此时的子进程必然是会发生写时拷贝,数据独有一份,所以最终子进程退出时缓冲区的数据也会被强制刷新,所以最终数据就有两份了。
而针对于系统调用write函数并不是将数据写进缓冲区当中,而是直接写到操作系统中,因此以上操作就与该函数无关。
?
缓冲区在哪里??
我们知道缓冲区与操作系统无关,所以缓冲区在哪里呢,其实就在FILE的结构体中。
就那我们比较熟悉的函数fflush,该函数的作用是刷新缓冲区,而参数就是FILE*的文件指针,所以此时其实就可以看出端倪了。
FILE其实是一个结构体,我们前面知道FILE结构体当中封装了文件描述符,其实也有缓冲区,其实就是一些指针。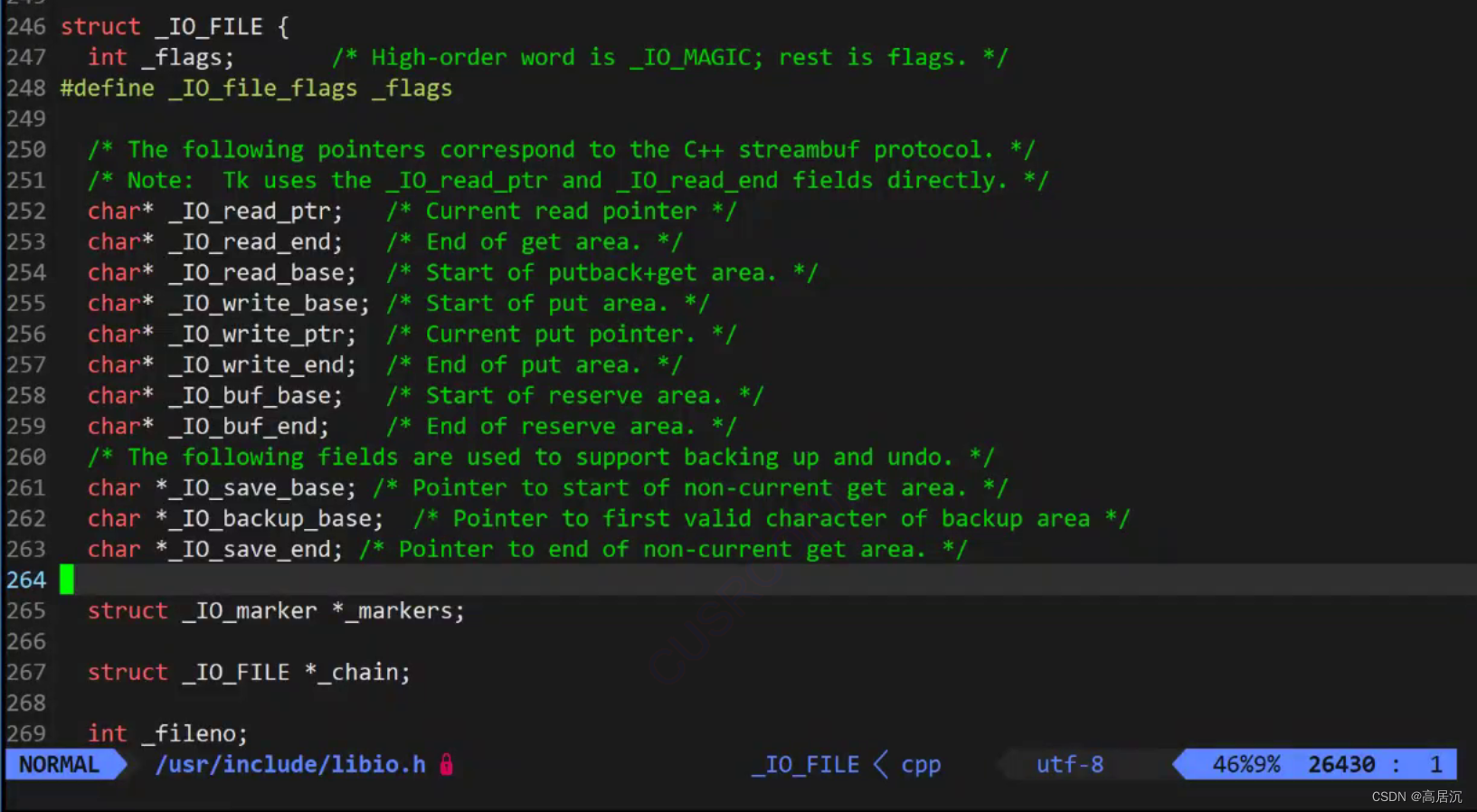
?????????
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 十、Qt 操作PDF文件
- WEB渗透—PHP反序列化(十)
- [Mac软件]PullTube 1.8.5.22视频下载工具
- C++的内存模型,动态内存和智能指针相关总结
- KSO-SAP ABAP调用远程RFC函数详细过程
- el-table嵌套两层el-dropdown-menu导致样式错乱
- TypeScript 二
- 青少年CTF-qsnctf-Web-PingMe02
- 万界星空电机行业MES/电机mes
- 向量数据库的新浪潮:支持向量及标量查询的解决方案