ID3决策树的建模流程
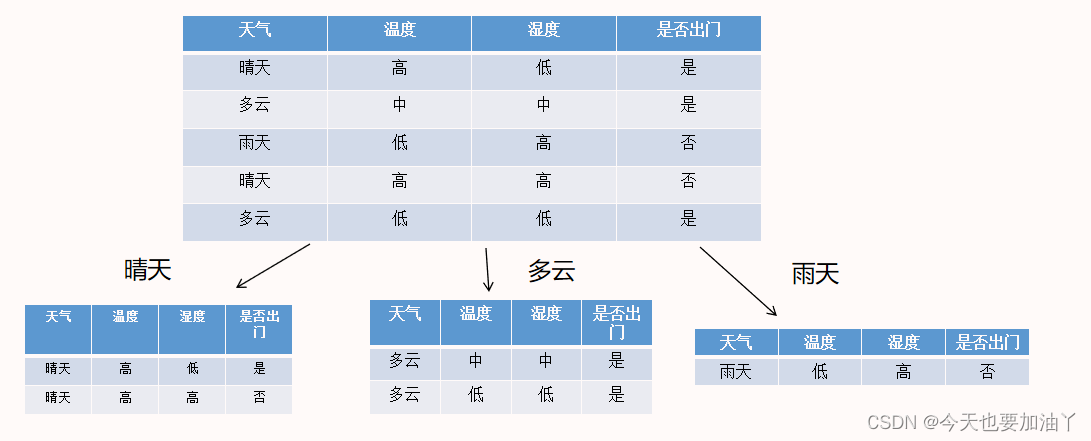
下面以一个简单的数据集,包括了天气、温度、湿度三个特征,以及是否出门的目标变量,来演示ID3决策树的建模流程。
| 天气 | 温度 | 湿度 | 是否出门 |
|---|---|---|---|
| 晴天 | 高 | 低 | 是 |
| 多云 | 中 | 中 | 是 |
| 雨天 | 低 | 高 | 否 |
| 晴天 | 高 | 高 | 否 |
| 多云 | 低 | 低 | 是 |
CART树是按照某切分点来展开,而ID3则是按照列来展开,即根据某列的不同取值来对数据集进行划分。
以天气的不同取值为划分规则
首先计算父节点的信息熵
为了表示方便,[2,3]表示[否的数量,是的数量]
entropy([2,3]) = ? 2 5 ? l o g 2 2 5 ? 3 5 ? l o g 2 3 5 = 0.97 -\frac{2}{5}*log_2\frac{2}{5}-\frac{3}{5}*log_2\frac{3}{5}=0.97 ?52??log2?52??53??log2?53?=0.97
然后计算每个子节点的信息熵
以天气的不同取值为划分规则:
天气=晴天时
entropy([1,1]) =
?
1
2
?
l
o
g
2
1
2
?
1
2
?
l
o
g
2
1
2
=
1
-\frac{1}{2}*log_2\frac{1}{2}-\frac{1}{2}*log_2\frac{1}{2}=1
?21??log2?21??21??log2?21?=1
天气=多云时
entropy([0,2]) = 0
天气=雨天时
entropy([1,0]) = 0
子节点的信息熵加权平均和为:(权重就是各子节点数据集数量占父节点数量)
entropy([1,1],[0,2],[1,0]) = 2 5 \frac{2}{5} 52?*entropy([1,1]) + 2 5 \frac{2}{5} 52?*entropy([0,2])+ 1 5 \frac{1}{5} 51?*entropy([1,0])]= 2 5 \frac{2}{5} 52?*1 + 2 5 \frac{2}{5} 52?*0+ 1 5 \frac{1}{5} 51?*0=0.4
基于天气判断是否出行的信息增益为gain(天气) = 0.97-0.4= 0.5

以温度的不同取值为划分规则:
温度=高时
entropy([1,1]) =
?
1
2
?
l
o
g
2
1
2
?
1
2
?
l
o
g
2
1
2
=
1
-\frac{1}{2}*log_2\frac{1}{2}-\frac{1}{2}*log_2\frac{1}{2}=1
?21??log2?21??21??log2?21?=1
温度=中时
entropy([0,1]) = 0
温度=低时
entropy([1,1]) = 1
子节点的信息熵加权平均和为:
entropy([1,1],[0,1],[1,1]) = 2 5 \frac{2}{5} 52?*entropy([1,1]) + 1 5 \frac{1}{5} 51?*entropy([0,1])+ 2 5 \frac{2}{5} 52?*entropy([1,1])]= 2 5 \frac{2}{5} 52?*1 + 1 5 \frac{1}{5} 51?*0+ 2 5 \frac{2}{5} 52?*1=0.8
基于温度判断是否出行的信息增益为gain(天气) = 0.97-0.8= 0.17

以湿度的不同取值为划分规则:
湿度=高时
entropy([2,0]) = 0
湿度=中时
entropy([0,1]) = 0
湿度=低时
entropy([0,2]) =0
子节点的信息熵加权平均和为:
entropy([2,0],[0,1],[0,2]) = 2 5 \frac{2}{5} 52?*entropy([2,0]) + 1 5 \frac{1}{5} 51?*entropy([0,1])+ 2 5 \frac{2}{5} 52?*entropy([0,2])]= 2 5 \frac{2}{5} 52?*0 + 1 5 \frac{1}{5} 51?*0+ 2 5 \frac{2}{5} 52?*0=0
基于湿度判断是否出行的信息增益为gain(天气) = 0.97-0 = 0.97
选择信息增益最大的为划分规则,即以湿度为划分节点。
Notes:
(1) ID3树根据列来提取规则,每次展开一列会产生分支数量取决于当前列的分类水平,而CART树则只能生成二叉树。
(2) 由于ID3每次展开一列,建模过程中对列的消耗很快,树的最大深度取决于数据集中的特征个数,而CART树则具有更多备选规则,能够提取更精细的规则。
(3) ID3只能处理特征都是离散变量的数据集。此外,ID3更倾向于选择取值较多的分类变量展开,容易导致过拟合,且缺乏防止过拟合的措施,而这些缺陷正是C4.5算法改进的方向。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【C语言题解】【洛谷P1980 计数问题】
- 利用大模型审合同真的可以吗?
- 9 个让你的 Python 代码更快的小技巧
- 黑马程序员——javase基础——day03——循环语句
- 微信闪退怎么回事?本文为你揭晓答案!
- 黑客(网络安全)技术自学——高效学习
- 01详解Gateway服务网关的功能,实现,分类.工作流程
- Golang中记录日志详解
- 华为机试:HJ92 在字符串中找出连续最长的数字串
- 【C++】sizeof()、strlen()、length()、size()详解和区别