集成学习之GBDT算法详解
先说一下提升树(Boosting Decision Tree):通过拟合残差的思想来进行提升,残差 = 真实值 - 预测值,例如:
-
某人年龄为100岁,预测其年龄
-
第一次预测结果为80岁,残差为100-80=20
-
第二次预测以残差20为目标,预测结果为16岁,残差为4
-
第三次预测以残差4为目标,预测结果为3.2,残差为0.8
-
三次结果串联起来预测结果为80+16+3.2=99.2,通过拟合残差可以将多个弱学习器组成一个强学习器
梯度提升树(Gradient Boosting Decisen Tree):梯度提升树不再拟合残差,而是采用类似于梯度下降的方法,利用损失函数的负梯度作为提升树算法中的残差近似值。一句话:把损失函数的负梯度作为下次预测的目标值,把同子树的均值作为预测值,相减作为负梯度。
假设:
-
前一轮迭代得到的强学习器:
-
????????????????????????????????????????????????????????????????????
-
-
损失函数为平方损失:
-
???????????????????????????????????????????????????????????????????
-
-
本轮迭代的目标是找到一个弱学习器:
-
??????????????????????????????????????????????????????????????????????????????????
-
-
本轮的强学习器为:
-
??????????????????????????????????????????????????????????????????????????????????
-
则本轮的损失函数为:
????????????????
则要拟合的负梯度为:
???????????????????????????????????????????????????????????????????????????????????
注:如果GBDT进行的是分类问题,则损失函数变为对数损失。
算法推导案例
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 目标值 | 5.56 | 5.70 | 5.91 | 6.40 | 6.80 | 7.05 | 8.90 | 8.70 | 9.00 | 9.05 |
1. 初始化弱学习器(CART树):把预测值初始化为目标值的均值,可使第一个弱学习器的损失函数最小,证明如下:
? ? ,求平方误差最小,即对损失函数求导,导数为0时,函数最小
? ? ?
? ? 则?可令?
?由以上公式可得,当初始化为均值时,可以使损失函数最小
2. 构建第1个弱学习器,根据负梯度的计算方法得到下表

-
当以1.5为分割点,拟合负梯度为-1.75,-1.61,-1.4,-0.91,…,1.74
-
左子树均值为-1.75,右子树均值为( - 1.61 - 1.40 - 0.91 - 0.51 - 0.26 + 1.59 + 1.39 + 1.69 + 1.74 ) / 9=0.19
-
平方损失:左子树0+右子树(-1.61-0.19)2 + (-1.40-0.19)2 + (-0.91-0.19)2 + (-0.51-0.19)2 +(-0.26-0.19)2 +(1.59-0.19)2 + (1.39-0.19)2 + (1.69-0.19)2 + (1.74-0.19)2 =15.72308
-
-
以次把其它点作为分割点,并求损失函数
-

 ?
?
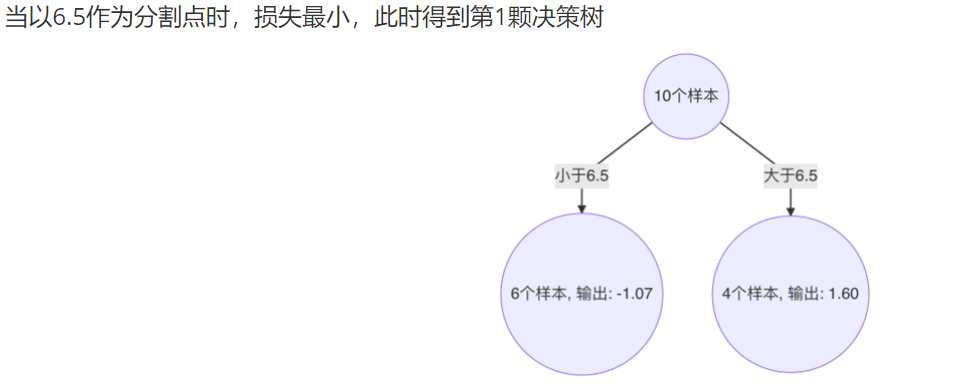
3. 构建第2个弱学习器,以3.5 作为切分点时,平方损失最小,此时得到第2棵决策树



API
# 1 初始化弱学习器(目标值的均值作为预测值)
# 2 迭代构建学习器,每一个学习器拟合上一个学习器的负梯度
# 3 直到达到指定的学习器个数
# 4 当输入未知样本时,将所有弱学习器的输出结果组合起来作为强学习器的输出
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import GridSearchCV, train_test_split
import pandas as pd
titanic_df = pd.read_csv('titanic/train.csv')
X = titanic_df[['Pclass','Age','Sex']]
y = titanic_df['Survived']
# 性别编码
X = pd.get_dummies(X)
# 年龄进行缺失值填充
X['Age'].fillna(X['Age'].mean(),inplace = True)
# 训练集测试集划分
X_train, X_test, y_train, y_test = train_test_split(X,y,stratify=y,random_state=66)
gboost_classifier = GradientBoostingClassifier()
parmas = {"n_estimators": [50,100,150], "max_depth": [2,3,5,8,10],'learning_rate':[0.1,0.3,0.5,0.7,0.9]}
# 交叉验证和网格搜索 寻找最优的超参数组合
gs_estimator = GridSearchCV(gboost_classifier,param_grid=parmas,cv=4)
gs_estimator.fit(X_train,y_train)本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JSON 简介
- [AutoSar]BSW_OS 08 Autosar OS_内存保护
- RocketMQ系统性学习-RocketMQ高级特性之文件恢复与 CheckPoint 机制
- YOLOv5改进 | 主干篇 | SwinTransformer替换Backbone(附代码 + 修改步骤)
- 计算机组成原理 01:计算机的发展历程
- 在Linux系统中已经可用的重要的网络和故障排除命令
- 【动态壁纸】推荐
- LeetCode 1531. 压缩字符串 II【动态规划】2575
- MyBatis Plus wrapper A and (B or C or D)
- Xilinx MicroBlaze 告警提示解决方案