JVM垃圾回收面试知识点
哪些是垃圾? == 标记阶段 (对象存活判断)==
引用计数算法
每个对象保存一个整型的引用计数器属性,只要有一个对象引用了,则该引用计数器就会加1,反之减1,最终为0的计数器对象会被标记为垃圾。
优点:判定效率高,几乎没有延迟
缺点:空间开销(单独字段存储)、时间开销(计数器加减法操作)、不能解决循环引用问题
循环引用问题-->存在多个对象互相引用的,计数器不为0。
Java垃圾回收器没有采用这种算法。Python会使用,但是Python怎么去解决呢?1.手动解除 2.使用弱引用weakref
可达性分析算法
GC Roots:(小技巧:如果一个指针,它保存了堆内存里面的对象,但是自己又不存放在堆内存中,那它就是一个Root)
-
虚拟机栈中的对象--参数、局部变量等
-
本地方法栈中的对象--本地方法JNI
-
方法区中类静态属性引用的对象、常量引用对象(String Table)
-
synchronized持有的对象。。。
从GC Roots为起始点,从上至下是否可以被搜索到。搜索过的路径成为引用链。
对象的finalize机制:
触发GC的垃圾回收之前会调用finalize方法,不要主动调用,应该交给GC去调用。
-
finalize()可能会导致对象复活
-
完全由GC去决定要不要执行finalize()方法,若不发生GC,则永远没有机会执行
-
一个糟糕的finalize()会让GC更糟糕
Root根可达(可触及的)--------反之不可达(缓刑)===finalize方法(复活(可复活状态)/不复活(不可触及阶段))
怎样去会收垃圾?==清除阶段Mark-Sweep==
============================ 标记-清除算法 ===========================
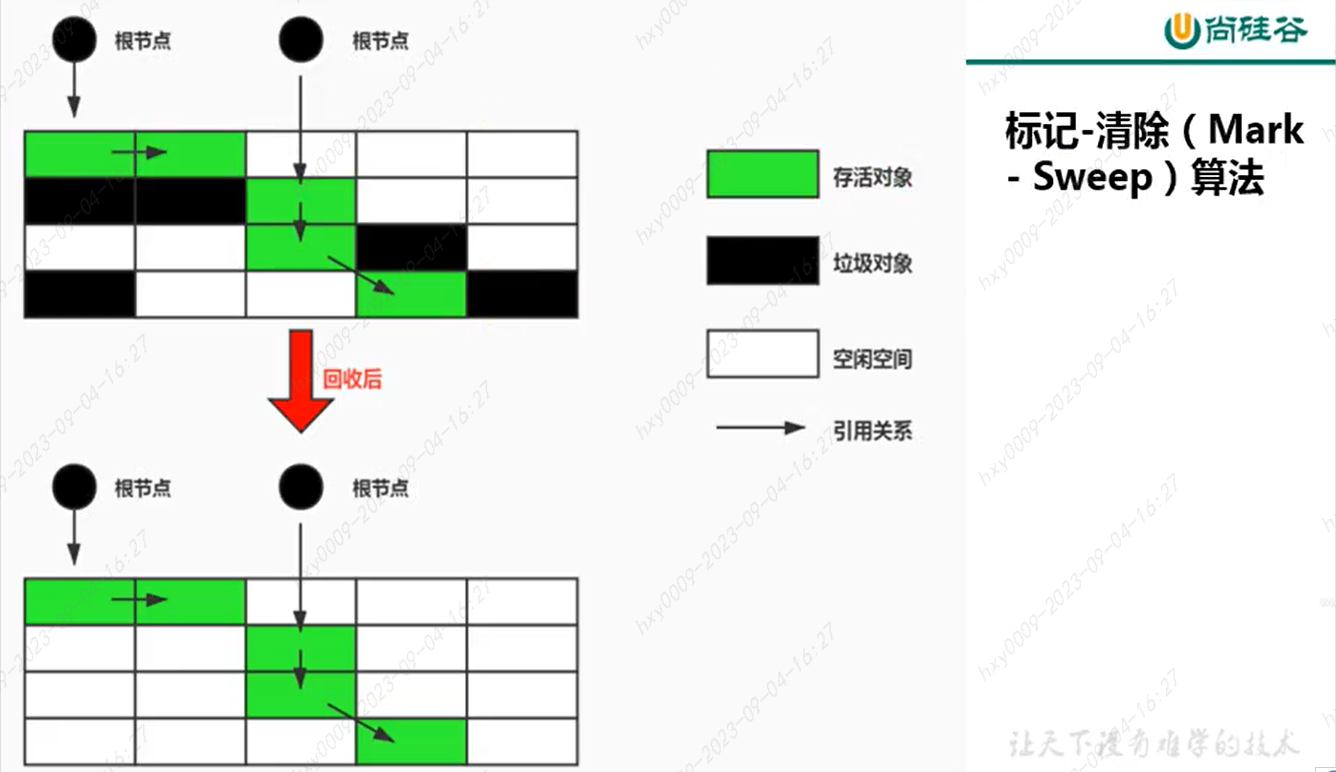
缺点:效率不高、进行GC会产生STW、空间内存不连续,产生内存碎片,需要维护一个空闲列表(对象:空间规整--指针碰撞,空间不规整--需要进行空闲列表分配)
清除:并不是直接把垃圾对象清除,会把其放在空闲列表中
========================= 复制算法Copying ===========================
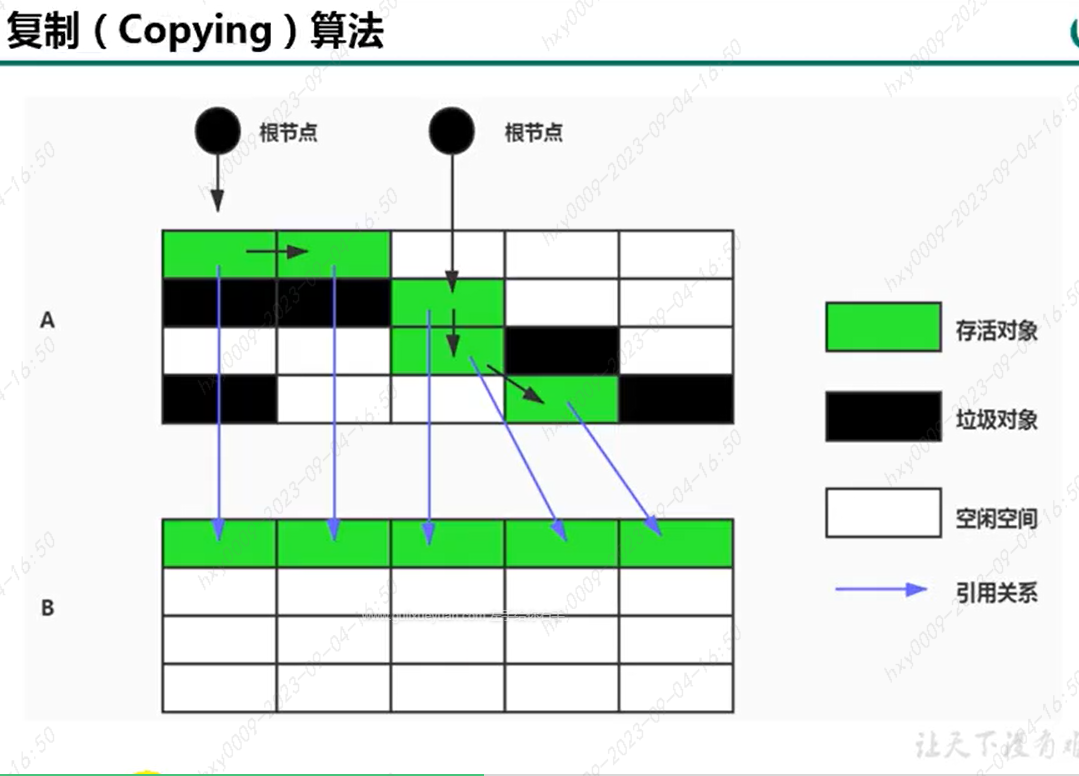
优点:没有标记和清除的过程--简单高效、复制过去,空间连续,不会出现碎片化问题。
缺点:两倍空间、复制需要维护region的对象和引用,内存占用和时间开销都不小。百分百复制则效率更低,适用于存活的对象并不是太多,所以很适用于年轻代的YGC。
===================== 标记-压缩算法Mark-Compact ======================
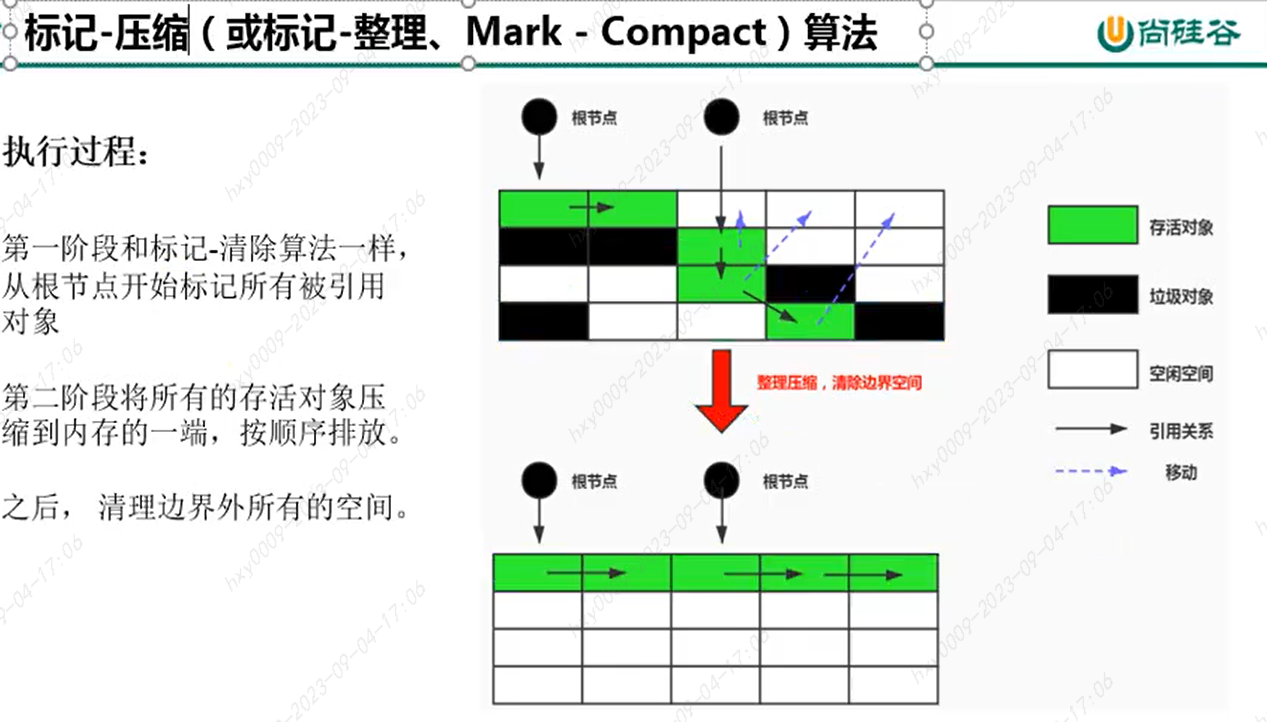
类似于:标记--清除--压缩,会在标记清除后执行一次压缩(碎片整理)
优点:解决另外两个算法,碎片化,内存减半的问题
缺点:效率比较低、全部暂停用户线程STW、整理过程中需要调整引用的地址。
内存溢出(OOM)== GC后才OOM
垃圾回收和内存消耗速度的平衡--失衡就会出现OOM
-
没有空闲内存
-
存在内存泄露问题,例如买房子的公摊。。。
-
堆的大小设置不合理,-Xms,-Xmx来调整
-
-
代码中创建大量的大对象,并且生命周期较长,不能被GC(被引用),例如老版本的常量池在永久代中,GC不积极
-
超大对象,也可导致不GC,直接OOM
内存泄露(Memory Leak)
严格意义:对象不会被程序应用,但是GC又不能回收它们的情况,买房子的公摊。。。
忘记断开的指针引用会导致一定量的不会用到的对象不会被回收
-
单例模式中,生命周期和应用程序一样长,如果引用外部对象,则这个外部对象不会被回收
-
数据库(dataSource)连接、IO连接需要手动关闭,否则不会被回收
强、软、弱、虚(Reference)引用的区别?使用场景?
-
强引用:死也不会收(99%的情况下都是,new)--造成Java内存泄露的主要原因
-
软引用:内存不足才回收(使用内存敏感的缓存的场景下,相比弱引用来说--不快,需要经过内存算法计算)
-
弱引用:只要下次GC就回收(使用内存敏感的缓存的场景下)
-
虚引用:GC回收跟踪
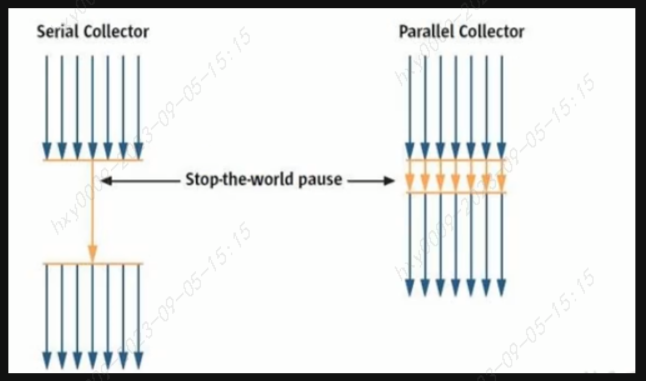
垃圾回收器(绿色--用户线程,红色--垃圾回收线程)

-
按照线程数划分
-
串行垃圾回收器:同一时间段只允许一个cpu用于执行垃圾回收操作,此时垃圾线程被暂停,直至垃圾收集工作结束
-
并行垃圾回收器:多个cpu同时执行垃圾回收,提升了应用的吞吐量,不过并行回收和串行回收一样,采用独占式,使用了STW机制
-
-
按照工作模式划分
-
并发式垃圾回收器:并发式垃圾回收器与应用程序交替工作,以尽可能减少应用程序的停顿时间
-
独占式垃圾回收器:独占式垃圾回收器(STW)一旦运行,就需要停止应用程序中的所有用户线程,直到垃圾回收过程完全结束为止
-
-
按照碎片处理方式划分
-
压缩式垃圾回收器:垃圾回收后对碎片进行回收,对象进行整理
-
非压缩式垃圾回收器:垃圾回收后不进行碎片的压缩整理工作
-
-
按照工作的内存区间划分
-
年轻代垃圾回收器
-
老年代垃圾回收器
-
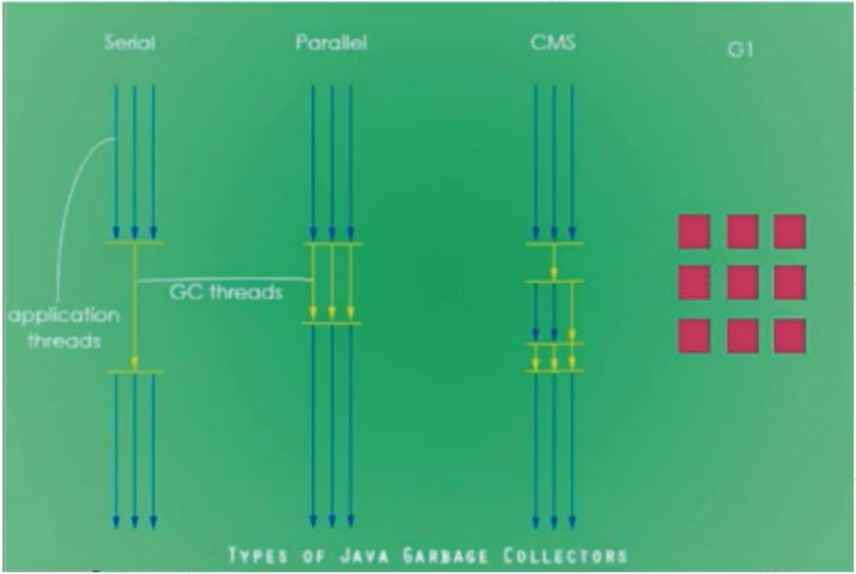
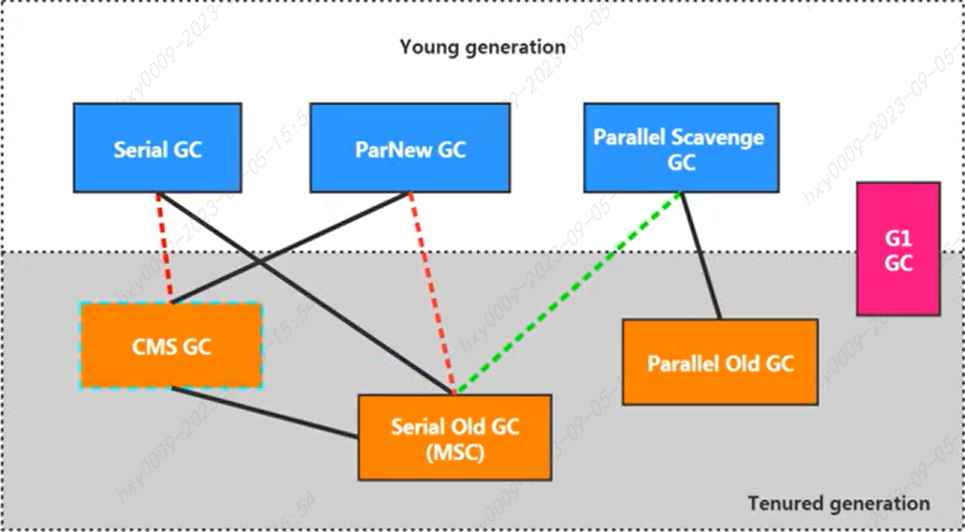
串行回收器:Serial(新生代)、Serial Old(老年代) 并行回收器:ParNew(新生代)、Parallel Scavenge(新生代,吞吐量优先)、Parallel Old(老年代,吞吐量优先) 并发回收器:CMS(老年代,低延迟,第一个标记-清除算法)、G1(既可以回收新生代又可以回收老年代)
评估GC的性能指标(不可能三角)
| 性能指标 | 内容 |
|---|---|
| ★吞吐量★ | 指的是运行用户代码的时间占总运行时间的比例(总运行时间 = 程序的运行时间 + 内存回收的时间) |
| ★暂停时间★ | 执行垃圾收集时,程序的工作线程被暂停的时间 |
| 垃圾收集开销 | 吞吐量的补数,垃圾收集所用时间占总运行时间的比例 |
| 垃圾收集频率 | 相对于应用程序的执行,收集操作发生的频率 |
| ★内存的占用★ | Java堆区所占的内存大小 |
| 快速 | 一个对象从诞生到被回收所经历的时间 |
CMS GC执行垃圾回收的过程:
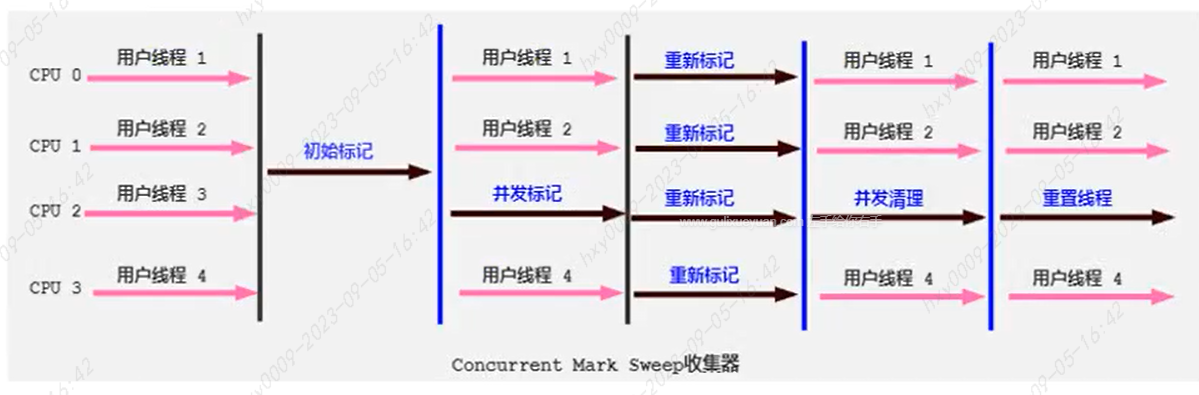
| 步骤 | 具体内容 |
|---|---|
| 初始标记阶段 | 在此阶段,程序的所有的工作线程会因为“Stop-The-World”机制而出现短暂的暂停(此时停顿第一次),这个阶段的主要任务仅仅只是标记出GC Roots能关联到的对象。一旦标记完成,就会恢复之前被暂停的所有的应用线程。由于直接关联的对象比较的小(因为此时在老年代中进行垃圾回收,能被GC Roots标记到的对象很少),所以这里的速度会很快!! |
| 并发标记阶段 | 从GC Roots的直接关联对象开始遍历整个对象图,这个过程耗时比较长,但是不需要停顿用户线程,可以与垃圾收集收集线程一起并发运行 |
| 重新标记阶段 | 由于在并发标记阶段中,程序的工作线程一一直在运行过程中 ,可能会由于和垃圾的收集线程交叉运行导致之前的一些标记会发生一些变动,故进行标记的修正,这个过程比初始标记略长(STW,此时停顿第二次),但比并发标记的时间要短很多 |
| 并发清除阶段 | 此阶段清理删除掉标记阶段已被判断为已经死亡的对象,并释放内存空间,由于不需要移动内存对象的位置,则此阶段也是可以和用户线程同时并发执行的 |
CMS的缺点:
-
由于回收线程和用户线程是并发执行的,所以整体的回收是低停顿的
-
CMS不会内存满了才进行GC(达到一定阈值),所以工作过程中需要预留足够的空间,不足则会Concurrent Mode Failure失败,再启用备用的串行Serial Old收集器(优点:可以用SO的标记压缩算法)
-
标记-清除算法会产生内存碎片,维护空闲列表
G1---区域化分代式(大内存更具优势)==多个GC线程并行,GC线程和用户线程并发==
G1采用全新的分区算法,并行与并发、分代算法、以region之间是复制算法,整体上是标记-压缩算法
可预测的停顿时间模型:G1除了低停顿,选取部分区域进行内存回收,评估价值在后台维护一个优先列表,优先回收价值最大的Region
G1的缺点:需要占用额外的10%-20%的内存空间(记忆集)
解决分代之间的引用,避免Old的全局扫描(记忆集-一个用于记录引用对象的集合)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!