主键(设置/删除方法,复合主键),唯一键,主键和唯一键的应用差异,自增长字段(如何实现,查看上次的值),外键(引入,外键约束)
目录
主键(primary key)
介绍
格式为 primary key
- 主键列的数据不可重复,不可为空(也就是自动设置为not null)
- 一张表中最多只能有一个主键
- 主键所在的列通常是整数类型
作用
可以作为某行数据的唯一标识符,然后进行增删查改(利用where)
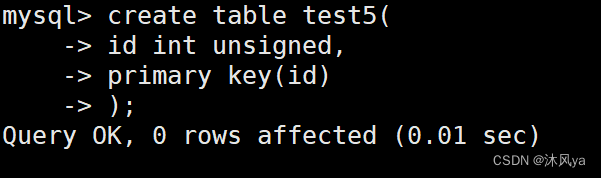
设置主键
建表前
在属性列设置中添加
单独一行添加 primary key (属性列名)
被设置主键的列中,key会被设置为pri:

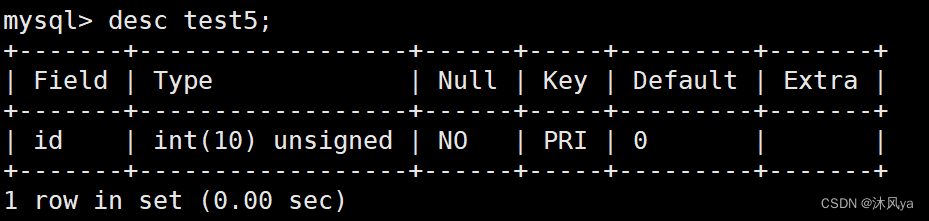
建表后
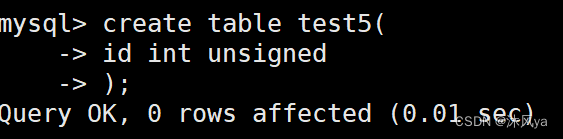
alter table 表名 add primary key(属性列名)建表后设置主键,需要保证该列属性没有重复,才能设置:
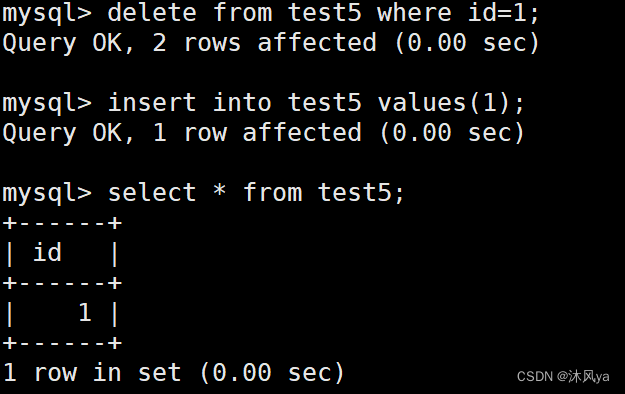
- 我们重新建立一张没有主键的表:
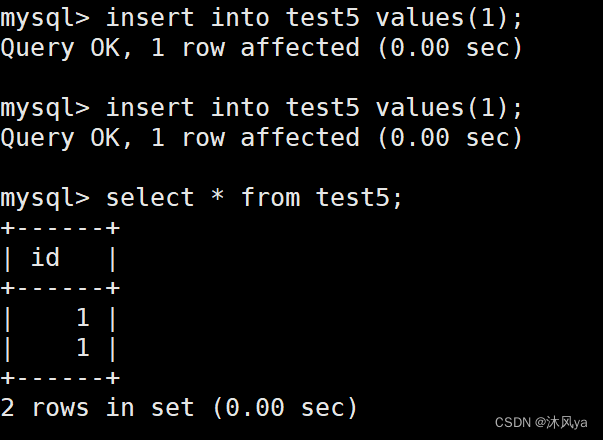
- 并且插入相同数据:
- 然后我们设置id为主键,会发现mysql并不允许,因为id列存在重复数据:
- 所以我们需要先删除重复数据,然后重新插入:
- 之后我们再次设置id为主键,就成功了:


复合主键
介绍
一张表只有一个主键,但一个主键可以被添加到多列
格式 primary key (属性列名1 , 属性列名2 ...)
- 它用于将设置为主键的属性列的数据绑定在一起,让这个绑定后的数据不会重复出现
- 换句话说,只有当这几列的数据同时重复,才不被允许
- 其中某列重复,是可以的
示例?
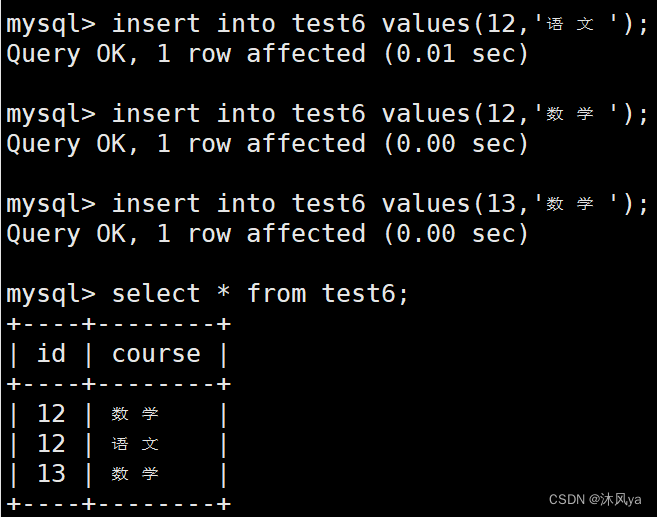
我们设置一个选课的场景
选课的时候,我们可以一个人选多门课,多个人选一门课,但并不允许一个人重复选同一门课
所以我们可以将人和课作为复合主键,来规避这样的问题:
- 根据复合主键的特性,以下数据都是合法的:
- 但是,他不允许出现同时重复:


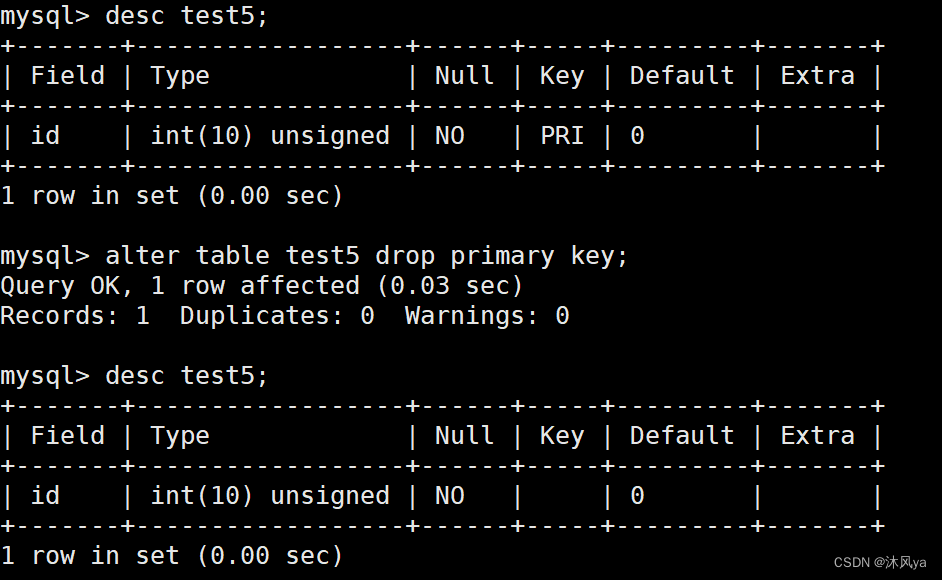
删除主键
alter table + 表名 + drop primary key因为每张表只有一个主键,所以直接对表进行删除主键即可
唯一键(unique)
介绍
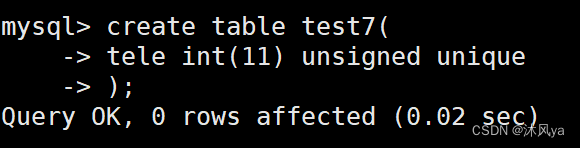
格式 unique (key)
和主键一样,数值不能重复?
但它可以为空,其中空字段不作唯一性比较,所以可以多个为空
意义
也许你可能会好奇,为什么有了主键,还需要有唯一键呢?
- 虽然一张表中只能有一个主键,但是,不仅只有选择设置为主键的属性需要保证唯一性,其他属性可能也会有这样的需求
- 唯一键就是为了实现这个功能
示例
建表
和主键使用基本相同(唯一不同就是,唯一键可以省略key,但主键不行)
主键
唯一键


和主键一样,除了可以在属性列中设置唯一键,也可以单独一行设置(且可以省略key):

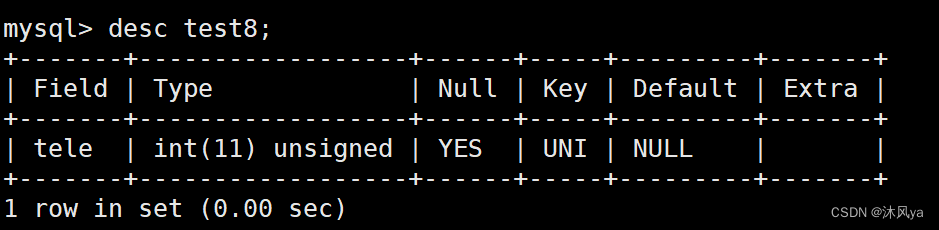
设置唯一键后:
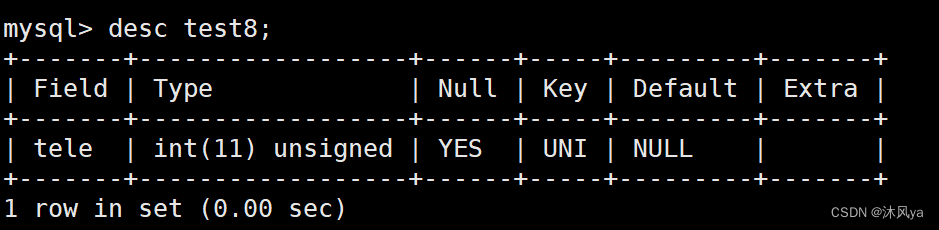
插入数据示例
因为它可以为null,所以可以省略该列,默认值为null:
当然也可以手动插入null:
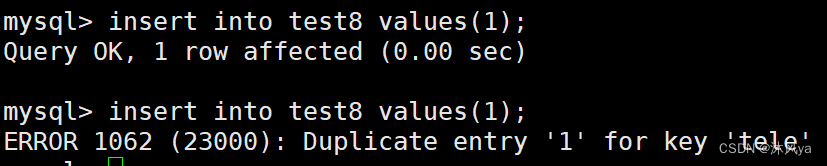
唯一限制就是不能重复:

?
主键和唯一键的应用差异
主键
- 更多的是用来标识该行数据在整张表中的唯一性
- 比如id,身份证,学号等等,用来表示这行数据属于谁
- 且尽量让主键和当前业务无关,这样在进行业务调整时,可以保证尽量不调整主键
唯一键
- 只是为了保证该列数据不出现重复
- 比如,电话号码,身份证等等
- 当这些属性不是主键,但需要保证唯一性时,就需要设置为唯一键
索引
MySQL 索引是一种数据结构,用于提高数据库查询性能
- 索引类似于书籍的目录,通过在数据表中创建索引,可以更快地定位和检索数据
- 比如我们上面介绍的主键和唯一键,都属于索引
- 这里我们仅仅简单提一下,之后会详细介绍
auto_increment
介绍
可以自己增加数值,不需要我们手动插入
- 自增长字段必须是整数类型
- 要做自增长的属性,必须是索引(key一栏有值),一般和主键搭配使用
- 和主键一样,一张表只能有一个自增长
- 默认从1开始
示例?
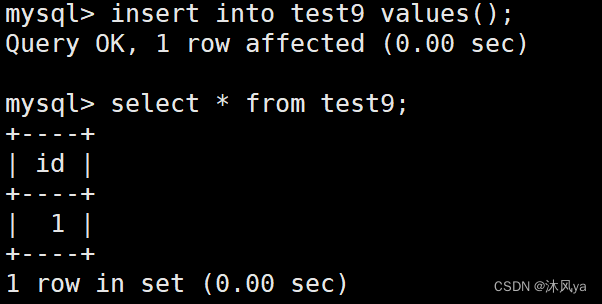
我们先建立一张表,且id属性设置为主键,自增长:

自动插入
即使我们不插入数值,它也会自动从1开始:
再次无数值插入,id自增为2:
如果我们插入非法数值:
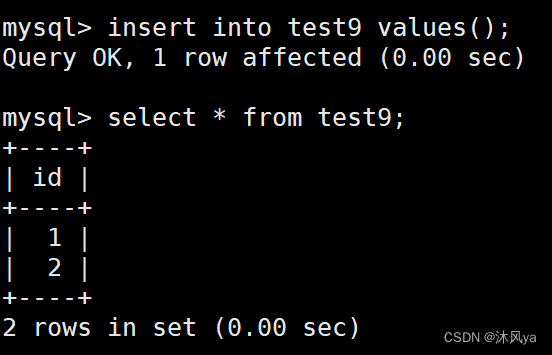
手动插入
也可以手动插入数据:
然后进行无数值插入,会发现这一次自增是从10开始的:
所以,我们可以得出一个结论 --?新的数值=最后一个数值+1
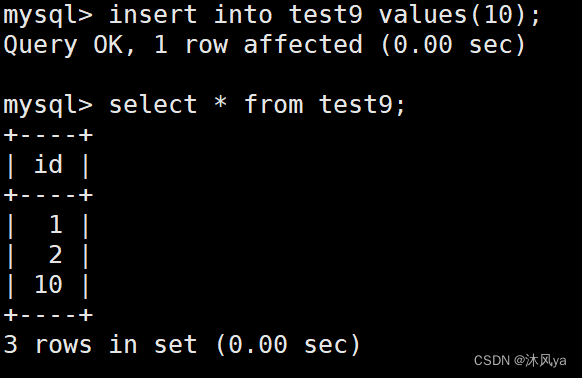

?
如何实现自增
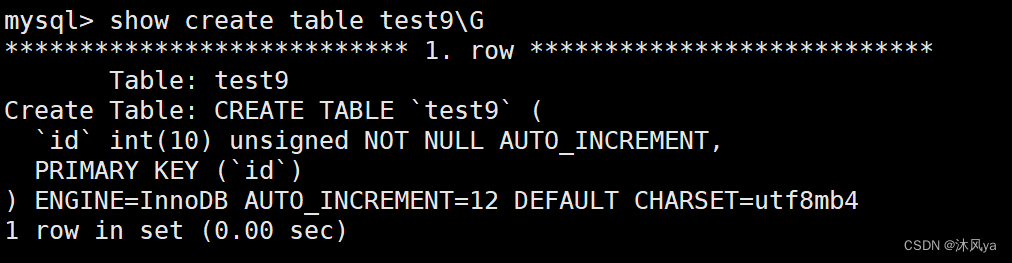
实际上,表外有一个字段auto_increment,用于存放当前的auto_increment值+1
我们可以通过查看建表语句看到,此时该值为12:
恰好上一次id自增成了11:
所以我们可以发现,其实每次改变的都是表外的字段,然后这个值会作为下一次插入数据时auto_increment的起始值,这样就实现了自增

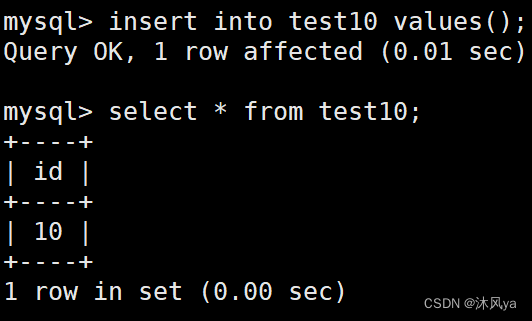
手动设置初始值
介绍
可以在建表时,手动设置auto_increment的初始值
格式 (建表语句)auto_increment=xx;
示例
我们设置10为初始值:

last_insert_id()
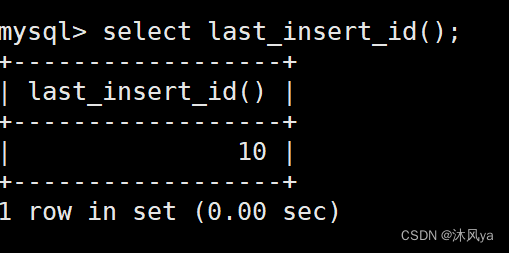
last_insert_id() 可以获取最后一次插入时的auto_increment值
比如,我们在上面的最后一次插入操作中,id=10,他就返回了10:
外键
引入
介绍
外键用于建立两张表之间的联系
外键是从表中的一个属性,主表提供从表所需的信息
从表依附于主表
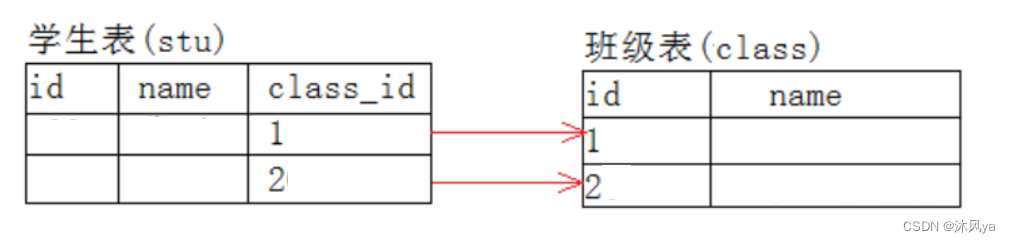
- 比如学生依附于班级
- 在插入学生信息前,班级信息就得存在了
问题示例
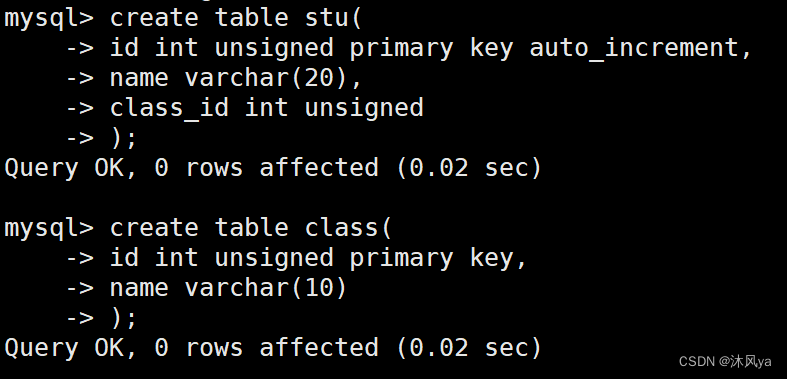
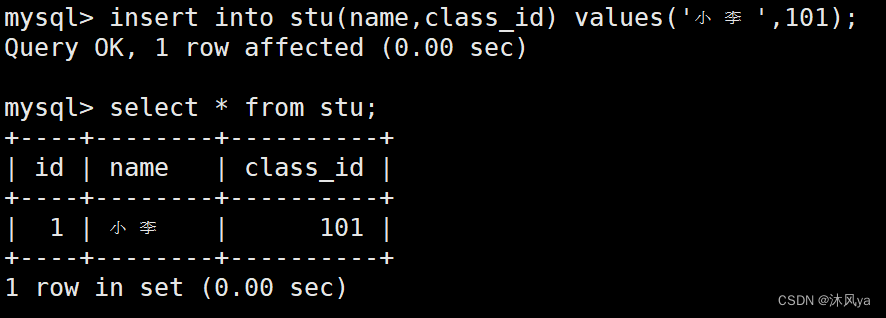
我们创建两张表,学生表和班级表:
我们想让学生表中的class_id和班级表的id是相同的,这样就建立起了联系:
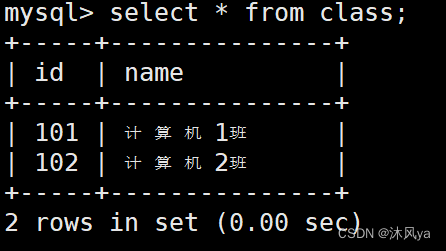
- 首先完善好班级表:
- 然后插入学生信息:
- 但是我们无法规避一些错误:
分析
- 当我们插入并不存在的班级id时,mysql并没有提示我们,因为它是合法的; 但从逻辑上来说是错误的
- 因为此时我们建立的联系并不完整,看似建立了联系,实际上根本没有
解决
- 所以,我们需要一些约束,来帮助我们建立联系 -- 也就是外键约束
- 就像道德和法律的关系,道德的约束虚无缥缈,我们需要强硬的法律手段来维护公平正义

?
外键约束
介绍
用于建立表与表之间关系的一种约束
- 格式?foreign key (外键列名) references 关联的主表名?(关联的列名)
作用
- 外键字段的数值,必须在主表的主键列中存在
- 删除主表中的数据时,从表中不能还存在与其对应的数据
这都是为了保证数据的完整性,维护它们的对应关系
示例
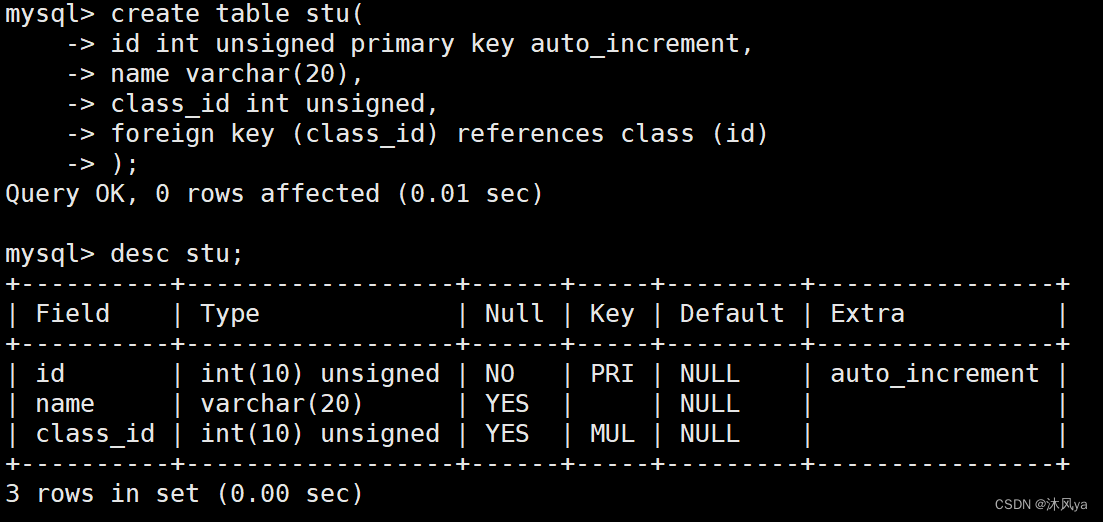
我们首先删除原先的std表,然后创建新表:
可以看到,设置为外键的列,其key列为MUL
然后我们向学生表插入数据:
这次插入110班(不存在的班级),就插入失败了

?
不同错误导致自增长字段处理不同
在进行操作的时候,我发现,发生外键错误,id会自增
而其他错误(比如,一个not null属性的name,不提供值,id不会自增)
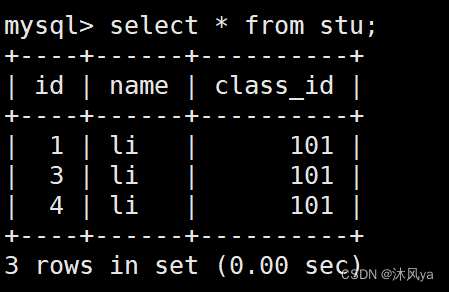
在发生外键错误前后,插入正确值:
在发生默认值错误后,插入正确值:
这样操作后的表:
很明显在发生外键错误的中间,id出现了断层
但是我不明白,为什么不同的错误会有差异,先搁置在这吧(瘫倒)


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vue3 中使用 Vuex 和 Pinia 对比之 Vuex的用法
- 进程内协同:原子操作、互斥、同步和通信的原理
- OpenGL Assimp加载各类型模型(.obj、.fbx、.glb、.3ds)
- Java基础语法(持续更新中......)
- 鸿鹄云商B2B2C:JAVA实现的商家间直播带货商城系统概览
- WINDOW系统添加IP黑名单
- 1135. 新年好 (Dijkstra,dfs枚举)
- 数据结构学习 jz43 数字 1 的个数
- WPF+Halcon 培训项目实战(6):目标匹配助手
- 代码随想录27期|Python|Day29|回溯算法|491.递增子序列|46.全排列|47.全排列 II