深度学习目标检测(2)yolov3设计思想
YOLOv3基础
YOLOv3算法基本思想可以分成两部分:
- 按一定规则在图片上产生一系列的候选区域,然后根据这些候选区域与图片上物体真实框之间的位置关系对候选区域进行标注。跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置作为正样本的位置目标。偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别。
- 使用卷积神经网络提取图片特征并对候选区域的位置和类别进行预测。这样每个预测框就可以看成是一个样本,根据真实框相对它的位置和类别进行了标注而获得标签值,通过网络模型预测其位置和类别,将网络预测值和标签值进行比较,就可以建立起损失函数。
? ? ? ? YOLOv3算法预测过程的流程图如下,预测图片经过一系列预处理(resize、normalization等)输入到YOLOv3模型,根据预先设定的Anchor和提取到的图片特征得到目标预测框,最后通过非极大值抑制(NMS)消除重叠较大的冗余预测框,得到最终预测结果。

YOLOv3网络结构大致分为3个部分:Backbone、Neck、Head:
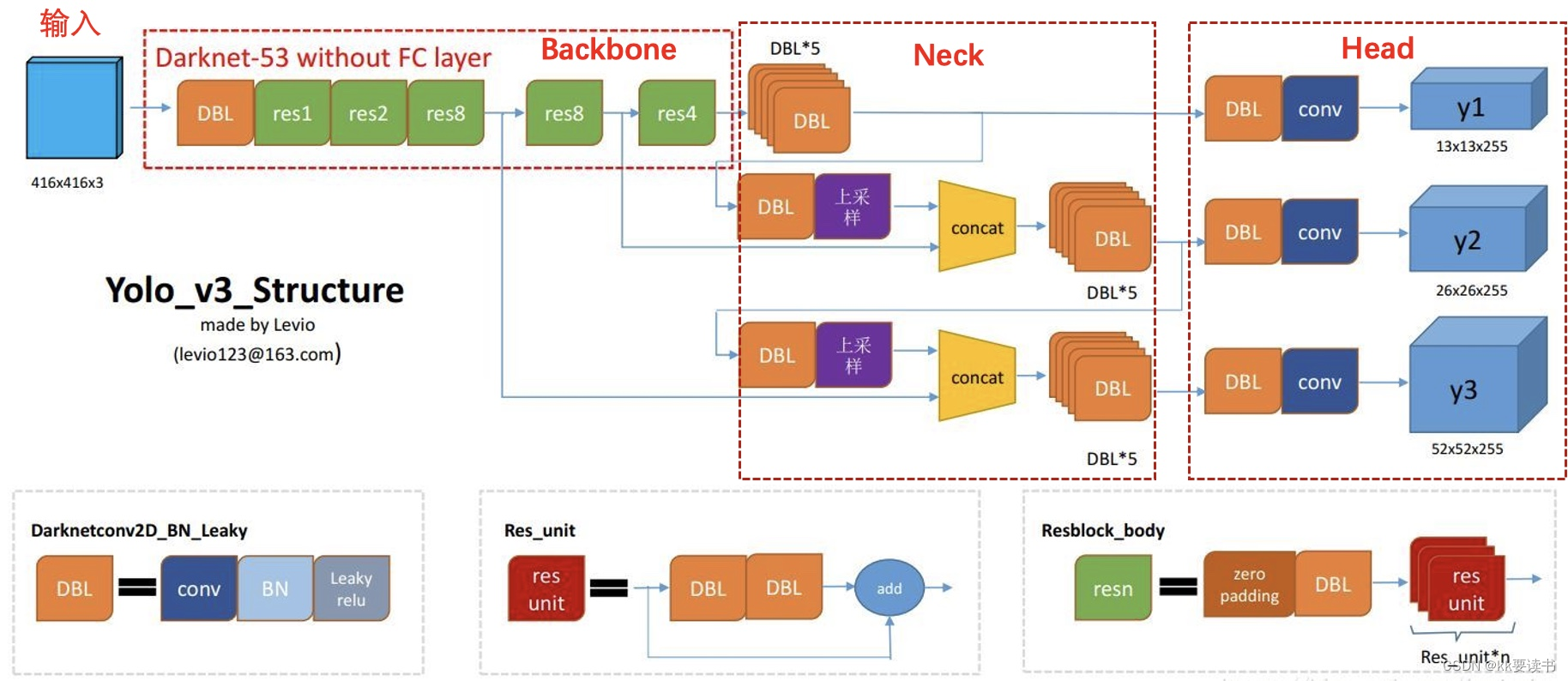
- Backbone:骨干网络,主要用于特征提取
- Neck:在Backbone和Head之间提取不同阶段中特征图
- Head:检测头,用于预测目标的类别和位置
产生候选区域
? ? ? ?如何产生候选区域,是检测模型的核心设计方案。目前大多数基于卷积神经网络的模型所采用的方式大体如下:
- 按一定的规则在图片上生成一系列位置固定的锚框,将这些锚框看作是可能的候选区域。
- 对锚框是否包含目标物体进行预测,如果包含目标物体,还需要预测所包含物体的类别,以及预测框相对于锚框位置需要调整的幅度。
生成锚框
? ? ? ? 将原始图片划分成m×n个区域,如下图所示,原始图片高度H=640, 宽度W=480,如果我们选择小块区域的尺寸为32×3232×32,则m和n分别为:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?m=32640?=20
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?n=32480?=15
? ? ? ? ? ? ? ? ? ? ? ? ? ??
YOLOv3算法会在每个区域的中心,生成一系列锚框。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
在每个区域附近都生成3个锚框,很多锚框堆叠在一起可能不太容易看清楚,但过程跟上面类似,只是需要以每个区域的中心点为中心,分别生成3个锚框。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
生成预测框
在前面已经指出,锚框的位置都是固定好的,不可能刚好跟物体边界框重合,需要在锚框的基础上进行位置的微调以生成预测框。预测框相对于锚框会有不同的中心位置和大小,采用什么方式能得到预测框呢?我们先来考虑如何生成其中心位置坐标。
比如上面图中在第10行第4列的小方块区域中心生成的一个锚框,如绿色虚线框所示。以小方格的宽度为单位长度,
此小方块区域左上角的位置坐标是:
? ? ? ? ? ? ? ? cx?=4
? ? ? ? ? ? ? ? cy?=10
此锚框的区域中心坐标是:
? ? ? ? ? ? ? center_x=cx?+0.5=4.5
? ? ? ? ? ? ? center_y=cy?+0.5=10.5
可以通过下面的方式生成预测框的中心坐标:
? ? ? ? ? ? ? by?=cy?+σ(ty?)
其中tx?和ty?为实数,σ(x)是我们之前学过的Sigmoid函数,其定义如下:
? ? ? ? ? ? ? σ(x)=1+exp(?x)1?
由于Sigmoid的函数值在0~10~1之间,因此由上面公式计算出来的预测框的中心点总是落在第十行第四列的小区域内部。
当tx?=ty?=0时,bx?=cx?+0.5,by?=cy?+0.5,预测框中心与锚框中心重合,都是小区域的中心。
锚框的大小是预先设定好的,在模型中可以当作是超参数,下图中画出的锚框尺寸是
? ? ? ? ? ? ? ?ph?=350
? ? ? ? ? ? ? ?pw?=250
通过下面的公式生成预测框的大小:
? ? ? ? ? ? ? bh?=ph?eth?
? ? ? ? ? ? ? bw?=pw?etw?
如果tx?=ty?=0,th?=tw?=0,则预测框跟锚框重合。
如果给?,ty?,th?,tw?随机赋值如下:
? ? ? ? ? ? ? ?=?0.12tx?=0.2,ty?=0.3,tw?=0.1,th?=?0.12
则可以得到预测框的坐标是(154.98, 357.44, 276.29, 310.42)

对候选区域进行标注
真实框的中心点坐标是:
? ? ? ? ? ? ? ? ? ? center_x=133.96
? ? ? ? ? ? ? ? ? ? center_y=328.42
? ? ? ? ? ? ? ? ? ? 5=133.96/32=4.18625
? ? ? ? ? ? ? ? ? ? j=328.42/32=10.263125
它落在了第10行第4列的小方块内,如下所示。此小方块区域可以生成3个不同形状的锚框,其在图上的编号和大小分别是(373,326)A1?(116,90),A2?(156,198),A3?(373,326)。

用这3个不同形状的锚框跟真实框计算IoU,选出IoU最大的锚框。这里为了简化计算,只考虑锚框的形状,不考虑其跟真实框中心之间的偏移,具体计算结果如 下

其中跟真实框IoU最大的是锚框3?,形状是(373,326)(373,326),将它所对应的预测框的objectness标签设置为1,其所包括的物体类别就是真实框里面的物体所属类别。
依次可以找出其他几个真实框对应的IoU最大的锚框,然后将它们的预测框的objectness标签也都设置为1。这里一共有20×15×3=90020×15×3=900个锚框,只有3个预测框会被标注为正。
由于每个真实框只对应一个objectness标签为正的预测框,如果有些预测框跟真实框之间的IoU很大,但并不是最大的那个,那么直接将其objectness标签设置为0当作负样本,可能并不妥当。为了避免这种情况,YOLOv3算法设置了一个IoU阈值iou_threshold,当预测框的objectness不为1,但是其与某个真实框的IoU大于iou_threshold时,就将其objectness标签设置为-1,不参与损失函数的计算。
所有其他的预测框,其objectness标签均设置为0,表示负类。
对于objectness=1的预测框,需要进一步确定其位置和包含物体的具体分类标签,但是对于objectness=0或者-1的预测框,则不用管他们的位置和类别。

Backbone(特征提取)
? ? ? ?在检测任务中,将图中C0后面的平均池化、全连接层和Softmax去掉,保留从输入到C0部分的网络结构,作为检测模型的基础网络结构,也称为骨干网络。YOLOv3模型会在骨干网络的基础上,再添加检测相关的网络模块。
? ? ? ? ? ? ? ? ???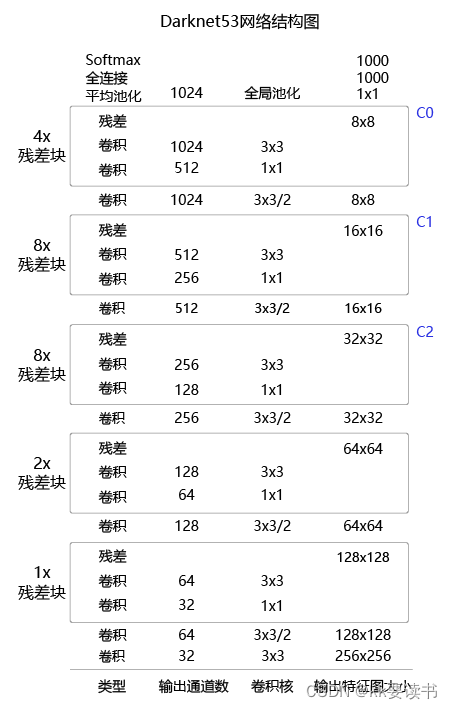
下面的程序是Darknet53骨干网络的实现代码,这里将上图中C0、C1、C2所表示的输出数据取出,并查看它们的形状
import paddle
import paddle.nn.functional as F
import numpy as np
class ConvBNLayer(paddle.nn.Layer):
def __init__(self, ch_in, ch_out,
kernel_size=3, stride=1, groups=1,
padding=0, act="leaky"):
super(ConvBNLayer, self).__init__()
self.conv = paddle.nn.Conv2D(
in_channels=ch_in,
out_channels=ch_out,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Normal(0., 0.02)),
bias_attr=False)
self.batch_norm = paddle.nn.BatchNorm2D(
num_features=ch_out,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Normal(0., 0.02),
regularizer=paddle.regularizer.L2Decay(0.)),
bias_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Constant(0.0),
regularizer=paddle.regularizer.L2Decay(0.)))
self.act = act
def forward(self, inputs):
out = self.conv(inputs)
out = self.batch_norm(out)
if self.act == 'leaky':
out = F.leaky_relu(x=out, negative_slope=0.1)
return out
class DownSample(paddle.nn.Layer):
# 下采样,图片尺寸减半,具体实现方式是使用stirde=2的卷积
def __init__(self,
ch_in,
ch_out,
kernel_size=3,
stride=2,
padding=1):
super(DownSample, self).__init__()
self.conv_bn_layer = ConvBNLayer(
ch_in=ch_in,
ch_out=ch_out,
kernel_size=kernel_size,
stride=stride,
padding=padding)
self.ch_out = ch_out
def forward(self, inputs):
out = self.conv_bn_layer(inputs)
return out
class BasicBlock(paddle.nn.Layer):
"""
基本残差块的定义,输入x经过两层卷积,然后接第二层卷积的输出和输入x相加
"""
def __init__(self, ch_in, ch_out):
super(BasicBlock, self).__init__()
self.conv1 = ConvBNLayer(
ch_in=ch_in,
ch_out=ch_out,
kernel_size=1,
stride=1,
padding=0
)
self.conv2 = ConvBNLayer(
ch_in=ch_out,
ch_out=ch_out*2,
kernel_size=3,
stride=1,
padding=1
)
def forward(self, inputs):
conv1 = self.conv1(inputs)
conv2 = self.conv2(conv1)
out = paddle.add(x=inputs, y=conv2)
return out
class LayerWarp(paddle.nn.Layer):
"""
添加多层残差块,组成Darknet53网络的一个层级
"""
def __init__(self, ch_in, ch_out, count, is_test=True):
super(LayerWarp,self).__init__()
self.basicblock0 = BasicBlock(ch_in,
ch_out)
self.res_out_list = []
for i in range(1, count):
# 使用add_sublayer添加子层
res_out = self.add_sublayer("basic_block_%d" % (i),
BasicBlock(ch_out*2,
ch_out))
self.res_out_list.append(res_out)
def forward(self,inputs):
y = self.basicblock0(inputs)
for basic_block_i in self.res_out_list:
y = basic_block_i(y)
return y
# DarkNet 每组残差块的个数,来自DarkNet的网络结构图
DarkNet_cfg = {53: ([1, 2, 8, 8, 4])}
class DarkNet53_conv_body(paddle.nn.Layer):
def __init__(self):
super(DarkNet53_conv_body, self).__init__()
self.stages = DarkNet_cfg[53]
self.stages = self.stages[0:5]
# 第一层卷积
self.conv0 = ConvBNLayer(
ch_in=3,
ch_out=32,
kernel_size=3,
stride=1,
padding=1)
# 下采样,使用stride=2的卷积来实现
self.downsample0 = DownSample(
ch_in=32,
ch_out=32 * 2)
# 添加各个层级的实现
self.darknet53_conv_block_list = []
self.downsample_list = []
for i, stage in enumerate(self.stages):
conv_block = self.add_sublayer(
"stage_%d" % (i),
LayerWarp(32*(2**(i+1)),
32*(2**i),
stage))
self.darknet53_conv_block_list.append(conv_block)
# 两个层级之间使用DownSample将尺寸减半
for i in range(len(self.stages) - 1):
downsample = self.add_sublayer(
"stage_%d_downsample" % i,
DownSample(ch_in=32*(2**(i+1)),
ch_out=32*(2**(i+2))))
self.downsample_list.append(downsample)
def forward(self,inputs):
out = self.conv0(inputs)
#print("conv1:",out.numpy())
out = self.downsample0(out)
#print("dy:",out.numpy())
blocks = []
#依次将各个层级作用在输入上面
for i, conv_block_i in enumerate(self.darknet53_conv_block_list):
out = conv_block_i(out)
blocks.append(out)
if i < len(self.stages) - 1:
out = self.downsample_list[i](out)
return blocks[-1:-4:-1] # 将C0, C1, C2作为返回值?Neck(多尺度检测)
? ? ? ? 如果只在在特征图P0的基础上进行的,它的步幅stride=32。特征图的尺寸比较小,像素点数目比较少,每个像素点的感受野很大,具有非常丰富的高层级语义信息,可能比较容易检测到较大的目标。为了能够检测到尺寸较小的那些目标,需要在尺寸较大的特征图上面建立预测输出。如果我们在C2或者C1这种层级的特征图上直接产生预测输出,可能面临新的问题,它们没有经过充分的特征提取,像素点包含的语义信息不够丰富,有可能难以提取到有效的特征模式。在目标检测中,解决这一问题的方式是,将高层级的特征图尺寸放大之后跟低层级的特征图进行融合,得到的新特征图既能包含丰富的语义信息,又具有较多的像素点,能够描述更加精细的结构。
 YOLOv3在每个区域的中心位置产生3个锚框,在3个层级的特征图上产生锚框的大小分别为P2 [(10×13),(16×30),(33×23)],P1 [(30×61),(62×45),(59× 119)],P0[(116 × 90), (156 × 198), (373 × 326]。越往后的特征图上用到的锚框尺寸也越大,能捕捉到大尺寸目标的信息;越往前的特征图上锚框尺寸越小,能捕捉到小尺寸目标的信息。
YOLOv3在每个区域的中心位置产生3个锚框,在3个层级的特征图上产生锚框的大小分别为P2 [(10×13),(16×30),(33×23)],P1 [(30×61),(62×45),(59× 119)],P0[(116 × 90), (156 × 198), (373 × 326]。越往后的特征图上用到的锚框尺寸也越大,能捕捉到大尺寸目标的信息;越往前的特征图上锚框尺寸越小,能捕捉到小尺寸目标的信息。
检测头设计(计算预测框位置和类别)
YOLOv3中对每个预测框计算逻辑如下:
-
预测框是否包含物体。也可理解为objectness=1的概率是多少,可以用网络输出一个实数 x,可以用 Sigmoid(x)表示objectness为正的概率 Pobj?
-
预测物体位置和形状。物体位置和形状 tx?,ty?,tw?,th?可以用网络输出4个实数来表示 tx?,ty?,tw?,th?
-
预测物体类别。预测图像中物体的具体类别是什么,或者说其属于每个类别的概率分别是多少。总的类别数为C,需要预测物体属于每个类别的概率 (P1?,P2?,...,PC?),可以用网络输出C个实数 (x1?,x2?,...,xC?),对每个实数分别求Sigmoid函数,让 Pi?=Sigmoid(xi?),则可以表示出物体属于每个类别的概率。
对于一个预测框,网络需要输出 (5+C)个实数来表征它是否包含物体、位置和形状尺寸以及属于每个类别的概率。
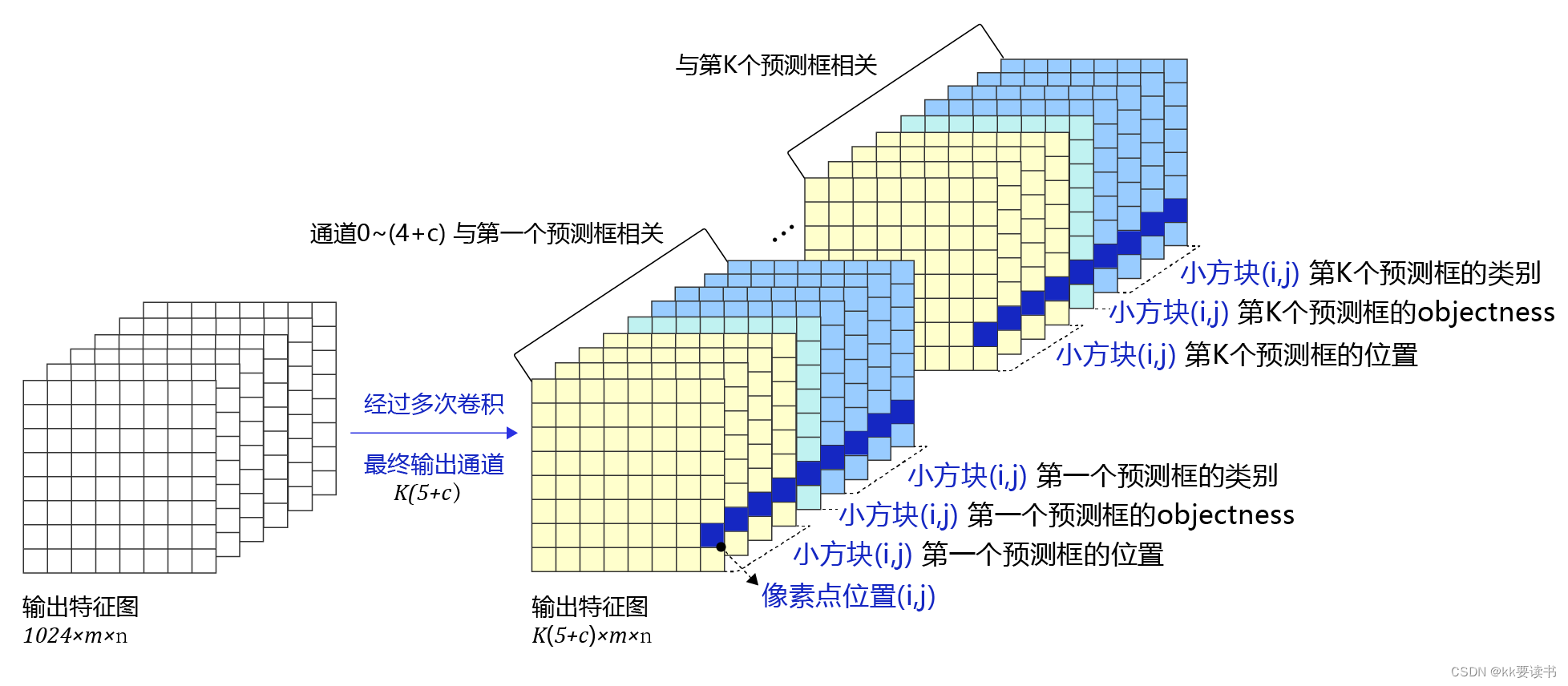
? ? ? ?由于我们在每个小方块区域都生成了K个预测框,则所有预测框一共需要网络输出的预测值数目是:
? ? ? ? ? ? ? ? [K(5+C)]×m×n
还有更重要的一点是网络输出必须要能区分出小方块区域的位置来,不能直接将特征图连接一个输出大小为[K(5+C)]×m×n的全连接层。
建立输出特征图与预测框之间的关联
现在观察特征图,经过多次卷积核池化之后,其步幅stride=32,640×480640×480大小的输入图片变成了20×1520×15的特征图;而小方块区域的数目正好是20×1520×15,也就是说可以让特征图上每个像素点分别跟原图上一个小方块区域对应。这也是为什么我们最开始将小方块区域的尺寸设置为32的原因,这样可以巧妙的将小方块区域跟特征图上的像素点对应起来,解决了空间位置的对应关系。

下面需要将像素点(i,j)与第i行第j列的小方块区域所需要的预测值关联起来,每个小方块区域产生K个预测框,每个预测框需要(5+C)个实数预测值,则每个像素点相对应的要有K(5+C)个实数。为了解决这一问题,对特征图进行多次卷积,并将最终的输出通道数设置为K(5+C),即可将生成的特征图与每个预测框所需要的预测值巧妙的对应起来。当然,这种对应是为了将骨干网络提取的特征对接输出层来形成Loss。实际中,这几个尺寸可以随着任务数据分布的不同而调整,只要保证特征图输出尺寸(控制卷积核和下采样)和输出层尺寸(控制小方块区域的大小)相同即可。
骨干网络的输出特征图是C0,下面的程序是对C0进行多次卷积以得到跟预测框相关的特征图P0。
class YoloDetectionBlock(paddle.nn.Layer):
# define YOLOv3 detection head
# 使用多层卷积和BN提取特征
def __init__(self,ch_in,ch_out,is_test=True):
super(YoloDetectionBlock, self).__init__()
assert ch_out % 2 == 0, \
"channel {} cannot be divided by 2".format(ch_out)
self.conv0 = ConvBNLayer(
ch_in=ch_in,
ch_out=ch_out,
kernel_size=1,
stride=1,
padding=0)
self.conv1 = ConvBNLayer(
ch_in=ch_out,
ch_out=ch_out*2,
kernel_size=3,
stride=1,
padding=1)
self.conv2 = ConvBNLayer(
ch_in=ch_out*2,
ch_out=ch_out,
kernel_size=1,
stride=1,
padding=0)
self.conv3 = ConvBNLayer(
ch_in=ch_out,
ch_out=ch_out*2,
kernel_size=3,
stride=1,
padding=1)
self.route = ConvBNLayer(
ch_in=ch_out*2,
ch_out=ch_out,
kernel_size=1,
stride=1,
padding=0)
self.tip = ConvBNLayer(
ch_in=ch_out,
ch_out=ch_out*2,
kernel_size=3,
stride=1,
padding=1)
def forward(self, inputs):
out = self.conv0(inputs)
out = self.conv1(out)
out = self.conv2(out)
out = self.conv3(out)
route = self.route(out)
tip = self.tip(route)
return route, tip如上面的代码所示,可以由特征图C0生成特征图P0,P0的形状是[1,36,20,20][1,36,20,20]。每个小方块区域生成的锚框或者预测框的数量是3,物体类别数目是7,每个区域需要的预测值个数是3×(5+7)=363×(5+7)=36,正好等于P0的输出通道数。
将P0[t,0:12,i,j]与输入的第t张图片上小方块区域(i,j)第1个预测框所需要的12个预测值对应,]P0[t,12:24,i,j]与输入的第t张图片上小方块区域(i,j)第2个预测框所需要的12个预测值对应,P0[t,24:36,i,j]与输入的第t张图片上小方块区域(i,j)第3个预测框所需要的12个预测值对应。
P0[t,0:4,i,j]与输入的第t张图片上小方块区域(i,j)第1个预测框的位置对应,P0[t,4,i,j]与输入的第t张图片上小方块区域(i,j)第1个预测框的objectness对应,P0[t,5:12,i,j]与输入的第t张图片上小方块区域(i,j)第1个预测框的类别对应。
损失函数
上面从概念上将输出特征图上的像素点与预测框关联起来了,那么要对神经网络进行求解,还必须从数学上将网络输出和预测框关联起来,也就是要建立起损失函数跟网络输出之间的关系。下面讨论如何建立起YOLOv3的损失函数。
对于每个预测框,YOLOv3模型会建立三种类型的损失函数:
-
表征是否包含目标物体的损失函数,通过pred_objectness和label_objectness计算。
-
表征物体位置的损失函数,通过pred_location和label_location计算。
-
表征物体类别的损失函数,通过pred_classification和label_classification计算。
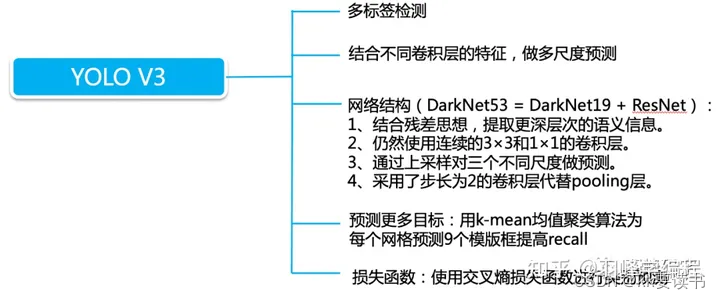
总结
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- STM32 基础知识(探索者开发板)--135讲 ADC转换
- Linux mdu命令教程:如何有效地使用mdu命令(附实例教程和注意事项)
- 九州金榜|叫停教育小妙招让这几种方式为亲子互动增色添彩
- 一键查询,轻松掌握所有物流动态,全新物流查询工具助您高效管理
- python将logger内容保存到日志文件中 + 将控制台信息保存到日志文件中 + 生成时间戳记录
- 庆祝安科瑞企业微电网智慧能源管理系统生态交流会圆满举办-安科瑞 蒋静
- <软考高项备考>《论文专题 - 68 质量管理(7) 》
- 链表:约瑟夫环
- 算法训练营Day25
- 使用css动画animation及@keyframes实现图片持续放大缩小动画展示