【基础篇】九、程序计数器 && JVM栈
0、运行时数据区域
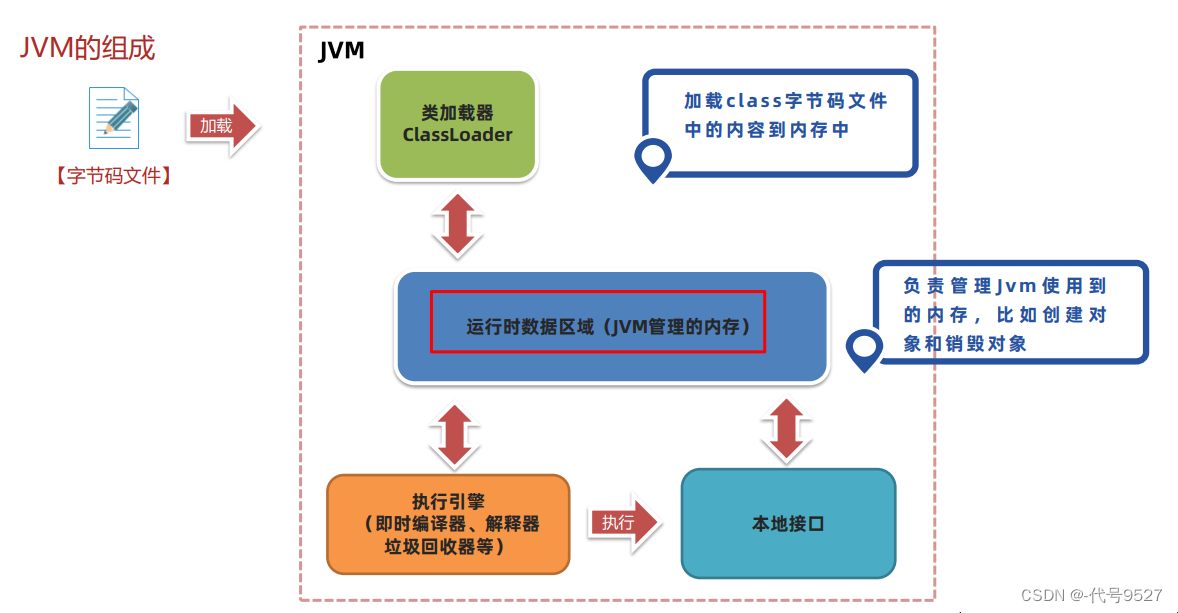
JVM结构里,类加载器下来,到了运行时数据区域,即Java程序运行时,JVM管理的内存区域,其又分为:
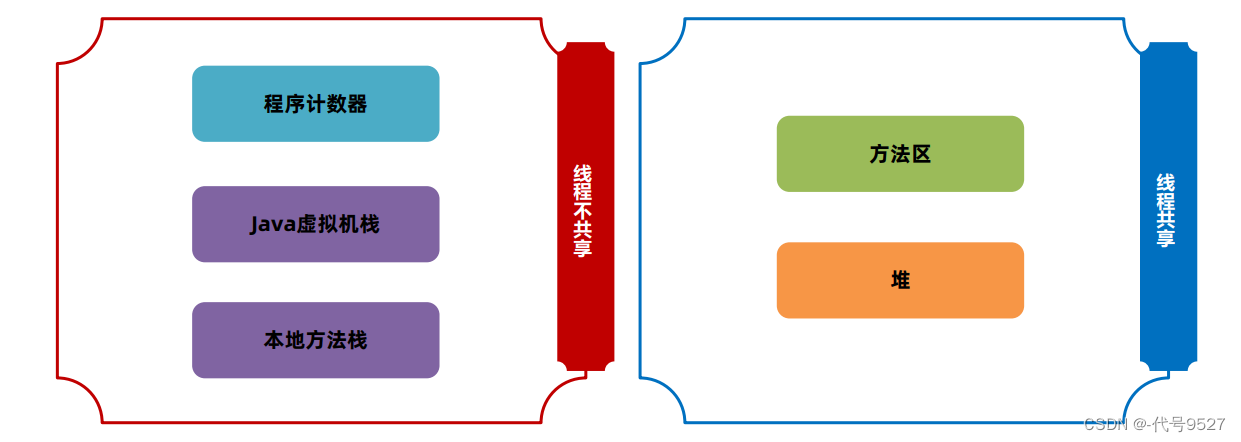
栈这里可以细划分为两部分:
- Java虚拟机栈:保存在Java中的方法
- 本地方法栈:保存的native方法,c++实现的那些
1、程序计数器
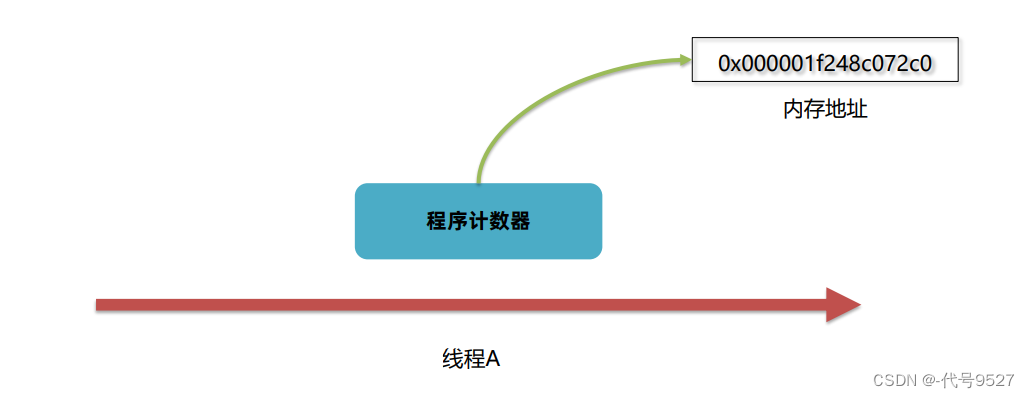
程序计数器(Program Counter Register)也叫PC寄存器,每个线程会通过它来记录接下来要执行的的字节码指令的地址
举个例子:
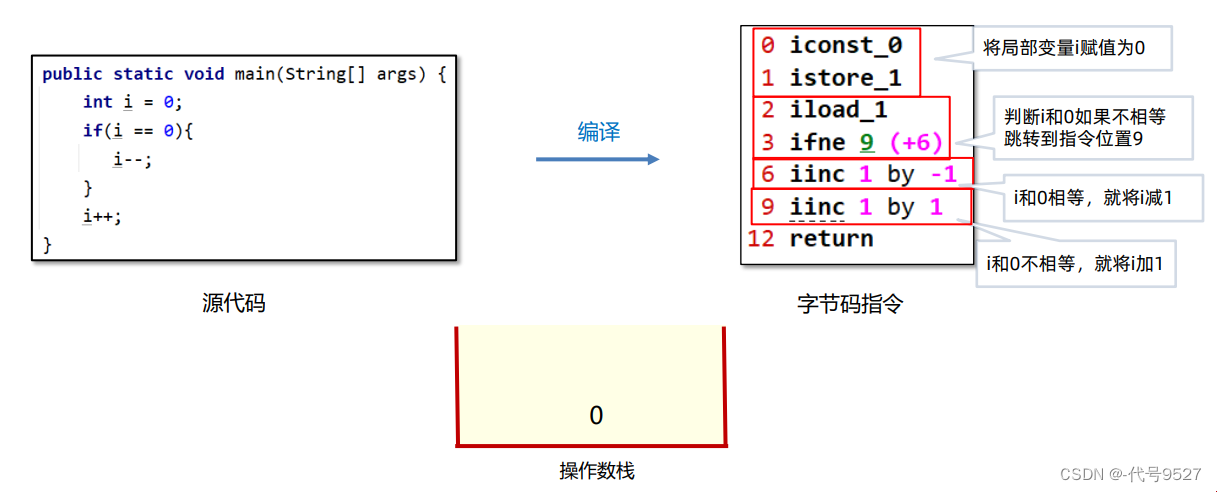
类加载阶段,类加载器将字节码指令读到内存中后,将原来的偏移量改为内存地址,每条字节码指令都对应一个内存地址:
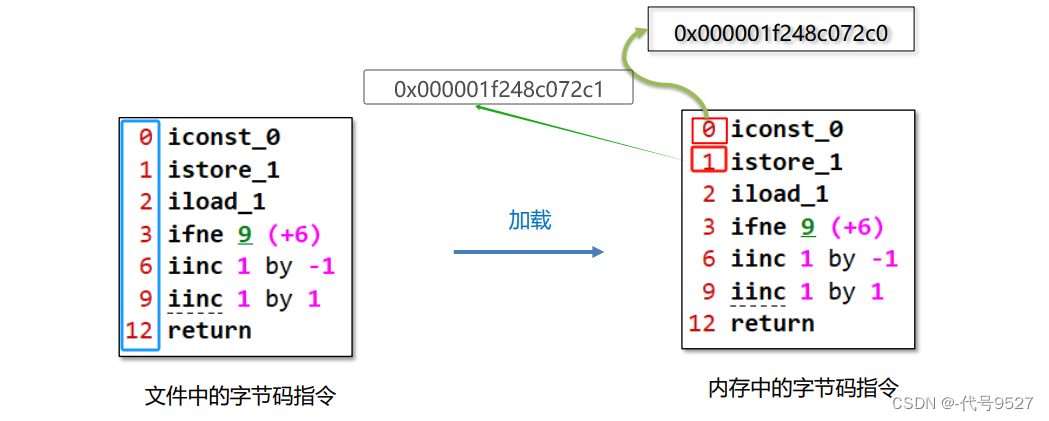
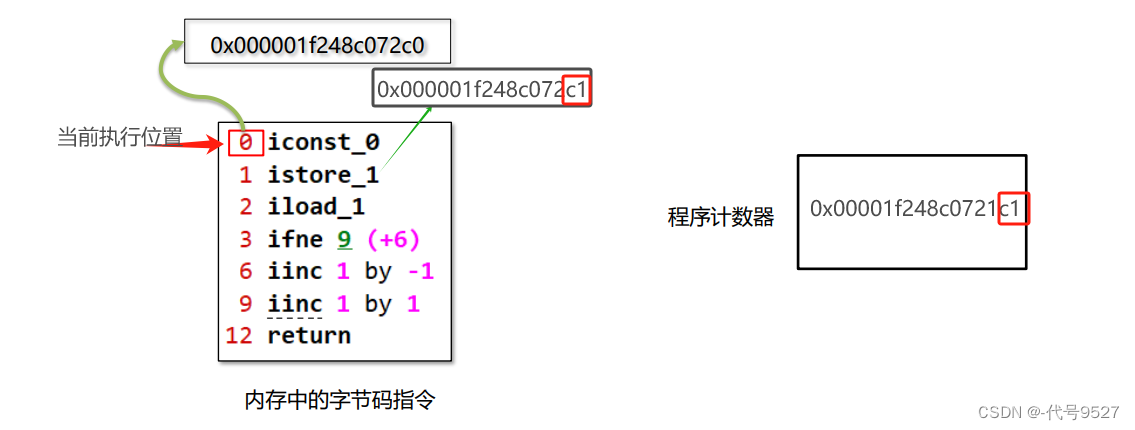
执行完当前这一条指令后,JVM的执行引擎(JIT、解释器等)根据程序计数器中记录的数据,就拿到了接下来要执行的指令的地址。
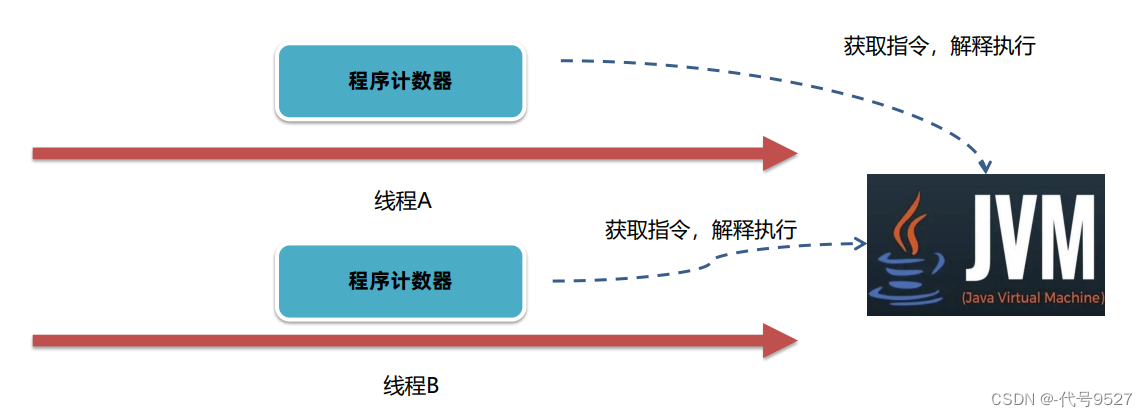
多线程下,CPU从线程A切换到线程B,得知道线程B之前解释执行到哪一句指令了,此时JVM的程序计数器就发挥作用了
2、JVM栈
JVM的栈采用栈的数据结构,保存方法调用的基本数据,先进后出,其中,每一个调用的方法用一个叫
栈帧的东西存。
如下图,流程为:
main入栈
study入栈
eat入栈
eat出栈.....
sleep入栈
sleep出栈.....
study出栈.....
main出栈.....
执行结束!

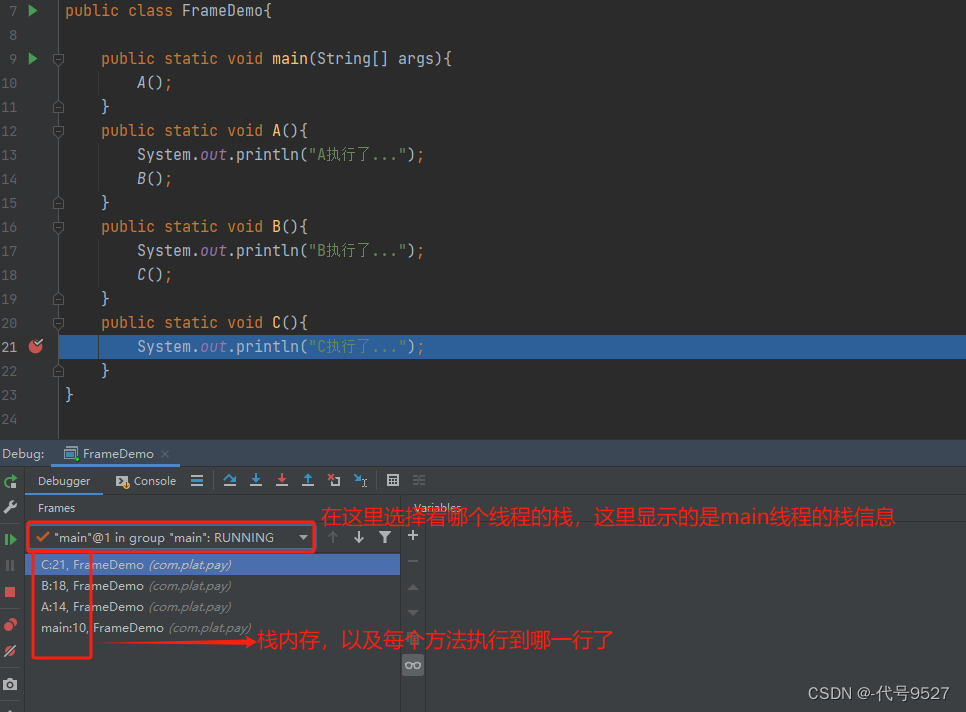
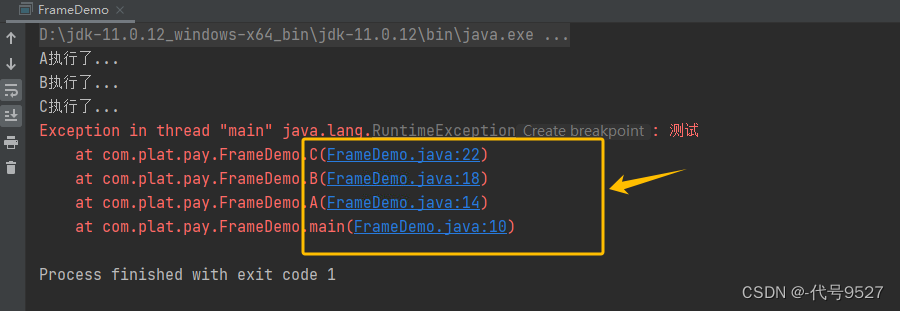
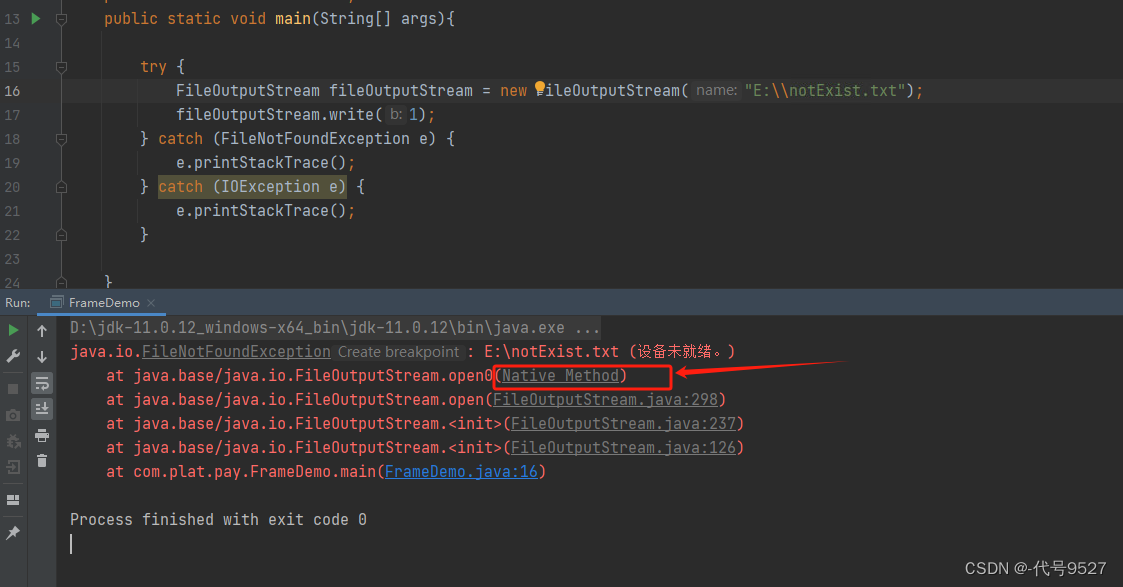
断点打在C方法里,看下IDEA中debug的栈信息,点击栈里的每个方法,跳到当前该方法执行在的那一行:
修改程序,让C程序抛出异常:
public class FrameDemo{
public static void main(String[] args){
A();
}
public static void A(){
System.out.println("A执行了...");
B();
}
public static void B(){
System.out.println("B执行了...");
C();
}
public static void C(){
System.out.println("C执行了...");
throw new RuntimeException("测试"); //异常
}
}
可以发现,结果里也展示了异常发生时的栈信息,以及每个方法具体执行到哪一行了:
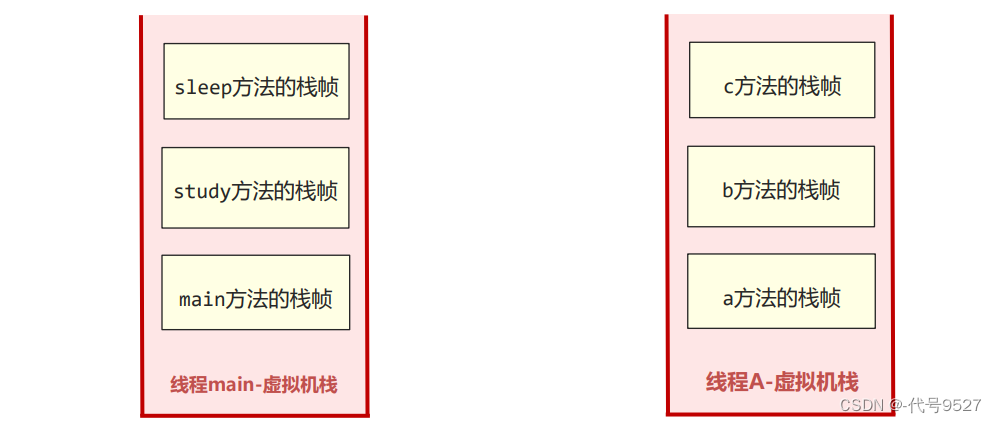
JVM的栈随着线程的创建而创建,也随着线程的销毁而回收,每个线程都有一个自己的JVM栈:
3、JVM栈–栈帧–局部变量表
栈里的一个个栈帧,由三部分构成:

局部变量表用来存方法执行过程中的所有局部变量,类被编译成字节码时,局部变量表的内容就确定了:
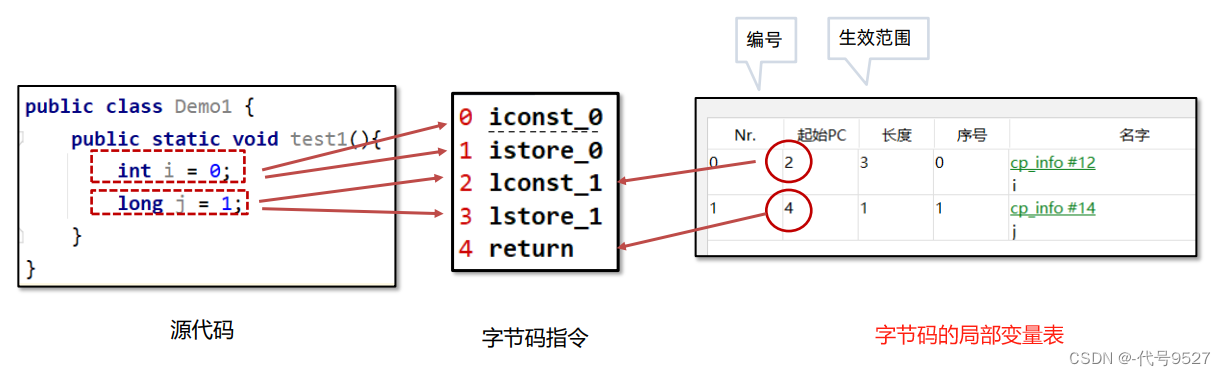
想访问一个变量,自然是要在它声明定义之后,所以局部变量表里的起始PC就是保存了从哪一行字节码指令开始,可以访问这个变量,对于变量i,其值就为2。而长度字段为3,即代表在2.3.4这三行里可以访问i。总之就是通过局部变量表控制可以访问每个变量的范围。 是字节码文件中的局部变量表,它的作用是做安全性上的校验,比如变量的生效范围。

而栈帧自己的局部变量表就是一个数组,数组的每个位置叫槽slot,long和double类型占用两个槽,其他类型占用一个槽。 如上图,i占0号位,一个槽,后面long类型的j则占两个。再看字节码文件里局部变量表中的序号,其实就是这个局部变量i,在栈帧的局部变量表的起始槽的编号。
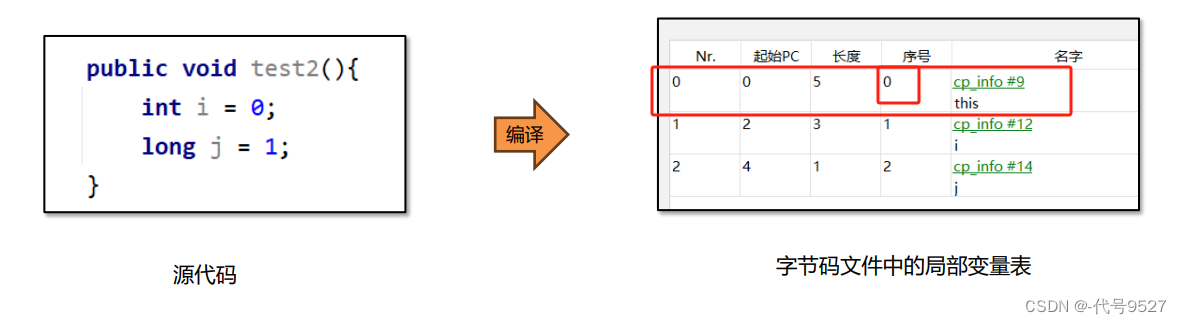
实例方法中的序号为0的位置存放的是this,指的是当前调用方法的对象,运行时会在内存中存放实例对象
的地址。
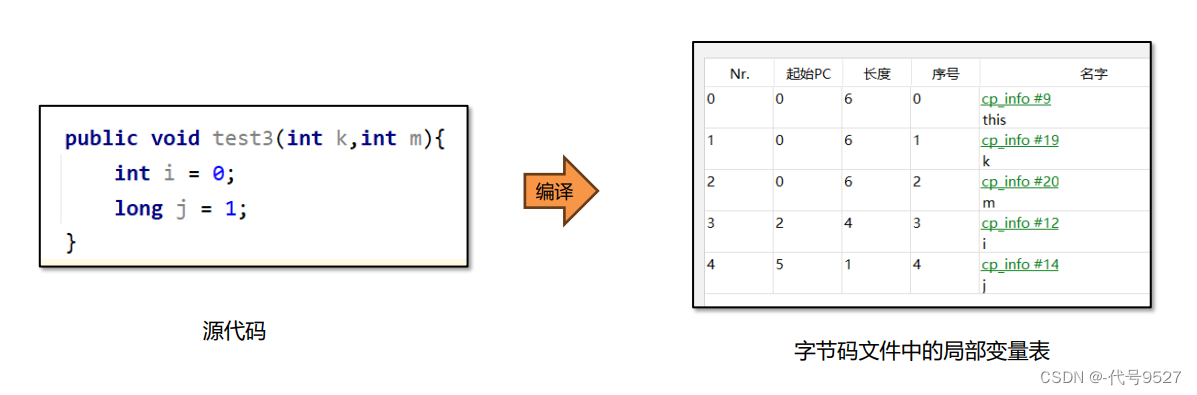
局部变量表也会存方法的形参,且顺序与形参顺序一致。
一句话,局部变量表中存的是实例方法的this对象、方法的形参、方法体中声明的局部变量
注意,局部变量表的槽可以重复使用,一旦某个局部变量不再生效,当前槽就可以再次被使用。
public void test4(int k,int m){
{
int a = 1;
int b = 2;
}
{
int c = 1;
}
int i = 0;
int j = 1;
}
执行完b=2时,栈帧的局部变量表长这样:
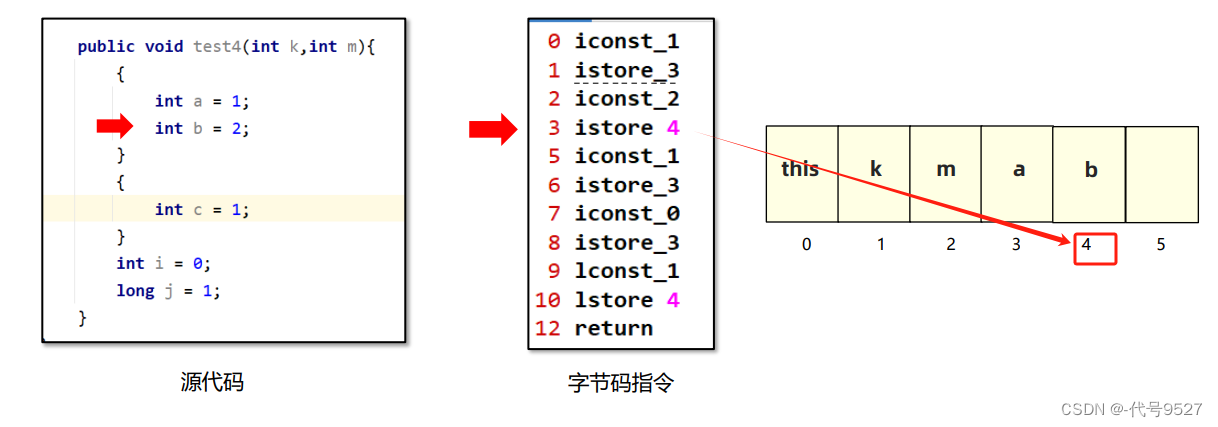
再往下走,字节码为:
iconst_1
istore_3
即把字面量1放入了3号槽,复用了a变量的槽。同理往下推,最终的局部变量表长这样:
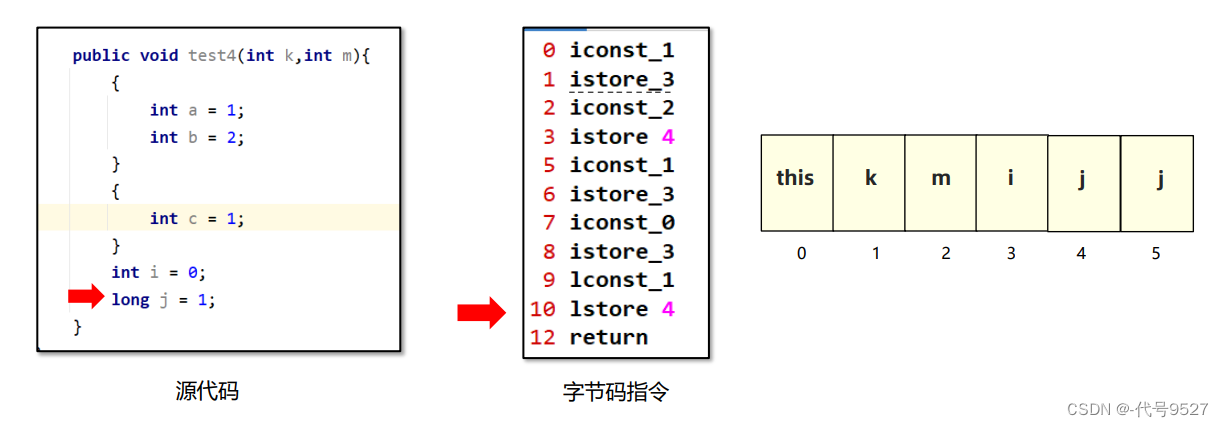
因此,上面的代码在其栈帧的局部变量表中会占用6个槽,而不是简单的1+1+1 +1+1 +1 +1+2 = 9
4、JVM栈–栈帧–操作数栈
- 操作数栈是JVM在执行指令时,用来存放中间数据的区域
- 栈的数据结构,压栈+弹栈
- 编译器就可决定操作数栈的最大深度,用jclasslib验证:
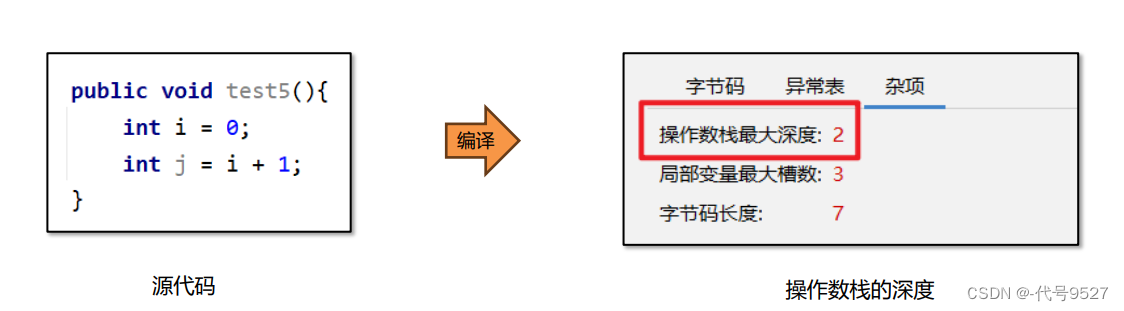
分析下以上源码的字节码:
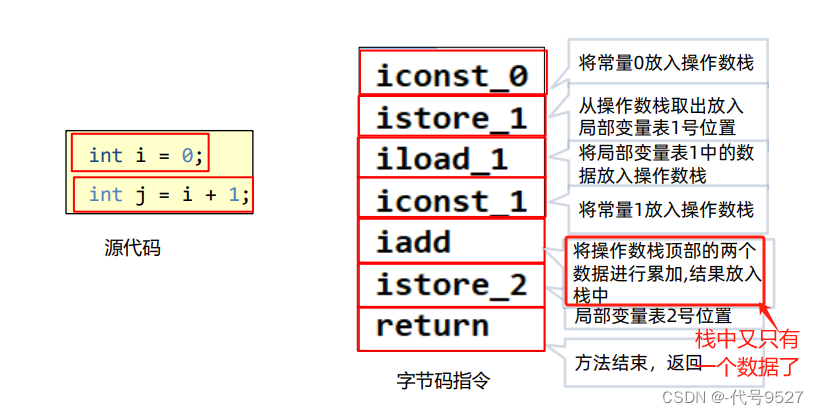
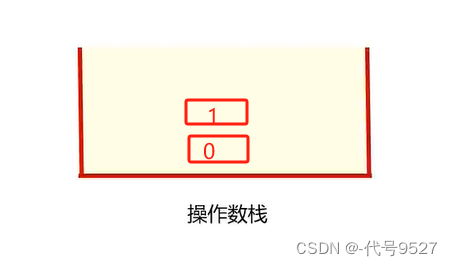
操作数栈的变化过程如下:
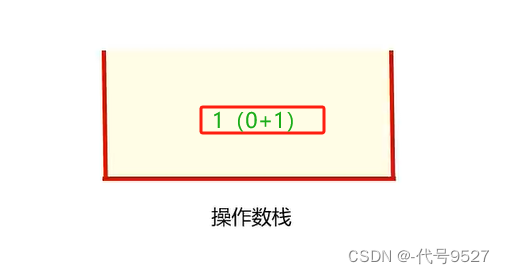
最终状态:
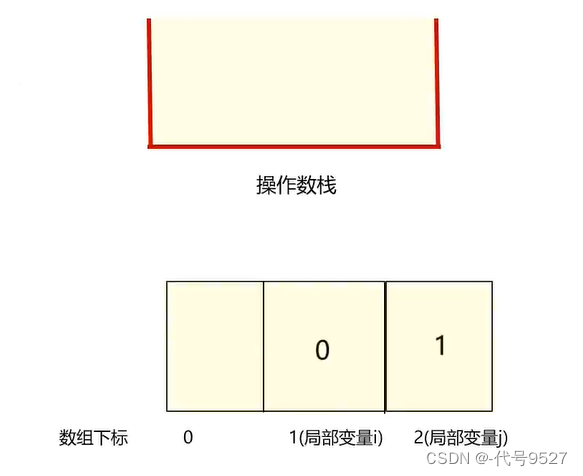
可以看到,整个过程中,操作数栈里最多有两个数据,即操作数栈的最大深度为2,此时创建栈帧时,创建深度为2的操作数栈即可。
5、JVM栈–栈帧–桢数据
桢数据主要含:
- 动态链接
- 方法出口
- 异常表引用
Part1:动态链接
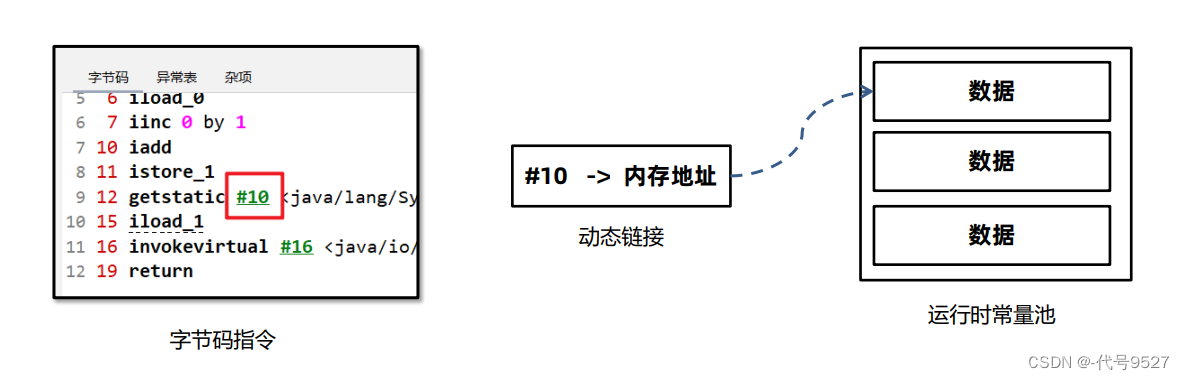
当前类的字节码中引用了别的类的方法或属性,要将符号引用(#10)转成内存地址。动态链接就保存了编号到运行时常量池的内存地址的映射关系。
Part2:方法出口
在栈帧的桢数据中,存放了上一个方法的地址(sleep方法的桢数据有study方法执行到哪一行的信息)
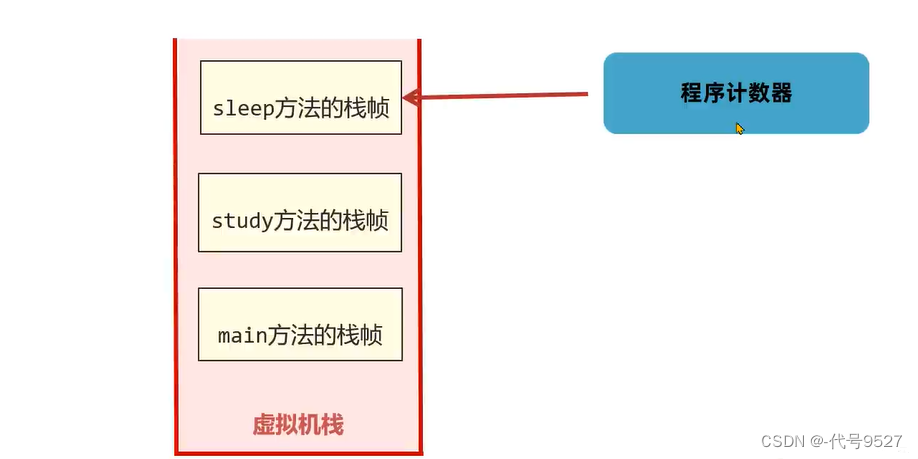
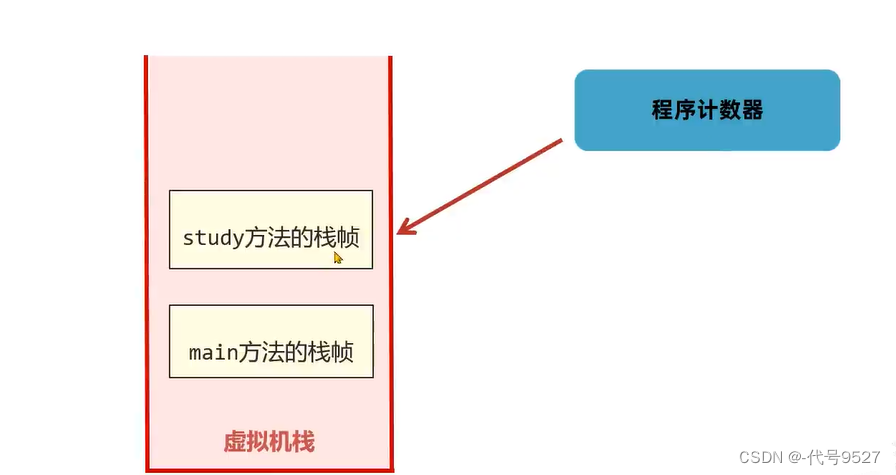
当方法正常结束或发生异常结束时,当前栈帧被弹出,同时程序计数器指向上一个栈帧的下一条指令地址:
Part3:异常表引用
存放异常捕获的范围,以及这个范围发生异常后跳哪一行。 eg:看异常表的第一行,从起始PC 0到结束PC 2,如果发生异常,就跳转到第7行,astore_0即把捕获的异常对象e放到局部变量表中,因为catch块中大概率会用到e对象

6、栈溢出
一个线程的栈里,栈帧过多,占用的内存到达了分配的最大值,再入栈就会StackOverflowError,即栈溢出。

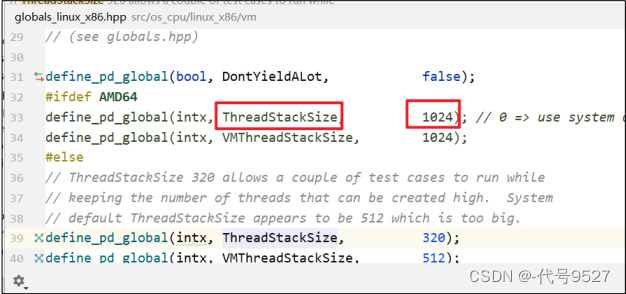
如下为OpenJDK8里JVM的源码,不指定栈的大小时,JVM创建的是一个默认大小的栈,不同的操作系统里,这个默认值也不同。
用无停止条件的递归来看栈溢出:
public static int count = 0;
//递归方法调用自己
public static void recursion(){
System.out.println(++count);
recursion();
}
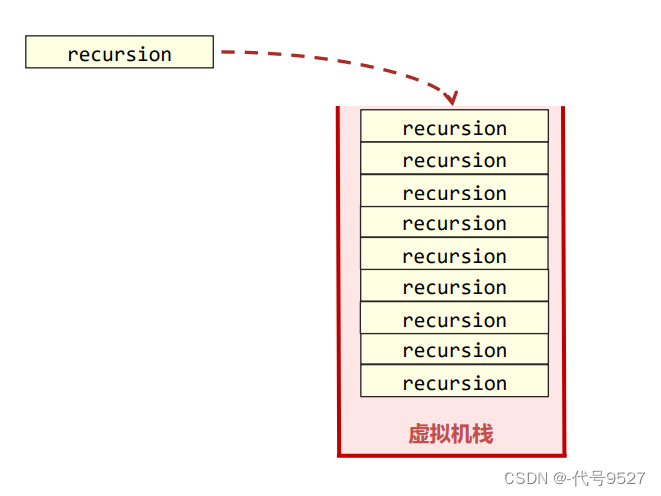
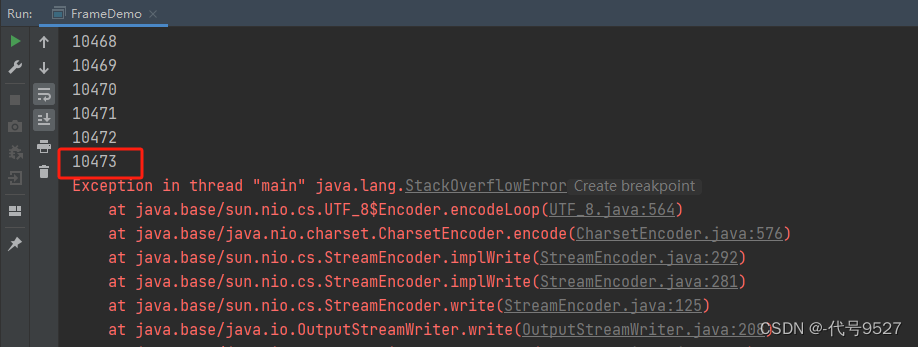
运行,默认情况下,main线程的栈里放了大约10473个栈帧:
7、设置栈空间大小
添加JVM参数:
-Xss栈大小
单位默认是byte字节(默认,必须是 1024 的倍数),可选k或者K(KB)、m或者M(MB)、g或者G(GB)
eg:
-Xss1048576
-Xss1024K
-Xss1m
-Xss1g
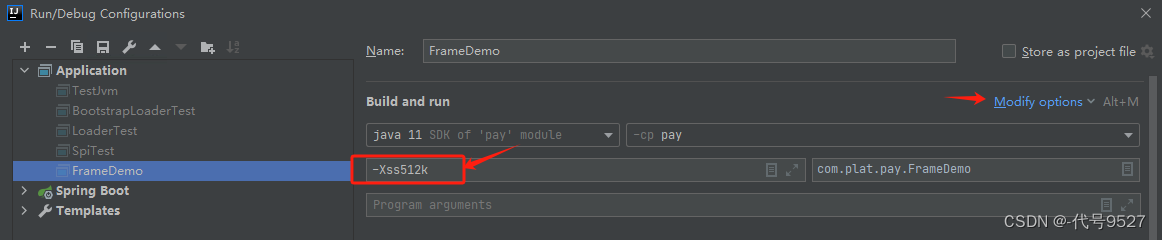
设置线程栈空间大小,还可以用另一个参数:
//注意等号
-XX:ThreadStackSize=1024
HotSpot对栈空间的大小有范围限制,Windows(64位)下的JDK8测试最小值为180k,最大值为1024m,超过这个范围,即使设置了也不会生效。
//无效
-Xss1k
-Xss1025m
当然,局部变量过多(栈帧局部变量表大)、操作数栈深度大,在相同大小下,能存的栈帧数量也就少了。最后,工作中,该值建议用:
-Xss256k
8、本地方法栈
JVM栈中存的是Java方法的栈桢,本地方法栈里存的则是native本地方法的栈帧。不过在HotSpot虚拟机中,JVM栈和本地方法栈实现上使用了同一个栈空间。
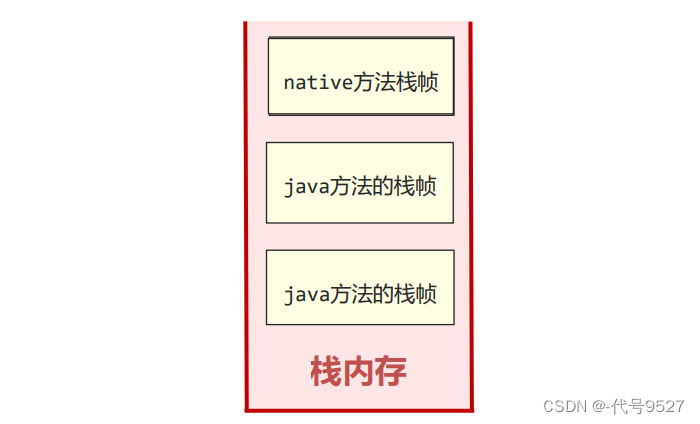
如下:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机网络-物理层基本概念(接口特性 相关概念)
- 【C++】set和map封装
- Intel 显卡小结
- CEC2013(python):五种算法(HHO、WOA、GWO、DBO、PSO)求解CEC2013(python代码)
- [蓝桥杯学习] 树状数组的二分
- js逆向第20例:猿人学第19题乌拉乌拉乌拉
- 为什么现在越来越多人选择使用海外的服务器?
- 如何把透明OLED显示屏介绍给用户人群
- 漏刻有时数据可视化Echarts组件开发(45)机场流程导航线和指示点的开发记录
- 17.Kubernetes集群资源备份还原(Velero Minio)