Pandas的datetime数据类型
Python的datetime对象
Python内置了datetime对象,可以在datetime库中找到
from datetime import datetime
now = datetime.now()
now还可以手动创建datetime
t2 = datetime(2023,4,21)
now-t2
#
datetime.timedelta(days=251, seconds=31427, microseconds=546921)
将pandas中的数据转换成datetime
1.to_datetime函数
Timestamp是pandas用来替换python datetime.datetime的 可以使用to_datetime函数把数据转换成Timestamp类型
import pandas as pd
ebola = pd.read_csv(r'C:\Users\Administrator\Documents\WeChat Files\wxid_mgaxcaeufcpq22\FileStorage\File\2023-12\country_timeseries.csv')
ebola.iloc[:5,:5]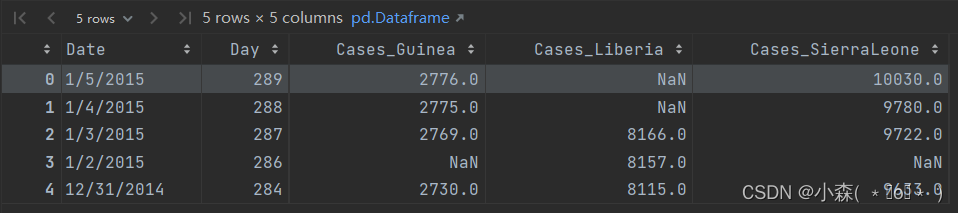
从数据中看出 Date列是日期,但通过info查看加载后数据为object类型
某些场景下, (比如从csv文件中加载进来的数据), 日期时间的数据会被加载成object类型, 此时需要手动的把这个字段转换成日期时间类型
可以通过to_datetime方法把Date列转换为Timestamp,然后创建新列
ebola['date_dt'] = pd.to_datetime(ebola['Date'])
ebola.info()
#
18 date_dt 122 non-null datetime64[ns]2.通过Timestamp创建
d=pd.Timestamp(2023,12,28)
d
# Timestamp('2023-12-28 00:00:00')3 .通过parse_dates参数指定?
ebola = pd.read_csv('data/country_timeseries.csv',parse_dates=[0])
ebola.info()
# Date列转换为datetime类型提取日期的各个部分
d = pd.to_datetime('2023-04-20’)
# 可以看到得到的数据是Timestamp类型,通过Timestamp可以获取年,月,日等部分
d.year
d.month
d.day
日期运算和Timedelta
Ebola数据集中的Day列表示一个国家爆发Ebola疫情的天数。这一列数据可以通过日期运算重建该列 疫情爆发的第一天(数据集中最早的一天)是2014-03-22。
计算疫情爆发的天数时,只需要用每个日期减去这个日期即可
获取疫情爆发的第一天
ebola['Date'].min()
添加新列
ebola['outbreak_d'] = ebola['Date']-ebola['Date'].min()
查看数据
ebola[['Date','Day','outbreak_d']].head() ebola[['Date','Day','outbreak_d']].tail()banks['倒闭的季度'] = banks['Closing Date'].dt.quarter
banks['倒闭的年份'] = banks['Closing Date'].dt.year
.dt.quarter和.dt.year可以获取当前日期的季度和年份
# 类似于这个方法
d=pd.Timestamp(2023,12,30)
d.weekday()closing_year = banks.groupby(['倒闭的年份'])['Bank Name'].count()
closing_year
#
2000,2
2001,4
2002,11
2003,3
2004,4
2007,3
2008,25
2009,140
2010,157
2011,92
基于日期数获取数据子集
先将第一列数据处理为datetime类型
tesla = pd.read_csv(r'C:\Users\Administrator\Documents\WeChat Files\wxid_mgaxcaeufcpq22\FileStorage\File\2023-12\TSLA.csv',parse_dates=[0])
tesla.info()tesla.loc[(tesla.Date.dt.year==2015) & (tesla.Date.dt.month == 8)]
将索引设为Date 列,然后可以查询2015年8月的所有数据
tesla.set_index('Date',inplace=True)
tesla['2015-08']
tesla['ref_date'] = tesla['Date']-tesla['Date'].min()
tesla.set_index('ref_date',inplace=True)
tesla.loc['1000 days']?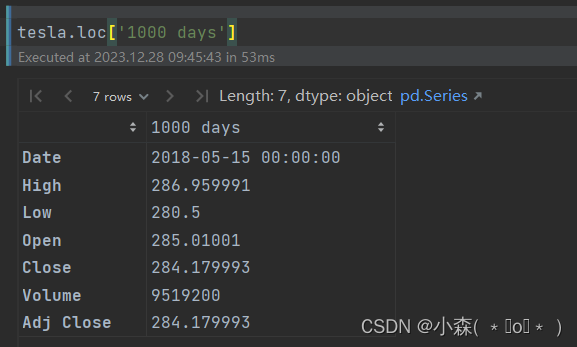
?日期范围
使用date_range函数来创建连续的日期范围
head_range = pd.date_range(start='2014-12-31',end='2015-01-05')
head_range # 使用date_range函数创建日期序列时,可以传入一个参数freq,默认情况下freq取值为D,表示日期范围内的值是逐日递增的
#
DatetimeIndex(['2014-12-31', '2015-01-01', '2015-01-02', '2015-01-03',
'2015-01-04', '2015-01-05'],
dtype='datetime64[ns]', freq='D')包含日期的数据集中,并非每一个都包含固定频率。比如在Ebola数据集中,日期并没有规律 ebola.iloc[:,:5]
从上面的数据中可以看到,缺少2015年1月1日,2014年3月23日,如果想让日期连续,可以创建一个日期范围来为数据集重建索引。

在freq传入参数的基础上,可以做一些调整
# 隔一个工作日取一个工作日
pd.date_range('2023-01-01','2023-01-07',freq='2B’)
freq传入的参数可以传入多个
#2023年每个月的第一个星期四
pd.date_range('2023-01-01','2023-12-31',freq='WOM-1THU’)
#每个月的第三个星期五
pd.date_range('2023-01-01','2023-12-31',freq='WOM-3FRI')
?datetime类型案例
加载数据
crime = pd.read_csv('data/crime.csv',parse_dates=['REPORTED_DATE’])
查看数据
crime.info()
设置报警时间为索引
crime = crime.set_index('REPORTED_DATE')
crime.head()
crime.loc['2016-05-12’]
查看某一段时间的犯罪记录
crime.loc['2015-3-4':'2016-1-1'].sort_index()
时间段可以包括小时分钟
crime.loc['2015-3-4 22':'2016-1-1 23:45:00'].sort_index()查询凌晨两点到五点的报警记录
crime.between_time('2:00', '5:00', include_end=False)
查看发生在某个时刻的犯罪记录
crime.at_time('5:47’)
在按时间段选取数据时,可以将时间索引排序,排序之后再选取效率更高
crime_sort = crime.sort_index()
%timeit crime.loc['2015-3-4':'2016-1-1’]
%timeit crime_sort.loc['2015-3-4':'2016-1-1’]
(%timeit是ipython的魔术函数,可用于计时特定代码段)
总结:
Pandas中,datetime64用来表示时间序列类型
时间序列类型的数据可以作为行索引,对应的数据类型是DatetimeIndex类型
datetime64类型可以做差,返回的是Timedelta类型
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- P1928-外星密码[递归过程的剖析]
- 如何信任机器学习模型的预测结果?
- 【语音去噪】IIR(巴特沃斯、切比雪夫)滤波器语音去噪【含GUI Matlab源码 3716期】
- android studio升级后怎么删除安装插件
- 【C++11新特性】Lambda表达式
- 多态-多态的基本概念-类和对象
- 大数据平台Bug Bash大扫除最佳实践
- 2023年全国职业院校技能大赛软件测试赛题—单元测试卷⑦
- 安德尔房产数据分析
- Soul、腾讯音乐、美图加速“攀登”AIGC高地