大一C语言查缺补漏1 12.2
学习方向非C语言方向,但是专业是。。
仅供参考,,祝大家期末考试顺利。
对于二维数组定义,要给出明确的定义
eg:double a [2+1][4]
int a [ ][3] = {1,2,3,4,5,6}
不可以是:int a [ ][3];
在c语言中,对于二维数组初始化,为什么 int a[2][] ={1,2,3,4,5,6}不对,而int a[ ][3] ={1,2,3,4,5,6}是对的?
在C语言中,二维数组的初始化需要明确每一维的大小。这是因为编译器需要知道每一维的大小来正确地分配内存。
1. 对于`int a[2][] ={1,2,3,4,5,6}`,这个声明是不合法的。在这里,你只指定了第一维的大小为2,但没有指定第二维的大小。编译器无法确定第二维应该有多大才能容纳所有的初始化元素。因此,这种方式无法用于二维数组的初始化。
2. 而`int a[][3] ={1,2,3,4,5,6}`是合法的。在这个声明中,虽然你没有明确指定第一维的大小,但是你指定了第二维的大小为3。由于二维数组的元素是按行存储的,编译器可以通过初始化元素的数量来推算出第一维的大小。在这个例子中,有6个初始化元素,每行3个元素,所以可以推算出第一维的大小为2。因此,这种方式可以正确地初始化二维数组。
需要注意的是,虽然第二种方式在某些情况下可以省略第一维的大小,但并不是所有情况下都可以。如果你的初始化元素的数量不能被第二维的大小整除,那么编译器将无法准确推算出第一维的大小,这时就需要显式地指定第一维的大小。
关于C语言函数的参数,实参必须是常量吗?
在C语言中,函数的实参(实际参数)并不必须是常量。实参可以是各种类型的变量、表达式或者是常量。当你调用一个函数并传递参数时,函数接收的是实参的值(对于基本数据类型)或地址(对于指针类型)。
以下是一些例子:
1. 基本数据类型的变量作为实参:
```c
int x = 10;
void my_func(int y) {
? ? // ...
}
my_func(x); // 这里x是一个变量,但作为实参传递给函数
```2. 表达式作为实参:
```c
int a = 5, b = 3;
void my_func(int z) {
? ? // ...
}
my_func(a + b); // 这里a + b是一个表达式,其结果作为实参传递给函数
```3. 常量作为实参:
```c
void my_func(int c) {
? ? // ...
}
my_func(10); // 这里10是一个常量,直接作为实参传递给函数
```需要注意的是,如果你试图在函数内部修改一个基础类型的实参(如整数或浮点数),由于函数接收到的是实参的副本,所以对副本的修改不会影响到原来的实参变量。但是,如果实参是指针,那么通过指针在函数内部修改的数据会影响到原始变量,因为指针传递的是变量的地址。
关于C语言函数的参数,实参要与对应形参的数据类型保持一致吗?
在C语言中,函数的实参(实际参数)通常需要与对应形参(形式参数)的数据类型保持一致或者可以进行隐式类型转换。以下是一些要点:
-
类型匹配:理想情况下,实参的数据类型应该与形参的数据类型完全一致。例如,如果函数定义为
void func(int x),那么在调用时应该传递一个整数类型的实参,如func(5)。 -
隐式类型转换:在某些情况下,C语言允许自动进行类型转换(也称为隐式类型转换)。例如,如果你有一个函数
void func(int x),但在调用时传递了一个小于INT_MAX的浮点数,如func(3.5),编译器会自动将浮点数转换为最接近的整数(3)并传递给函数。 -
不允许的转换:然而,并非所有类型之间都可以进行隐式转换。例如,你不能直接将一个指针类型转换为整数类型,或者将一个结构体类型转换为另一个不兼容的结构体类型,除非进行了显式的类型转换。
-
警告和错误:虽然某些不严格的类型匹配可能会被编译器接受并进行隐式转换,但这种做法通常不推荐,因为它可能导致数据丢失、精度降低或者难以察觉的错误。编译器可能会发出警告来提示这种类型的不匹配。
总的来说,为了保证代码的清晰性、可读性和避免潜在的错误,建议在调用函数时尽量保持实参和形参的数据类型一致。如果需要进行类型转换,应明确使用显式的类型转换操作,并确保转换是安全和有意义的。
主调函数,定义函数,调用函数分别是什么?主调函数的数据类型,定义函数时指定的数据类型,调用函数时系统临时决定的类型分别是什么?举个例子。
在C语言中:
1. **主调函数(Caller Function)**:也称为调用函数,是执行过程中调用其他函数的函数。例如,在以下代码中,`main()` 是主调函数,因为它调用了 `max()` 函数:
```c
#include <stdio.h>
int max(int x, int y) {
? ? if (x > y)
? ? ? ? return x;
? ? else
? ? ? ? return y;
}
int main() {
? ? int a = 10, b = 20;
? ? int result = max(a, b);
? ? printf("Max is %d\n", result);
? ? return 0;
}
```2. **定义函数(Defining a Function)**:这是为完成特定任务编写的一组语句集合,并为其指定一个名称和参数列表。在定义函数时,需要指定函数的返回类型和参数的数据类型。例如,在上面的 `max()` 函数中,返回类型是 `int`,参数 `x` 和 `y` 的数据类型也是 `int`。
3. **调用函数(Calling a Function)**:在程序中使用函数名并传递实际参数来执行已经定义的函数。系统并不临时决定数据类型,而是根据函数定义时指定的参数类型来接收和处理实参。在上面的 `main()` 函数中,通过 `max(a, b)` 调用了 `max()` 函数,其中 `a` 和 `b` 是实参,它们的值被传递给形参 `x` 和 `y`。
关于数据类型:
- **主调函数的数据类型**:主调函数本身也有一个返回类型,例如在上面的 `main()` 函数中,返回类型是 `int`。但这并不是主调函数特有的,所有函数都应有返回类型。
- **定义函数时指定的数据类型**:在定义函数时,需要明确指定函数的返回类型和参数的数据类型。如上述 `max()` 函数,返回类型是 `int`,参数 `x` 和 `y` 的数据类型也是 `int`。
- **调用函数时系统的行为**:当调用函数时,系统并不临时决定数据类型。实际上,系统会检查实参的数据类型是否与形参的数据类型兼容,如果兼容则进行隐式类型转换或直接传递,如果不兼容则会导致编译错误。实参的值按照函数定义时的参数顺序和类型传递给形参。在上述 `max()` 函数的调用中,`a` 和 `b` 的值被复制给 `x` 和 `y`,这个过程不涉及临时决定数据类型,而是基于预先定义的类型规则。
在C语言中,使用"scanf(“x=%f,y=%f",&x,&y);"要使变量x和y的值均为1.5,正确的输入是什么?为什么不可以是1.5 1.5?
在C语言中,使用scanf("x=%f,y=%f",&x,&y);要求输入的格式必须与指定的格式字符串匹配。在这个例子中,格式字符串是 "x=%f,y=%f",它期望的输入格式是 x=1.5,y=1.5,其中x=和,y=是格式说明符的一部分,用于指示输入值对应的变量。
因此,要使变量x和y的值均为1.5,正确的输入应该是:
code
x=1.5,y=1.5
而不能是:
code
1.5 1.5
因为后者没有按照指定的格式字符串输入,scanf()函数无法正确解析这两个值分别对应哪个变量x和y。在这种情况下,如果你输入1.5 1.5,scanf()可能会读取第一个1.5赋值给变量x,但第二个1.5由于没有对应的格式说明符,可能会被忽略或者导致读取错误。
在C语言中,除了空格,还有什么也算是字符??
在C语言中,除了空格,以下所有字符都被视为字符:
1. 所有的字母:包括大写和小写的英文字母、其他语言的字母(如德语、法语、中文等)。
2. 数字:0-9。
3. 特殊符号:包括 punctuation marks(如逗号、句号、问号、感叹号等)、运算符(如+、-、*、/、%等)、分隔符(如冒号、分号、逗号、引号等)、特殊控制字符(如换行符 `\n`、制表符 `\t`、回车符 `\r` 等)。
4. 控制字符:这些是不可见的字符,例如换行符 (`\n`)、制表符 (`\t`)、退格符 (`\b`) 等。
5. 所有的Unicode字符:包括各种语言的字符、表情符号等。
在C语言中,每个字符都被表示为一个整数值,这个值对应于该字符在ASCII或Unicode字符集中的位置。因此,从计算机的角度来看,所有这些字符都视为不同的数字或编码。
?在C语言中,什么是标准库函数,在调用时有什么注意
在C语言中,标准库函数是指由C语言标准定义的一组预先编写好的、可重用的函数。这些函数提供了各种基本的编程功能,包括输入/输出操作、字符串处理、内存管理、数学运算、数据类型转换等。标准库函数是C语言编译器的一部分,通常在头文件(如`stdio.h`、`string.h`、`math.h`等)中声明,并在链接阶段与用户代码一起链接。
调用标准库函数时需要注意以下几点:
1. **包含正确的头文件**:在使用任何标准库函数之前,需要在源代码中包含相应的头文件。例如,如果你要使用`printf()`和`scanf()`函数,你需要包含`stdio.h`头文件。
2. **理解函数的行为和返回值**:每个标准库函数都有特定的功能和返回值。在使用前,应查阅相关文档以了解其参数、返回值以及可能的错误情况。
3. **正确传递参数**:确保按照函数原型的要求正确地传递参数。例如,某些函数可能需要指针作为参数,而其他函数可能需要常量或变量。
4. **检查函数的返回值**:许多标准库函数会返回一个状态值来表示操作是否成功。在调用函数后,应该检查返回值以确定操作是否按预期执行。
5. **缓冲区溢出和安全性**:某些标准库函数(如`gets()`)存在安全风险,可能导致缓冲区溢出。应尽量使用更安全的替代函数(如`fgets()`)并注意限制输入的大小。
6. **内存管理**:对于涉及动态内存分配的函数(如`malloc()`和`calloc()`),记得在使用完内存后使用`free()`函数释放,以避免内存泄漏。
7. **遵循良好的编程实践**:在使用标准库函数时,遵循良好的编程实践,如适当的错误处理、注释和文档化代码。
8. **跨平台兼容性**:虽然标准库函数在大多数C编译器中都是可用的,但不同平台上的实现可能存在细微差别。在编写跨平台代码时,需要注意这些差异并进行适配。
用户可以重新定义标准库函数吗
在C语言中,用户理论上可以重新定义标准库函数,但是这种做法强烈不推荐,因为这样做可能会导致以下问题:
1. **命名冲突**:当你重新定义标准库函数时,你可能会覆盖编译器自带的函数实现,导致程序行为不可预测。
2. **兼容性问题**:不同的C编译器和库可能对标准库函数有不同的实现。如果你重新定义了这些函数,你的代码可能无法在其他环境中正确运行。
3. **维护困难**:当你重新定义标准库函数时,你将负责维护这个函数的行为和兼容性。这会增加代码的复杂性和维护成本。
4. **难以调试**:如果你的程序出现问题,由于你已经改变了标准库函数的行为,调试过程可能会变得更加困难。
5. **违反编程规范**:重新定义标准库函数通常被视为不良编程实践,因为它破坏了代码的清晰性和可读性。
为了避免上述问题,建议遵循以下最佳实践:
- **避免重定义标准库函数**:除非你有非常特殊的需求并且完全理解可能的后果,否则应避免重定义标准库函数。
- **使用自定义函数名称**:如果你需要实现类似功能的函数,为你的函数选择一个不同于标准库函数的名称,以避免命名冲突。
- **封装和扩展**:如果需要修改或扩展标准库函数的行为,考虑在你的代码中创建一个新的函数,该函数调用标准库函数并进行必要的修改或扩展。
总之,虽然从技术上讲可以重新定义标准库函数,但这样做通常会导致各种问题和不良后果。因此,应该尽量避免这样做,并遵循良好的编程实践。
?用户如果重新定义标准库函数,重新定义后,该库函数将会失去原有含义吗
如果用户重新定义标准库函数,那么在该作用域内,原有的标准库函数的确会失去其原有的含义。这是因为当你重新定义一个已经存在的函数时,编译器将使用你的新定义而不是原来的定义。
然而,这种做法有严重的风险和后果:
1. **命名冲突**:你可能会无意中覆盖了编译器自带的函数实现,导致程序行为不可预测。
2. **兼容性问题**:不同的C编译器和库可能对标准库函数有不同的实现。如果你重新定义了这些函数,你的代码可能无法在其他环境中正确运行。
3. **维护困难**:当你重新定义标准库函数时,你将负责维护这个函数的行为和兼容性。这会增加代码的复杂性和维护成本。
4. **难以调试**:如果你的程序出现问题,由于你已经改变了标准库函数的行为,调试过程可能会变得更加困难。
5. **违反编程规范**:重新定义标准库函数通常被视为不良编程实践,因为它破坏了代码的清晰性和可读性。
因此,尽管重新定义标准库函数会导致原有函数失去其含义,但强烈建议避免这样做。如果你需要自定义功能,应该创建一个新的函数并使用不同的名称,以防止与标准库函数产生冲突。这样可以确保代码的可读性、可维护性和跨平台兼容性。
表达式 `18/4*sqrt(4)` 的数据类型在 C 语言中取决于上下文和编译器的实现。
在这个表达式中:
- `18` 和 `4` 是整数常量,它们的数据类型是 `int`。
- `/` 运算符用于两个整数之间的除法,根据C语言的标准,结果也是 `int` 类型。由于 `18 / 4` 等于 `4`(向下取整),所以这个子表达式的结果是 `int` 类型。
- `sqrt(4)` 是一个浮点数运算,因为它涉及到平方根计算。`sqrt` 函数通常在数学库(如 `<math.h>`)中定义,返回类型为 `double`。
- `*` 运算符用于将整数和浮点数相乘。在这种情况下,根据 C 语言的类型提升规则,整数会被转换为浮点数,然后进行浮点数乘法。因此,这个子表达式的结果是 `double` 类型。
综上所述,表达式 `18/4*sqrt(4)` 的最终数据类型是 `double`。不过请注意,如果你在没有包含 `<math.h>` 头文件和使用 `sqrt` 函数前缀 `std::`(在C++中)或使用正确的函数原型声明(在C中)的情况下尝试编译这段代码,编译器可能会报错。
16 的平方根是 4。
若有变量定义”int k =5678;“,则printf(”|%06d|\n“,k);”的输出是什么?这里的06代表什么意思。在C语言中。
在C语言中,`printf()`函数中的格式说明符`%06d`表示以十进制形式输出一个整数,且该整数总是在至少6位的宽度内显示。其中:
- `%` 是格式说明符的开始符号。
- `0` 表示在数值前面填充零(而不是空格),以达到指定的最小宽度。
- `6` 是指定的最小宽度,即输出的整数至少占用6个字符的位置。
- `d` 表示输出的是一个十进制整数。
所以,对于变量定义`int k = 5678;`,调用`printf("|%06d|\n", k);`将输出:
```
|005678|
```
注意,由于`k`的值是5678,它本身就有4位数字,加上前导的两个零,总共占用了6个字符的位置。如果数值大于等于10000,那么将会按照实际的数字位数输出,因为指定的宽度6是最低限度,实际宽度会根据数值大小自动调整。
C语言,
int Fun (int a ,int b);
int main (){
int k = 4,m =1,p1,p2;
p1 = Fun(k,m);
p2 = Fun(k,m);
printf("%d %d\n",p1,p2);
}
int Fun(int a, int b){
static int m = 0 ,i =1;
i =m+1;
m+i+a+b;r
eturn m;
}请输出最后正确答案,并解释为什么?


因此,
第一次调用函数 i=1,m=6
第二次调用 i=7 ,m=7+4+1
指针:
这篇好!!!!!!!
?int *p ,m =5,n; p=&n; *p =m
?*p =m: p本身是指针,*p是解引用,那解引用完它就是一个数字。所以是对的。
对于解引用,解释如下:
在C语言中,`*` 符号的含义取决于其上下文:
1. **定义指针变量**:
? ?当 `*` 符号出现在变量声明的类型前面时,它表示该变量是一个指针。例如:
? ?```c
? ?int *ptr; // ptr 是一个指向整数的指针
? ?char *str; // str 是一个指向字符的指针
? ?```
? ?在这种情况下,`*` 表示“指向”。2. **解引用操作符**:
? ?当 `*` 符号出现在已经声明为指针类型的变量前面时,它是一个解引用操作符,用于访问指针所指向的内存位置的值。例如:
? ?```c
? ?int x = 10;
? ?int *ptr = &x; // ptr 指向 x 的地址
? ?int y = *ptr; // 解引用 ptr,将 x 的值(10)赋给 y
? ?```
? ?在这种情况下,`*` 衡量“内容”或“指向的值”。判断 `*` 是作为解引用操作符还是用于定义指针的关键在于观察它出现的位置:
- 如果 `*` 出现在变量声明的类型部分,如 `int *ptr;`,那么它用于定义一个指针变量。
- 如果 `*` 出现在一个已经声明为指针类型的变量名前,如 `int y = *ptr;`,那么它是一个解引用操作符,用于获取指针所指向的值。简而言之,如果 `*` 左侧是类型名,那么它是定义指针;如果 `*` 左侧是一个已声明的指针变量名,那么它是一个解引用操作符。
?int *p ,m =5,n; p=&n; scanf("%d",*p);
错的。
在使用 `scanf()` 函数时,需要提供变量的地址作为参数,而不是变量的值,这是因为 `scanf()` 函数的工作方式是将输入的数据写入到指定内存地址处。
当你传递一个变量的地址给 `scanf()` 时,`scanf()` 知道应该将读取的数据存储到哪个内存位置。它会根据提供的格式字符串(如 `%d`、`%f`、`%s` 等)来解析输入的数据,并将其存入对应的内存地址,也就是你提供的变量地址。
如果传递变量的值给 `scanf()`,那么 `scanf()` 将尝试将数据写入到该值所代表的内存地址,这通常是不正确的,因为这个地址可能没有分配给程序使用,或者可能包含了其他重要的数据,导致程序行为异常或崩溃。
因此,为了正确地使用 `scanf()` 函数读取并存储用户输入的数据,你需要提供变量的地址,而不是其值。
int j ;&j是什么?
在C语言中,
int j;是一个声明语句,它声明了一个名为j的整型变量。
&j是取址运算符(address-of operator)应用于变量j。它返回变量j在内存中的地址。也就是说,&j是一个指向整型变量j的指针。这个指针的类型是int *,表示它可以存储一个整型变量的地址。
 ?
?
?
对于指针运算

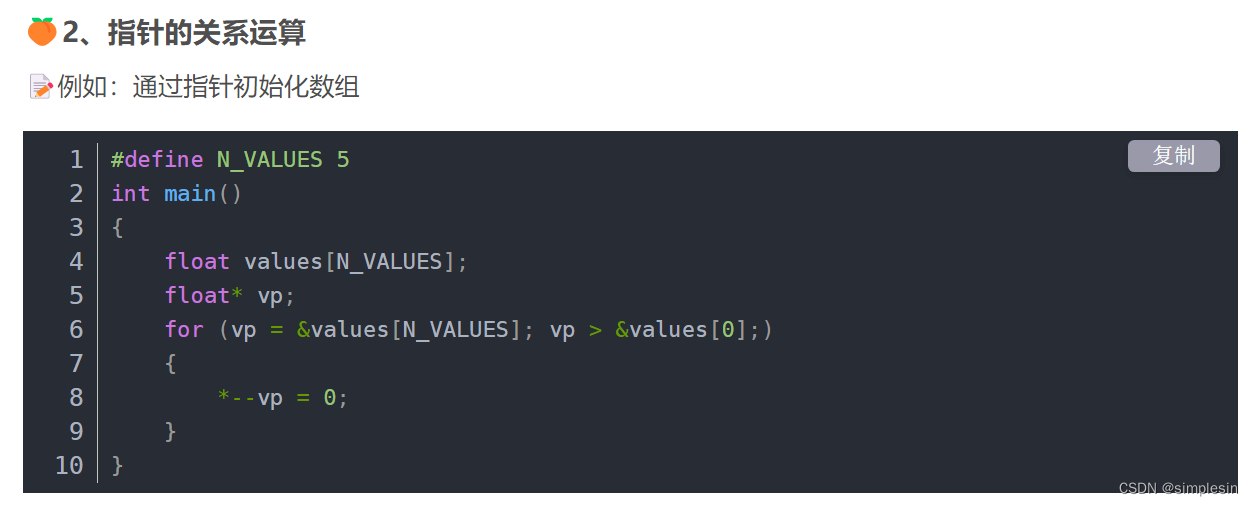
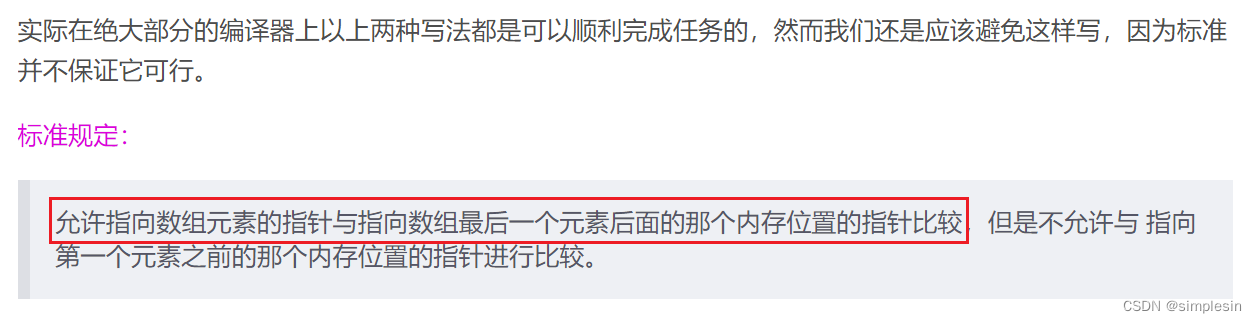
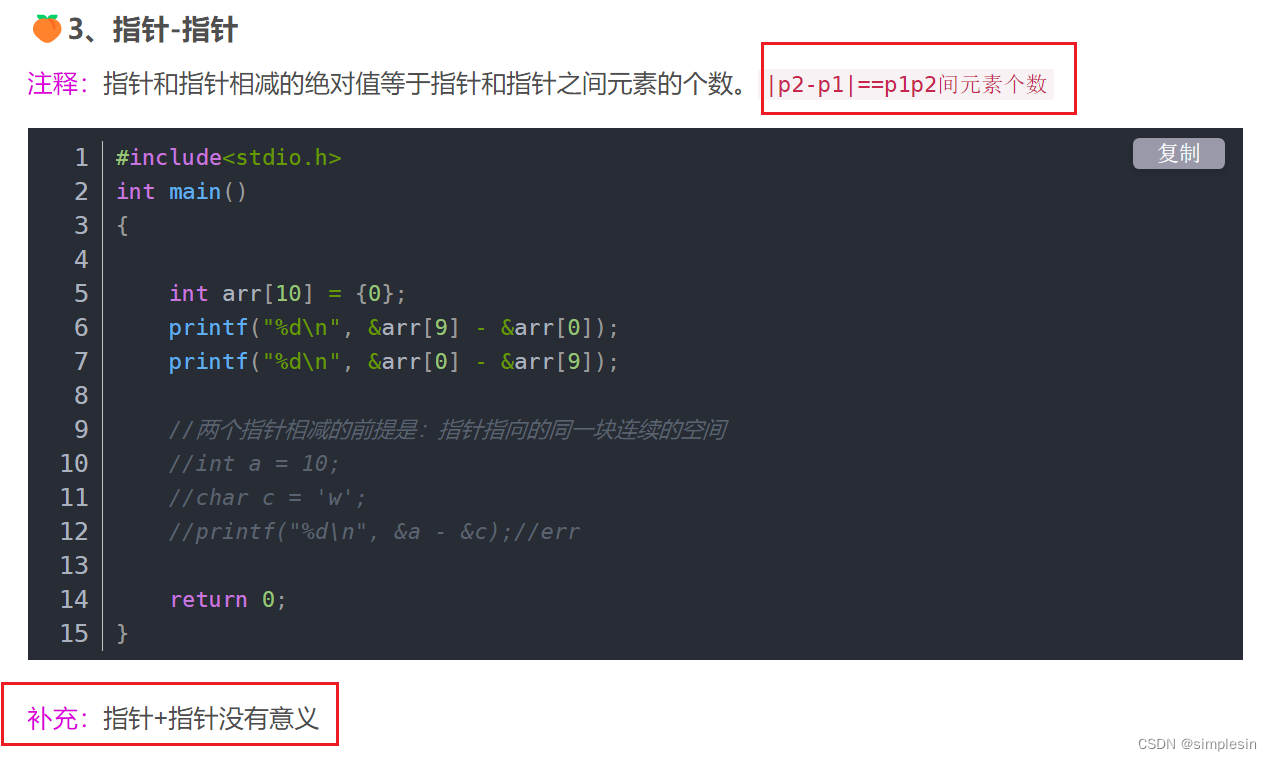 ?
?
int a =5,*p = &a ; *p是什么??
?在给定的C语言代码中:
```c
int a = 5, *p = &a;
```这里声明了一个整型变量 `a` 并初始化为 5,同时声明了一个指向整型变量的指针 `p`,并将其初始化为变量 `a` 的地址。
接下来的表达式 `*p` 是一个解引用操作符应用于指针变量 `p`。由于 `p` 指向变量 `a`,所以 `*p` 将访问 `p` 所指向的内存位置的值,即变量 `a` 的值。
因此,在这个上下文中,`*p` 等于变量 `a` 的值,也就是 5。
有指针p,q,现在,temp =*p ;*p =*q ;*q =temp 和 temp =p ;p =q ;q =temp 有什么区别?
这两段代码中的指针p和q的操作有不同的含义:
1. `temp = *p; *p = *q; *q = temp;`
这段代码是在操作指针所指向的变量的值。首先,将指针p所指向的变量的值赋给临时变量temp。然后,将指针q所指向的变量的值赋给指针p所指向的变量。最后,将临时变量temp的值(即原来指针p所指向的变量的值)赋给指针q所指向的变量。
通过这段代码,实现了指针p和q所指向的变量的值的交换。
2. `temp = p; p = q; q = temp;`
这段代码是在操作指针本身的值。首先,将指针p的值(即它所指向的地址)赋给临时变量temp。然后,将指针q的值(即它所指向的地址)赋给指针p。最后,将临时变量temp的值(即原来指针p的值)赋给指针q。
通过这段代码,实现了指针p和q本身的值(即它们所指向的地址)的交换。
所以,两段代码的主要区别在于:第一段代码交换的是指针所指向的变量的值,而第二段代码交换的是指针本身的值(即它们所指向的地址)。
在以下程序段中,目标是找到数组a中的最大值:
```c
int a[5] = {3, 5, 1, 8, 6}, *p, *q;
for (p = a, q = a; p < a + 5; p++)?
? ? if (*p > *q)?
? ? ? ? q = p;?
printf("%d\n", *q);
```在if语句中,不能使用 `p - a > q - a` 来判断哪个元素更大,因为 `p - a` 和 `q - a` 表示的是指针p和q距离数组a起始地址的偏移量,而不是它们所指向的元素的值。
要找到数组中的最大值,我们需要比较的是指针p和q所指向的元素的值,即 `*p` 和 `*q`。因此,在if语句中应填入 `*p > *q`。每当遇到一个比当前最大值(由指针q指向)更大的元素时,就更新q为指向这个更大的元素。循环结束后,指针q将指向数组中的最大值,输出 `*q` 即可得到结果。
int a =5 ,*p = &a; printf("%d %d\n", a, *p);*p =8; printf("%d %d\n", a, *p);return 0; 解释一下代码过程?
这段C语言代码的执行过程如下:
1. `int a = 5, *p = &a;`
? ?定义一个整型变量a,并初始化为5。同时,定义一个指向整型变量的指针变量p,并将其初始化为变量a的地址。
2. `printf("%d %d\n", a, *p);`
? ?使用printf函数输出两个整数,第一个是变量a的值(5),第二个是通过指针p访问的变量a的值(也是5)。
3. `*p = 8;`
? ?通过指针p将变量a的值修改为8。现在,变量a的值变为8,而指针p仍然指向变量a的地址。
4. `printf("%d %d\n", a, *p);`
? ?再次使用printf函数输出两个整数,第一个是变量a的值(已改为8),第二个是通过指针p访问的变量a的值(也是8)。
5. `return 0;`
? ?结束程序并返回0,表示程序执行成功。
总结:这段代码首先定义了一个整型变量a和一个指向a的指针变量p,然后输出了它们的初始值。接着,通过指针p修改了变量a的值,并再次输出了它们的值。整个过程中,指针p一直指向变量a的地址,因此通过指针p可以改变变量a的值。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 往adobe illustrator中添加latex字体
- 淘宝爬虫评论数据采集的探索之旅
- Tekton 基于 cronjob 触发流水线
- selenium + chrome109以上版本会自动在C:\Program Files (x86)目录下创建scoped_dir*文件夹
- 使用idea开发servlet
- git 如何将某个分支的某个提交复制到另外一个分支
- CSS||选择器
- vue+elementUI el-row和el-col 自动滚动table表格组件封装—基础版
- Linux防护与群集 第一章
- STM32CubeMX教程20 SPI - W25Q128驱动