protobuf
protobuf 简介
概念
protobuf 全称 Protocol buffers,是 Google 研发的一种跨语言、跨平台的序列化数据结构的方式,是一个灵活的、高效的用于序列化数据的协议。
特点
在序列化数据时常用的数据格式还有 XML、JSON 等,相比较而言,protobuf 更小、效率更高且使用更为便捷,protobuf 内置编译器,可以将 protobuf 文件编译成 C++、Python、Java、C#、Go 等多种语言对应的代码,然后可以直接被对应语言使用,轻松实现对数据流的读或写操作而不需要再做特殊解析。
Protobuf的优点如下:
1.高效一一序列化后字节占用空间比 XML 少3-10倍,序列化的时间效率比 XML 快 20-100 倍;
2.便捷——可以将结构化数据封装为类,使用方便;
3.跨语言——支持多种编程语言;
4.高兼容性——当数据交互的双方使用同一数据协议,如果一方修改了数据结构,不影响另一方的使
用。
Protobuf 也有缺点:
1.二进制格式易读性差;
2.缺乏自描述。
基本使用流程
在bazel中已经集成了protobuf的编译器,所以直接使用即可。
protobuf的基本使用,需求如下:
创建 protobuf 文件,在该文件中需要生命学生的姓名、年龄、身高、所有的书籍…等信息,然后分别使用C++和Python实现学生数据的读写操作。
实现大致流程如下:
1.编写 proto 文件;
2.配置 BUILD 文件,编译生成对应的 C++ 或 Python 文件;
3.在 C++ 或 Python 中调用。
proto 使用之文件创建
创建 proto 文件
在 /apollo/cyber 目录下新建文件夹 demo_base_proto,文件夹下新建文件 student.proto,并输入如下内容:
//使用的 proto 版本,cyber RT 中目前使用的是 proto2
syntax = "proto2";
//包
package apollo.cyber.demo_base_proto;
//消息 ——message 是关键字,Student 消息名称
message Student {
//字段
//字段格式:字段规则,数据类型,字段名称,字段编号
required string name = 1;
optional uint64 age = 2;
optional double height = 3;
repeated string books = 4;
}
proto 中的字段语法,字段就格式而言主要有四部分组成:字段规则、数据类型、字段名称、字段编号。
1.字段规则
字段类型主要有如下三种:
required——调用时,必须提供该字段的值,否则该消息将被视为"未初始化",不建议使用,当需要把字段修改为其他规则时,会存在兼容性问题。
optional——调用时该字段的值可以设置也可以不设置,不设置时,会根据数据类型生成默认值。repeated ——该规则字段可以以动态数组的方式存储多个数据。
2.数据类型
protobuf 中的数据类型与不同的编程语言存在一定的映射关系,具体可参考官方资料,如下:
 官方网站:https://protobuf.dev/programming-guides/proto2/
官方网站:https://protobuf.dev/programming-guides/proto2/
3.字段名称
变量名
4.字段编号
每个字段都有唯一编号,用于在二进制格式中标识字段。
proto 文件编译
1.编辑 BUILD 文件
在 demo_base_proto 目录下新建 BUILD 文件,并输入以下内容:
load("//tools:python_rules.bzl","py_proto_library")
package(default_visibility = ["//visibility:public"])
proto_library(
name="student_proto",
srcs=["student.proto"]
)
cc_proto_library(
name = "student_cc",
deps = [":student_proto"],
)
py_proto_library(
name = "student_py",
deps = [":student_proto"]
)
代码解释:
1.proto_library 函数
该函数用于生成 proto 文件对应的库,该库被其他编程语言创建依赖库时所依赖。
参数:
name:目标名称
srcs:proto 文件
2.cc_proto_library 函数
该函数用于生成C++相关的proto依赖库
参数:
name:目标名称
deps:依赖的 proto 库名称
3.py_proto_library 函数
该函数用于生成 python 相关的 proto 依赖库
参数:
name:目标名称
deps:依赖的proto 库名称。
注意:
1.使用 py_proto_library 必须声明 load(“M/ltools:python_rules.bzl”, “py_proto_library”);
2.proto_library 函数的参数 name 值必须后缀 _proto 否则,python调用时会抛出异常;
3.为了方便后期使用,建议先添加语句:package(default_visibility = [“//visibility_public”])。
2.编译
终端进入 /apollo 目录,执行编译命令:
bazel build cyber/demo_base_proto/...
在 /apollo/bazel-bin/cyber/demo_base_proto 下将生成可以被 C++ 和 python 调用的中间文件。

proto 读写之 C++ 实现
大致步骤如下:
1.编写C++源文件;
2.配置 BUILD 文件;
3.编译;
4.执行。
1.编写 C++ 源文件
/*
演示C++ 中 protobuf 的基本读写使用
*/
#include "cyber/demo_base_proto/student.pb.h"
using namespace std;
int main(int argc, char const *argv[])
{
//创建对象
apollo::cyber::demo_base_proto::Student stu;
//数据写
stu.set_name("zhangsan");
stu.set_age(18);
stu.set_height(1.75);
stu.add_books("yuwen");
stu.add_books("shuxue");
stu.add_books("english");
//读数据
string name=stu.name();
uint64_t age=stu.age();
double height=stu.height();
cout<<"name:"<<name<<"; age:"<<age<<";height:"<<height<<endl;
for(int i=0;i<stu.books_size();i++){
string book = stu.books(i);
cout << book<<" ";
}
cout<<endl;
return 0;
}
代码解释:
proto 文件生成的对应的 C++ 源码中,字段的设置与获取有其默认规则:
1.如果是非repeated规则的字段:那么字段值的设置函数对应的格式为: set_xxx(value),获取函数对应的格式为xxx()。
2.如果是repeated规则的字段:那么字段值的设置函数对应的格式为: add_xxx(),获取函数对应的格式为xxx(索引),另外还可以通过函数xxx_size()获取数组中元素的个数。
2.编写BUILD文件
cc_binary(
name="test_student",
srcs=["test_student.cc"],
deps=[":student_cc"]
)
3.编译以及执行
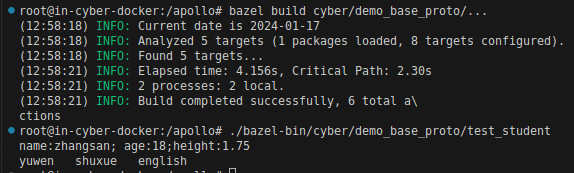
proto 读写之python实现
1.编写 Python源文件;
2.配置 BUILD文件;
3.编译;
4.执行。
1.编写 python 源文件
#!/usr/bin/env python3
from cyber.demo_base_proto.student_pb2 import Student
if __name__ =="__main__":
#创建 student对象
stu = Student()
# 写数据
stu.name="automan"
stu.age=8
stu.height=1.4
stu.books.append("class1")
stu.books.append("class2")
stu.books.append("class3")
# 读数据
print("name = %s, age = %d, height = %.2f" %(stu.name,stu.age,stu.height))
for book in stu.books:
print("book = %s" %book)
2.编辑 BUILD
py_binary(
name="test_student_py",
srcs=["test_student_py.py"],
deps=[":student_py"]
)
3.编译和执行

。。。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 电子学会C/C++编程等级考试2023年09月(七级)真题解析
- 基于easyexcel实现导出excel,包括导出图片以及导出下拉框
- 编译原理 sql简易编译器
- 使用FPDF生成不同样式的PDF表格数据
- SLAM中用到的GTSAM是什么,如何构建和使用GTSAM
- 软件测试|Chrome 115之后的版本,如何更新driver?
- 递归算法实现进制转换
- 全网最新Q绑查询手机号工具(三)
- 基于自定义权重的支持向量机,基于自定义权重的SVM
- 【服务器NextChat】创建部署NextChat网站