大模型Transformer 推理 :kvCache原理浅析
发布时间:2023年12月18日
大模型Transformer 推理 :kvCache原理浅析
kvCache 原理
在采样时,Transformer模型会以给定的提示/上下文作为初始输入进行推理(可以并行处理),然后逐一生成额外的标记来继续完善生成的序列(体现了模型的自回归性质)。在采样过程中,Transformer会执行自注意力操作,为此需要给当前序列中的每个元素(无论是提示/上下文还是生成的标记)提取键值(kv)向量。这些向量存储在一个矩阵中,通常被称为kv缓存或者past缓存(开源GPT-2的实现称其为past缓存)。past缓存通常表示为:[batch, 2, num_heads, seq_len, features]
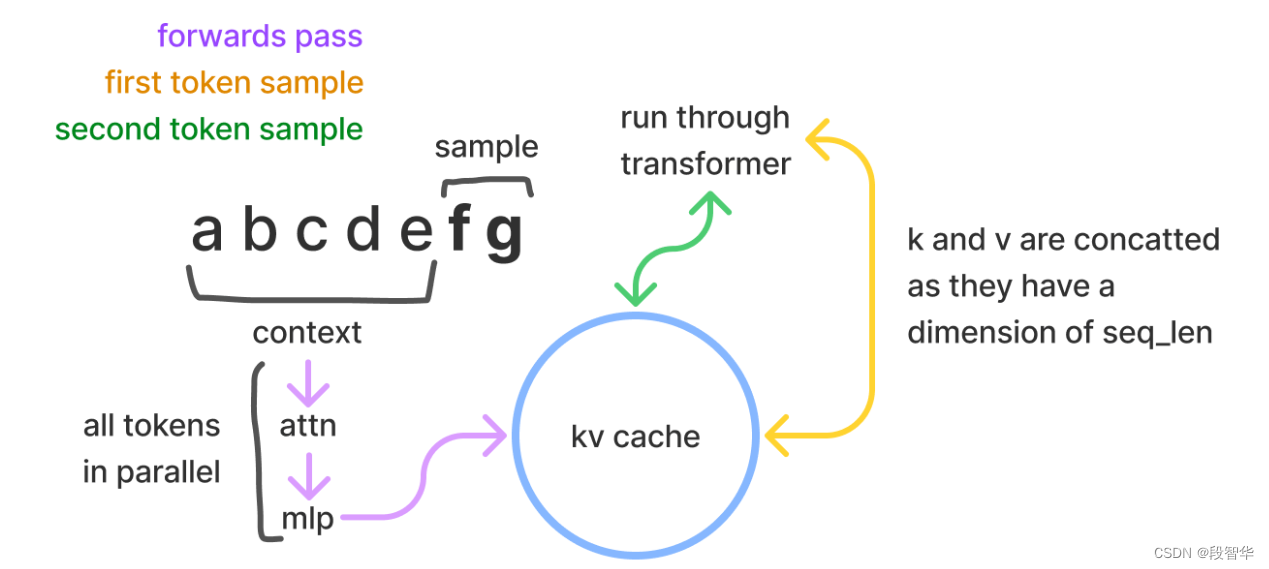
kv缓存是为了避免每次采样标记时重新计算key键向量、value值向量。利用预先计算好的k值和v值,可以节省大量计算时间,尽管这会占用一定的存储空间。每个token所存储的字节数为:
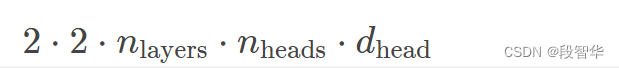
- 第一个2表示k和v这两个向量。在每一层中我们都要存储这些k,v向量,每个值都为一个矩阵。
- 然后再乘以2,以计算每个向量所需的字节数,假设采用16位格式。
所有层的k和v需进行的浮点运算次数为:
文章来源:https://blog.csdn.net/duan_zhihua/article/details/134799301
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RabbitMQ交换机
- 安科瑞Acrel-2000MG微电网能量管理系统 光伏 储能风电负荷——安科瑞 顾烊宇
- 轻松传输文件,高效管理数据——FileZilla FTP 免费客户端完美解决方案
- 电机(一):直流有刷电机和舵机
- SpringBoot整合RocketMQ
- 《Kotlin核心编程》笔记:面向表达式编程
- Jmeter 性能 —— 阶梯负载最终请求数!
- c语言函数篇——递归函数
- centos通过yum 安装nginx和基本操作
- React16源码: React中的HostComponent & HostText的源码实现