neural network basics2-2
common neural networks
两个比较常见的神经网络模型:循环神经网络RNN和卷积神经网络CNN
RNN
sequential memory;??language model
gradient problem for rnn
variants:GRU; LSTML;Bidirectional;
1、sequential memory:它在处理这个序列数据的期间,会进行一个顺序的记忆
序列数据:如:听到的一句话,一段音频
顺序记忆:如:人在读取字母表的时候,由于我们的经验,因此在看这个字母表的时候是非常容易没有卡顿的,但是当我们把字母表倒置一下,这时候读起来就会有一定的难度


因此,顺序记忆就是我们的大脑更容易识别这些序列模式的数据的一个机制,而RNN可以很好的利用这个机制来递归地进行更新我们这个生命记忆,以此来对我们这些序列数据进行一个很好的建模

如下是一个比较典型的一个RNN的神经网络结构:
输入层:通常是不定长的序列数据,如:我们说的一句话,
当我们把这个数据输入到我们的隐藏层之后,其h0、h1、h2、h3表示这个是一个不同时间步下的一个状态变量,它存储着过去的一集当前我们输入的一些信息,这里的不同时间步,不一定是我们寻常意义上的一个时间,可以理解为表示具有前后顺序的一个变量
y1、y2、y3分别表示对应每一个输入的一个输出
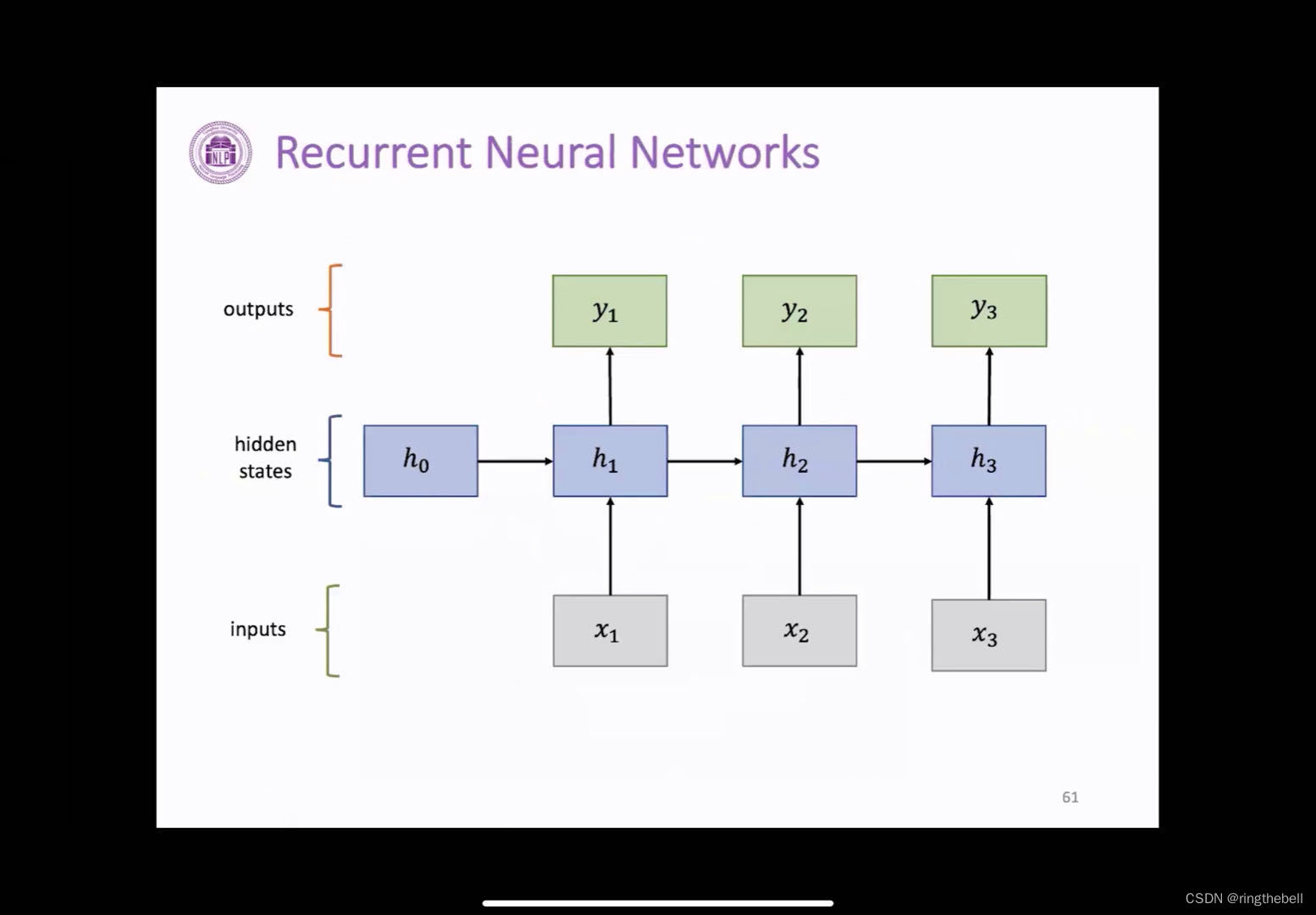
数据的走向
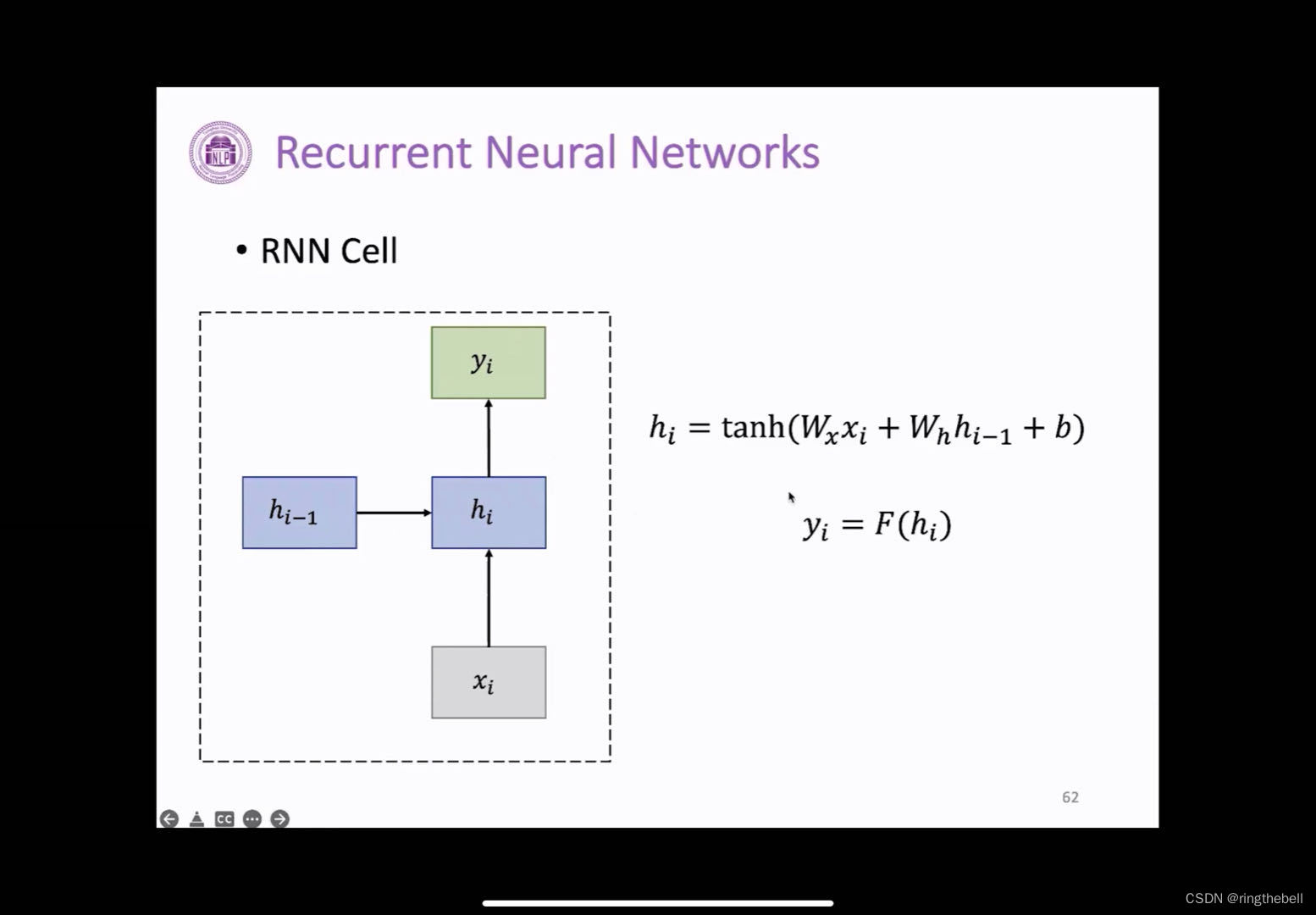
由公式可以看出,RNN是一个顺序的记忆,因为它每一个时间步下这个隐藏状态变量计算都包含了我们过去的一个时间,即都是由过去的这个隐藏状态变量才能得到的,它是一个一个计算按照顺序来
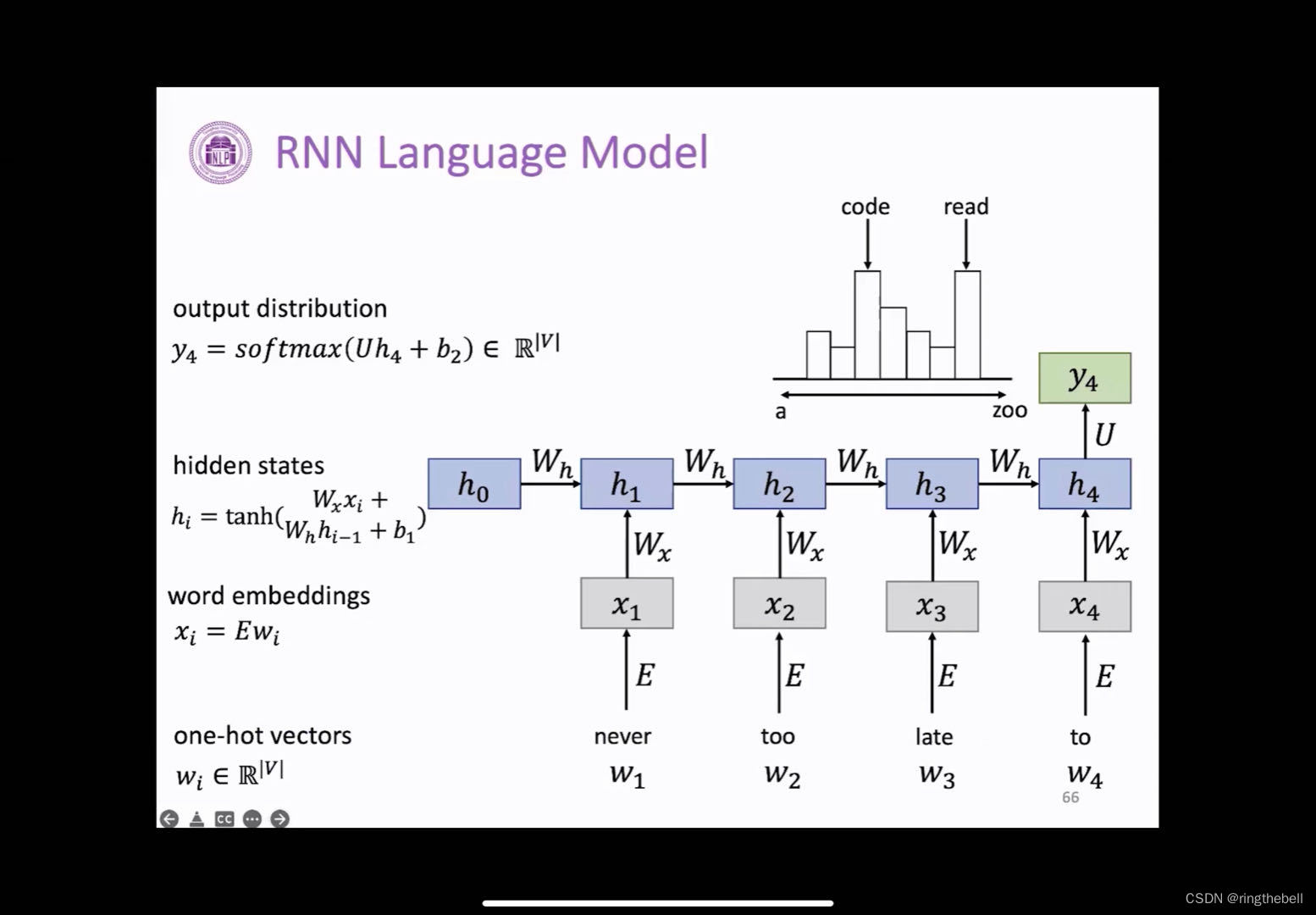
eg:输入一句话的前面几个词,来预测我们的下一个词是什么:
第一个词never,获得它的one-hot向量,经过预处理获得它的词向量,即转化成一个语义更丰富的一个向量,然后按照之前计算的这个方式,在得到xi之后要计算这个hi-1,h1包含上一个时间步的h0,以及我们当前的这个x1这个输入来组成的,(注意:这里的h0,都是我们随机进行初始化的,因为它之前没有这个状态),所以我们第一个词的计算方式是这样的,随后的每个词计算方式也是如此
计算后,就要预测to后面我们需要跟什么词,这个时候需要我们计算这个h4,因为h4
包含了前面4个词的所有的信息,所以可能可以对整个句子的语义有一个很好的把握,然后当我们获取到h4这个向量的时候,我们一般会经过一个线性层,用过一个softmax进行处理,然后输出词表上的每个词的概率,我们选择概率最大的词来作为我们的预测词,这里可能是code或者read,所以整句话连起来可能是never too late to code 或者是never too late to read
其中,wh和wx这个矩阵都是一样的,因为在这个里面,整个结构都是每一个RNN的单元的不断地复制,所以这里每个RNN单元它的功能都是一样的,可以很好地实现参数共享,这样不仅可能会有助于我们模型能够泛化到不同长度的样本,而且也有助于我们更好地进行学习,同时也会节省参数量,因为参数量和我们序列数据是没有关系的。
RNN的应用场景也很多
序列标注:给定一句话的时候,我们可能会要求给出每个词的词性
序列预测:如:给定一周七天的温度,我们来预测每一天的天气情况如何
图片描述:如:我们给一张图片,或要求生成一句话来描述这个图片的内容
文本分类:给定一个句子,我们会要求区别这句话,它的情感倾向是正面的还是负面的

RNN的优点和缺点:
优点:
1、可处理变长的数据
2、模型的大小不会随着输入的增加而增大,因为我们这里面的权重基本上是共享的,有一个很好的参数共享,
3、而且通过前面的机制也可以了解到,我们后面的这些信息计算的时候是在理论上也可以使用到我们之前的这个信息的
缺点:
因为我们这里是一个顺序计算,需要用到前一个单元的学习结果才能得到后一个的学习结果,所以我们时间上可能会比较慢,而且我们在实际场景应用中会发现,随着我们时间步的不停地往后进行推移,我们后面的一些单元进行计算可能就很难获取到我们之前那些信息单元的计算

比较出名的一个问题就是梯度消失或者梯度爆炸
对于hi,除了当前的输入,还会包含之前时间步的状态变量hi-1,这又会包含更之前的hi-2,一直往后推,我们随着层数的增多,也会越来越多,所以我们在进行反向传播的时候,由于链式法则,其反向传播是一层套着一层,然后从后往前推
以计算faihn为例,当我们计算这个梯度大于1的时候,就随着这个层数的增加,它的梯度会呈现一个指数型的增长,即,梯度爆炸。
而当我们这个梯度小于1的时候,,它会呈现一个指数型的衰减,也是呈一个梯度型的,而且它这个根本的目的也是我们所说的,它会有太多的链式梯度计算。
一般情况下,梯度爆炸很少会出现,比较多的是梯度消失。
因此,这个我们应该怎么解决?用RNN variants(RNN变体)
前面介绍的RNN模型一般都是由一个单元组成,所以它的核心也是在这个单元上,因此我们需要对这个单元进行优化,来找一个更好更复杂的一个单元计算,其中RNN比较有名的这个变体代表有两个,一个GRU,一个LSTM
他们的核心就是,在计算的时候,保存我们当前周围的这些数据,以捕捉到我们长距离的依赖性。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 运维工程师的出路到底在哪里?
- 用js做点击切换携程旅游
- 2024年起重机司机(限桥式起重机)证考试题库及起重机司机(限桥式起重机)试题解析
- 上海开融资融券账户交易佣金利率最低是多少?佣金万一+融资融券4.5%!
- 【Python】内置的type()函数详解和示例
- 基于Vue+node.js的宿舍管理系统的设计与实现-计算机毕业设计源码80331
- 华为全屋wifi6蜂鸟套装标准
- 什么是POM设计模式?
- 文件夹怎么加密?电脑文件夹加密方法介绍
- 毕业设计:基于python淘宝数据采集分析可视化系统 商品销量数据分析 大数据项目(附源码+文档)?