注意力机制
self-attention是什么?是自己注意自己吗?
Q K V又是什么?
为什么它们要叫query、key、value,它们有啥关系?
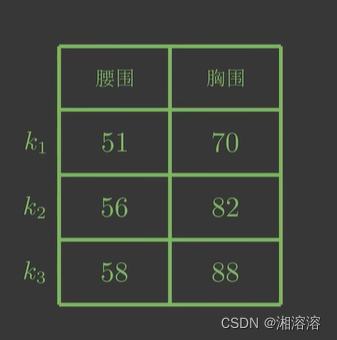
先来看一个问题,假设现在我们有一个键值对(字典),如下图
我们想要求腰围为57对应的体重是什么,显然57在56-58之间,所以体重在43-48之间
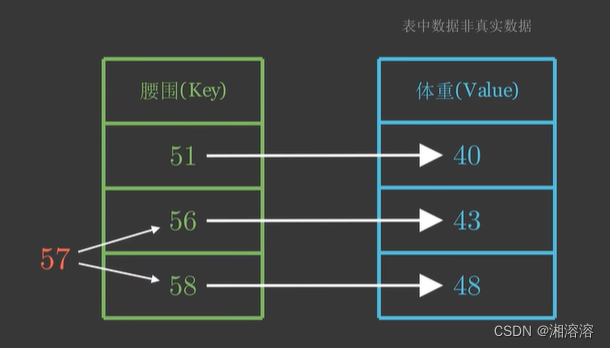
但是还需要定量计算体重预测值。
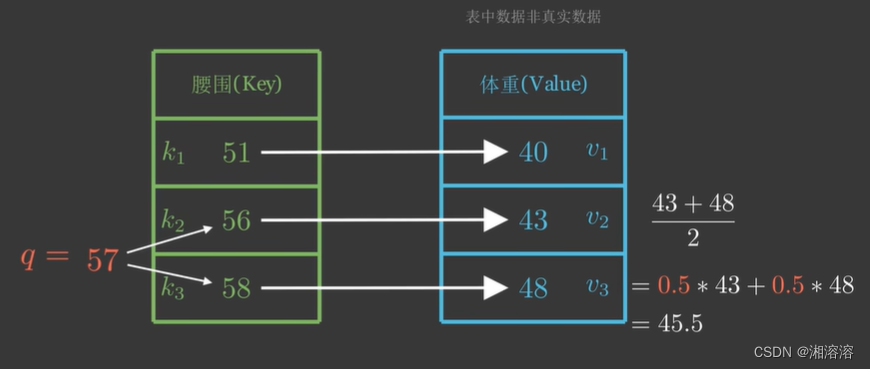
由于57到56、58的距离一样,所以另一种方法是取它们对应体重的平均值 (43+48)/2=0.543+0.548=45.5
因为57距离56、58最近,我们自然会非常“注意”它们,所以我们分给它们的注意力权重各为0.5
但是以上计算没有用到其他(key、value)
我们应该调整一下注意力权重,但权重如何计算?
假设用α(q,ki)来表示q与k对应的注意力权重,则体重预测值f(q)为

α是任意能刻画相关性的函数,但需要归一化,以高斯核(注意力分数)为例(包括softmax函数)

通过这种方式就可以求得体重预估值,也就是注意力机制(attention)
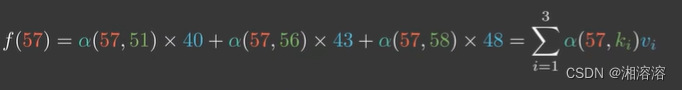
所以把q叫做query(请求),k叫做key(键),v叫做value(值)
q、k、v都为多维的情况也是类似的
假设现在给出的q和k是二维的
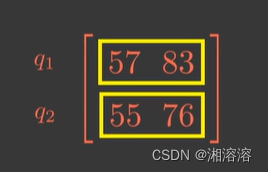

由于q1和k1都是二维向量
注意力分数α(q,ki)可以是以下几种
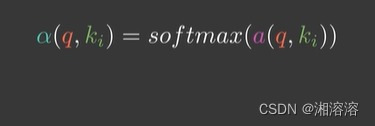

以点积模型为例
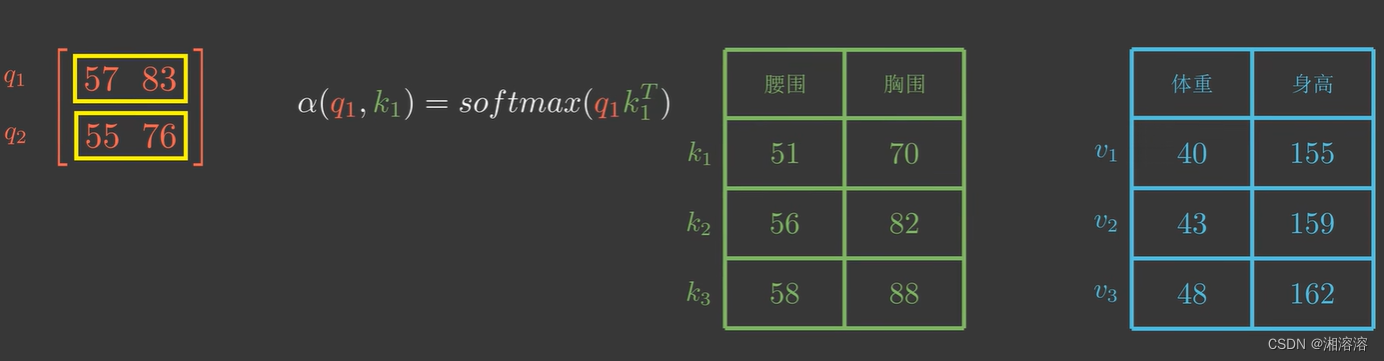
q2也是类似的
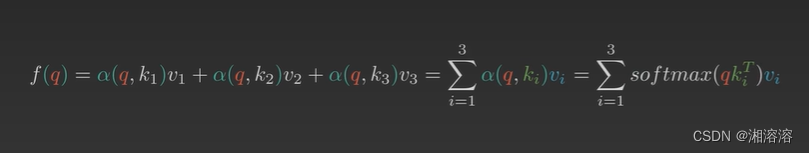
用矩阵来表示


将以上一系列操作称为缩放点积注意力模型(scaled dot-product attention)
如果Q、K、V是同一个矩阵会发生什么?
即自注意力(self-attention)
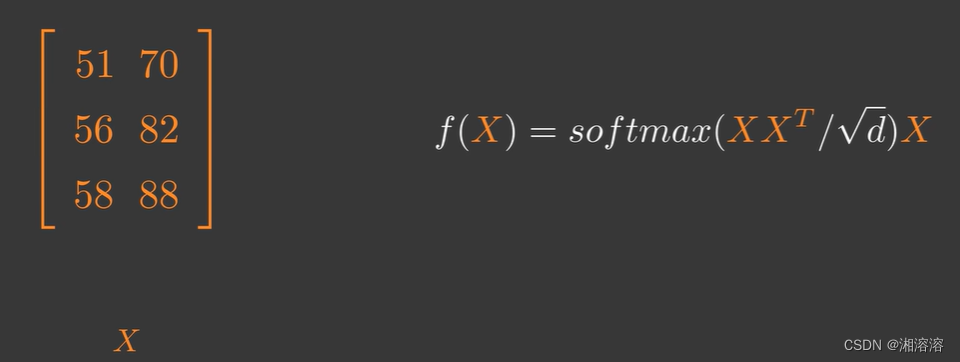
但在实际运用中可能会对X先做不同的线性变换再输入,比如transformer模型
Wq Wk Wv是三个可以训练的矩阵
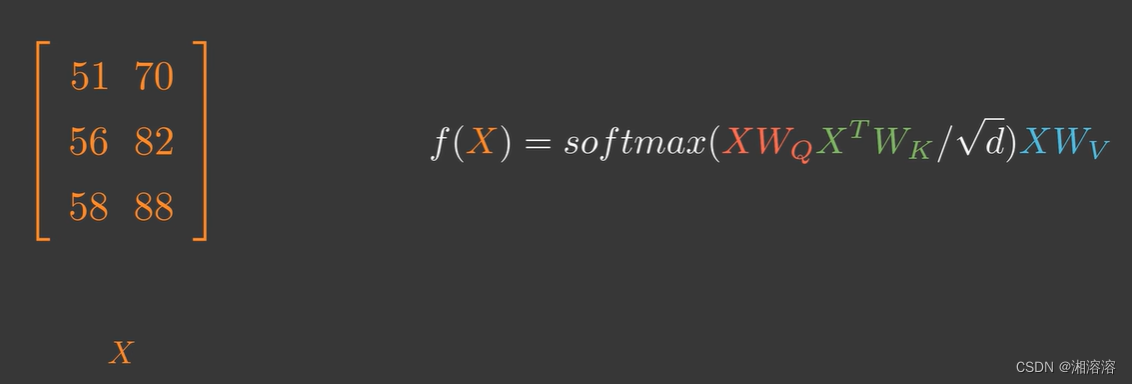
这可能是因为X转换空间后能更加专注注意力的学习
以上内容是以下视频的笔记
【注意力机制的本质|Self-Attention|Transformer|QKV矩阵】https://www.bilibili.com/video/BV1dt4y1J7ov?vd_source=da2cf0642d93108949f85aeccf95736a
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!