go实现判断20000数据范围内哪些是素数(只能被1和它本身整除的数),采用多协程和管道实现
实现一个并发程序,用于寻找 20000 以内的所有素数。使用了 Goroutines 和 Channels 来分发和处理任务,并通过 WaitGroup(实现为 exitChan)来同步 Goroutines 的退出。
一.GO代码
package main
import (
"fmt"
"time"
)
// 判断20000数据范围内哪些是素数(只能被1和它本身整除的数) 开启4个协程完成 采用管道同步通信 sync.WaitGroup
// WaitGroup 通常用于当只需要知道一组 Goroutines 何时结束,而不需要它们之间通信的场景
func main() {
// 创建用于保存待检查数字的通道
intChan := make(chan int, 1000)
// 创建用于保存素数结果的通道
primeChan := make(chan int, 2000)
// 创建用于协调 Goroutines 退出的通道
exitChan := make(chan bool, 4) // 协程数量并不是越多越快 根据CPU核数改变充分利用CPU性能
// 开始时间 时间戳
//startTime := time.Now().Unix()
startTime := time.Now()
// 开启一个 Goroutine 向 intChan 写入数据
go putNum(intChan)
// 开启 8 个 Goroutines 从 intChan 读取数据并判断是否为素数
for i := 0; i < cap(exitChan); i++ {
go primeNum(intChan, primeChan, exitChan)
}
// 开启一个匿名 Goroutine 等待所有 primeNum Goroutines 完成
go func() {
for i := 0; i < cap(exitChan); i++ {
<-exitChan // 等待每个 primeNum Goroutine 的退出信号
}
// 结束时间
useTime := time.Now().Sub(startTime)
fmt.Println("-----------------所用时间:------------------------", useTime) // 所用时间: 3.1556ms
close(primeChan) // 所有 primeNum Goroutines 完成后关闭 primeChan
}()
for i := 0; i < 10; i++ {
go say(i)
//time.Sleep(time.Second)
}
// 从 primeChan 中读取并打印素数结果
for {
//prime, ok := <-primeChan
_, ok := <-primeChan
if !ok {
break // 如果 primeChan 被关闭,则退出循环
}
//fmt.Println("素数:", prime)
}
fmt.Println("主线程退出!!!!!!!!!!")
}
// putNum 函数:向 intChan 中写入数字
func putNum(intChan chan int) {
for i := 1; i <= 20000; i++ {
intChan <- i // 将数字 1 到 20000 写入 intChan
}
close(intChan) // 写入完成后关闭 intChan
fmt.Println("向intChan写入2000条数据完成")
}
// primeNum 函数:从 intChan 中读取数字并判断是否为素数
func primeNum(intChan chan int, primeChan chan int, exitChan chan bool) {
for {
num, ok := <-intChan // 从 intChan 中读取数据
if !ok {
fmt.Println("其中一个协程数据处理完毕~~~")
break // 如果 intChan 被关闭,则退出循环
}
// 判断读取的数字是否为素数
if isPrime(num) {
primeChan <- num // 如果是素数,将其发送到 primeChan
}
}
exitChan <- true // 发送退出信号到 exitChan
}
// isPrime 函数:判断一个数是否为素数
/*
假设 n 不是素数,那么它可以表示为两个因子的乘积,即 n = a * b。
如果 a 和 b 都大于 sqrt(n)(n 的平方根),那么 a * b 将大于 n,这与 n = a * b 矛盾。
因此,如果 n 有超过1和它本身以外的因子,它必定至少有一个因子是小于或等于 sqrt(n) 的。
*/
func isPrime(n int) bool {
if n == 1 {
return false // 1 不是素数
}
for i := 2; i*i <= n; i++ { //如果一个数不是素数,则它必定有一个因子小于或等于它的平方根。
if n%i == 0 {
return false // 如果 n 能被除了 1 和它本身以外的数整除,则不是素数
}
}
return true // 如果不能被任何数整除,则是素数
}
func say(i int) {
defer func() {
if e := recover(); e != nil {
fmt.Println("eeeeee:", e)
}
}()
if i == 5 {
panic("say-------------------i==5 err")
}
fmt.Printf("协程 %d 执行完毕\n", i)
}
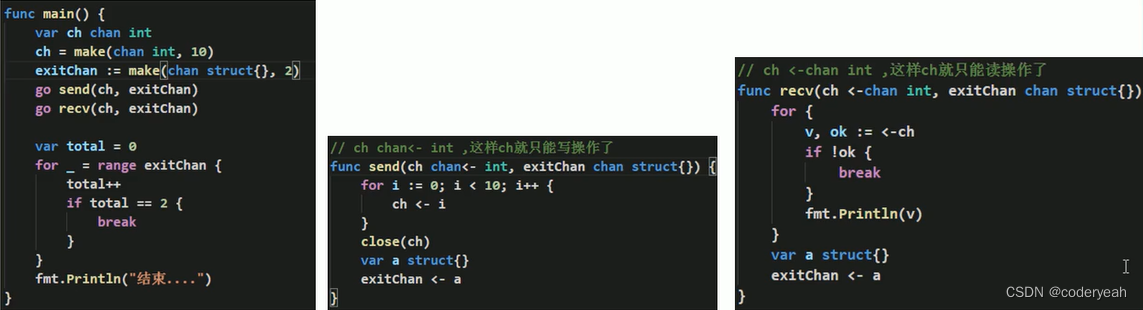
二.管道只读和只写
在 Go 语言中,通道(Channel)是用于在不同的 Goroutines 之间传递数据的一种方式。通道可以是双向的,也可以是单向的。单向通道分为只读和只写通道。这种区分有助于提高程序的类型安全性和清晰性。
1.只读通道(Receive-Only Channel)
只读通道是一种只能从中接收数据的通道。在函数参数中使用只读通道可以确保该函数不会意外地向通道发送数据。
声明只读通道的方式是:<-chan DataType。
2.只写通道(Send-Only Channel)
只写通道是一种只能向其发送数据的通道。在函数参数中使用只写通道可以确保该函数不会意外地从通道读取数据。
声明只写通道的方式是:chan<- DataType。
3.示例
下面是一个简单的例子,展示了如何使用只读和只写通道:
goCopy codepackage main
import (
"fmt"
"time"
)
// 该函数接收一个只写通道参数,只能向该通道发送数据
func sendOnly(ch chan<- int) {
for i := 0; i < 5; i++ {
ch <- i
}
close(ch) // 发送完数据后关闭通道
}
// 该函数接收一个只读通道参数,只能从该通道读取数据
func receiveOnly(ch <-chan int) {
for v := range ch {
fmt.Println("Received:", v)
}
}
func main() {
ch := make(chan int)
go sendOnly(ch) // 启动一个 Goroutine 向通道发送数据
receiveOnly(ch) // 在主 Goroutine 中从通道接收数据
fmt.Println("Done")
}
在这个例子中:
sendOnly函数有一个只写通道参数,它向该通道发送一系列整数,然后关闭通道。receiveOnly函数有一个只读通道参数,它从该通道接收并打印数据,直到通道被关闭。- 在
main函数中,我们创建了一个双向通道ch,然后启动sendOnly函数在一个新的 Goroutine 中运行,并在主 Goroutine 中调用receiveOnly函数。
三.select的应用介绍
在 Go 语言中,select 语句是一种处理多个通道(Channel)的方式。它可以监听多个通道上的发送和接收操作,并且当任何一个通道准备就绪时,select 就会执行该操作。如果多个通道同时就绪,select 将随机选择一个执行。select 语句是非阻塞的,它可以与 Go 的并发特性结合,实现高效的任务处理和通信。
1.基本语法
select 语句的基本语法如下:
select {
case <-chan1:
// 执行通道 chan1 上的接收操作
case chan2 <- value:
// 向通道 chan2 发送值 value
default:
// 如果以上都没有准备就绪,则执行默认操作
}
2.示例
-
启动多个协程,每个协程向各自的通道发送数据。
-
使用
select语句来接收不同协程的数据,同时监控超时情况和程序结束信号。package main import ( "fmt" "math/rand" "time" ) func sendData(ch chan<- int, id int) { for { // 模拟随机的发送间隔 time.Sleep(time.Duration(rand.Intn(3)) * time.Second) ch <- id } } func main() { rand.Seed(time.Now().UnixNano()) // 创建两个通道 ch1 := make(chan int) ch2 := make(chan int) // 创建一个超时通道 timeout := make(chan bool) // 创建一个结束信号的通道 done := make(chan bool) // 启动协程发送数据 go sendData(ch1, 1) go sendData(ch2, 2) // 启动一个协程来控制超时 go func() { time.Sleep(5 * time.Second) // 设置超时时间为5秒 timeout <- true }() // 使用 select 处理不同的情况 for { select { case msg := <-ch1: fmt.Printf("Received from ch1: %d\n", msg) case msg := <-ch2: fmt.Printf("Received from ch2: %d\n", msg) case <-timeout: fmt.Println("Operation timed out!") done <- true return case <-done: fmt.Println("Program ended!") return } } }- 有两个数据发送协程,每个协程向其通道
ch1和ch2发送一个唯一的标识符。 - 设置了一个超时协程,如果在5秒内没有完成操作,则向
timeout通道发送一个信号。 - 在
main函数的select语句中,我们监听四种情况:从ch1接收数据、从ch2接收数据、超时和结束程序。 - 一旦超时发生,我们向
done通道发送一个信号并结束程序。
- 有两个数据发送协程,每个协程向其通道
四.recover
在 Go 中,协程(Goroutines)是轻量级的线程,用于并发执行任务。当一个协程因为 panic 而异常中断时,它不会影响其他协程的运行,但是如果 panic 没有被捕获(recover),它会导致整个程序崩溃。因此,在协程中合理使用 recover 是处理 panic 的一种有效方法。每个协程都应该独立地处理它们自己的 panic。这意味着你应该在每个可能产生 panic 的协程中使用 recover。recover 需要在 defer 函数中使用,因为只有在延迟函数中它才能捕获到协程的 panic。
1.示例
package main
import (
"fmt"
"time"
)
func main() {
// 启动多个协程
for i := 0; i < 3; i++ {
go safeGoroutine(i)
}
// 等待足够长的时间以确保协程执行
time.Sleep(1 * time.Second)
fmt.Println("主程序结束")
}
func safeGoroutine(id int) {
defer func() {
if r := recover(); r != nil {
fmt.Printf("协程 %d 捕获到 panic: %v\n", id, r)
}
}()
// 这里是协程可能会触发 panic 的地方
if id == 1 { // 假设只有 id 为 1 的协程会触发 panic
panic(fmt.Sprintf("协程 %d 发生 panic", id))
}
fmt.Printf("协程 %d 执行完毕\n", id)
}
main函数启动了 3 个协程。- 每个协程都调用了
safeGoroutine函数,在这个函数中,我们使用defer和recover来捕获并处理可能发生的 panic。 - 如果在协程中发生 panic,
recover会捕获到它,并允许协程优雅地处理 panic,而不是使整个程序崩溃。
2.位置
将 defer func() { ... }() 放在函数中的最上面是一种最佳实践。
- 确保覆盖整个函数: 将
defer放在函数开始处可以确保无论 panic 在函数的哪个部分发生,defer代码块都将被执行。这意味着,无论是由于哪个操作引发的 panic,都会被defer中的recover捕获和处理。 - 防止遗漏 panic: 如果将
defer放在函数中间或末尾,那么在defer之前的代码如果发生了 panic,recover将无法捕获到这个 panic,因为defer语句本身还没有被执行。
2.位置
将 defer func() { ... }() 放在函数中的最上面是一种最佳实践。
- 确保覆盖整个函数: 将
defer放在函数开始处可以确保无论 panic 在函数的哪个部分发生,defer代码块都将被执行。这意味着,无论是由于哪个操作引发的 panic,都会被defer中的recover捕获和处理。 - 防止遗漏 panic: 如果将
defer放在函数中间或末尾,那么在defer之前的代码如果发生了 panic,recover将无法捕获到这个 panic,因为defer语句本身还没有被执行。 - 逻辑清晰: 将
defer放在函数开头,可以让读代码的人立即知道这个函数有处理 panic 的逻辑,这使得代码的逻辑更清晰、更易于理解。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LAMA Inpaint:大型掩模修复
- 临界资源访问一个有趣现象
- WPF常用控件-选择文件与保存文件窗口
- 站群服务器对SEO的重要性
- Spark中使用DataFrame进行数据转换和操作
- pikachu_csrf通关攻略
- WEB 3D技术 three.js 3D贺卡(3) 点光源灯光动画效果
- 剑指“CPU飙高”问题
- 机器环境无法访问GitHub情况下linux安装OpenCV执行cmake无法下载ADE文件v0.1.1f.zip
- python下载wheel并安装