数字人对话系统 Linly-Talker(已加入Qwen和GeminiPro加强对话+上传任意图片的数字人)
🔥🔥🔥数字人对话系统 Linly-Talker🔥🔥🔥(已加入Qwen和GeminiPro加强对话+上传任意图片的数字人)
欢迎大家star我的仓库 https://github.com/Kedreamix/Linly-Talker
我在B站也有更新我的视频,大家也可以看看效果 ?www.bilibili.com/video/BV1rN4y1a76x/
2023.12 更新 📆
用户可以上传任意图片进行对话
2024.01 更新 📆
令人兴奋的消息!我现在已经将强大的GeminiPro和Qwen大模型融入到我们的对话场景中。用户现在可以在对话中上传任何图片,为我们的互动增添了全新的层面。
介绍
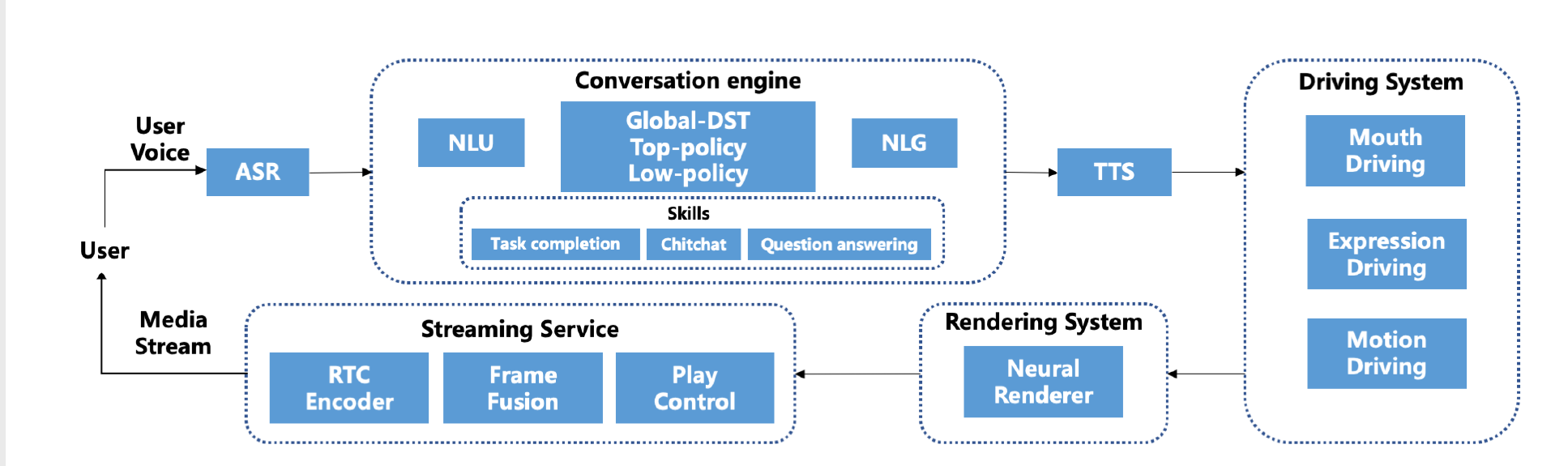
Linly-Talker是一个将大型语言模型与视觉模型相结合的智能AI系统,创建了一种全新的人机交互方式。它集成了各种技术,例如Whisper、Linly、微软语音服务和SadTalker会说话的生成系统。该系统部署在Gradio上,允许用户通过提供图像与AI助手进行交谈。用户可以根据自己的喜好进行自由的对话或内容生成。
创建环境
conda create -n linly python=3.8
conda activate linly
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install -r requirements_app.txt
ASR - Whisper
借鉴OpenAI的Whisper,具体使用方法参考https://github.com/openai/whisper
TTS - Edge TTS
使用微软语音服务,具体使用方法参考https://github.com/rany2/edge-tts
THG - SadTalker
说话头生成使用SadTalker,参考CVPR 2023,详情见https://sadtalker.github.io
下载SadTalker模型:
bash scripts/download_models.sh
LLM - Conversation
Linly-AI
Linly来自深圳大学数据工程国家重点实验室,参考https://github.com/CVI-SZU/Linly
下载Linly模型:https://huggingface.co/Linly-AI/Chinese-LLaMA-2-7B-hf
git lfs install
git clone https://huggingface.co/Linly-AI/Chinese-LLaMA-2-7B-hf
或使用API:
# 命令行
curl -X POST -H "Content-Type: application/json" -d '{"question": "北京有什么好玩的地方?"}' http://url:port
# Python
import requests
url = "http://url:port"
headers = {
"Content-Type": "application/json"
}
data = {
"question": "北京有什么好玩的地方?"
}
response = requests.post(url, headers=headers, json=data)
# response_text = response.content.decode("utf-8")
answer, tag = response.json()
# print(answer)
if tag == 'success':
response_text = answer[0]
else:
print("fail")
print(response_text)
Qwen
来自阿里云的Qwen,查看 https://github.com/QwenLM/Qwen
下载 Qwen 模型: https://huggingface.co/Qwen/Qwen-7B-Chat-Int4
git lfs install
git clone https://huggingface.co/Qwen/Qwen-1_8B-Chat
Gemini-Pro
来自 Google 的 Gemini-Pro,了解更多请访问 https://deepmind.google/technologies/gemini/
请求 API 密钥: https://makersuite.google.com/
模型选择
在 app.py 文件中,轻松选择您需要的模型。
# 取消注释并设置您选择的模型:
# llm = Gemini(model_path='gemini-pro', api_key=None, proxy_url=None) # 不要忘记加入您自己的 Google API 密钥
# llm = Qwen(mode='offline', model_path="Qwen/Qwen-1_8B-Chat")
# 自动下载
# llm = Linly(mode='offline', model_path="Linly-AI/Chinese-LLaMA-2-7B-hf")
# 手动下载到指定路径
llm = Linly(mode='offline', model_path="./Chinese-LLaMA-2-7B-hf")
优化
一些优化:
- 使用固定的输入人脸图像,提前提取特征,避免每次读取
- 移除不必要的库,缩短总时间
- 只保存最终视频输出,不保存中间结果,提高性能
- 使用OpenCV生成最终视频,比mimwrite更快
Gradio
Gradio是一个Python库,提供了一种简单的方式将机器学习模型作为交互式Web应用程序来部署。
对Linly-Talker而言,使用Gradio有两个主要目的:
-
可视化与演示:Gradio为模型提供一个简单的Web GUI,上传图片和文本后可以直观地看到结果。这是展示系统能力的有效方式。
-
用户交互:Gradio的GUI可以作为前端,允许用户与Linly-Talker进行交互对话。用户可以上传自己的图片并输入问题,实时获取回答。这提供了更自然的语音交互方式。
具体来说,我们在app.py中创建了一个Gradio的Interface,接收图片和文本输入,调用函数生成回应视频,在GUI中显示出来。这样就实现了浏览器交互而不需要编写复杂的前端。
总之,Gradio为Linly-Talker提供了可视化和用户交互的接口,是展示系统功能和让最终用户使用系统的有效途径。
启动
首先说明一下的文件夹结构如下
Linly-Talker/
├── app.py
├── app_img.py
├── utils.py
├── Linly-api.py
├── Linly-example.ipynb
├── README.md
├── README_zh.md
├── request-Linly-api.py
├── requirements_app.txt
├── scripts
│ └── download_models.sh
├── src
│ └── .....
├── inputs
│ ├── example.png
│ └── first_frame_dir
│ ├── example_landmarks.txt
│ ├── example.mat
│ └── example.png
├── examples
│ ├── driven_audio
│ │ ├── bus_chinese.wav
│ │ ├── ......
│ │ └── RD_Radio40_000.wav
│ ├── ref_video
│ │ ├── WDA_AlexandriaOcasioCortez_000.mp4
│ │ └── WDA_KatieHill_000.mp4
│ └── source_image
│ ├── art_0.png
│ ├── ......
│ └── sad.png
├── checkpoints // SadTalker 权重路径
│ ├── mapping_00109-model.pth.tar
│ ├── mapping_00229-model.pth.tar
│ ├── SadTalker_V0.0.2_256.safetensors
│ └── SadTalker_V0.0.2_512.safetensors
├── gfpgan // GFPGAN 权重路径
│ └── weights
│ ├── alignment_WFLW_4HG.pth
│ └── detection_Resnet50_Final.pth
├── Chinese-LLaMA-2-7B-hf // Linly 权重路径
├── config.json
├── generation_config.json
├── pytorch_model-00001-of-00002.bin
├── pytorch_model-00002-of-00002.bin
├── pytorch_model.bin.index.json
├── README.md
├── special_tokens_map.json
├── tokenizer_config.json
└── tokenizer.model
接下来进行启动
python app.py
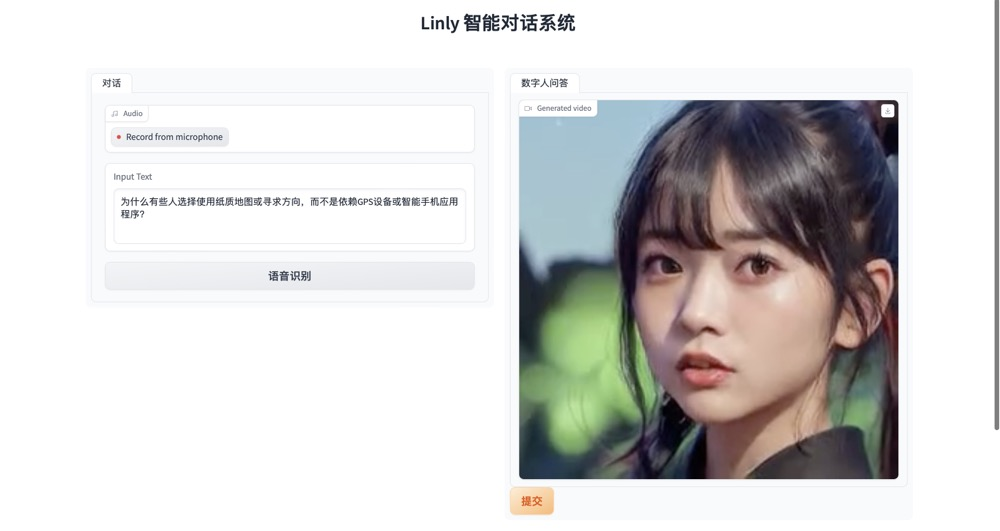
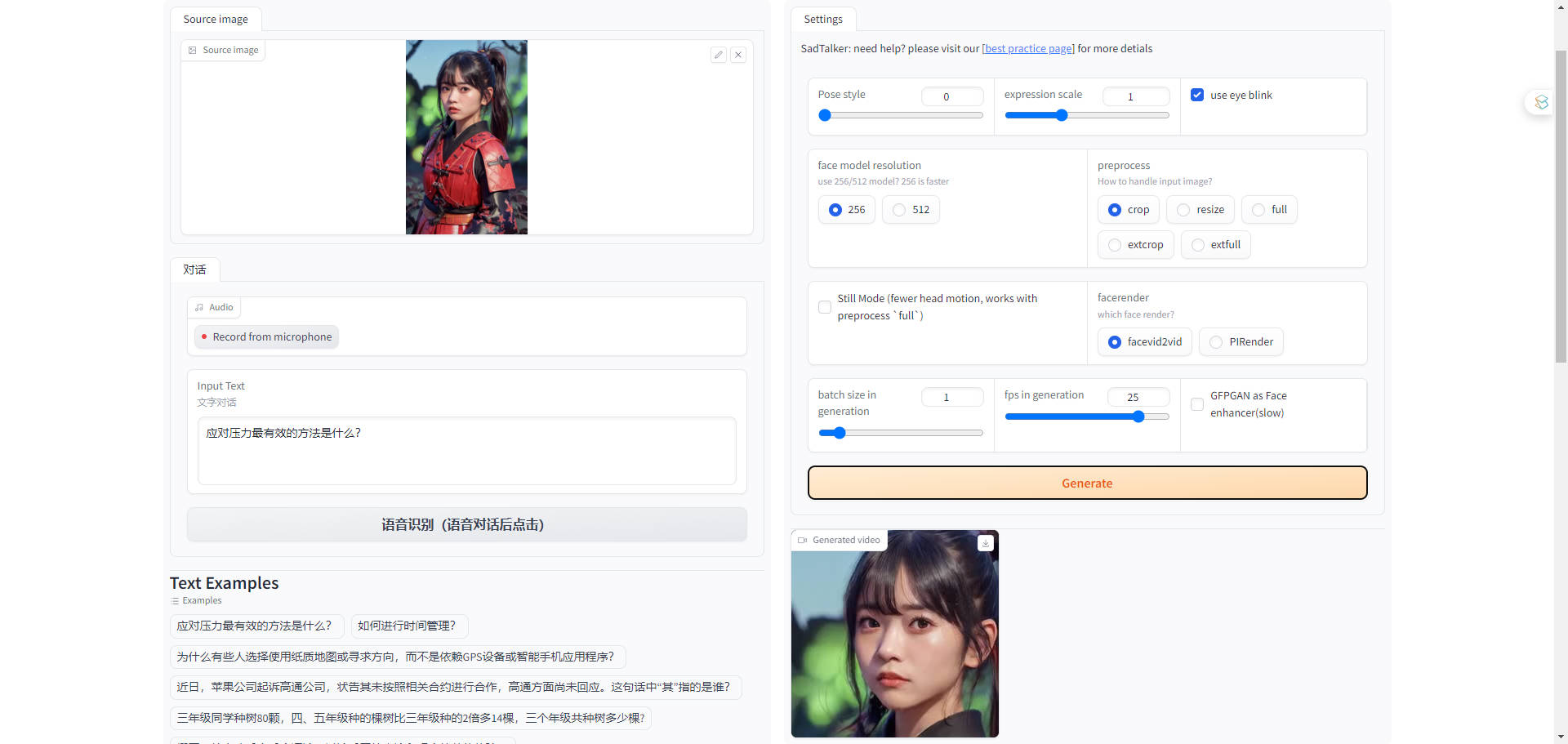
可以任意上传图片进行对话
python app_img.py
参考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!