忘记RAG,未来是RAG-Fusion
英文原文地址:https://towardsdatascience.com/forget-rag-the-future-is-rag-fusion-1147298d8ad1
忘记RAG,未来是RAG-Fusion
搜索的下一个前沿:检索增强生成与相互排名融合和生成的查询相遇
2023 年 10 月 6 日
在探索搜索技术近十年后,我可以诚实地说,没有什么比最近兴起的检索增强一代 (RAG) 更具颠覆性了。该系统使用矢量搜索和生成式人工智能,基于可信数据生成直接答案,正在彻底改变搜索和信息检索。
在我的搜索项目中,对 RAG 的试验让我考虑了它的潜在增强功能;我认为RAG仍然太有限,无法满足用户的需求,需要升级。

我的个人搜索系统(Project Ramble),我在 2022 年将Obsidian笔记与 GPT-3 相结合的矢量搜索连接起来。
不要误会我的意思,RAG 非常出色,并且绝对是信息检索技术朝着正确方向迈出的一步。自 2021 年 GPT-2 出现以来,我一直在使用 RAG,当我从自己的笔记或工作文档中查找有价值的信息时,它极大地帮助提高了我的工作效率。
RAG现在非常火,当然性能也非常出色,它绝对走在了信息检索技术的康庄大道上,RAG有许多优点:
- 向量搜索融合:?RAG通过将向量搜索功能与生成模型集成,引入了一种新的范例。这种融合能够从大型语言模型(大语言模型)生成更丰富、更具上下文感知的输出。
- 减少幻觉:?RAG显著降低了LLM的幻觉倾向,使生成的文本更基于数据。
- 个人和专业实用程序:从个人应用程序如筛选笔记到更专业的集成,RAG展示了在提高生产力和内容质量方面的多功能性,同时基于可信赖的数据源。
然而,我发现越来越多的“限制”:
- 当前搜索技术的限制:RAG受到限制我们基于检索的词法和向量搜索技术的相同限制。
- 人工搜索效率低下:人类并不擅长在搜索系统中输入他们想要的东西,比如打字错误、模糊的查询或有限的词汇,这通常会导致错过明显的顶级搜索结果之外的大量信息。虽然RAG有所帮助,但它并没有完全解决这个问题。
- 搜索的过度简化:我们流行的搜索模式将查询线性地映射到答案,缺乏深度来理解人类查询的多维本质。这种线性模型通常无法捕捉更复杂的用户查询的细微差别和上下文,从而导致相关性较低的结果。
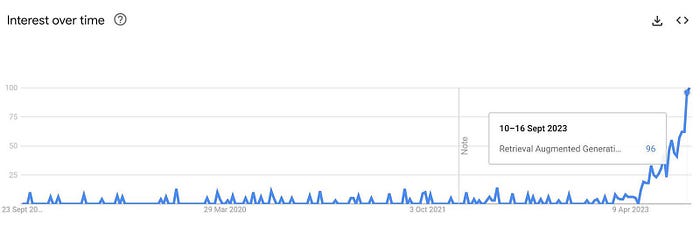
RAG关键词的Google搜索量在2023年暴涨。
那么,我们能做些什么来解决这些问题?我们需要一个系统,它不仅能检索我们的问题,还能掌握我们查询背后的细微差别,而不需要更高级的大语言模型。认识到这些挑战并受到可能性的启发,我开发了一个更精细的解决方案:RAG-Fusion。
为什么使用RAG-Fusion?
- 通过生成多个用户查询和重新排序结果来解决RAG固有的约束。
- 利用倒数排序融合(RRF)和自定义向量评分加权,生成全面准确的结果。
RAG-Fusion希望弥合用户明确提出的问题和他们(原本的意图)打算提出的问题之间的差距,更接近于发现通常仍然隐藏的变革性知识。
深入研究RAG-Fusion的机制
工具和技术栈
RAG Fusion的基本三要素与RAG相似,并在于相同的三个关键技术:
- 一种通用编程语言,通常是Python。
- 一个专用的向量搜索数据库,如Elasticsearch或Pinecone,指导文档检索。
- 一个强大的大型语言模型,如ChatGPT,制作文本。
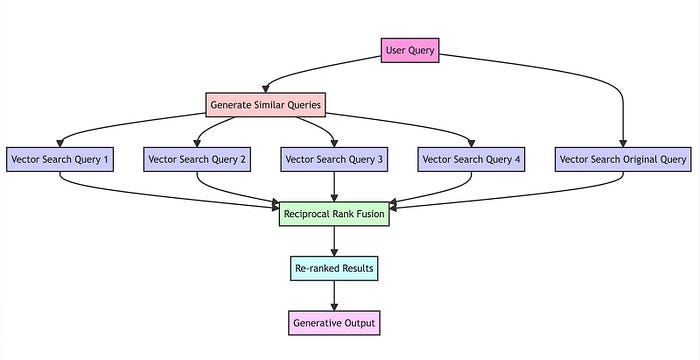
RAG-Fusion工作机制的图示
然而,与RAG不同的是,RAG-Fusion通过几个额外的步骤来区分自己——查询生成和结果的重新排序。
RAG-Fusion’s 工作步骤:
-
查询语句的相关性复制:通过LLM将用户的查询转换为相似但不同的查询。
-
并发的向量搜索:对原始查询及其新生成的同级查询执行并发的向量搜索。
-
智能重新排名:聚合和细化所有结果使用倒数排序融合(RRF)。
-
最后优中选优:将精心挑选的结果与新查询配对,引导LLM进行有针对性的查询语句输出,考虑所有查询和重新排序的结果列表。
RAG-Fusion代码:https://github.com/Raudaschl/rag-fusion
让我们更详细地介绍每一个步骤。
多查询生成
为什么使用多查询?
在传统的搜索系统中,用户经常输入一个单一的查询来查找信息。虽然这种方法很简单,但它有局限性。单个查询可能无法捕获用户感兴趣的全部范围,或者它可能太窄而无法产生全面的结果。这就是从不同角度生成多个查询的地方。
技术实施(Prompt工程)
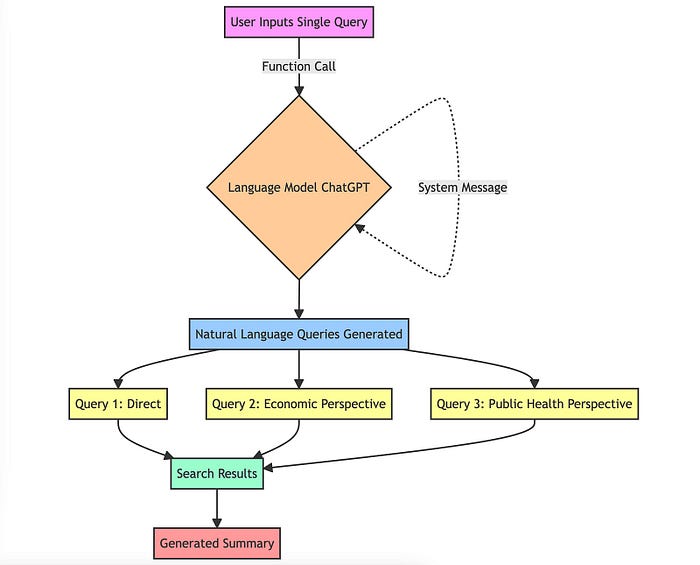
多查询生成流程图:利用prompt工程和自然语言模型来拓宽搜索视野和提高结果质量。
prompt工程的使用对于生成多个查询至关重要,这些查询不仅与原始查询相似,而且还提供不同的角度或透视图。
下面是它的工作原理:
- 对语言模型的函数调用:函数调用语言模型(在本例中为ChatGPT)。这种方法需要一个特定的指令集(通常被描述为“系统消息”)来指导模型。例如,这里的系统消息指示模型充当“AI助手”。
- 自然语言查询:然后模型根据原始查询生成多个查询。
- 多样性和覆盖范围:这些查询不仅仅是随机变化。它们是精心生成的,以提供对原始问题的不同观点。例如,如果最初的查询是关于“气候变化的影响”,生成的查询可能包括“气候变化的经济后果”、“气候变化和公共卫生”等角度。
这种方法确保搜索过程考虑更广泛的信息,从而提高生成的摘要的质量和深度。
倒数排序融合 (RRF)
Why RRF?
倒数排序融合(RRF) 是一种将具有不同相关性指标的多个结果集组合成单个结果集的方法,不同的相关性指标也不必相互关联即可获得高质量的结果。该方法的优势在于不利用相关分数,而仅靠排名计算。相关分数存在的问题在于不同模型的分数范围差。RRF是与滑铁卢大学(CAN)和谷歌(Google)合作开发的(https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf),用其作者的话来说,“比任何单独的系统产生更好的结果,比标准的重新排名方法产生更好的结果”。
在elasticsearch的8.8版本,已经引入了RRF。
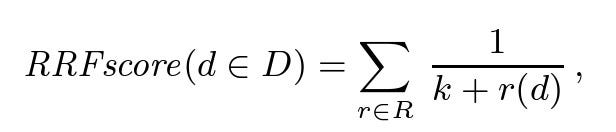
D是文档集,R是一组排名作为(1..|D| )的排列,其中k默认是60.
通过组合来自不同查询的排名,我们增加了最相关的文档出现在最终列表顶部的机会。RRF特别有效,因为它不依赖于搜索引擎分配的绝对分数,而是依赖于相对排名,这使得它非常适合组合来自可能具有不同分数尺度或分布的查询的结果。
通常,RRF用于混合词法和向量结果。虽然这种方法可以帮助弥补向量搜索在查找特定术语(例如首字母缩写词)时缺乏专一性的不足,但我对结果并不满意,它往往更像是多个结果集的拼凑,因为对于词法和向量搜索的相同查询很少出现相同的结果。
把RRF想象成那种坚持在做决定之前征求每个人意见的人,这种意见是有帮助的,兼听则明,多多益善。
技术实现
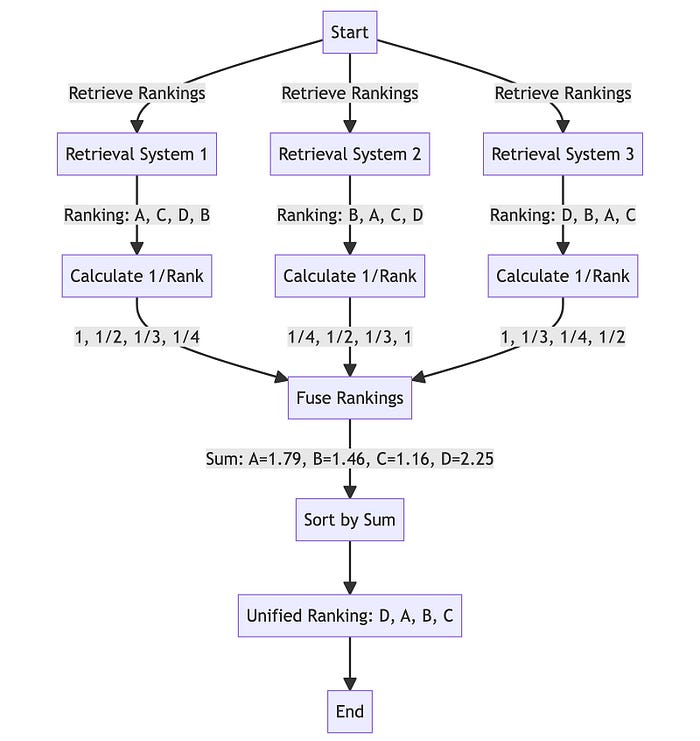
倒数排序融合流程示意图
函数reciprocal_rank_fusion接受一个搜索结果字典,其中每个键都是一个查询,对应的值是一个文档id列表,按照它们与该查询的相关性排序。然后,RRF算法根据每个文档在不同列表中的排名计算一个新分数,并对它们进行排序,以创建一个最终的重新排名的列表。
在计算融合分数之后,该函数按照分数的降序对文档进行排序,以获得重新排序的最终列表,然后返回该列表。
生成的输出
用户意图保存
使用多个查询的挑战之一是可能会削弱用户的原始意图。为了缓解这种情况,我们指示模型在prompt工程中给予原始查询更多的权重。
技术实现
最后,重新排序的文档和所有查询被馈送到LLM的Prompt中,以典型的RAG方式生成输出,例如请求响应或摘要。
通过对这些技术和技巧进行分层,RAG Fusion提供了一种强大而细致的文本生成方法,它利用最好的搜索技术和生成AI来产生高质量,可靠的输出。
RAG-Fusion优缺点
优势
1、优质的原材料质量
当您使用RAG Fusion时,您的搜索深度不仅仅是“增强”,并且其实搜索范围已经被放大了。相关文档的重新排序意味着你不仅仅是在抓取信息的字面意思,而是在深入这个搜索的意图,所以会涉及到更多的优质文档和待搜索内容。
2、增强用户意图对齐
RAG Fusion的设计理念中包含了自动提示,很多时候我们在搜索的时候并不知道应该怎么描述,像Google、百度就会进行输入框的自动补全提示。RAG Fusion可以捕获用户信息需求的多个方面,从而提供整体输出并与对用户意图进行增强。
3、自动为用户查询输入纠错
该系统不仅可以解释用户的查询,还可以精炼用户的查询。通过生成多个查询变体,RAG Fusion执行隐式拼写和语法检查,从而提高搜索结果的准确性。
4、导航复杂查询(自动分解长句的意图)
人类的语言在表达复杂或专门的思想时往往会结结巴巴。该系统就像一个语言催化剂,生成各种变体,这些变体可能包含更集中、更相关的搜索结果所需的行话或术语。它还可以处理更长的、更复杂的查询,并将它们分解成更小的、可理解的块,用于向量搜索。
5、搜索中的意外发现(关联推荐)
以前在亚马逊买书的时候,总能因为相关推荐发现我更想要的书,RAG Fusion允许这个偶然的发现。通过使用更广泛的查询范围,系统有可能挖掘到信息,而这些信息虽然没有明确搜索,但却成为用户的“啊哈”时刻。这使得RAG Fusion有别于其他传统的搜索模型。
挑战
1、过于啰嗦的风险
RAG-Fusion的深度有时会导致信息泛滥。输出可能会详细到令人难以承受的程度,把RAG-Fusion想象成一个过度解释事物的朋友。
2、可能成本会比较昂贵
多查询输入是需要LLM来做处理的,这时候,很有可能会引起更多的tokens消耗。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java学习常用实用类2
- 空气污染大屏,UI可视化大屏设计(PSD源文件)
- 大二下 课程安排
- 深入解析 Flink CDC 增量快照读取机制
- 全面硬件检查 | 确保设备完美运行
- 新版Android Studio Logcat 筛选日志
- c++多久会被Python或者新语言取代?
- 解决pip安装第三库echarts报错:Package would be ignored而安装失败的问题
- 回顾丨车载以太网IEEE标准
- 黑客利用宝马网站发起钓鱼攻击