Emu2:37亿参数开创多模态生成新篇章
引言
多模态任务在人工智能领域一直是极具挑战性的「技术高地」。智源研究院最近开源发布的新一代多模态基础模型Emu2,在这一领域取得了突破性进展。Emu2以其庞大的37亿参数规模和强大的多模态生成能力,为AI的多模态理解和生成开启了新的篇章。
模型概述
Emu2是一款大规模自回归生成式多模态预训练模型,训练过程中采用了大量图文、视频序列,以及统一的自回归建模方式。这款模型在少样本多模态理解任务上大幅超越了当下主流的多模态预训练大模型,如Flamingo-80B和IDEFICS-80B,在众多任务中取得了最优性能。
-
Huggingface模型下载:https://huggingface.co/BAAI/Emu2-Chat
-
AI快站模型免费加速下载:https://aifasthub.com/models/BAAI/Emu2-Chat
技术创新
Emu2模型的一个显著特点是其简化的建模框架。相比于第一代Emu模型,Emu2在训练中使用了更简单的框架,并扩展了模型规模至37B参数。这不仅提升了模型的能力和通用性,还增强了其在多模态任务中的表现。Emu2利用了统一自回归建模的多模态预训练框架,将图像、视频等模态的token序列与文本token序列交错在一起输入到模型中进行训练。
应用表现
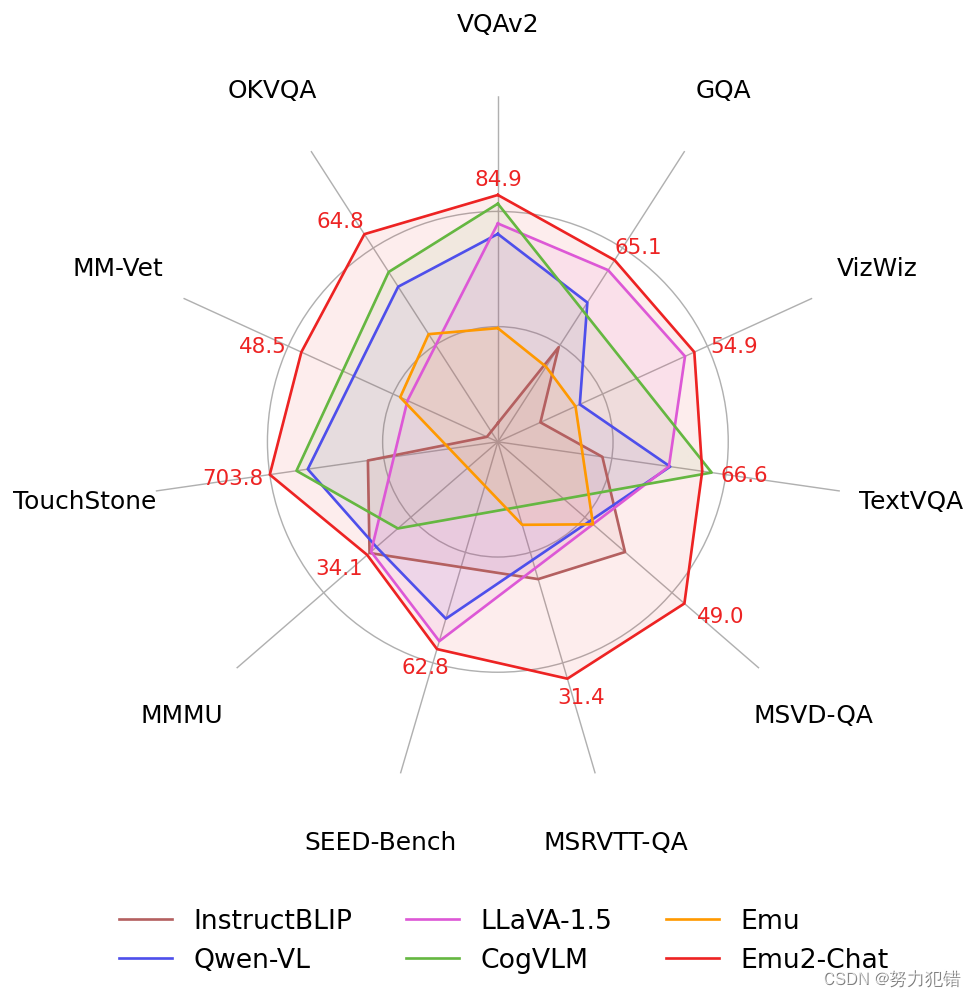
在多项少样本理解、视觉问答、主体驱动图像生成等任务上,Emu2表现卓越。尤其在VQAv2、OKVQA、MSVD等十余个图像和视频问答评测集上,Emu2都取得了最优性能。此外,在DreamBench主体驱动图像生成测试上,Emu2相较于此前的方法取得显著提升。
多模态上下文学习
Emu2的另一个突出特点是其全面而强大的多模态上下文学习能力。基于几个例子,Emu2可以完成对应的理解和生成任务,如在上下文中描述图像、理解视觉提示、生成类似风格的图像等。这种能力在多模态AI应用中具有重要的实际意义。

强大的多模态理解
Emu2-Chat作为模型的一个变体,特别擅长多模态理解任务。它可以精准理解图文指令,更好地完成多模态理解任务,例如推理图像中的要素、读指示牌提供引导等。


图像和视频生成能力
Emu2-Gen则是Emu2在图像和视频生成方面的展现。该模型可以接受图像、文本、位置交错的序列作为输入,生成对应的高质量图像和视频。这种灵活性和高可控性在AI图像生成领域具有重要价值。


未来展望
Emu2的开源不仅是多模态AI技术的一大进步,也为AI在艺术创作、内容生成、互动娱乐等领域的应用提供了无限可能。随着更多的研究和开发,Emu2有望在多模态AI领域继续引领技术潮流。
结论
Emu2的出现标志着多模态AI的一个重要里程碑。以其37亿参数的规模和卓越的生成能力,Emu2不仅在多模态理解和生成方面取得了显著成就,更为AI的未来发展铺平了新的道路。作为目前最大的开源生成式多模态模型,Emu2无疑将在AI领域继续发挥其重要作用。
模型下载
Huggingface模型下载
https://huggingface.co/BAAI/Emu2-Chat
https://huggingface.co/BAAI/Emu2-Gen
AI快站模型免费加速下载
https://aifasthub.com/models/BAAI/Emu2-Chat
https://aifasthub.com/models/BAAI/Emu2-Gen
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LeetCode 24. 两两交换链表中的节点
- 使用腾讯云服务器搭建个人网站详细步骤介绍
- 系列九(实战)、生产环境服务器变慢,请你谈谈诊断思路和性能评估?
- 【预测控制1】模型预测控制概论
- matlab appdesigner系列-常用13-标签
- XUbuntu22.04之删除多余虚拟网卡和虚拟网桥(二百零四)
- 鸿蒙开发系列教程(一)--环境安装
- 环形链表问题2(返回链表开始入环的第一个节点)
- 第2篇最强Redis面试八股文
- 详细分析对比copliot和ChatGPT的差异