CSAPP 第七章 Linking part2
CSAPP 第七章 Linking part2
Executable Object Files
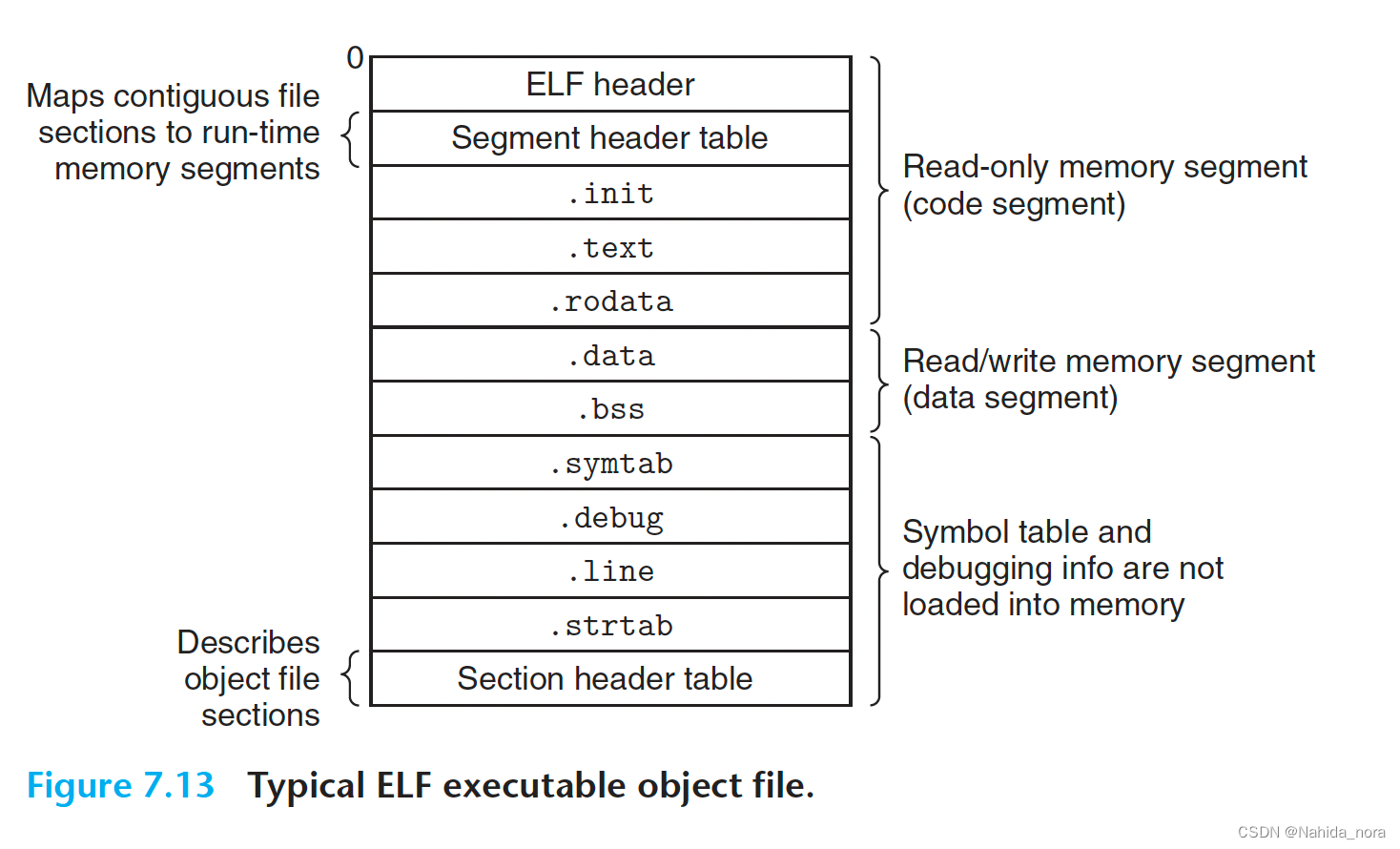
可执行目标文件(executable object file)的格式与可重定位目标文件(relocatable object file)相似。ELF 头(ELF header)描述了文件的总体格式。它还包括程序的入口点,即程序运行时执行的第一条指令的地址。.text、.rodata 和 .data 部分与可重定位目标文件中的相似,不同之处在于这些部分已经被重定位到它们最终的运行时内存地址。.init 部分定义了一个名为 _init 的小函数,该函数将被程序的初始化代码调用。由于可执行文件已经完全链接(重定位),因此不需要 .rel 部分。
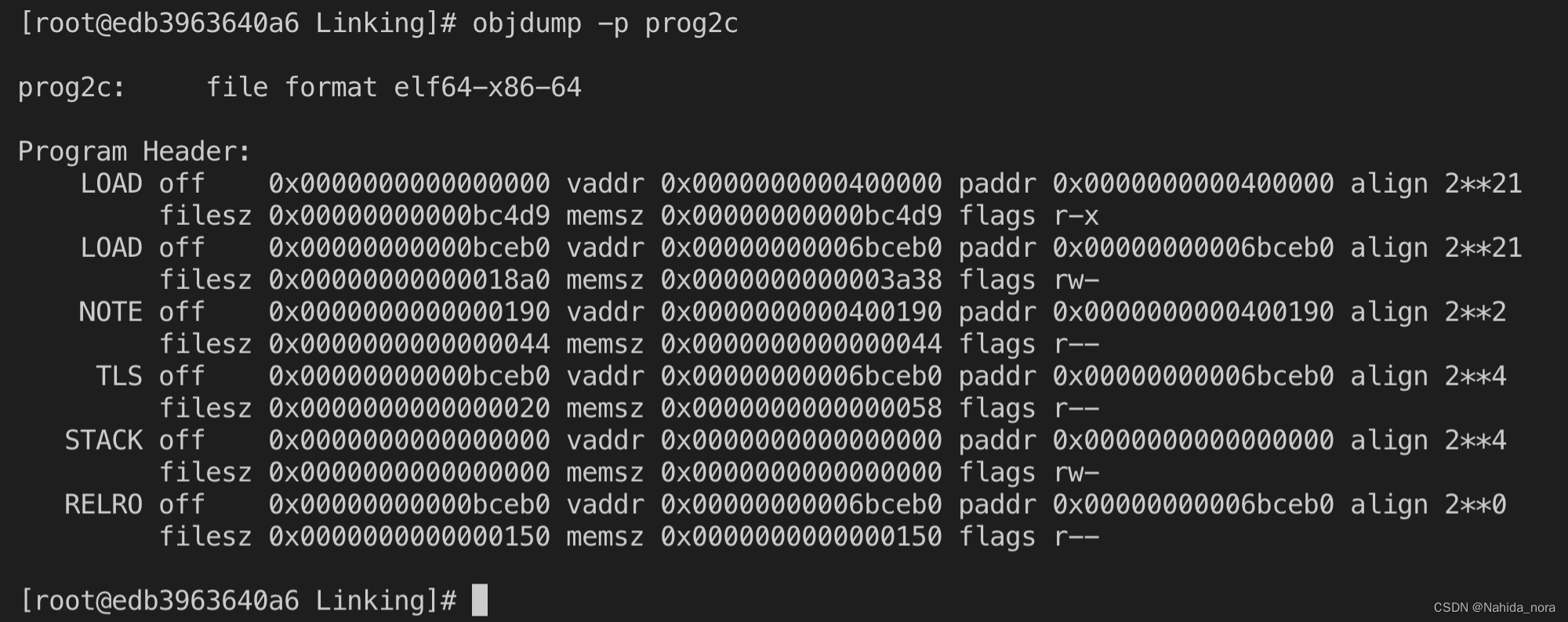

ELF 可执行文件被设计为易于加载到内存中,可执行文件的连续块映射到连续的内存段。这种映射由程序头表(program header table)描述。图 7.14 显示了示例可执行文件 prog 的程序头表的一部分,如 objdump 所示。从程序头表中,我们看到将用可执行目标文件的内容初始化两个内存段。第 1 和第 2 行告诉我们第一个段(代码段)具有读/执行权限,从内存地址 0x400000 开始,总大小为 0x69c 字节,并使用可执行目标文件的前 0x69c 字节进行初始化,其中包括 ELF 头、程序头表以及 .init、.text 和 .rodata 部分。
第 3 和第 4 行告诉我们第二个段(数据段)具有读/写权限,从内存地址 0x600df8 开始,总内存大小为 0x230 字节,并使用从目标文件中偏移量 0xdf8 处开始的 .data 部分的 0x228 字节进行初始化。段中的剩余 8 字节对应于在运行时将被初始化为零的 .bss 数据。
对于任何段 s,链接器必须选择一个起始地址 vaddr,使得 vaddr mod align = off mod align,其中 off 是段在目标文件中第一个部分的偏移量,align 是程序头中指定的对齐方式(这里是 0x200000)。例如,在图 7.14 中的数据段中:
vaddr mod align = 0x600df8 mod 0x200000 = 0xdf8
和
off mod align = 0xdf8 mod 0x200000 = 0xdf8
这种对齐要求是一种优化,使得在程序执行时,目标文件中的段可以有效地传输到内存中。这是由虚拟内存以大块连续的2的幂字节组织的方式导致的。
Loading Executable Object Files
运行executable object files:
在Linux系统中,当用户运行一个程序时,Shell会假定该程序是一个可执行对象文件,并通过调用 execve 函数来执行该程序。加载器(loader)负责将可执行对象文件中的代码和数据从磁盘复制到内存,并通过跳转到其第一条指令或入口点来运行程序。这个过程被称为加载。
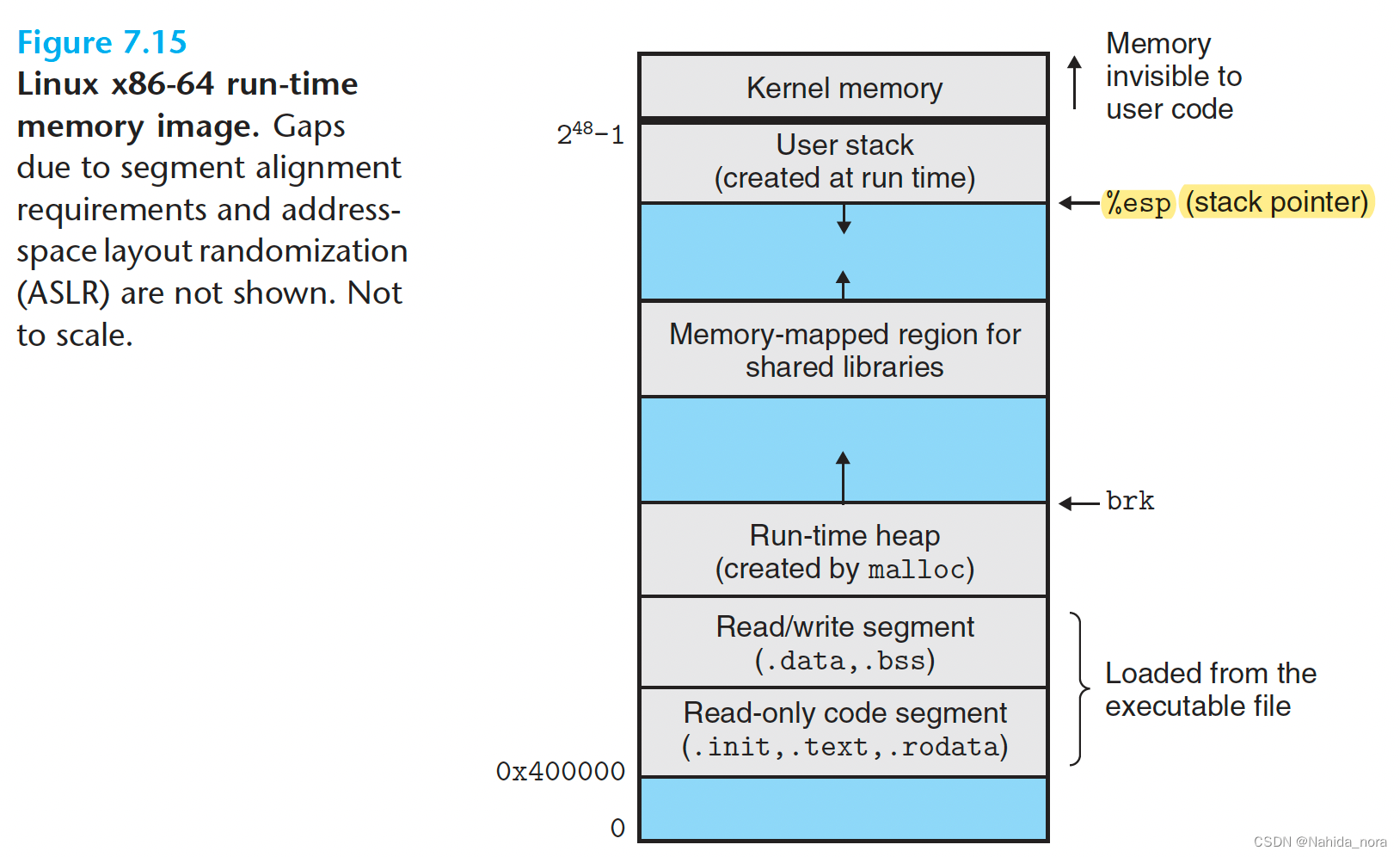
每个运行中的Linux程序都有一个类似于图7.15中所示的运行时内存图像。在Linux x86-64系统上,代码段从地址0x400000开始,其后是数据段。运行时堆紧随数据段后面,通过调用malloc库而向上增长(我们将在第9.9节详细介绍malloc和堆)。然后是一个为共享模块保留的区域。用户栈从最大的合法用户地址(2^ 48 ? 1)开始向下增长,朝着较小的内存地址。栈上方的区域,从地址2^48开始,为内核中的代码和数据保留。
为了简化,我们将堆、数据和代码段绘制成相邻的,将栈的顶部放在最大的合法用户地址上。实际上,由于.data段的对齐要求(第7.8节),代码和数据段之间存在间隙。此外,链接器在为栈、共享库和堆分配运行时地址时使用地址空间布局随机化(ASLR,第3.10.4节)。尽管这些区域的位置在每次运行程序时都会改变,但它们的相对位置保持不变。
加载器运行时,它创建了一个类似于图7.15所示的内存图像。在程序头表的指导下,加载器将可执行对象文件的块复制到代码和数据段中。接下来,加载器跳转到程序的入口点,该入口点始终是_start函数的地址。该函数在系统对象文件(system object file)crt1.o中定义,对于所有C程序都是相同的。_start函数调用系统启动函数__libc_start_main,该函数在libc.so中定义。它初始化执行环境,调用用户级main函数,处理其返回值,并在必要时将控制权返回给内核。
Dynamic Linking with Shared Libraries
我们在第7.6.2节中学到的静态库解决了许多与向应用程序提供大量相关功能的问题。然而,静态库仍然存在一些显著的缺点。静态库,像所有软件一样,需要定期维护和更新。如果应用程序员想使用库的最新版本,他们必须以某种方式得知库已更改,然后明确地重新链接他们的程序以使用更新后的库。
更新静态库
重新链接使用修改过的静态库时,你需要确保在编译时使用更新后的库文件。以下是一些建议的步骤:
-
重新编译修改后的静态库:
在修改静态库的源代码后,确保你重新编译了这个库,生成了更新后的静态库文件(.a文件)。gcc -c 修改后的源文件.c -o 修改后的目标文件.o ar rcs libyourlibrary.a 修改后的目标文件.o 其他目标文件.o -
编译源文件并链接新的库:
在编译源文件时,使用更新后的库文件路径和名称。确保在编译命令中包含了新的静态库。gcc -o your_program your_source.c -L/path/to/updated_library -lyourlibrary这里的
/path/to/updated_library是新库文件的路径,yourlibrary是新库文件的名称。 -
运行程序:
如果编译没有错误,你可以运行生成的可执行文件。
注意事项:
- 确保新的静态库路径和名称正确。
- 如果你使用的是相对路径,确保当前工作目录正确设置。
- 如果库文件位于标准路径中,你可能无需指定路径,只需指定库文件名。
这样,你就能够使用更新后的静态库重新链接你的程序。
另一个问题是几乎每个C程序都使用标准I/O函数,比如printf和scanf。在运行时,这些函数的代码会在每个运行中的进程的文本段中复制。在运行数百个进程的典型系统上,这可能是对稀缺内存系统资源的重大浪费。(内存的一个有趣属性是,无论系统中有多少内存,它总是一种稀缺资源。)
共享库(Shared libraries)是解决静态库缺点的现代创新。共享库是一个目标模块,可以在运行时或加载时加载到任意内存地址,并与内存中的程序链接。这个过程被称为动态链接(dynamic linking),由一个称为动态链接器(dynamic linker)的程序执行。共享库也被称为共享对象(shared objects),在Linux系统上它们以.so后缀表示。Microsoft操作系统大量使用共享库,它们称之为DLL(动态链接库)。
共享库(Shared libraries)在两个不同的方面是“共享”的。首先,在给定的文件系统中,一个特定库只有一个.so文件。该.so文件中的代码和数据被引用该库的所有可执行对象文件共享,与静态库的内容不同,静态库的内容会被复制并嵌入到引用它们的可执行文件中。其次,内存中一个共享库的.text部分的单个副本可以被不同运行的进程共享。在第9章学习虚拟内存时,我们将更详细地探讨这一点。
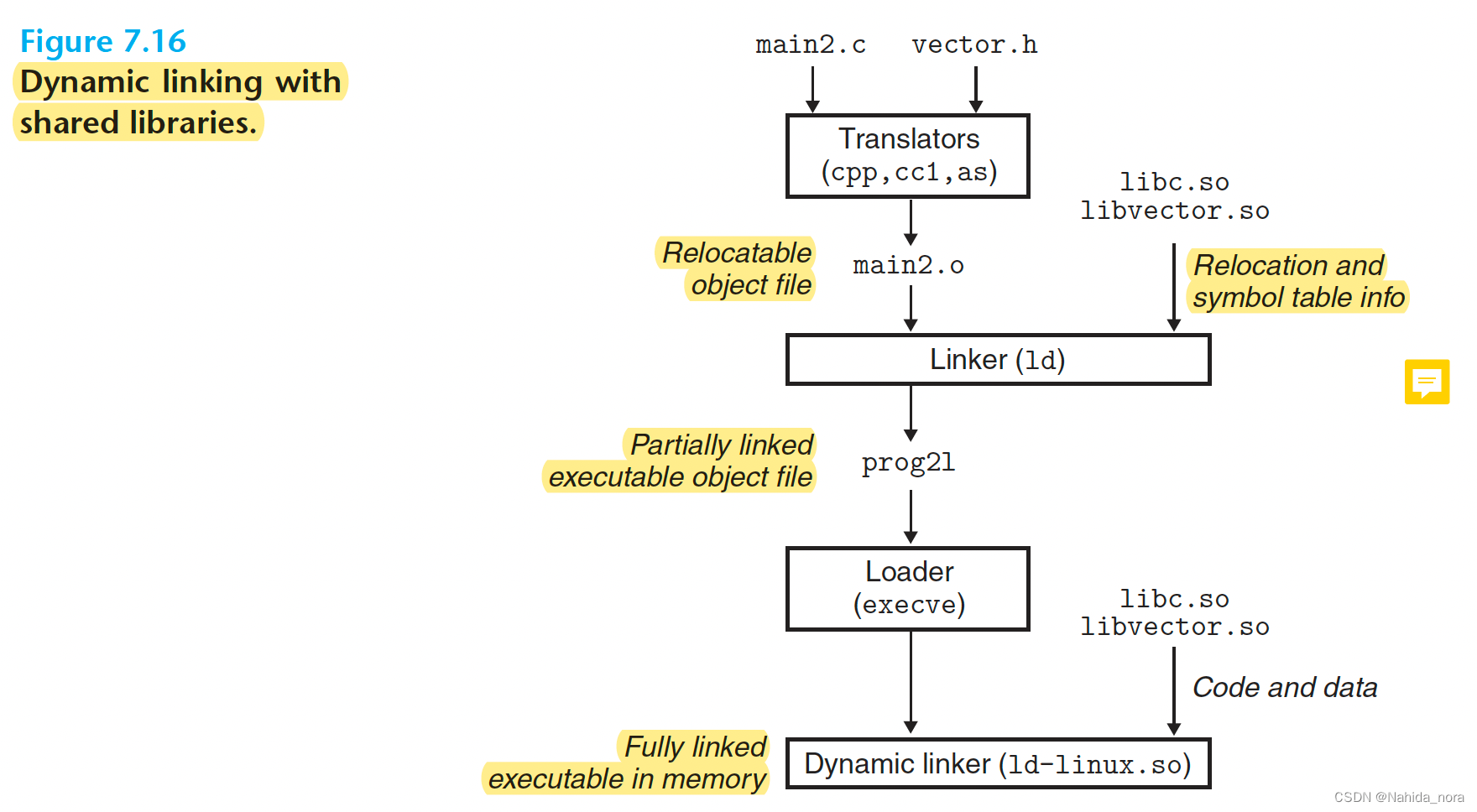
图7.16总结了图7.7中示例程序的动态链接过程。要构建我们在图7.6中示例向量例程的共享库libvector.so,我们使用编译器驱动程序并带有一些特殊的指示符传递给编译器和链接器:
linux> gcc -shared -fpic -o libvector.so addvec.c multvec.c
-fpic标志指示编译器生成位置无关代码(在下一节中更详细介绍)。-shared标志指示链接器创建一个共享对象文件。创建库后,我们然后将其链接到图7.7中的示例程序:
linux> gcc -o prog2l main2.c ./libvector.so
这将创建一个可执行对象文件prog2l,以一种形式链接到libvector.so,可以在运行时链接。基本思想是在创建可执行文件时静态地执行一些链接,然后在程序加载时动态地完成链接过程。重要的是要意识到此时libvector.so的任何代码或数据部分都没有被实际复制到可执行文件prog2l中。相反,链接器复制了一些重定位和符号表信息,这将允许在加载时解析对libvector.so中的代码和数据的引用。
当加载器加载和运行可执行文件prog2l时,它使用第7.9节中讨论的技术加载了部分链接的可执行文件prog2l。接下来,它注意到prog2l包含一个.interp部分,其中包含动态链接器的路径名,它本身是一个共享对象(例如,在Linux系统上是ld-linux.so)。加载器不像通常那样将控制权传递给应用程序,而是加载并运行动态链接器。然后,动态链接器通过执行以下重定位完成链接任务:
- 将libc.so的文本和数据重新定位到某个内存段
- 将libvector.so的文本和数据重新定位到另一个内存段
- 重新定位prog2l中对libc.so和libvector.so定义的符号的任何引用
最后,动态链接器将控制权传递给应用程序。从这一点开始,共享库的位置被固定,程序执行过程中不再改变。
静态库和动态库在的加载方式的区别
静态库和动态库在加载方式上有一些区别:
静态库在编译时被链接到应用程序中,成为应用程序的一部分。在这种情况下,加载器(Loader)的主要任务是将整个应用程序加载到内存中,并解析应用程序内部的符号引用。加载器在这个过程中并不涉及动态加载共享库的任务,因为静态库已经在编译时被完全链接到应用程序中了。
动态库(共享库),相反,是在运行时加载和链接到应用程序中的。在这种情况下,加载器扮演了重要的角色,负责在程序运行时将动态库加载到内存中,并解析程序对这些库的引用。
总的来说,对于静态库,加载器在应用程序启动时将整个应用程序加载到内存中,而对于动态库,加载器可以在程序运行时动态加载和链接共享库。
Loading and Linking Shared Libraries from Applications
到目前为止,已经讨论了在应用程序加载并在执行之前,动态链接器加载和链接共享库的情景。然而,也有可能在应用程序运行时请求动态链接器加载和链接任意的共享库,而无需在编译时将应用程序与这些库链接在一起。动态链接是一种强大而有用的技术。以下是现实世界中的一些例子:
-
软件分发:
Microsoft Windows应用程序的开发人员经常使用共享库来分发软件更新。他们生成共享库的新副本,用户可以下载并用作当前版本的替代品。下次运行应用程序时,它将自动链接和加载新的共享库。 -
构建高性能Web服务器:
许多Web服务器生成动态内容,例如个性化的网页、账户余额和横幅广告。早期的Web服务器通过使用fork和execve创建子进程并在子进程的上下文中运行“CGI程序”来生成动态内容。然而,现代高性能Web服务器可以使用基于动态链接的更高效和复杂的方法生成动态内容。思路是将生成动态内容的每个函数打包到一个共享库中。当来自Web浏览器的请求到达时,服务器动态加载和链接适当的函数,然后直接调用它,而不是使用fork和execve在子进程的上下文中运行该函数。函数保留在服务器的地址空间中缓存,因此后续的请求可以通过简单的函数调用来处理。这对繁忙站点的吞吐量可能产生显著影响。此外,可以在运行时更新现有函数并添加新函数,而无需停止服务器。
服务器动态加载和链接适当的函数 和 使用fork和execve在子进程的上下文中运行该函数的区别?
动态加载和链接适当的函数与使用fork和execve在子进程的上下文中运行该函数之间存在一些重要的区别,特别是在性能和灵活性方面:
-
性能:
- 动态加载和链接: 在动态加载的模型中,服务器在收到请求时动态加载适当的函数,然后链接并直接调用它。这避免了创建新进程的开销,因为函数被直接调用,而不是通过fork和execve创建子进程。
- fork和execve: 通过fork和execve创建子进程来运行函数,这涉及到复制父进程的地址空间和重新加载可执行文件。这样的模型可能会导致较高的资源消耗和较慢的响应时间,因为每个请求都需要创建新的进程。
-
资源利用率:
- 动态加载和链接: 函数在服务器的地址空间中保持缓存,因此可以在多个请求之间共享。这减少了资源的浪费,因为不需要为每个请求都创建新的进程。
- fork和execve: 每个请求都需要创建新的子进程,这可能导致较高的内存和CPU利用率,尤其是在频繁的请求下。
-
灵活性和更新:
- 动态加载和链接: 新的函数可以在运行时添加,现有的函数也可以在不停止服务器的情况下更新。这提供了更大的灵活性,允许系统在不中断服务的情况下进行更新和修改。
- fork和execve: 更新或添加新函数可能需要停止服务器,因为每次更改都需要重新启动子进程。
总的来说,动态加载和链接适当的函数通常在高性能和资源利用率方面更具优势,尤其是在需要频繁处理请求的情况下。这种方法也提供了更大的灵活性,允许在运行时更新和修改功能。
Linux系统为动态链接器提供了一个简单的接口,允许应用程序在运行时加载和链接共享库。

dlopen 函数加载并链接共享库文件 filename。filename 中的外部符号会使用之前使用 RTLD_GLOBAL 标志打开的库进行解析。如果当前可执行文件是使用 -rdynamic 标志编译的,那么它的全局符号也可用于符号解析。flag 参数必须包含 RTLD_NOW,它告诉链接器立即解析对外部符号的引用,或者 RTLD_LAZY 标志,它指示链接器推迟符号解析,直到从库中执行代码。这两个值可以与 RTLD_GLOBAL 标志进行按位或操作。
RTLD_GLOBAL介绍
RTLD_GLOBAL 是 dlopen 函数中的一个标志,用于指定共享库的全局符号在解析外部符号时应该是可用的。当使用 RTLD_GLOBAL 标志时,共享库中的符号将被链接到全局符号表中,使得其他共享库或可执行文件可以访问这些符号。
具体来说,使用 RTLD_GLOBAL 标志的效果是,共享库中的符号可以被后续加载的共享库或主程序(如果使用了 -rdynamic 标志编译)引用。这对于在不同的共享库之间共享全局变量或函数非常有用,因为它们可以在整个应用程序的多个模块之间共享状态。
举例说明,在使用 dlopen 打开共享库时,如果使用了 RTLD_GLOBAL 标志,共享库中的符号将在整个应用程序中可见,而不仅仅是在打开共享库的模块中可见。
void *handle = dlopen("mylibrary.so", RTLD_NOW | RTLD_GLOBAL);
// 共享库中的符号现在在整个应用程序中可见

dlsym 函数接受一个先前打开的共享库的句柄和一个符号名称,如果该符号存在,则返回符号的地址,否则返回 NULL。

图7.17展示了我们如何在运行时使用这个接口动态链接我们的libvector.so共享库,然后调用它的addvec例程。为了编译这个程序,我们将以以下方式调用gcc:
Position-Independent Code (PIC)
可以在不需要任何重定位的情况下加载的代码称为位置无关代码(PIC)。用户可以使用gcc的-fpic选项来指示GNU编译系统生成PIC代码。共享库必须始终使用此选项进行编译。
在x86-64系统上,对同一可执行对象模块中符号的引用无需特殊处理即可成为PIC。这些引用可以使用基于PC的寻址进行编译,并在构建对象文件时由静态链接器进行重定位。然而,对由共享模块定义的外部过程和全局变量的引用则需要一些特殊的技术,我们将在下文中描述。
PIC Data References
编译器通过利用以下有趣的事实生成对全局变量的PIC引用:无论我们将一个对象模块(包括共享对象模块)加载到内存的任何位置,数据段始终与代码段相同的距离。因此,代码段中任何指令与数据段中任何变量之间的距离是一个运行时常数,独立于代码和数据段的绝对内存位置。
希望生成对全局变量的PIC引用的编译器通过在数据段开头创建一个称为全局偏移表(GOT)的表来利用这一事实。GOT包含每个由对象模块引用的全局数据对象(过程或全局变量)的8字节条目。编译器还为GOT中的每个条目生成一个重定位记录。在加载时,动态链接器重新定位每个GOT条目,使其包含对象的绝对地址。每个引用全局对象的对象模块都有自己的GOT。
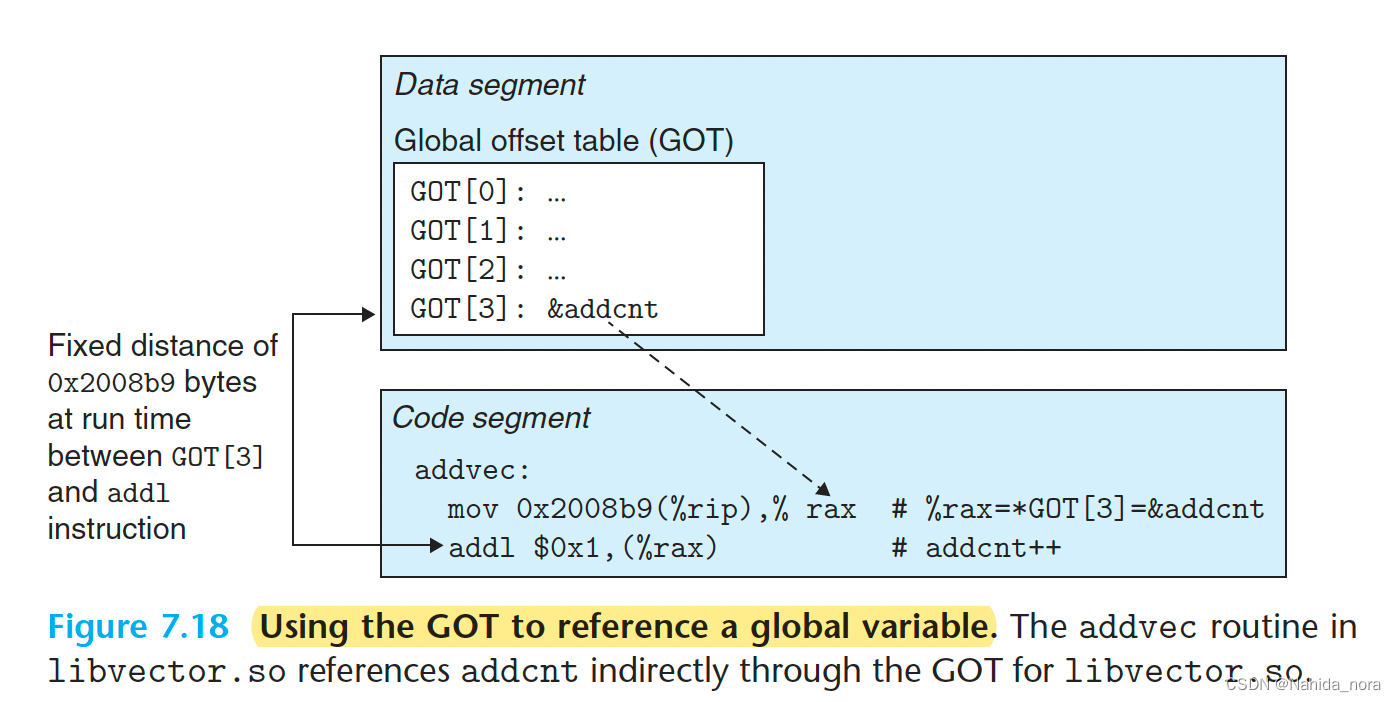
图7.18显示了我们示例的libvector.so共享模块的GOT。addvec例程通过GOT[3]间接加载全局变量addcnt的地址,然后在内存中递增addcnt。这里的关键思想是对GOT[3]的PC相对引用的偏移是一个运行时常数。
由于addcnt由libvector.so模块定义,编译器可以通过生成对addcnt的直接PC相对引用并在构建共享模块时添加一个链接器需要解决的重定位来利用代码和数据段之间的常数距离。然而,如果addcnt由另一个共享模块定义,那么通过GOT的间接访问将是必要的。在这种情况下,编译器选择使用最通用的解决方案,即GOT,用于所有引用。
PIC Function Calls
"Lazy binding"的动机在于,一个典型的应用程序可能只调用共享库(如libc.so)导出的数百到数千个函数中的少数几个。通过推迟函数地址的解析直至其被首次调用,动态链接器可以避免在加载时进行数百到数千次不必要的重定位。虽然在首次调用函数时存在一些运行时开销,但之后的每次调用只需要一条指令和一个内存引用来进行间接引用。
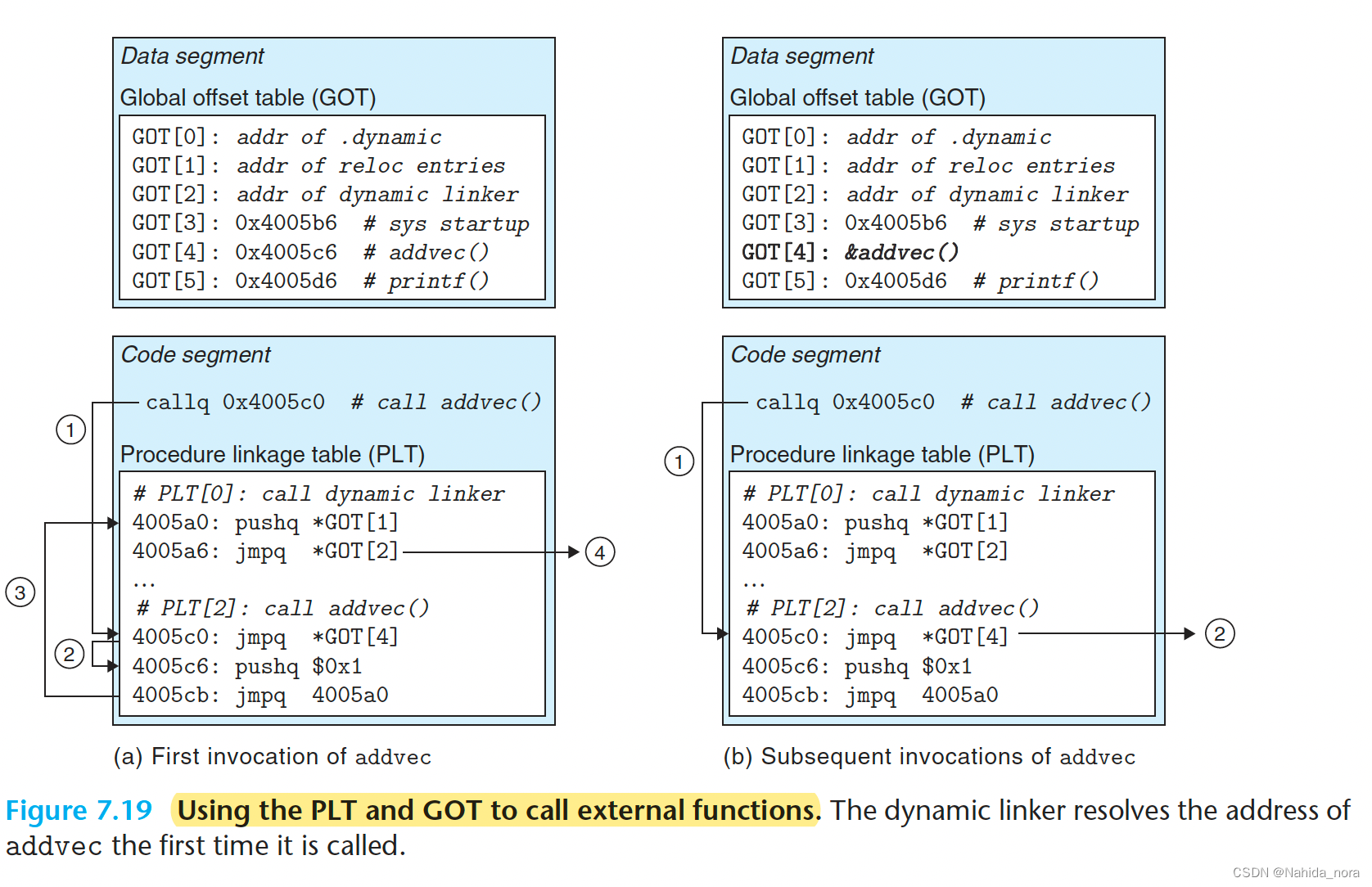
"Lazy binding"通过两个数据结构之间的紧凑但略显复杂的交互来实现:全局偏移表(GOT)和过程链接表(PLT)。如果一个目标模块调用由共享库定义的任何函数,那么它会有自己的GOT和PLT。GOT是数据段的一部分,而PLT是代码段的一部分。
以下是文中提到的PLT和GOT如何协同工作以在运行时解析函数地址的简要说明:
过程链接表(PLT):
- PLT是一个包含16字节代码条目的数组。
- PLT[0]是一个特殊的条目,跳转到动态链接器。每个被执行文件调用的共享库函数都有自己的PLT条目。
- 每个PLT条目负责调用特定的函数。例如,PLT[2]调用addvec,PLT[3]调用printf。
全局偏移表(GOT):
- GOT是一个包含8字节地址条目的数组。与PLT结合使用时,GOT[0]和GOT[1]包含动态链接器在解析函数地址时使用的信息。
- GOT[2]是ld-linux.so模块中动态链接器的入口点。其余的条目对应需要在运行时解析地址的被调用函数。例如,GOT[4]和PLT[2]对应于addvec。
这种组合机制使得在程序运行时能够按需解析函数地址,从而实现懒惰绑定的效果。
图7.19(a)展示了GOT和PLT如何在第一次调用函数addvec时协同工作以懒惰地解析运行时地址的过程:
步骤1:程序不直接调用addvec,而是调用PLT[2],这是addvec的PLT条目。
步骤2:第一个PLT指令通过GOT[4]进行间接跳转。由于每个GOT条目最初指向其对应PLT条目的第二条指令,这个间接跳转简单地将控制传递回PLT[2]的下一条指令。
步骤3:在将addvec的标识(0x1)推送到堆栈后,PLT[2]跳转到PLT[0]。
步骤4:PLT[0]通过GOT[1]间接推送一个参数给动态链接器,然后通过GOT[2]间接跳转到动态链接器。动态链接器使用堆栈中的两个条目来确定addvec的运行时位置,将此地址覆盖到GOT[4],并将控制传递给addvec。
图7.19(b)展示了对addvec的任何后续调用的控制流程:
步骤1:控制再次传递到PLT[2]。
步骤2:然而,这一次通过GOT[4]的间接跳转直接将控制传递给addvec。
Library Interpositioning
Linux链接器支持一种强大的技术,称为库插桩(library interpositioning),允许你拦截对共享库函数的调用并执行你自己的代码。使用插桩,你可以跟踪特定库函数被调用的次数,验证和跟踪其输入和输出值,甚至用完全不同的实现替换它。
基本思想是:给定一些目标函数需要插桩,你创建一个包装函数,其原型与目标函数相同。使用某种特定的插桩机制,然后欺骗系统调用包装函数而不是目标函数。包装函数通常执行自己的逻辑,然后调用目标函数并将其返回值传递给调用者。

插桩可以发生在编译时、链接时或运行时,即在程序加载和执行时。为了探索这些不同的机制,我们将使用图7.20(a)中的示例程序作为运行示例。该程序调用了C标准库(libc.so)中的malloc和free函数。malloc调用从堆中分配32字节的块并返回块的指针。free调用将块返回给堆,供后续对malloc的调用使用。我们的目标是使用插桩在程序运行时跟踪对malloc和free的调用。
Compile-Time Interpositioning
图7.20展示了如何使用C预处理器在编译时进行插桩。mymalloc.c中的每个包装函数(图7.20?)调用目标函数,打印一条跟踪信息,然后返回。本地的malloc.h头文件(图7.20(b))指示预处理器用其包装函数替换对目标函数的每次调用。以下是编译和链接程序的方法:
linux> gcc -DCOMPILETIME -c mymalloc.c
linux> gcc -I. -o intc int.c mymalloc.o
插桩是通过-I.参数实现的,该参数告诉C预处理器在查找malloc.h时先查找当前目录,然后再查找通常的系统目录。请注意,mymalloc.c中的包装函数是使用标准的malloc.h头文件编译的。
运行程序会得到以下跟踪信息:
linux> ./intc
malloc(32)=0x9ee010
free(0x9ee010)
这表示malloc分配了32字节,并返回了指向这个块的指针,然后使用free释放了这个块。
define malloc(size) mymalloc(size)
这行代码是C语言中的宏定义(macro definition)。在这个特定的例子中,这行代码用于定义一个宏,将所有对malloc函数的调用替换为mymalloc函数。
具体而言,#define malloc(size) mymalloc(size) 这行代码的作用是告诉预处理器,每次代码中出现malloc(size)时,都将其替换为mymalloc(size)。这可以在插桩技术中用于实现函数的替代或重定向。
在你提供的上下文中,这样的宏定义用于在编译时插桩,将标准库中的malloc函数替换为自定义的mymalloc函数。这是实现库函数插桩的一种方法,允许你在函数调用时执行额外的逻辑或进行跟踪。
Link-Time Interpositioning
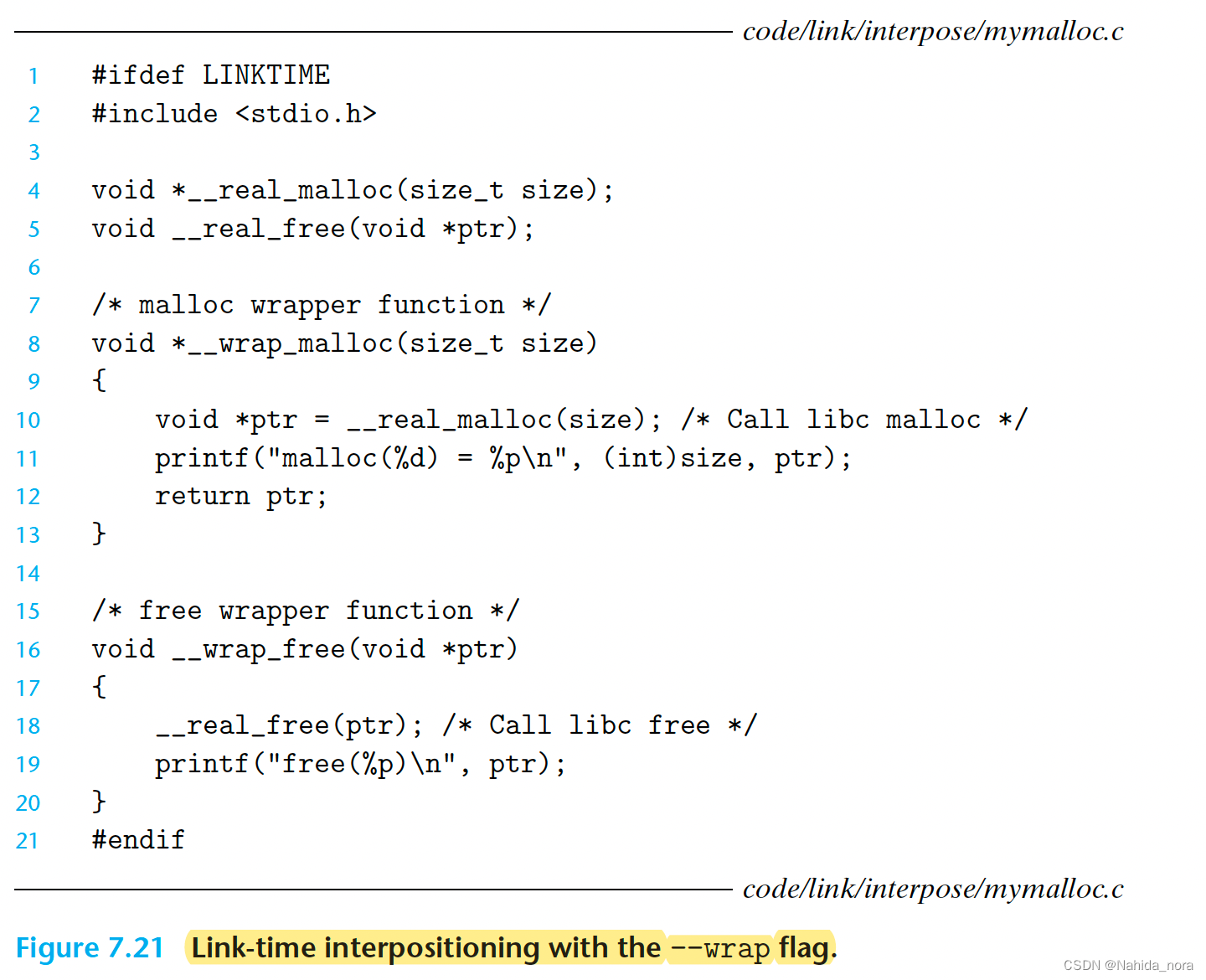
Linux静态链接器支持使用--wrap标志进行链接时插桩。这个标志告诉链接器将对符号f的引用解析为__wrap_f(前缀有两个下划线),并将对符号__real_f(前缀有两个下划线)的引用解析为f。图7.21显示了我们示例程序的包装函数。
以下是将源文件编译成可重定位目标文件的方法:
linux> gcc -DLINKTIME -c mymalloc.c
linux> gcc -c int.c
以下是将目标文件链接为可执行文件的方法:
linux> gcc -Wl,--wrap,malloc -Wl,--wrap,free -o intl int.o mymalloc.o
-Wl,option标志将选项传递给链接器。选项中的每个逗号都被替换为一个空格。因此,-Wl,--wrap,malloc将--wrap malloc传递给链接器,类似地,-Wl,--wrap,free也是如此。
运行程序会得到以下跟踪信息:
linux> ./intl
malloc(32) = 0x18cf010
free(0x18cf010)
这表示malloc分配了32字节,并返回了指向这个块的指针,然后使用free释放了这个块。这里的插桩是通过链接器在链接时完成的,而不是在编译时。
Run-Time Interpositioning
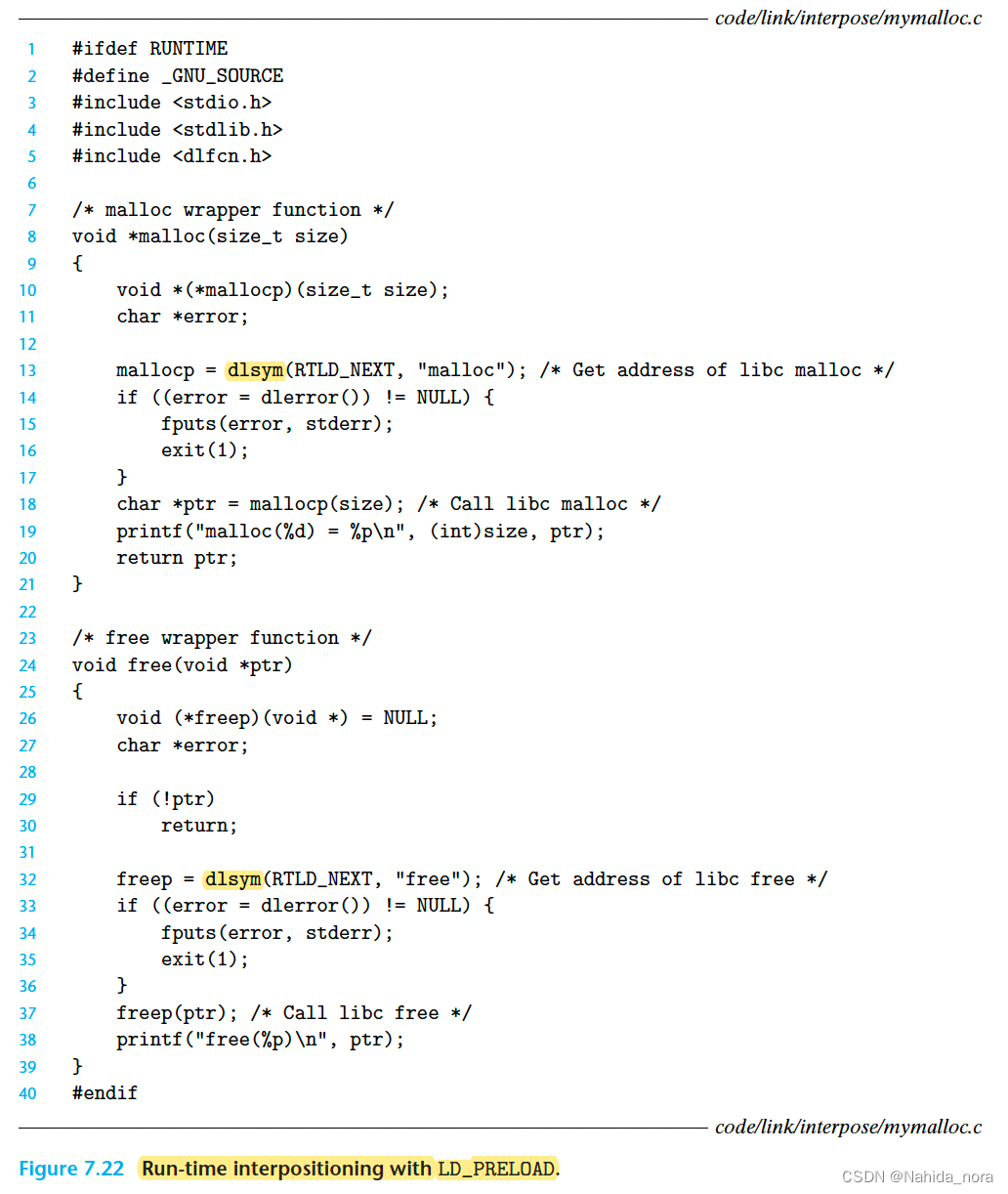
如果将LD_PRELOAD环境变量设置为一系列共享库路径名(用空格或冒号分隔),那么当加载和执行程序时,动态链接器(ld-linux.so)在解析未定义引用时会首先搜索LD_PRELOAD库,而不是其他任何共享库。使用这个机制,你可以在加载和执行任何可执行文件时对任何共享库中的任何函数进行插桩,包括libc.so。图7.22显示了malloc和free的包装函数。在每个包装函数中,对dlsym的调用返回目标libc函数的指针。然后,包装函数调用目标函数,打印跟踪信息,然后返回。
以下是构建包含包装函数的共享库的方法:
linux> gcc -DRUNTIME -shared -fpic -o mymalloc.so mymalloc.c -ldl
以下是编译主程序的方法:
linux> gcc -o intr int.c
以下是如何从bash shell运行程序:
linux> LD_PRELOAD="./mymalloc.so" ./intr
malloc(32) = 0x1bf7010
free(0x1bf7010)
以下是如何从csh或tcsh shells运行它:
linux> (setenv LD_PRELOAD "./mymalloc.so"; ./intr; unsetenv LD_PRELOAD)
malloc(32) = 0x2157010
free(0x2157010)
请注意,你可以使用LD_PRELOAD对任何可执行程序的库调用进行插桩!
linux> LD_PRELOAD="./mymalloc.so" /usr/bin/uptime
malloc(568) = 0x21bb010
free(0x21bb010)
malloc(15) = 0x21bb010
malloc(568) = 0x21bb030
malloc(2255) = 0x21bb270
free(0x21bb030)
malloc(20) = 0x21bb030
malloc(20) = 0x21bb050
malloc(20) = 0x21bb070
malloc(20) = 0x21bb090
malloc(20) = 0x21bb0b0
malloc(384) = 0x21bb0d0
20:47:36 up 85 days, 6:04, 1 user, load average: 0.10, 0.04, 0.05
这表明你可以使用LD_PRELOAD对任何可执行程序的库调用进行插桩,而不仅仅是在特定的示例程序上。
Tools for Manipulating Object Files
在Linux系统上有许多工具可帮助你理解和操作目标文件。特别是GNU binutils软件包在每个Linux平台上都非常有帮助。
- ar: 创建静态库,并插入、删除、列出和提取库成员。
- strings: 列出目标文件中包含的所有可打印字符串。
- strip: 从目标文件中删除符号表信息。
- nm: 列出目标文件符号表中定义的符号。
- size: 列出目标文件中各个部分的名称和大小。
- readelf: 显示目标文件的完整结构,包括ELF头中编码的所有信息。包含了size和nm的功能。
- objdump: 所有二进制工具之母。可以显示目标文件中的所有信息。其最有用的功能是反汇编.text部分中的二进制指令。
此外,Linux系统还提供了用于操作共享库的ldd程序:
- ldd: 列出可执行文件在运行时所需的共享库。
mod 运算
mod 运算,也称为模运算或取余运算,是一种用于计算除法余数的数学运算。在计算机科学和编程中,通常使用符号 % 表示取余操作。以下是一些 mod 运算的例子:
-
基本示例:
5 % 2的结果是 1,因为 5 除以 2 的余数是 1。10 % 3的结果是 1,因为 10 除以 3 的余数是 1。
-
检查奇偶性:
n % 2可用于检查一个数n是否为偶数。如果结果为 0,则n是偶数;如果结果为 1,则n是奇数。
-
计算时钟周期:
- 在计算机系统中,可以使用
mod运算来计算时钟周期。例如,如果时钟周期是 100,那么(t + 1) % 100表示下一个时钟周期。
- 在计算机系统中,可以使用
-
循环索引:
- 在循环结构中,可以使用
mod运算来实现循环索引。例如,i % n可以用作数组索引,确保在数组长度为n时,索引会在 0 到n-1之间循环。
- 在循环结构中,可以使用
-
日期和时间处理:
- 在处理日期和时间时,可以使用
mod运算来实现周期性的时间间隔。例如,(currentHour + 1) % 24可以用于获取下一个小时的时间。
- 在处理日期和时间时,可以使用
这些例子说明了 mod 运算在计算中的多种应用。它通常用于处理循环、周期性问题以及其他需要计算余数的情况。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Midjourney表情包制作及变现最全教程
- 数组A[m+n]中存放了两个线性表(a1,a2,.....am)和(b1,b2.....bn),将数组中的两个线性表的位置互换,要求空间复杂度为1
- 新颖度爆表。网络药理学+PPI+分子对接+实验验证
- 第十章 React之使用CSS、Sass
- springboot/java/php/node/python智慧点餐系统【计算机毕设】
- 【Python】Python 中使用for循环取返回值 json 中的指定值
- 学习STM32获取相关资料的官方网站
- 第4章-第1节-初识Java的数组
- 外包干了1年,已经摆烂了
- 掌握鸿蒙开发技术,24年初即将启程!