How to Clean Text for Machine Learning with Python
在本教程中,您将了解如何清理和准备文本,以便使用机器学习进行建模。
完成本教程后,您将了解:
如何通过开发自己的非常简单的文本清理工具开始。
如何更上一层楼并使用 NLTK 库中更复杂的方法。
在使用现代文本表示方法(如单词嵌入)时如何准备文本。
使用我的新书《自然语言处理的深度学习》开始您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
教程概述
本教程分为 6 个部分;他们是:
- 弗朗茨·卡夫卡的《变形记》
- 文本清理是特定于任务的 手动令牌化
- 使用 NLTK 进行标记化和清理
- 其他文本清理注意事项
- 清理单词嵌入文本的提示
准备数据 弗朗茨·卡夫卡的《变形记》
https://www.gutenberg.org/cache/epub/5200/pg5200.txt
在本教程中,我们将使用弗朗茨·卡夫卡 (Franz Kafka) 的《变形记》一书中的文本。没有具体的原因,除了它很短,我喜欢它,你可能也喜欢它。我希望这是大多数学生在学校必须阅读的经典作品之一。
《变形记》的全文可从古腾堡计划免费获得。
弗朗茨·卡夫卡(Franz Kafka)在古腾堡计划中的变形记
您可以在此处下载文本的 ASCII 文本版本:
弗朗茨·卡夫卡(Franz Kafka)的变形记纯文本UTF-8(可能需要加载页面两次)。
该文件包含我们不感兴趣的页眉和页脚信息,特别是版权和许可信息。打开文件并删除页眉和页脚信息,并将文件另存为“metamorphosis_clean.txt”。
The start of the clean file should look like:
"One morning, when Gregor Samsa woke from troubled dreams, he found himself transformed in his bed into a horrible vermin.
The file should end with:
And, as if in confirmation of their new dreams and good intentions, as soon as they reached their destination Grete was the first to get up and stretch out her young body."
文本清理是基于特定任务的
在实际掌握了文本数据后,清理文本数据的第一步是对你要实现的目标有一个强烈的想法,并在该上下文中查看你的文本,看看到底有什么帮助。
花点时间看一下课文。你注意到了什么?
这是我所看到的:
- 它是纯文本,因此没有要解析的标记(耶!
- 德语原文的翻译使用英式英语(例如“travelling”)。
- 这些行被人为地用大约 70 个字符(meh) 的新行包裹起来。
- 没有明显的错别字或拼写错误。
- 有逗号、撇号、引号、问号等标点符号。 有连字符的描述,如“盔甲状”。
- 有很多使用em破折号(“-”)来继续句子(也许用逗号代替? 有名字(例如“萨姆萨先生”) 似乎没有需要处理的数字(例如1999年)
- 有部分标记(例如“II”和“III”),我们删除了第一个“I”。
手动令牌化
文本清理很困难,但我们选择使用的文本已经很干净了。
我们可以编写一些 Python 代码来手动清理它,这对于您遇到的那些简单问题是一个很好的练习。正则表达式和拆分字符串等工具可以让你走很长的路。

加载数据
filename = 'metamorphosis_clean.txt'
file = open(filename, 'rt',encoding='utf-8')
text = file.read()
file.close()
以空格为标志分词
filename = 'metamorphosis_clean.txt'
file = open(filename, 'rt')
text = file.read()
file.close()
# split into words by white space
words = text.split()
print(words[:100])
Split by Whitespace and Remove Punctuation (特殊符号)
Another approach might be to use the regex model (re) and split the document into words by selecting for strings of alphanumeric characters (a-z, A-Z, 0-9 and ‘_’).

# load text
filename = 'metamorphosis_clean.txt'
file = open(filename, 'rt')
text = file.read()
file.close()
# split into words by white space
words = text.split()
# remove punctuation from each word
import string
table = str.maketrans('', '', string.punctuation)
stripped = [w.translate(table) for w in words]
print(stripped[:100])
Normalizing Case 词规范统一
全都变成小写
file = open(filename, 'rt')
text = file.read()
file.close()
# split into words by white space
words = text.split()
# convert to lower case
words = [word.lower() for word in words]
print(words[:100])
Tokenization and Cleaning with NLTK
安装
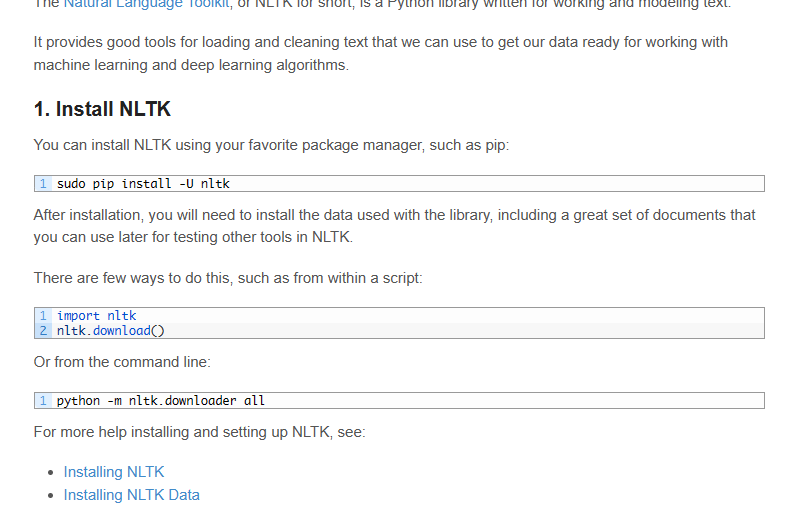
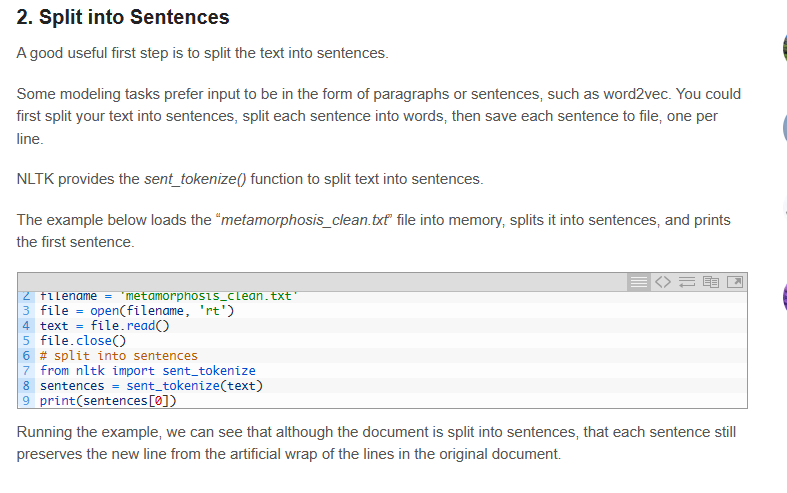
split into sentence
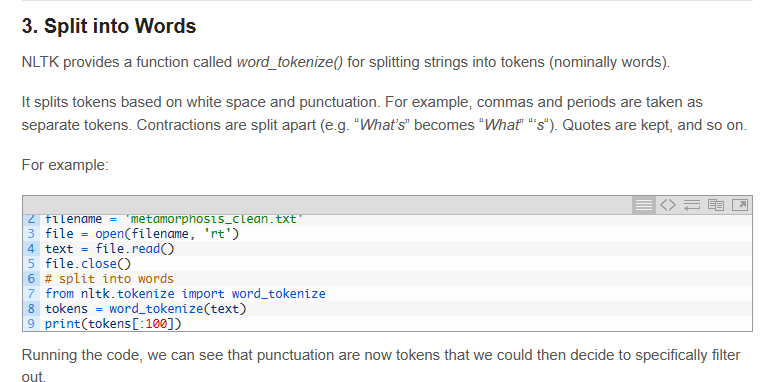
split into words
filter out punctuation

filter out stop words
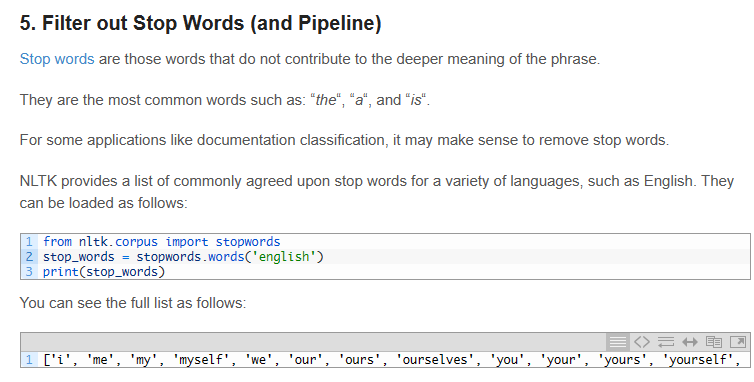
# load data
filename = 'metamorphosis_clean.txt'
file = open(filename, 'rt')
text = file.read()
file.close()
# split into words
from nltk.tokenize import word_tokenize
tokens = word_tokenize(text)
# convert to lower case
tokens = [w.lower() for w in tokens]
# remove punctuation from each word
import string
table = str.maketrans('', '', string.punctuation)
stripped = [w.translate(table) for w in tokens]
# remove remaining tokens that are not alphabetic
words = [word for word in stripped if word.isalpha()]
# filter out stop words
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
words = [w for w in words if not w in stop_words]
print(words[:100])
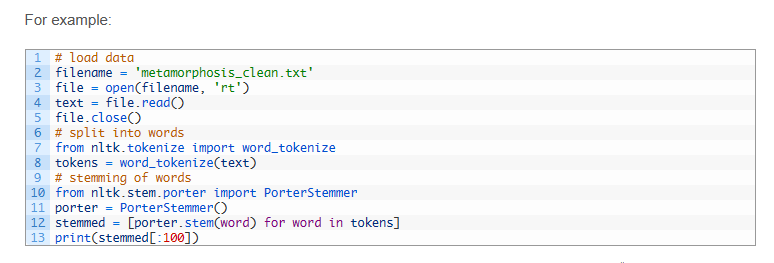
Stem Words
如 fish fishing fished 统一为fish
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- houdini 神经网络
- 批量检测小程序是否封禁
- 个性化定制的知识付费小程序,为用户提供个性化的知识服务
- 一个寒假能学会黑客技术吗?看完你就知道了
- 并发控制工具类CountDownLatch、CyclicBarrier、Semaphore
- 微信小程序登录(生成token,token校验)——后端
- 【map】【滑动窗口】C++算法:最小区间
- 2023.12.25 ubuntu程序输出另存为文件log
- gitee(ssh)同步本地
- window安装DockerDesktop无法使用host网络模式解决方案