爬虫案例分享:爬虫获取房天下房地产相关数据
发布时间:2024年01月06日
爬虫案例分享:爬取房天下房地产数据
一、踩点房天下网
1、让我带各位未来的富翁们选购楼房
不一定要买,可以先了解房地产市场,这里我们选择二手房数据,因为博主的预算有限,也就只能考虑二手房了😔。![]()
- 筛选出我们想看的数据,然后分析页面网址。
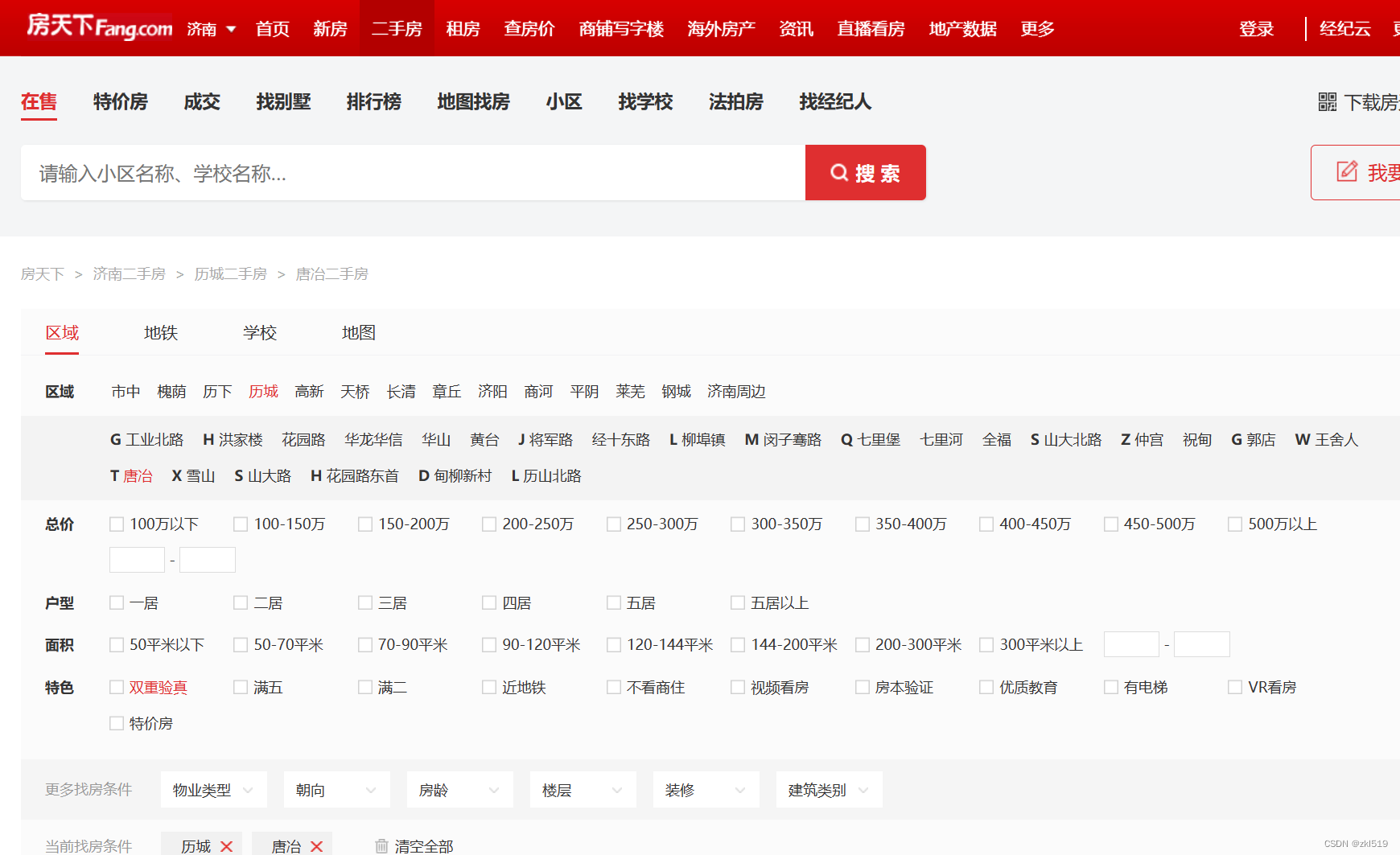
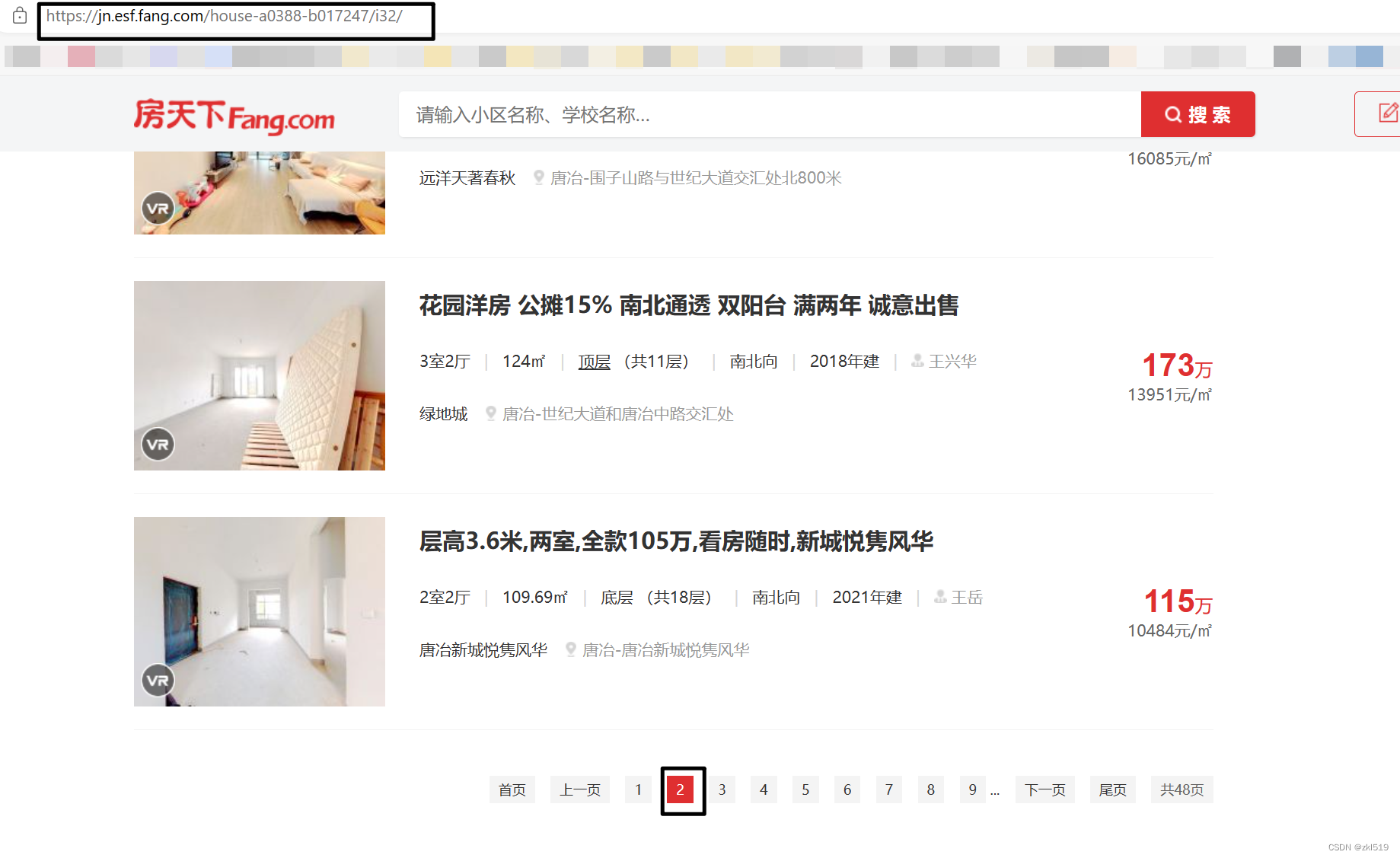
- 分析不同页面的URL地址
页面地址由页码与https://jn.esf.fang.com/house-a0388-b017247/i3 共同决定,例如第一页便是https://jn.esf.fang.com/house-a0388-b017247/i31。
二、分析页面数据
1、F12查看页面源码

2、根据网页元素,分析网页源码

- 这里发现每一条数据都对应一个 class属性为clearfix的dl元素,我们想要的数据都在这个dl标签中。我们可以先用Xpath语句测试一下我们的猜想。
在F12的元素界面按Ctrl+F,出现搜索框输入我们的xpath语句://dl[@class=“clearfix”],查看所有筛选出的元素,也印证了我们的想法。

- 继续寻找我们想要的数据,发现所有我们关注的信息如:价格、大小、地产商等信息均在dl标签中

(如果大家想学习xpath相关知识,可以关注我,后续我将推出细致的xpath语句的相关教学)
三、编写python代码爬取数据。
1、 首先,我们针对单个页面编写爬虫语句
import requests
from lxml import etree
import re
import os
import time
#本方法用于替换字符中的 \t \r \n ' '
def rentr(str):
return re.sub(r'\\t|\\r|\\n','',str).strip()
url = 'https://jn.esf.fang.com/house-a0388-b017247/i31'
#初步尝试,网站进行了一定程度的保护,我们需要再请求头(headers)中添加 cookie属性,我们可以通过请求抓包的方式获取cookie。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0' #用户代理
,'Referer':'https://jn.esf.fang.com/' #请求来源
,'cookie':''#需要用自己的cookie
}
#通过get方法请求url地址
resp = requests.get(url,headers=headers)
#修改返回值的编码方式
resp.encoding = resp.apparent_encoding
#HTML类对HTML文本进行初始化,构造XPath解析对象
html = etree.HTML(resp.text)
#这里是取到所有class属性等于clearfix的dl标签
r = html.xpath('//dl[@class= "clearfix"]')
titlel = []
layoutl = []
sizel = []
positionl = []
directionl = []
completionl= []
add_shopl= []
addlrl= []
pricel= []
unitl= []
houseurll= []
imgurll= []
#循环dl标签下所有的标签
for i,ri in enumerate(r):
#获取当前标签下的元素
title = rentr(ri.xpath('.//span[@class = "tit_shop"]/text()')[0]) #标题
tel_shop = ri.xpath('.//p[@class = "tel_shop"]/text()')
link_rk = ri.xpath('.//a[@class = "link_rk"]/text()[1]')
layout = rentr(tel_shop[0]) #布局
size = rentr(tel_shop[1])
position = ""
if len(link_rk) != 0:
position = link_rk[0]+rentr(tel_shop[2]) + rentr(tel_shop[3])
else:
position = rentr(tel_shop[2]) + rentr(tel_shop[3]) #层数位置
direction = rentr(tel_shop[4]) #朝向
completion = rentr(tel_shop[5])
add_shop = rentr(ri.xpath('.//p[@class = "add_shop"]/a/text()')[0])
addr = rentr(ri.xpath('.//p[@class = "add_shop"]/span/text()')[0])
price = rentr(ri.xpath('.//dd[@class = "price_right"]/span/b/text()')[0]
+ ri.xpath('.//dd[@class = "price_right"]/span/text()')[1])
unit = rentr(ri.xpath('.//dd[@class = "price_right"]/span/text()')[2])
houseurl = "https://jn.esf.fang.com" + rentr(ri.xpath('//*[@id="kesfqbfylb_A01_01_06"]/dd[1]/h4/a/@href')[0])
imgurl = 'https:'+ri.xpath('//*[@id="kesfqbfylb_A01_01_03"]/dt/a/img/@src')[0]
titlel.append(title)
layoutl.append(layout)
sizel.append(size)
positionl.append(position)
directionl.append(direction)
completionl.append(completion)
add_shopl.append(add_shop)
addlrl.append(addr)
pricel.append(price)
unitl.append(unit)
houseurll.append(houseurl)
imgurll.append(imgurl)
#因为后续要将数据存入到excel中,所以对数据进行了包装
data = {
"title" : titlel,
"layout" : layoutl,
"size" : sizel,
"position" : positionl,
"direction" : directionl,
"completion" : completionl,
"add_shop" : add_shopl,
"addr" : addlrl,
"price" : pricel,
"unit" : unitl,
"houseurl" : houseurll,
"imgurl" : imgurll,
}
print(data)
2、为了更方便的展示数据写一个将数据存入excel的方法
#利用pandas类中的方法将数据导出到excel中
from pandas import pandas as pd
def write_data2excel(file_path :str,data : list):
#判断文件是否已存在,存在则续写,否则创建。
if os.path.exists(file_path) :
df = pd.read_excel(file_path)
new_data = pd.DataFrame(data)
df = pd.concat([df, new_data], ignore_index=True)
df.to_excel(file_path, index=False)
else :
df = pd.DataFrame(data)
df.to_excel(file_path, index=False)
3、不能满足于爬取一个界面上的数据,爬取多个页签上的数据
import time
import requests
#拼接我们的url 并请求
url = 'https://jn.esf.fang.com/house/i3'
for i in range(1,101,1):
urli = url +str(i)
# requests.get(urli) #先测试拼接的链接是否正确再请求
#慢点薅数据,做一个有操守的爬虫,小睡一会
# 每次爬取数据让进程睡一秒,保证服务器安全,也保证你的安全,降低被验证码验证的可能
time.sleep(1)
4、得到最后的爬虫程序
#爬取济南房天下二手房数据 现房是买不上了,二手房看一看吧
import requests
from lxml import etree
import re
import os
import time
# from xlsxwriter import Workbook
# import openpyxl
from pandas import pandas as pd
def rentr(str):
return re.sub(r'\\t|\\r|\\n','',str).strip()
def write_data2excel(file_path :str,data : list):
if os.path.exists(file_path) :
df = pd.read_excel(file_path)
new_data = pd.DataFrame(data)
df = pd.concat([df, new_data], ignore_index=True)
df.to_excel(file_path, index=False)
else :
df = pd.DataFrame(data)
df.to_excel(file_path, index=False)
def geturl(url,path):
#包装一下请求,避免被反扒策略拦截
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0' #用户代理
,'Referer':'https://jn.esf.fang.com/' #请求来源
,'cookie':'' #需要用自己的cookie
}
#通过get方法请求url地址
resp = requests.get(url,headers=headers)
#修改返回值的编码方式
resp.encoding = resp.apparent_encoding
#HTML类对HTML文本进行初始化,构造XPath解析对象
html = etree.HTML(resp.text)
r = html.xpath('//dl[@class= "clearfix"]')
titlel = []
layoutl = []
sizel = []
positionl = []
directionl = []
completionl= []
add_shopl= []
addlrl= []
pricel= []
unitl= []
houseurll= []
imgurll= []
for i,ri in enumerate(r):
title = rentr(ri.xpath('.//span[@class = "tit_shop"]/text()')[0]) #标题
tel_shop = ri.xpath('.//p[@class = "tel_shop"]/text()')
link_rk = ri.xpath('.//a[@class = "link_rk"]/text()[1]')
layout = rentr(tel_shop[0]) #布局
size = rentr(tel_shop[1])
position = ""
if len(link_rk) != 0:
position = link_rk[0]+rentr(tel_shop[2]) + rentr(tel_shop[3])
else:
position = rentr(tel_shop[2]) + rentr(tel_shop[3]) #层数位置
direction = rentr(tel_shop[4]) #朝向
completion = rentr(tel_shop[5])
add_shop = rentr(ri.xpath('.//p[@class = "add_shop"]/a/text()')[0])
addr = rentr(ri.xpath('.//p[@class = "add_shop"]/span/text()')[0])
price = rentr(ri.xpath('.//dd[@class = "price_right"]/span/b/text()')[0]
+ ri.xpath('.//dd[@class = "price_right"]/span/text()')[1])
unit = rentr(ri.xpath('.//dd[@class = "price_right"]/span/text()')[2])
houseurl = "https://jn.esf.fang.com" + rentr(ri.xpath('//*[@id="kesfqbfylb_A01_01_06"]/dd[1]/h4/a/@href')[0])
imgurl = 'https:'+ri.xpath('//*[@id="kesfqbfylb_A01_01_03"]/dt/a/img/@src')[0]
titlel.append(title)
layoutl.append(layout)
sizel.append(size)
positionl.append(position)
directionl.append(direction)
completionl.append(completion)
add_shopl.append(add_shop)
addlrl.append(addr)
pricel.append(price)
unitl.append(unit)
houseurll.append(houseurl)
imgurll.append(imgurl)
data = {
"title" : titlel,
"layout" : layoutl,
"size" : sizel,
"position" : positionl,
"direction" : directionl,
"completion" : completionl,
"add_shop" : add_shopl,
"addr" : addlrl,
"price" : pricel,
"unit" : unitl,
"houseurl" : houseurll,
"imgurl" : imgurll,
}
write_data2excel(path, data)
url = 'https://jn.esf.fang.com/house/i3'
for i in range(1,101,1):
urli = url +str(i)
geturl(urli,"房地产.xlsx")
time.sleep(1)
四、总结
我们通过分析网站源码,找到网页中我们关注的数据,利用request库中的方法爬取到数据元素,并通过正则表达式等提取我们想要的数据,并通过pandas库中的方法,将数据导出到excel中保存并查看,得到结论:房价真高,生活不易,打工真难。对于爬虫或者购房,有什么问题或者想法的,都可以在评论区沟通交流哦。
当然用了人家的数据 ,如果有购房需求也可以在房天下选购哦。
关注我,有更有趣的知识分享哦
本文内容仅供参考学习,如果雷同,纯属偶然,不得用于商用或非法用途,不负任何法律责任,技术无罪。
文章来源:https://blog.csdn.net/zkl519/article/details/135418463
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AI智能绘图
- 如何将图片转为PDF
- 为什么学C语言和做底层的工作不好找,工资还没做Java的高?
- 05-Seata下SQL使用限制
- 基于SpringBoot的婚恋交友网站 JAVA简易版
- 探寻编程深渊:那些你无法想象的‘最差程序员’
- 安卓Android Studioy读写NXP ICODE2 15693标签源码
- 使用results.csv文件数据绘制mAP对比图
- 郑州大学算法设计与分析实验4
- 从国内发货到印尼,海运空运双清到门攻略!