爬虫中scrapy模块的概念作用和工作流程
发布时间:2023年12月20日
scrapy的概念和流程
学习目标:
- 了解 scrapy的概念
- 了解 scrapy框架的作用
- 掌握 scrapy框架的运行流程
- 掌握 scrapy中每个模块的作用
1. scrapy的概念
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。
Scrapy 使用了Twisted['tw?st?d]异步网络框架,可以加快我们的下载速度。
Scrapy文档地址:http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
2. scrapy框架的作用
少量的代码,就能够快速的抓取
3. scrapy的工作流程
3.1 回顾之前的爬虫流程
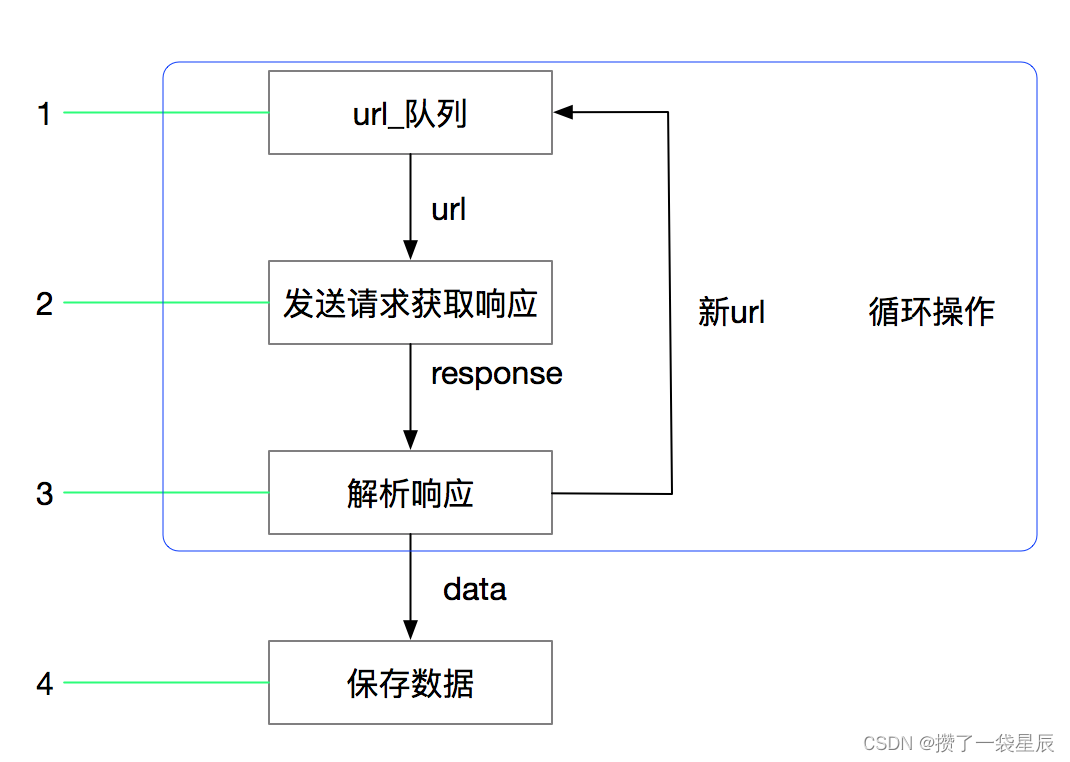
3.2 上面的流程可以改写为
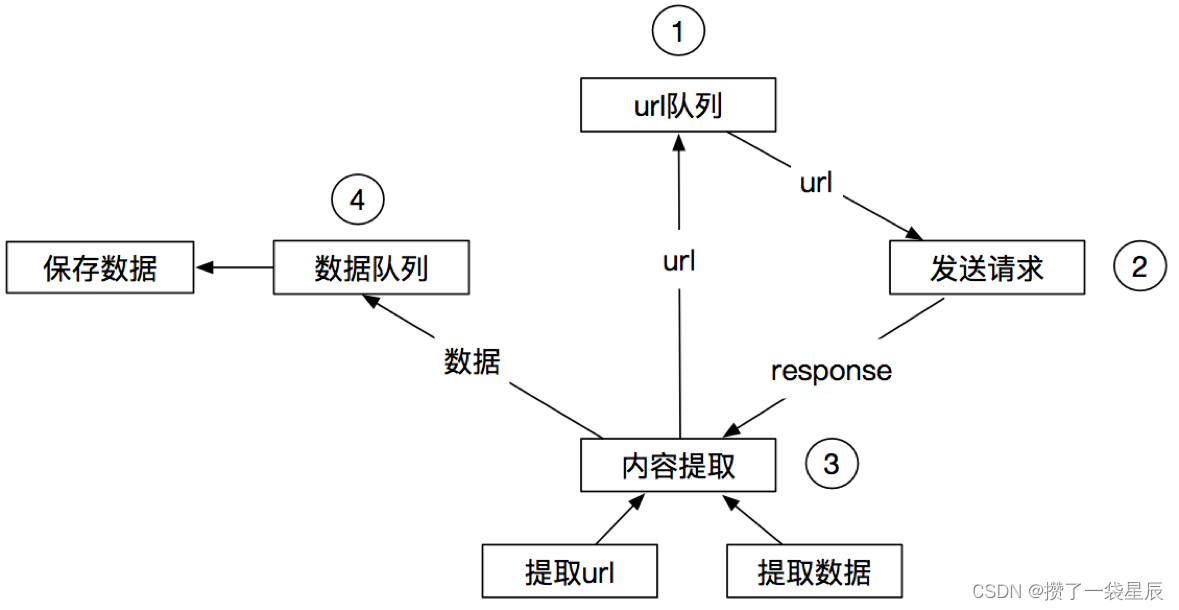
3.3 scrapy的流程
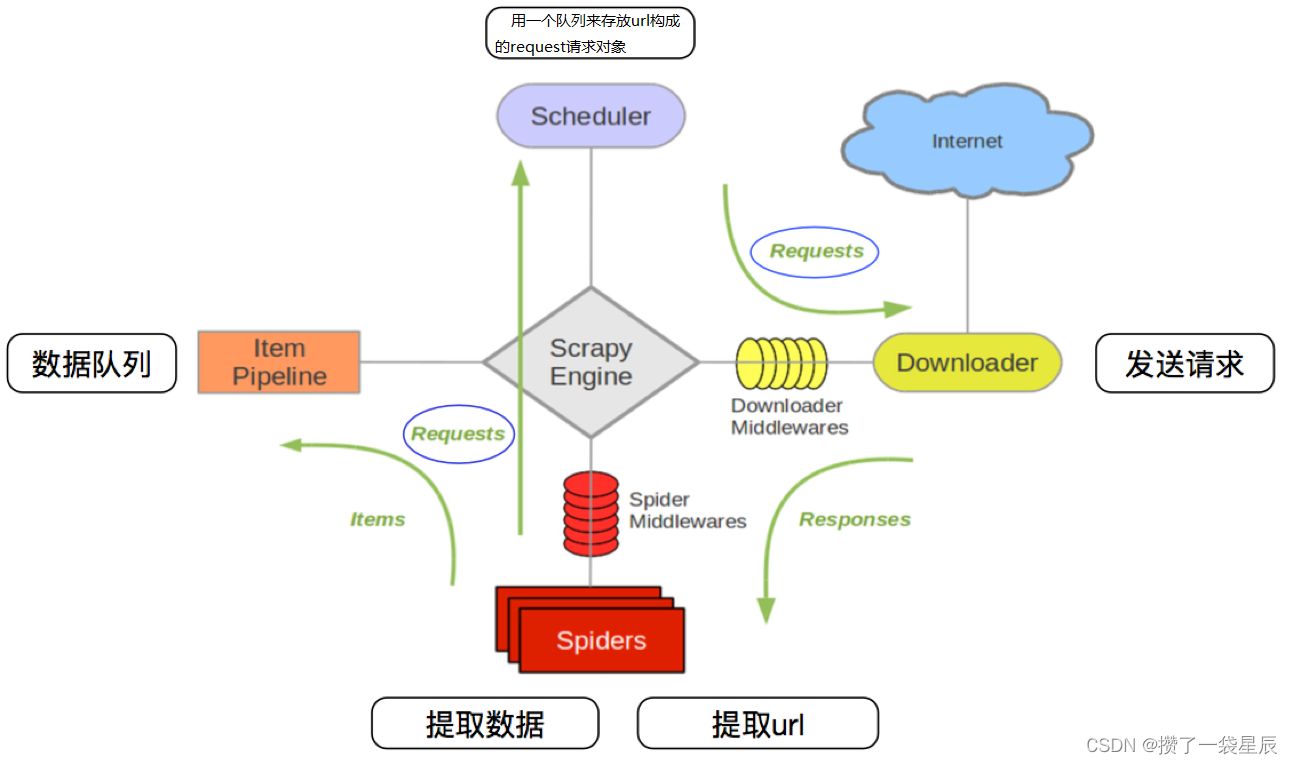
其流程可以描述如下:
- 爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器,重复步骤2
- 爬虫提取数据—>引擎—>管道处理和保存数据
注意:
- 图中中文是为了方便理解后加上去的
- 图中绿色线条的表示数据的传递
- 注意图中中间件的位置,决定了其作用
- 注意其中引擎的位置,所有的模块之前相互独立,只和引擎进行交互
3.4 scrapy的三个内置对象
- request请求对象:由url method post_data headers等构成
- response响应对象:由url body status headers等构成
- item数据对象:本质是个字典
3.5 scrapy中每个模块的具体作用
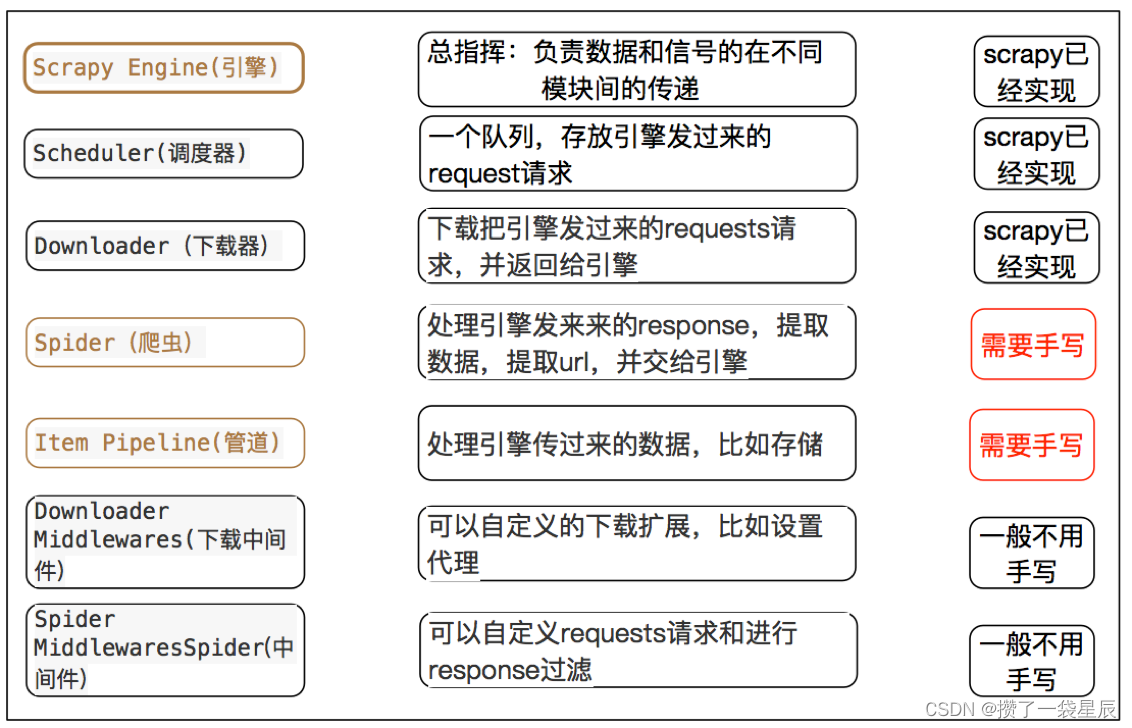
注意:
- 爬虫中间件和下载中间件只是运行逻辑的位置不同,作用是重复的:如替换UA等
小结
- scrapy的概念:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架
- scrapy框架的运行流程以及数据传递过程:
- 爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器,重复步骤2
- 爬虫提取数据—>引擎—>管道处理和保存数据
- scrapy框架的作用:通过少量代码实现快速抓取
- 掌握scrapy中每个模块的作用:
引擎(engine):负责数据和信号在不腰痛模块间的传递
调度器(scheduler):实现一个队列,存放引擎发过来的request请求对象
下载器(downloader):发送引擎发过来的request请求,获取响应,并将响应交给引擎
爬虫(spider):处理引擎发过来的response,提取数据,提取url,并交给引擎
管道(pipeline):处理引擎传递过来的数据,比如存储
下载中间件(downloader middleware):可以自定义的下载扩展,比如设置代理ip
爬虫中间件(spider middleware):可以自定义request请求和进行response过滤,与下载中间件作用重复
文章来源:https://blog.csdn.net/xiugtt6141121/article/details/135094524
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python一个键多个值 以及列表,元组,集合,字典辨析
- C++嵌入式编程:硬件控制与物联网
- 全面了解网络性能监测:从哪些方面进行监测?
- 【PUSDN】MySQL数据库建表规范【企业级】
- 自动创建设备节点代码的实现
- C 语言中布尔值的用法和案例解析
- Modbus RTU协议与S7 200 PLC通讯
- Web3与环保:区块链如何推动可持续发展
- matlab自动控制状态反馈 设计PID控制回路、保证控制效果
- 【AIGC-图片生成视频系列-4】DreamTuner:单张图像足以进行主题驱动生成