TCP的拥塞控制_基础知识_四种拥塞控制方法
TCP的拥塞控制
一.拥塞控制的基本概念
- 在某段时间,若
对网络中某一资源的需求超过了该资源所能提供的可用部分,网络性能就要变坏,这种情况就叫作拥塞。- 计算机网络中的链路容量(带宽)、交换节点中的缓存和处理机等都是网络的资源
- 若出现拥塞而不进行控制,整个网络的吞吐量将随输入负荷的增大而下降。
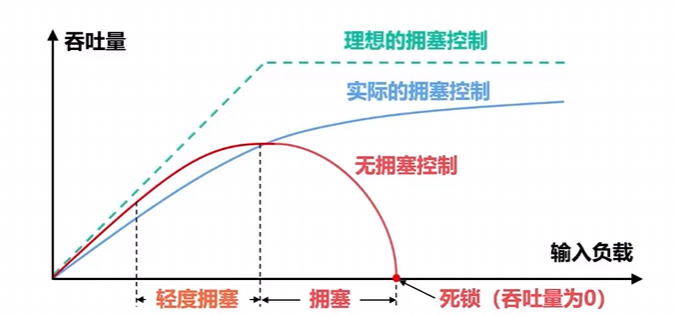
二.拥塞控制的基本方法
首先,先对比流量控制与拥塞控制
流量控制:以接收方的接收能力控制发送方(源点)的发送速率只与特定的点对点通信的发送方和接收方之间的流量有关
拥塞控制:源点根据各方面因素,按拥塞控制算法自行控制发送速率全局性问题,涉及网络中所有的主机、路由器等总结:流量控制是接收方限制发送方的流量,拥塞控制是根据全局的情况,设置了拥塞窗口,限制发送.
从控制论的角度分类,可分为开环控制和闭环控制
开环控制:
- 试图用良好的设计来解决问题。
- 从一开始就保证问题不会发生。
- 一旦系统启动并运行起来,就不需要中途修正。
当网络的流量特征可以准确规定且性能要求可以事先获得时,适合使用开环控制。
闭环控制:
- 基于反馈的控制方法,包括以下三个部分:
- 监测网络拥塞在何时、何地发生。
- 把拥塞发生的相关信息传送到可以采取行动的地方。
- 调整网络的运行以解决拥塞问题。
当网络的流量特征不能准确描述或者当网络不提供资源预留时,适合使用闭环控制。因特网采用的就是闭环控制方法。
衡量网络拥塞的一些指标:
- 由于缓存溢出而丢弃的分组的百分比
- 路由器的平均队列长度
- 超时重传的分组数量
- 平均分组时延和分组时延的标准差
根据拥塞信息的反馈形式,可将闭环拥塞控制算法分为显示反馈算法和隐式反馈算法.
显示反馈算法:从拥塞节点(即路由器)向源点提供关于网络中拥塞状态的显式反馈信息。
隐式反馈算法:源点自身通过对网络行为的观察(例如超重传或往返时间RTT)来推断网络是否发生了拥塞。TCP采用的就是隐式反馈算法。
拥塞控制并不仅仅是运输层要考虑的问题。显式反馈算法就必须涉及网络层。虽然一些网络体系结构(如ATM网络)主要在网络层实现拥塞控制,但因特网主要利用隐式反馈在运输层实现拥塞控制。
三.TCP的四种拥塞控制的方法
慢开始,拥塞避免,快重传,快恢复
为了集中精力讨论拥塞控制算法的基本原理,假定如下条件
1.数据是单方向传送的,而另一个方向只传送确认。
2.接收方总是有足够大的接收缓存空间,因而发送方的发送窗口的大小仅由网络的拥塞程度来决定,也就是不考虑接收方对发送方的流量控制。
3.以TCP最大报文段MSS(即TCP报文段的数据载荷部分)的个数作为讨论问题的单位,而不是以字节为单位(尽管TCP是面向空节流的)
首先,先来认清概念swnd,cwnd,rwnd
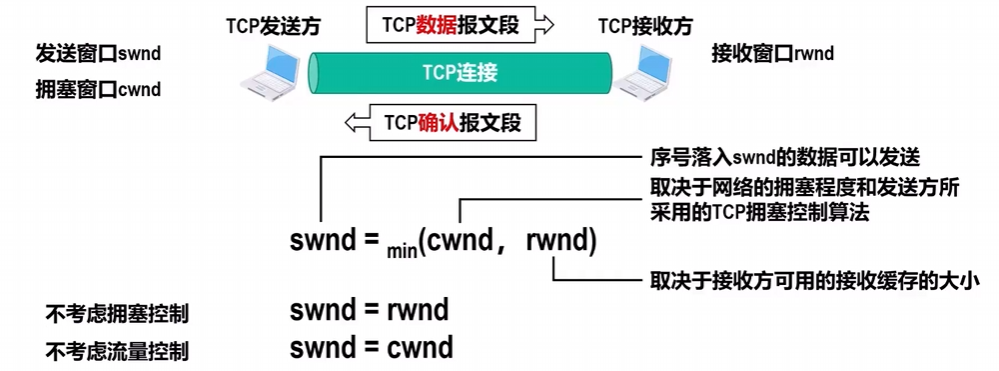
图解:
| 发送窗口的大小由接收窗口和拥塞窗口共同决定 |
加入慢开始门限
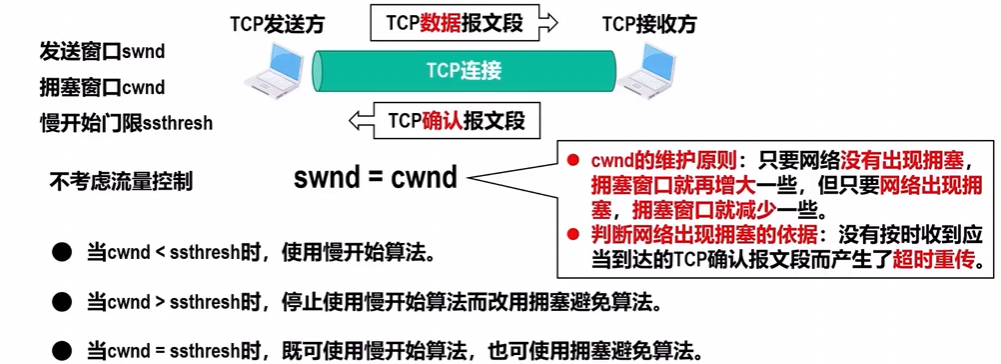
(一)慢开始算法与拥塞避免算法
最开始的拥塞窗口为cwnd=1,防止一开始数据传输量过大,造成拥塞.
假设慢开始门限值ssthresh=16,也就是说cwnd增大到16之后,切换算法为拥塞避免算法.
慢开始算法开始的过程:指数增长,一个传输轮次结束,也就是一个RTT的时间结束,cwnd由1变2,2变4,4变8…
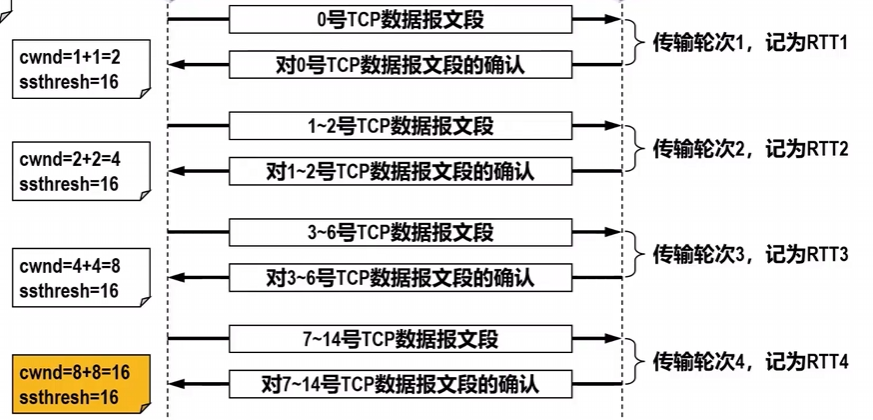
拥塞避免算法开始的过程:线性增长,不同与慢开始算法的指数增长,拥塞避免每次只+1.
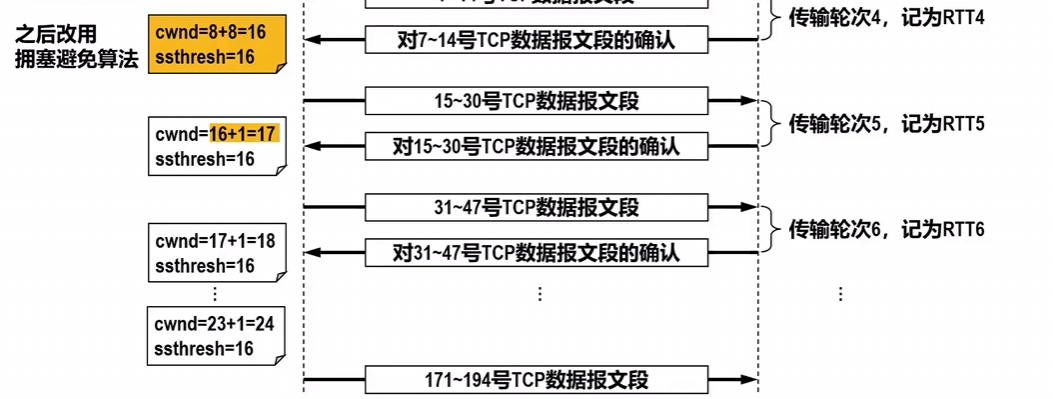
假如,出现了部分报文段丢失的情况,重传计时器超时,此时拥塞窗口变为1,重新开始慢开始算法,同时慢开始门限值/2.
总结:直观图如下:
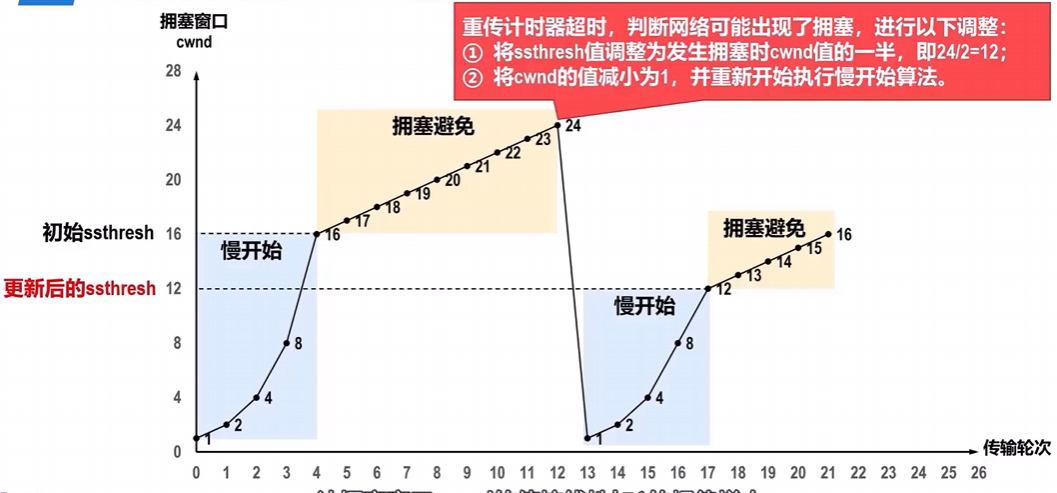
图解:
| “慢开始”是指一开始向网络注入的报文段少,而并不是指拥塞窗口cwnd的值增长速度慢。 “拥塞避免”也并非指完全能够避免拥塞,而是指在拥塞避免阶段将cwnd值控制为按线性规律增长,使网络比较不容易出现拥塞。 |
(二) 快重传算法和快恢复算法(改进TCP性能)
快重传算法有什么用?
- 采用快重传算法可以让发送方尽早知道发生了个别TCP报文段的丢失。
- “快重传”是
指使发送方尽快(尽早)进行重传,而不是等重传计时器超时再重传。- 这就要求
接收方不要等待自己发送数据时才进行捎带确认,而是要立即发送确认,即使收到了失序的报文段也要立即发出对已收到的报文段的重复确认。 发送方一旦收到3个连续的重复确认,就将相应的报文段立即重传,而不是等该报文段的重传计时器超时再重传。
- 这就要求
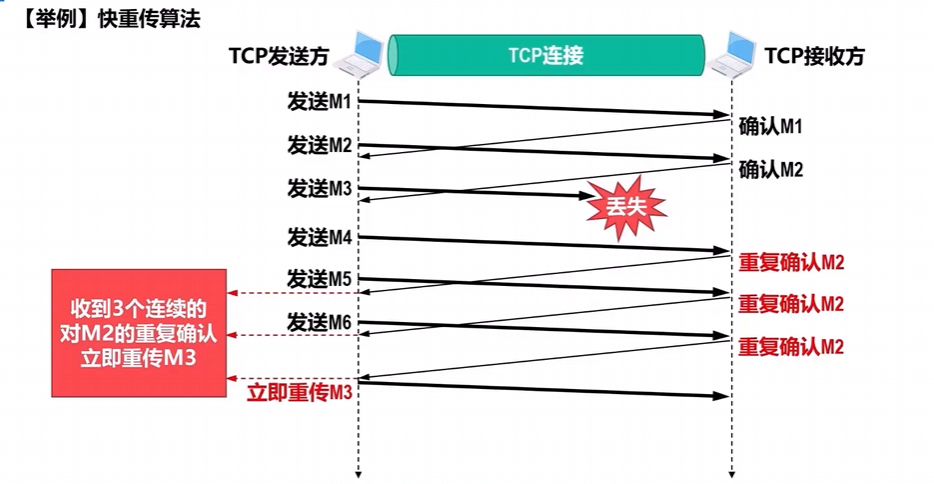
图解:
| 对于个别丢失的报文段,发送方不会出现超时重传,也就不会误认为出现了拥塞而错误地把拥塞窗口cwnd的值减为1。实践证明,使用快重传可以使整个网络的吞吐量提高约20%。 |
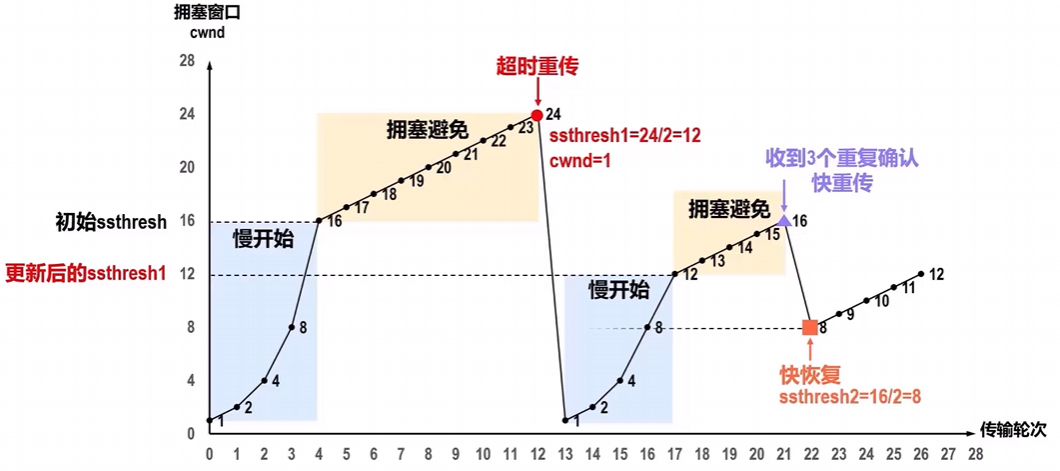
快恢复算法有什么用?
- 与快重传算法配合使用的是快恢复算法,发送方一旦
收到3个重复确认,就知道现在只是丢失了个别的报文段,于是不启动慢开始算法,而是执行快恢复算法。发送方将慢开始门限ssthresh的值和拥塞窗口cwnd的值都调整为当前cwnd值的一半,并开始执行拥塞避免算法。- 也有的快恢复实现是把快恢复开始时的cwnd值再增大一些,即cwnd=新ssthresh+3.
- 既然发送方收到了3个重复的确认,就表明有3个数据报文段已经离开了网络。
- 这3个报文段不再消耗网络资源而是停留在接收方的接收缓存中。
- 可见现在网络中不是堆积了报文段而是减少了3个报文段,因此可以适当把cwnd值增大一些。
总结:直观图如下:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 立体仓库系统堆垛机电气设计原理
- GPT4+Python近红外光谱数据分析及机器学习与深度学习建模
- 一.无名管道(pipe)
- EMQX windows 安装与使用
- JAVA电商平台免费搭建 B2B2C商城系统 多用户商城系统 直播带货 新零售商城 o2o商城 电子商务 拼团商城 分销商城
- Java版企业电子招标采购系统源码——鸿鹄电子招投标系统的技术特点
- Java毕业设计-基于ssm的饮品店接单网页管理系统-第86期
- 每日一练2023.12.23——考试座位号【PTA】
- 安全密码(字符串)
- MySQL中常见的函数和具体使用实例说明汇总