LinkedIn 开源分布式存储系统Ambry
分布式存储入门认知
分布式存储是一种用于处理大规模数据的存储系统。随着互联网的发展和数据量的爆发式增长,传统的集中式存储已经无法满足需求。分布式存储通过将数据分散存储在多个节点上,实现高可靠性、高扩展性和高性能的存储解决方案
分布式存储的基本原理
分布式存储系统由多个存储节点组成,每个节点负责存储一部分数据。数据通常被分成多个块,并通过数据切分和冗余备份来提高容错性和数据可用性。节点之间通过网络连接进行通信和数据同步,实现数据的高效分布式存储和访问
分布式存储的优势
-
高可靠性:分布式存储通过数据冗余备份和故障转移来提供高可靠性,即使某个节点出现故障,数据依然可用。
-
高扩展性:由于数据被分散存储在多个节点上,分布式存储可以方便地扩展存储容量和性能,以满足不断增长的数据需求。
-
高性能:通过将数据并行存储和访问,分布式存储可以实现高并发和低延迟的数据访问,提供快速的存储和检索能力。
分布式存储的应用场景
分布式存储广泛应用于以下场景:
-
大数据分析:分布式存储可以存储和处理大规模的结构化和非结构化数据,支持大数据分析和机器学习等应用。
-
云存储:云服务提供商使用分布式存储来存储用户的数据,并提供可靠的数据存储和备份服务。
-
分布式文件系统:分布式存储可以用于构建分布式文件系统,实现高性能和可扩展的文件存储和访问。
分布式存储的设计考虑因素
在设计分布式存储系统时,需要考虑以下因素:
-
数据切分和负载均衡:将数据切分成适当大小的块,并将块分散存储在不同的节点上,以实现负载均衡和提高性能。
-
数据一致性和容错性:保证多个节点上的数据一致性,并通过冗余备份来提高容错性和数据可用性。
-
数据访问和路由:设计有效的数据访问和路由机制,以实现快速的数据读写操作。
-
安全性:保护数据的安全性和隐私,采用合适的安全机制和加密技术。
Ambry 设计
设计特点
高可用性和水平可扩展性
Ambry 是一个高可用并且最终一致的系统。在大多数情况下,写入会写入本地数据中心,然后异步复制到其他数据中心。这确保在网络分区下,写入本地数据中心仍然可用。此外,当一台机器在本地不可用时,Ambry会选择同一数据中心内另一台机器上的另一个副本来读取或写入数据。对于读取,当数据不存在于本地数据中心时,它会将请求代理到具有blob的数据中心。
低运营开销
Ambry 的一个关键设计目标是使集群的操作变得非常容易。该系统是完全去中心化的,并配备了管理集群所需的所有工具。此外,大部分操作将在软件内自动进行,以确保维护集群所需的手动工作量非常少
低MTTR(平均修复时间)
这对于分布式系统来说非常重要。机器停机、磁盘故障、服务器崩溃和 GC 停止进程。所有这些故障在分布式系统中都是完全可以接受的故障。然而,关键是要在很短的时间内解决问题。在所有情况下,系统在维修期间都可以使用。 但是,保持较低的MTTR仍然很重要
双交叉DC
默认情况下,Ambry 支持主动主动设置。这意味着对象可以写入任何数据中心的同一分区,也可以从任何其他数据中心读取。这通常不是许多系统提供的通用功能。Ambry 通过复制以及在需要时将请求代理到远程数据中心来实现这一点。
适用于大型和小型媒体对象
大多数媒体流量由数万亿个小对象和数十亿个大对象组成。系统需要为这种混合工作负载正常运行。在Ambry中实现这一点的方式是将所有对象的写入合并到一个顺序日志中。这确保所有写入都是批处理并异步刷新,并且磁盘上的碎片非常少。
成本效益
最后,任何对象存储都需要长期存储媒体和数据类型。 随着时间的推移,较旧的数据会变冷并且读取QPS非常低。此外,对象通常很大并且占用大量空间。 设计应该能够启用JBOD,支持硬盘并将空间放大保持在最低限度。
技术架构
分区
Ambry 的核心抽象是blob块,一种用于存储数据的不可变结构。每个blob都分配给磁盘上的一个分区并通过blob ID进行引用。系统的用户通过执行put, get 和delete操作
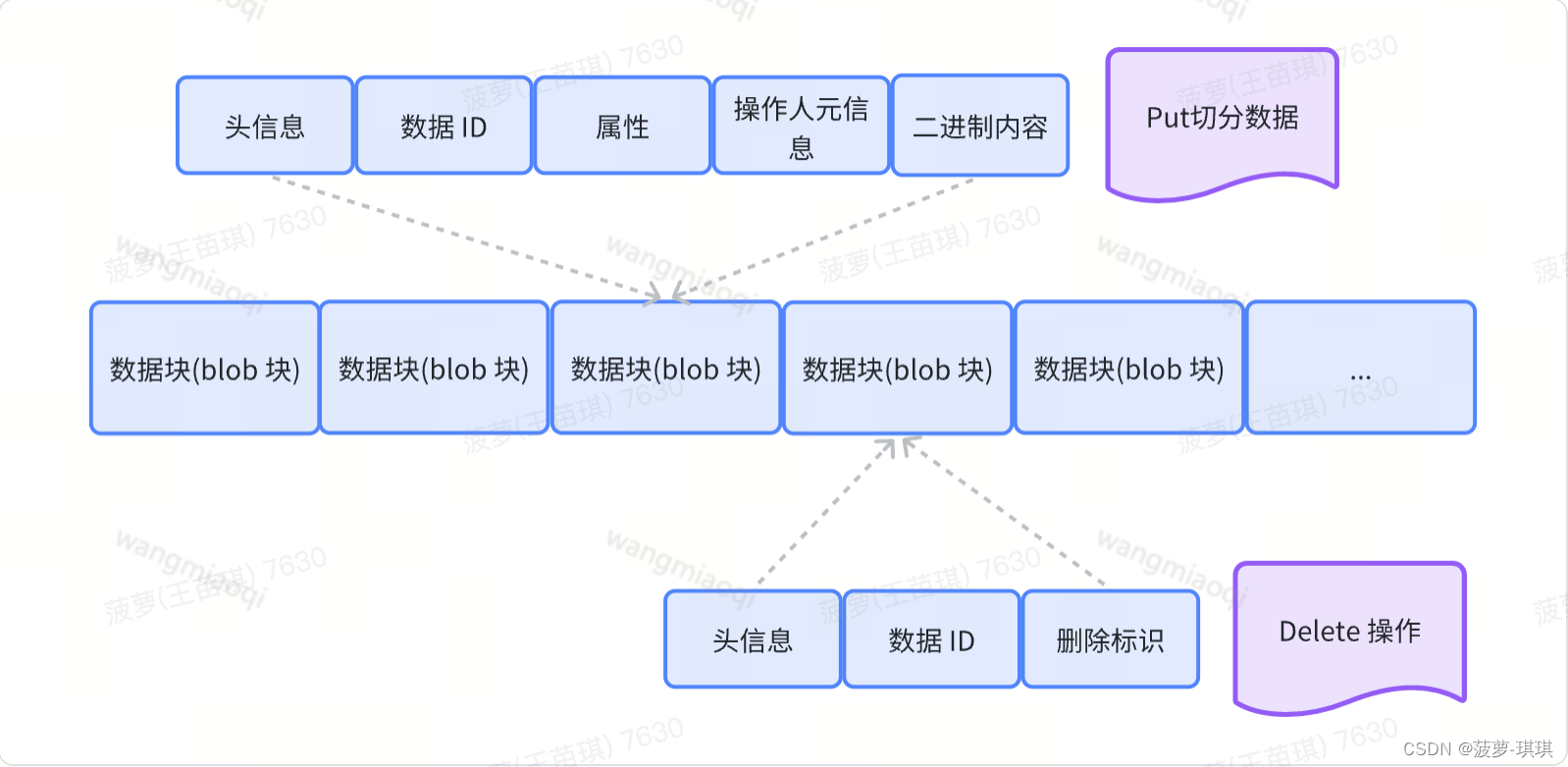
数据分区设计可以自由扩展——当用户向系统添加更多数据时,它可以添加更多分区。默认情况下,新分区是可读写的 (意味着它同时接受 put, get,和 delete流量)。当分区接近容量时,它会转换为只读,这意味着它不再支持通过以下方式存储新的blob put操作。系统的流量往往以更新的内容为目标,从而给读写分区带来更高的负载
为了提供对blob 的可扩展读写访问,Ambry使用了三个高级组件:集群管理器(Cluster Managers)、前端层(Frontend Layer)和 数据节点(Datanodes)。

集群管理器
集群管理器决定如何跨地理分布式数据中心将数据存储在系统中,以及存储集群的状态,状态主要存储在Zookeeper中。例如,它们存储Ambry部署的逻辑布局,包括分区可读写还是只读,以及分区在数据中心磁盘上的位置
Clustermap 由两部分组成:
-
硬件布局:包含了机器的列表、每台机器上的磁盘以及每个磁盘的容量。布局还维护资源的状态(机器和磁盘)并指定主机名和端口,通过主机名和端口就能连接到数据节点;
-
分区布局:包含了分区的列表、它们的位置信息以及状态。在 Ambry 中,分区有一个数字表示的 ID,副本的列表可以跨数据中心。分区是固定大小的资源,集群间的数据重平衡都是在分区级别进行的。
硬件管理
| Node | Disks | Size | State |
| DC1:NODE1 | Disk_0 Disk_1 Disk_2 ... | 1TB 1TB 1TB ... | Up Down Up ... |
| DC1:NODE2 | Disk_0 Disk_1 Disk_2 ... | 1TB 1TB 1TB ... | Up Down Up ... |
| ... | ... | ... | ... |
| ... | ... | ... | ... |
分区管理
| PartitionId | State | Replica |
| Partition_0 | Read write | DC1:NODE1:DISK_0 DC1:NODE3:DISK_1 |
| Partition_1 | Read write | ... |
| Partition_2 | Read | ... |
| ... | ... | ... |
数据节点和前端服务器都能够访问 clustermap,并且会始终使用它们当前的视图来做出决策,这些决策涉及到选择可用的机器、过滤副本以及识别对象的位置等。
处理流程
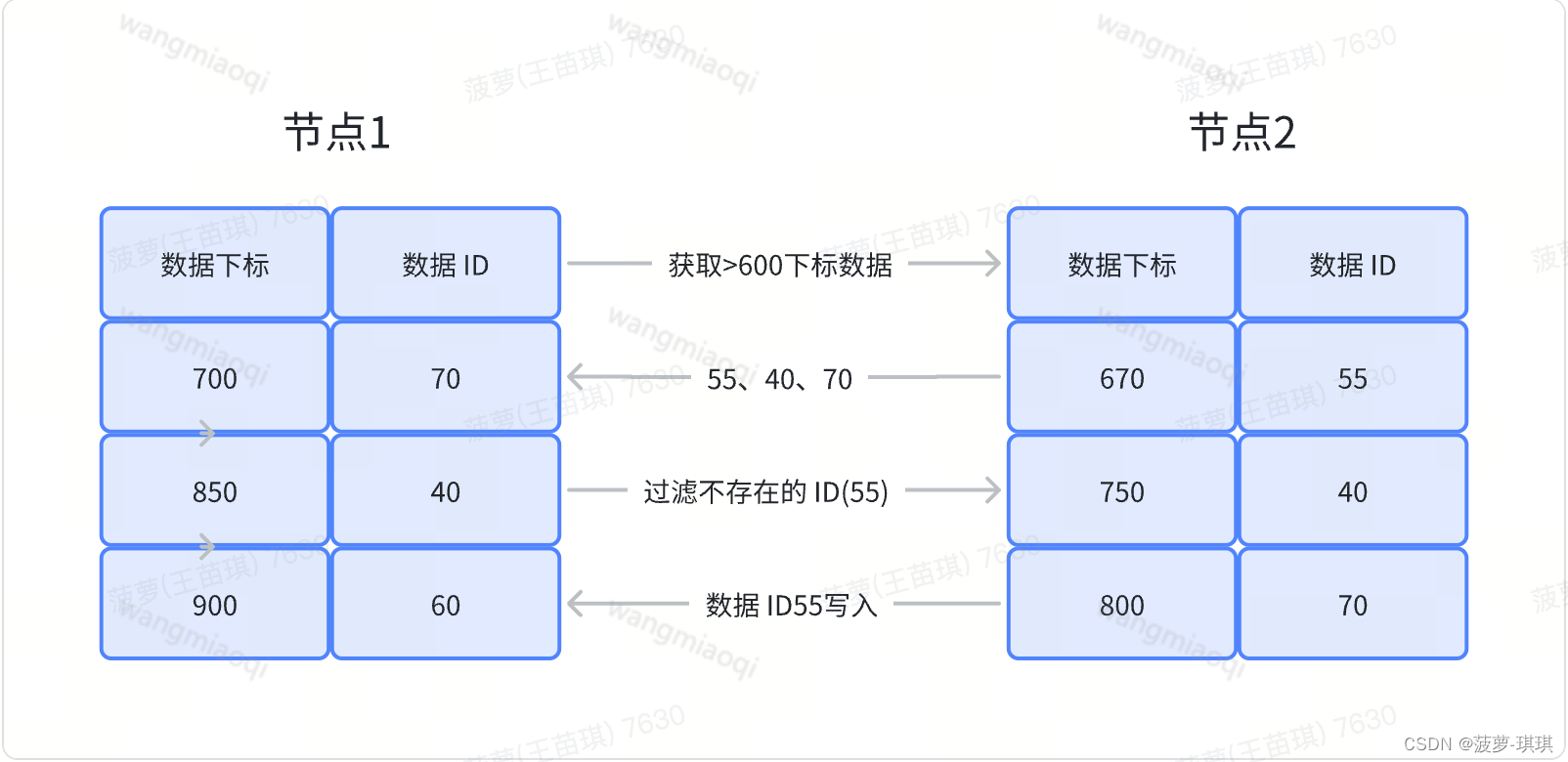
在put操作中,分区是随机选择的(出于数据平衡的目的),在get/delete 操作中,分区是从blob id 中提取的

为了put操作,Ambry可以配置为同步复制(确保 blob 在返回之前出现在多个数据节点上),或异步复制-同步复制可防止数据丢失,但会在写入路径上引入更高的延迟。
如果在异步配置中设置,分区交换日志的副本存储blob及其在存储中的偏移量。 核对这些日志之后,彼此之间再同步传递blob。
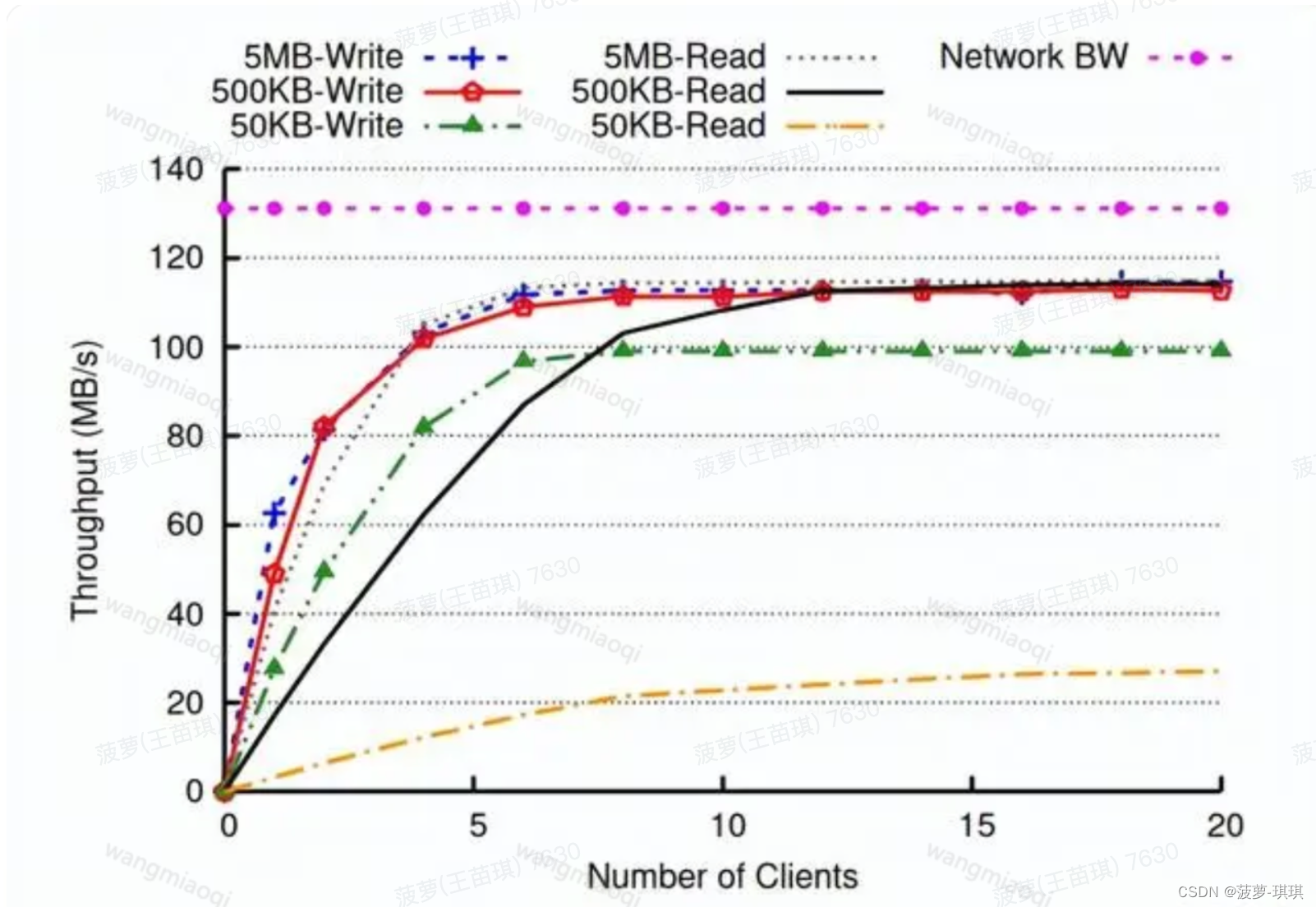
性能评测
根据评测报告本文评估了两个主要领域:吞吐量和延迟 ,以及地理分布式操作。
为了测试系统的吞吐量和延迟(对于大规模面向用户的低成本服务至关重要),不同大小对象的读写流量发送到Ambry。该系统能够为较大对象的读/写提供接近等效的性能,但在许多小的读/写操作中达到较低的性能限制
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机毕业设计 基于Java的供应商管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
- MD5:介绍与应用
- 三,TCP和UDP通信模型
- Flutter:跨平台移动应用开发的未来
- 【C/C++ 泛型编程 进阶篇 Type traits 】C++类型特征探究:编译时类型判断的艺术
- css 边框渐变
- AI代码助手的优点
- Array Equalizer(莫比乌斯反演)
- WPF入门到跪下 第十一章 Prism(一)数据处理
- vue 指定区域可拖拽的限定拖拽区域的div(如仅弹窗标题可拖拽的弹窗)