多模态模型论文最全总结
发布时间:2024年01月24日

?专栏介绍: 本作者推出全新系列《深入浅出多模态》专栏,具体章节如导图所示(导图后续更新),将分别从各个多模态模型的概念、经典模型、创新点、论文综述、发展方向、数据集等各种角度展开详细介绍,欢迎大家关注。
💙作者主页: GoAI |💚 公众号: GoAI的学习小屋 | 💛交流群: 704932595 |💜个人简介 : 掘金签约作者、百度飞桨PPDE、领航团团长、开源特训营导师、CSDN、阿里云社区人工智能领域博客专家、新星计划计算机视觉方向导师等,专注大数据与AI 知识分享。
💻文章目录
👨?💻导读: 本文为《深入浅出多模态》系列第一章,《多模态模型论文最全总结》将从整体介绍多模态模型发展,结合综述对各个模型按照发展时间线及发展对应关系进行介绍,后续将对其中经典及最新多模态模型进行解决,从具体论文、数据集、代码、模型结构、结果等角度分析,本专栏适合从事多模态小白及爱好者学习,欢迎大家关注,如有侵权请联系删除!
多模态模型最全总结
1.多模态模型综述总结
1.VLP:A Survey on Vision-Language Pre-training
2.A Survey of Vision-Language Pre-Trained Models
3.A SURVEY OF RESOURCE-EFFICIENT LLM AND MULTIMODAL FOUNDATION MODELS
4.微软研究院CVPR2023多模态大模型总结
PPT:多模态大模型
2.多模态相关github总结:
-
salesforce:https://github.com/salesforce/LAVIS
3.多模态论文综述:
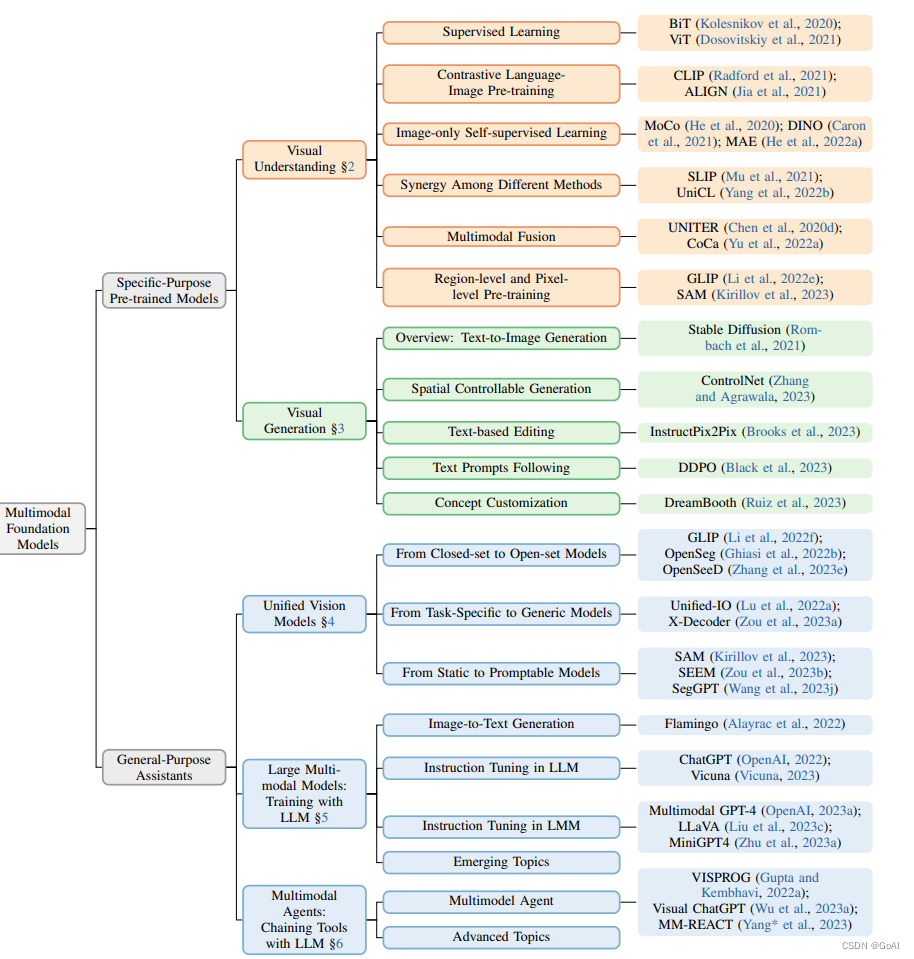
4.开源多模态大模型总览
| 开源模型 | 单位 | 包含模型 | 参数量 | |
|---|---|---|---|---|
| KOSMOS-2 | 微软 | 1.6B | ||
| OpenFlamingo | 微软 | MPT | 9B | |
| BLIP-2 | Salesforce | OPT.FlanT5 | 12B | |
| InstructBLIP | Salesforce | LLaMA | 7B,13B | |
| MiniGPT-4 | KAUST | LLaMA | 7B | |
| LLaMA-Adapter V2 | 上海人工智能实验室 | LLaMA | 7B | |
| ImageBind | Meta | ViT.CLIP | ||
| ChatBridge | 中科院自动化所 | LLaMA | 7B | |
| VisualGLM-6B | 清华大学 | ChatGLM | 7.8B | |
| VisCPM | 清华大学 | CPM-Bee | 10B | |
| mPLUG-Owl | 阿里巴巴 | LLaMA | 7B | |
| mPLUG-Owl2 | 阿里巴巴 | |||
| Qwen-VL | 阿里巴巴 | Qwen | 9.6B | |
| CogVLM、CogAgent |
最新模型后续待更新!!!!
多模态模型时间线
以下是按时间排序的不完整的多模态系统列表!
- Microsoft COCO Captions: 数据收集和评估服务器 (Apr 2015)
- VQA: 视觉问题回答 (May 2015)
- VideoBERT: 视频和语言表示学习的联合模型 (Google, Apr 3, 2019)
- LXMERT: 从转换器学习跨模态编码器表示 (UNC Chapel Hill, Aug 20, 2019)
- [CLIP] 从自然语言监督中学习可转移的视觉模型 (OpenAI, 2021)?
- 通过文本生成统一视觉和语言任务 (UNC Chapel Hill, May 2021)
- BLIP: 启动语言图像预训练,用于统一的视觉语言理解和生成 (Salesforce, Jan 28, 2022)?
- Flamingo: 用于小样本学习的视觉语言模型 (DeepMind, April 29, 2022)?
- GIT: 一种生成性图像到文本的变换器,用于视觉和语言 (Microsoft, May 2, 2022)
- MultiInstruct: 通过指导调优提高多模态零射击学习 (Xu 等人,Dec 2022)
- BLIP-2: 通过冻结图像编码器和大型语言模型启动语言图像预训练 (Salesforce, Jan 30, 2023)?
- 跨模态微调:先对齐再优化 (Shen 等人,Feb 11, 2023)
- KOSMOS-1: 语言不是你所需要的一切:与语言模型对齐的感知 (Microsoft, Feb 27, 2023)?
- PaLM-E: 一个具体的多模态语言模型 (Google, Mar 10, 2023)
- LLaMA-Adapter: 使用零初始化注意力的语言模型的高效微调 (Zhang 等人,Mar 28, 2023)
- mPLUG-Owl: 模块化赋予大型语言模型多模态性能 (Ye 等人,Apr 2, 2023)
- LLaMA-Adapter V2: 参数高效的视觉指令模型 (Gao 等人,Apr 28, 2023)?
- LLaVA: 视觉指令调优 (Liu 等人,Apr 28, 2023)
- InstructBLIP: 通过指导调优朝着通用的视觉语言模型迈进 (Salesforce, May 11, 2023)?
- 朝着专家级医疗问题回答的大型语言模型 (Singhal 等人,May 16, 2023)
- 便宜且快速:大型语言模型的高效视觉语言指令调优 (Luo 等人,May 24, 2023)
- Shikra: 释放多模态 LLM 的参考对话魔法 (SenseTime, Jun 3, 2023)
- Macaw-LLM: 带有图像、音频、视频和文本集成的多模态语言建模 (Tencent, Jun 15, 2023)
多模态发展关系图:
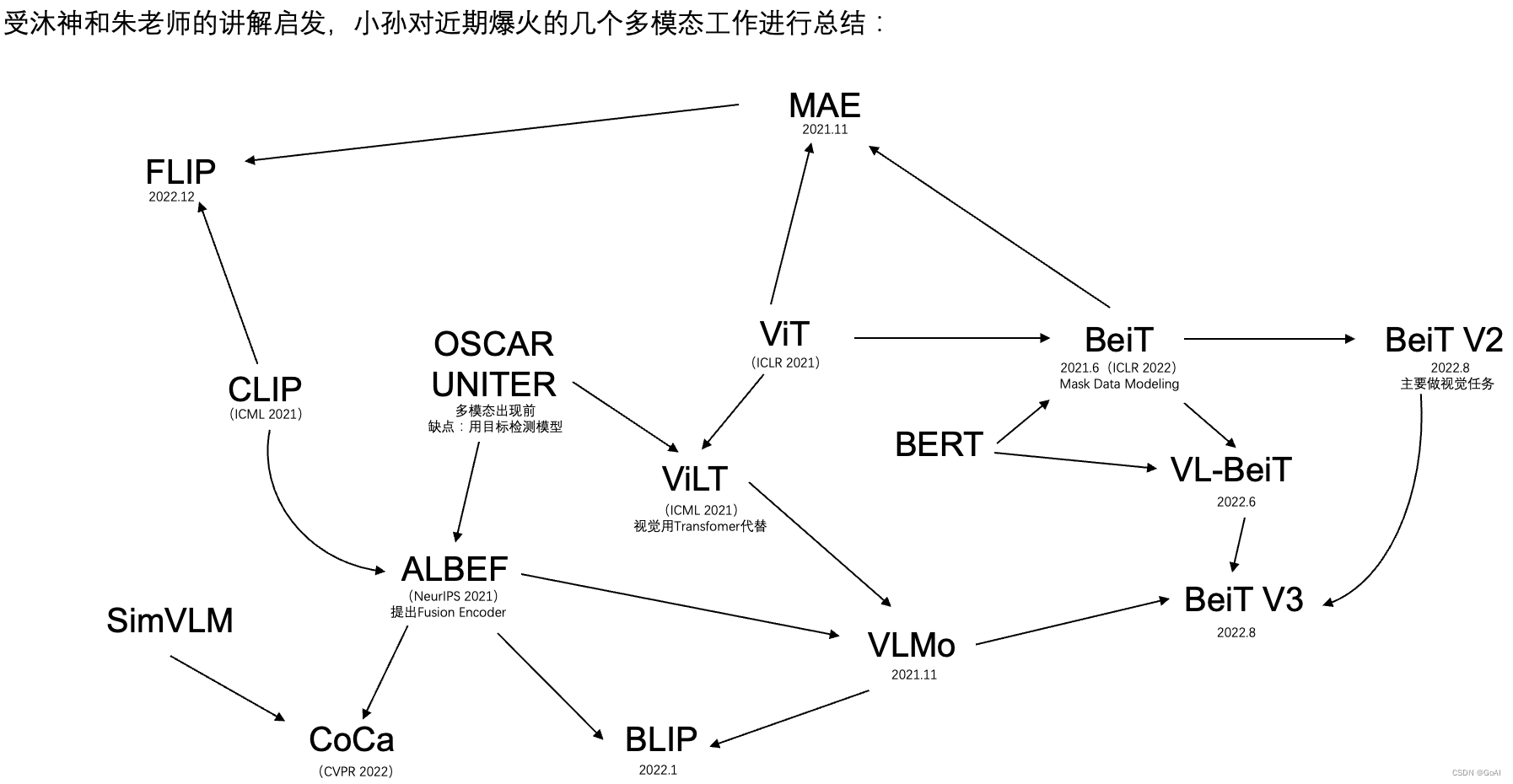
- ViLT:多模态学习之前都是Oscar或者Uniter的这些工作,但他们的缺陷是因为用了Object Detection的模型做视觉特征抽取,所以速度太慢,在Vision Transformer之后,Vilt的作者用一个Vision Transformer去代替vision特征提取,只用一个Embedding层大大简化了模型结构,所以结合VIT和Oscar推出了ViLT。
- ALBEF:ALBEF的作者发现Clip比较高效,适合做图像文本检索,原始的方法因为Modality Fusion做得很好,所以多模态任务非常强,ViLT结构比较简单,所以最后综合各算法长处推出了ALBEF这样一个Fusion Encoder的模式.
- CoCa:SimVLM用Encoder Decoder去做多模态,在ALBEF的基础上推出了CoCa,用一个Contrast和Captioning两个Loss训练出非常强大的模型。
- VLMO:微软根据ALBEF和Vilt,提出VLMO,用共享参数的方式做一个统一的多模态的框架
- BLIP:ALBEF的作者基于参数共享的思想,基于可以用很多Text Branch,提出Blip的模型,能做非常好的Captioning功能,而且它的Caption Filter模型非常好用,能够像一个普适工具一样用到各种各样的情形中。
- BEIT:ViT也用Mask Data Modeling的方式做Self-Supplied Learning,但是效果不是很好,而微软团队认为Mask Data Modeling是非常有前景的方向,所以顺着Bert的思想提出BEIT,号称计算机视觉界的Bert Moment,很快又推出BEITv2,但这个主要做视觉任务,不是多模态。
- Vision Language BEIT:BEIT可以在视觉上做Mask Modeling,Bert可以在文本上做Mask Modeling,因此作者将视觉和文本合在一起,推出VL-BEIT
- BEITv3:该团队将VLMO, VLBEIT和BEITv2三个工作合起来,推出多模态的BEITv3,大幅超过了CoCa, Blip在单模态和多模态上的各种表现。
- MAE:Mask Auto Encoder,主要是Mask and Predict Pixel(BEIT是Mask and Predict Patch),其实Vision Transformer都已经做,但是效果都不是很好,BEIT和MAE都把效果推到一个非常高的高度
- Flip:Fast Language Image Prediction,MAE有一个非常好的一个特性,就是在视觉端把大量的Patch全都Mask掉之后,只把没有Mask过的Patch送入Vision Transformer学习,大大减少了计算量,Flip把MAE的这个有用的特性用到Clip的结构里,模型就是Clip没有任何的改变,只不过在视觉端跟MAE一样,只用没有Mask的Token,这样就把Sequence Length降低了很多,训练就快了。
文章来源:https://blog.csdn.net/qq_36816848/article/details/135794758
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【漏洞复现】广州图创图书馆集群管理系统认证绕过漏洞
- jackson相关注解
- 钉钉考勤统计工时的方法
- 【管理篇 / 登录】? 07. FortiOS 7.4 初始登录提示 ? FortiGate 防火墙
- SuperPoint和SuperGlue 的算法介绍及学习应用经验分享
- 如何预防[[MyFile@waifu.club]].wis [[backup@waifu.club]].wis勒索病毒感染您的计算机?
- VScode安装C/C++编译器步骤
- Uniapp 开发 BLE
- APP启动流程
- 为什么大家开始用poe了?