MySQL核心SQL
一.结构化查询语言
SQL是结构化查询语言(Structure Query Language),它是关系型数据库的通用语言。
- DDL(Data Definition Languages)语句
数据定义语言,这些语句定义了不同的数据库、表、列、索引等数据库对象的定义。常用的语句关键字主要包括 create、drop、alter等。 - DML(Data Manipulation Language)语句
数据操纵语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性,常用的语句关键字,主要包括 insert、delete、update 和select 等。 - DCL(Data Control Language)语句
数据控制语句,用于控制不同的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户 的访问权限和安全级别。主要的语句关键字包括 grant、revoke 等。
二.库操作
show databases;
create database db01;
drop database db01;
use?db01;
三.表操作?
show tables;
create table user(
id int primary key auto_increment comment '主键',
nickname varchar(20) not null comment '昵称',
age int unsigned not null default 18 comment '年龄',
sex enum('男','女') default '男' comment '性别'
)engine=innodb default charset=utf8;
desc user
show create table user;或者show create table user\G
drop table user;
四.CRUD操作
1.insert增加
INSERT INTO USER(nickname,age,sex) VALUES('张三',19,'男'),('李四',20,'女');
INSERT INTO USER(nickname,age,sex) VALUES('王五',26,'男');
这两条语句的区别:一条SQL语句执行一次三次握手和四次挥手
多条语句执行多次

2.update修改
UPDATE USER SET age=age+1;
UPDATE USER SET age=age+1 where id=1;
3.delete删除
delete from user where id=1;
delete from user;
delete from user where age between 1 and 2;
4.select查询
1.简单select查询
select * from user;
select id,nickname,age,sex from user;
select id,nickname,age,sex from user where sex='男';
2.去重distinct
select distinct age from user;
3.空值查询
select * from user where nickname is null;
4.union合并查询
select * from user where age>=20 union all select * from user where sex='男';
select * from user where age>=20 union select * from user where sex='男';
5.带in子查询
select * from user where age in(20,21);
6.分页查询
select * from user limit 3;
select * from user limit 1,3;
select * from user limit 3 offset 1;
select * from user where age>=20 limit 2 offset 1;
我们都知道有索引字段的情况下查询的条数都是一条,但是没有使用会发生什么情况,使用limit会不会提高查询的效率呢??
可以使用explain查询select查询的条数
EXPLAIN SELECT * FROM USER WHERE age>=20 LIMIT 1;?
 ?可以看到还是要进行全表扫描的,但是实际执行过程中扫描到第一条符合条件的数据的时候就停止扫描了,在实际的环境中(对于大量的数据),使用limit查询的速度比不适用快很多
?可以看到还是要进行全表扫描的,但是实际执行过程中扫描到第一条符合条件的数据的时候就停止扫描了,在实际的环境中(对于大量的数据),使用limit查询的速度比不适用快很多
?向t_user表中插入2000000条数据的执行
delimiter $
Create Procedure add_t_user (IN n INT)
BEGIN
DECLARE i INT;
SET i=0;
WHILE i<n DO
INSERT INTO t_user VALUES(NULL,CONCAT(i+1,'@fixbug.com'),i+1);
SET i=i+1;
END WHILE;
END$
delimiter ;
call add_t_user(2000000);此时我们可以进行观察,速度明显是快很多的,自己可以尝试
因此当我们知道某个数据是唯一(或者需要查询执行数量的数据)时,并且字段没有建立索引,此时我们使用limit可以明显提高查询的效率.
实际生产项目中分页查询pagenum,pageno
select * from user limit (pageno-1)*pagenum,pagenum;
这种可以进行查询,但是效率很低,因为他首先需要从0->offset条数据,再将之后的数据取出来,0->offset条数据的时间
优化后的sql语句(id为主键,具体表的主键为准),因为主键建立了索引,我们只需要花常量的时间就可以定位到需要查询的位置
select * from user where id>(上一页最后一条数据的id) limit pagenum;
7.排序order by
select * from user order by age;(默认升序ASC)
select * from user order by age DESC;
select * from user order by age,nickname;
EXPLAIN SELECT * FROM USER ORDER BY nickname;?
使用的是外排序
 ?EXPLAIN SELECT id,nickname FROM USER ORDER BY nickname;
?EXPLAIN SELECT id,nickname FROM USER ORDER BY nickname;
使用的是索引
 是否使用的是索引与排序的字段是否添加索引和查询的字段是否有索引有关?
是否使用的是索引与排序的字段是否添加索引和查询的字段是否有索引有关?
8.分组group by
select age,count(age) as num from user group by age;
select age from user group by age having age>20;
select age,sex from user group by age,sex;
explain select age from user group by age;

查询出来的数据其实是经过排序的,因此会出现filesort,因此group by之后的字段加索引是十分必要的
9.笔试实践题
|
字段名
| 描述 |
| serno | 流水号 |
| date | 交易日期 |
| accno | 账号 |
| name | 姓名 |
| amount | 金额 |
| brno | 缴费网点 |
select count( serno),sum( amount) from? bank_bill;
select? ?brno,date,sum(amount) as sum_account?from?bank_bill group by?brno,date order by?sum_account?DESC;
5.连接查询?
连接查询主要分为以下的几个:
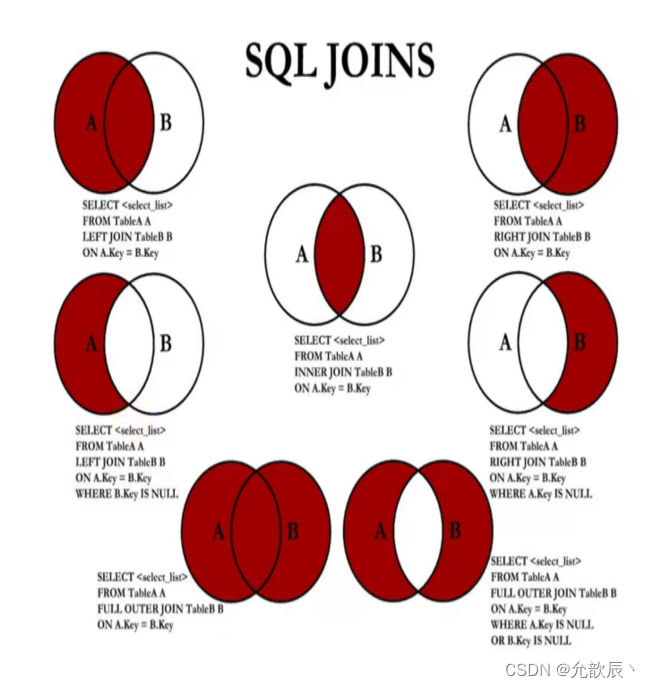
先来创建三个表
create table student(
uid int primary key auto_increment,
name varchar(20) not null,
age int not null,
sex enum('男','女') default '男' not null
);create table course(
cid int primary key auto_increment,
cname varchar(20) not null,
credit int not null
);create table exame(
uid int not null,
cid int not null,
time date not null,
score float not null,
primary key(uid,cid)
);
插入一些数据:
insert into student(name,age,sex)?
values('zhangsan',18,'男'),('gaoyang',20,'女'),('chenwei',22,'男') ,('linfeng',21,'女'),('liuxiang',19,'女');
insert into course(cname, credit)
values('c++基础课程',5),('c++高级课程',10),('c++项目开发',8),('c++算法课程',12);
insert into exame(uid,cid,time,score)?
values(1,2,'2021-04-10',80.0),(2,2,'2021-04-10',90.0),
(2,3,'2021-04-12',85.0),(3,1,'2021-04-09',56.0) ,
(3,2,'2021-04-10',93.0),(3,3,'2021-04-12',89.0),(3,4,'2021-04-11',100.0),
(4,4,'2021-04-11',99.0),(5,2,'2021-04-10',59.0),
(5,3,'2021-04-12',94.0),(5,4,'2021-04-11',95.0);?
1.内连接查询
select t1.uid,t1.name,t1.age,t1.sex,t2.`score` from student t1 join exame t2 on t1.`uid`=t2.`uid`;

重点:on a.uid=c.uid区分大表和小表,按照数据量来区分,小表永远是整表扫描,然后去大表搜索从student小表中取出所有的a.uid,然后拿着这些uid去exame大表中搜索
对于inner join内连接,过滤条件写在where的后面和on连接条件里面,效果是一样的
select t1.uid,t1.name,t1.age,t1.sex,t2.`score`,t3.`cid`,t3.`cname`,t3.`credit` from student t1 join exame t2 on t1.`uid`=t2.`uid`
join course t3 on t3.`cid`=t2.`cid`;
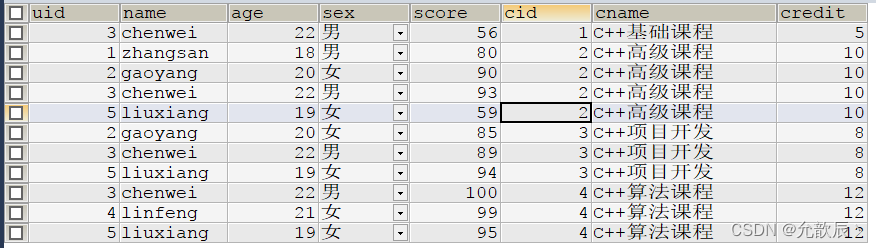
?
select b.cid,b.cname,b.credit,count(*) cnt
from exame c
inner join course b on c.cid=b.cid
where c.score>=90.0
group by c.cid
order by cnt;

?内连接应用场景,前面t_user表可以通过id直接定位分页查询的位置,是因为加了索引,如果我们直接查询id,因为id加了索引,也可以减少查询的时间,但是我们需要的是查询全部的信息,怎么通过内连接可以减少查询的时间呢?
select id from t_user limit 100000,10
下面给出解决方案
select a.id,a.email,a.password from t_user a join (select id from t_user limit 100000,10) b
on a.id=b.id;
通过产生的id临时表,可以直接定位到查询的位置,也是因为id加了索引.?
2.外连接查询
学生表中插入一条新的数据
insert into student(name,age,sex) values('weiwei',32,'男');
1.左连接查询
select a.*,b.* from student a left join exame b on a.`uid`=b.`uid`;
 把left这边的表所有的数据显示出来,在右表中不存在相应数据,则显示NULL
把left这边的表所有的数据显示出来,在右表中不存在相应数据,则显示NULL
使用explain查看可知是先查左表

2.右连接查询
select a.*,b.* from student a right join exame b on a.`uid`=b.`uid`;

select a.*,b.* from student a left join exame b on a.`uid`=b.`uid` where b.`cid`=2;select a.*,b.* from student a join exame b on a.`uid`=b.`uid` where b.`cid`=2;
此时上面的两条sql语句一个是内连接一个是外连接,两者按理来说应该是不一样的,但是实际显示的结果都是一致的

?使用explain查看

可以看到都是先全表查询右表,然后再查询左表,这样与我们预期中的左连接查询结果是不一样的了,此时我们应该?
select a.*,b.* from student a left join exame b on a.`uid`=b.`uid` and b.`cid`=2;
我们把查询的条件写在on的后面,此时查询的结果是我们想的左连接查询所预期的

使用explain查看也可以看到是先查询左表的.?

外连接的连接条件不能像内连接一样写在on和where都行,如果想要产生符合预期的答案,应该要写在on后面?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!