C++标准库中string的底层实现方式
前言
? ? ? ? string是C++标准库中常见的容器,不管是在校生日常练习换是职场老鸟写项目,它都是会经常使用的一个容器,你是否经常使用它呢?你是否了解过它的底层实现呢,如果你对此感兴趣,不妨与我共同探索一下它的底层原理。
1.string对象的大小
????????
#include<iostream>
#include<string>
using std::string;
using std::cout;
using std::endl;
int main(int argc, char **argv)
{
string s1;
string s2("asdfghjklbz");
string s3("asdfghjklzxcvbnmqwertyuio134455546787980");
cout << "sizeof(s1) : " << sizeof(s1) << endl;
cout << "sizeof(s2) : " << sizeof(s2) << endl;
cout << "sizeof(s3) : " << sizeof(s3) << endl;
cout << "sizeof(string) : " << sizeof(string) << endl;
while (1);
return 0;
}在vs2013下的结果:
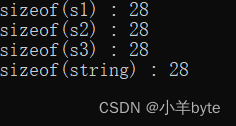
在gcc下的结果
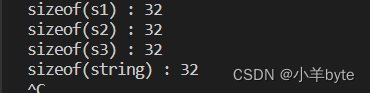
????????为什么在不同的编译器下会存在不同的结果呢,这就要和这些编译器所采用的string的实现方式有关系了。我们接着往下看...
2.string的底层实现方式
? ? ? ? 2.1Eager Copy
????????也就是所谓的深拷贝,无论是在什么情况下,都是采取复制字符串内容的方式来进行对象的拷贝和复制。这种实现方式,对于需要对字符串需要频繁复制而又不改变字符串的内容时效率就比较低了。所以要对其采用一定的策略进行优化,之后便出现了下面这种COW的实现方式。string深拷贝的实现
? ? ? ? 2.2COW(Copy-On-Write)
? ? ? ? cow也就是所谓写时复制机制。当对字符串进行拷贝和赋值时并不会进行深拷贝,而是通过增加引用计数的值,字符串只会进行浅拷贝,当对字符串中的内容进行修改时,此时才会执行真正的复制,也就是进行深拷贝。
? ? ? ? 其实现的内存图有下面两种方式:
? ? ? ? 第一种方式:
?
????????std::string的成员就是
class string
{
private:
Allocator _allocator;//空间配置器,用来管理空间,暂时不用管
size_t Capacity;
size_t Size;
char* Point;
};?????????第二种方式:

? ? ? ? std::string的成员包括:
?
class string
{
private:
char * Point;
};????????为了实现的简单,GNU4.8.4中就采用了第二种实现方式,我们可以看到第二种实现方式并没有将引用计数直接放到string的内部而是放在了字符串内容的前面,这么做有什么好处呢?
????????最显而易见的好处就是可以减少string创建对象的大小,并且对于引用计数是否可以放在栈空间上呢?放在全局/静态区是否可行呢?
????????我们来一起思考一下,如果放在栈上是否能够达到写时复制的效果,首先复制的字符串和被复制的字符串中的引用计数的变化应该是同步的(要增加都增加,要减少都减少)。
????????但是如果将引用技术放在栈空间中,那么复制的字符串和被复制的字符串的引用计数就无法同步变化,所以肯定不可以放在栈空间中,如果放在静态区中也是同样的道理(如果这里转不过弯来,可以好好思考一下,实在理解不了就接着往下看,看到最后你就会明白的)。
????????好了我们说完了理论,下面用代码进行一下简单的实现。?
? ? ? ? //代码
#include<iostream>
#include<string.h>
using std::cout;
using std::endl;
namespace qyy
{
class string
{
public:
friend std:: ostream &operator<< (std::ostream & os, const qyy::string & rhs);
string()//+1的字节是用来保存'\0'用来和C语言兼容,+ 4是用来保存引用计数的
:_point(new char[1 + 4] () + 4)//用来保存引用计数
{
initRefCount();
}
string(const char* point)
: _point(new char[strlen(point) + 1 + 4]() + 4)
{
initRefCount();
strcpy(_point, point);//拷贝数据到新的空间中
}
string(const string & rhs)
: _point(rhs._point)
{
//引用计数加1
incrementRefCount();
}
string & operator= (string& rhs)
{
if(this != &rhs)
{
//减少原来的引用计数
subRefCount();
if(getRefCount() == 0)
{
//如果此时引用计数等于0就需要将动态申请的空间进行释放
clear();
}
_point = rhs._point;
//增加新的引用计数
incrementRefCount();
}
return *this;
}
//对于operator[]的访问
char& operator[](size_t index)
{
if(index < size())
{
//这里要思考如何区分读操作和写操作
return _point[index];
}
else
{
static char nullchar = '\0';
return nullchar;
}
}
//初始化引用计数
void initRefCount()
{
*(int*)(_point - 4) = 1;
}
//引用计数自增
void incrementRefCount()
{
++*(int*)(_point - 4);
}
//获取引用计数
int getRefCount() const
{
return *(int*)(_point - 4);
}
//引用计数自减
void subRefCount()
{
--*(int*)(_point - 4);
}
size_t size() const
{
if(_point)
{
return strlen(_point);
}
else//如果string为空此时求出来的size就是一个极大值
{
return -1;
}
}
void clear()
{
if(_point)//清理空间
{
delete [](_point - 4);
_point = nullptr;
}
}
~string()
{
subRefCount();
if(getRefCount() == 0)
{
clear();
}
}
private:
char * _point;
};
std:: ostream &operator<< (std::ostream & os, const qyy::string & rhs)
{
if(rhs._point)
{
os << rhs._point;
}
return os;
}
}
? ? ? ?如何区分读操作和写操作来达到写时复制呢?如果是string s1 = "hello";cout << s[1] ; 这只是一次读操作,s1[1] = 'r';这才是一次写操作,直接在operator[]中好像是无法区分的,下面是错误的演示。
?
//对于operator[]的访问
char& operator[](size_t index)
{
if(index < size())
{
//这里要思考如何区分读和写操作
//申请新空间
char* tmp = new char[size() + 5]();
//拷贝数据
strncpy(tmp + 4, _point , size());
//减少原来的引用计数
subRefCount();
clear();//清理旧的空间
_point = tmp;
//初始化引用计数
initRefCount();
return _point[index];
}
else
{
static char nullchar = '\0';
return nullchar;
}
}? ? ? ? 这里提供一种思路:既然在operator[]中无法识别读和写操作,那么就在operator[]的返回值上来进行操作,将operator[]的返回值改为一个自定义类型,通过这个自定义类型来区分读写操作。?
#include<iostream>
#include<string.h>
using std::cout;
using std::endl;
namespace qyy
{
class string
{
public:
friend std:: ostream &operator<< (std::ostream & os, const qyy::string & rhs);
string()//+1的字节是用来保存'\0'用来和C语言兼容,+ 4是用来保存引用计数的
:_point(new char[1 + 4] () + 4)//用来保存引用计数
{
initRefCount();
}
string(const char* point)
: _point(new char[strlen(point) + 1 + 4]() + 4)
{
initRefCount();
strcpy(_point, point);//拷贝数据到新的空间中
}
string(const string & rhs)
: _point(rhs._point)
{
//引用计数加1
incrementRefCount();
}
string & operator= (string& rhs)
{
if(this != &rhs)
{
//减少原来的引用计数
subRefCount();
if(getRefCount() == 0)
{
//如果此时引用计数等于0就需要将动态申请的空间进行释放
clear();
}
_point = rhs._point;
//增加新的引用计数
incrementRefCount();
}
return *this;
}
//对于operator[]的访问
class CharProxy
{
public:
CharProxy(string & self, size_t index)
: _self(self)
, _index(index)
{}
char& operator=(const char &ch);//进行写时复制操作
operator char()
{
cout << "operator char() " << endl;
return _self._point[_index];
}
//operator<<(char)
string & _self;
size_t _index;
};
CharProxy operator[](size_t index)
{
return CharProxy(*this, index);
}
const char*c_str() const
{
return _point;
}
//初始化引用计数
void initRefCount()
{
*(int*)(_point - 4) = 1;
}
//引用计数自增
void incrementRefCount()
{
++*(int*)(_point - 4);
}
//获取引用计数
int getRefCount() const
{
return *(int*)(_point - 4);
}
//引用计数自减
void subRefCount()
{
--*(int*)(_point - 4);
}
size_t size() const
{
if(_point)
{
return strlen(_point);
}
else//如果string为空此时求出来的size就是一个极大值
{
return -1;
}
}
void clear()
{
if(getRefCount() ==0 && _point)//清理空间
{
delete [](_point - 4);
_point = nullptr;
}
}
~string()
{
subRefCount();
clear();
}
private:
char * _point;
};
std:: ostream &operator<< (std::ostream & os, const qyy::string & rhs)
{
if(rhs._point)
{
os << rhs._point;
}
return os;
}
char &string::CharProxy::operator=(const char & ch)
{
if(_index < _self.size())
{
char * tmp = new char[_self.size() + 5]() + 4;
strcpy(tmp, _self._point);
_self.subRefCount();
_self._point = tmp;
_self.initRefCount();
return _self._point[_index];
}
else
{
static char charnull = '\0';
return charnull;
}
}
}? ? ? ? 将这个自定义类型CharProxy的operator=和 std::ostream & operator<< (std::ostream & os, const string ::CharProxy & rhs)进行实现就能区分出来读,写操作了。?需要注意的是std::ostream & operator<< (std::ostream & os, const string ::CharProxy & rhs);这个函数需要在string类和CharProxy类中都进行友元的声明,不然会报错。在CharProxy的operator=函数中进行深拷贝。
? ? ? ? ?这种实现方式可能有一定的难度对于友元函数的声明,接下来我介绍一种较为简单的实现方式。
? ? ?实现CharProxy类中的类型转换函数:operator char();
operator char()
{
cout << "operator char() " << endl;
return _self._point[_index];
}这样也可以达到读写分离的要求。
//测试代码
int main(int argc, char **argv)
{
qyy::string s1;
qyy::string s2("asdfghjklbz");
qyy::string s3("asdfghjklzxcvbnmqwertyuio134455546787980");
cout << "sizeof(s1) : " << sizeof(s1) << endl;
cout << "sizeof(s2) : " << sizeof(s2) << endl;
cout << "sizeof(s3) : " << sizeof(s3) << endl;
cout << "sizeof(string) : " << sizeof(qyy::string) << endl;
cout << "s1 : " << s1 << endl;
cout << "s2 : " << s2 << endl;
cout << "s3 : " << s3 << endl;
cout << "s1.RefCount() : " << s1.getRefCount() << endl;
cout << "s2.RefCount() : " << s2.getRefCount() << endl;
cout << "s3.RefCount() : " << s3.getRefCount() << endl;
qyy::string s4 = s2;
cout << "s2.RefCount() : " << s2.getRefCount() << endl;
cout << "s4.RefCount() : " << s4.getRefCount() << endl;
//这里并未对s[4]的值进行修改,只是通过Operator[]函数来访问s4中的字符,
//但是s4的引用计数和s[2]的引用计数确改变了
cout << "s4[1]" << s4[1] << endl;
cout << "s4[2]" << s4[2] << endl;
cout << "s4[3]" << s4[3] << endl;
cout << "s1.RefCount() : " << s1.getRefCount() << endl;
cout << "s2.RefCount() : " << s2.getRefCount() << endl;
cout << "s3.RefCount() : " << s3.getRefCount() << endl;
cout << "s4.RefCount() : " << s4.getRefCount() << endl;
s4[1] = 'i';
s4[2] = 'l';
cout << endl;
cout << "s1.RefCount() : " << s1.getRefCount() << endl;
cout << "s2.RefCount() : " << s2.getRefCount() << endl;
cout << "s3.RefCount() : " << s3.getRefCount() << endl;
cout << "s4.RefCount() : " << s4.getRefCount() << endl;
return 0;
}? ? ? ? 2.3SSO
? ? ? ? 也就是所谓的短字符串优化,一般来说,一个程序中用到的字符串大部分都是比较短的,而在64位机器上面,一个指针的就占了8个字节的空间,所以SSO就出现了,其核心思想就是发生拷贝时要复制一个指针,对于短的字符串来说如果直接复制整个字符串不是更快吗,说不一定还没有复制一个指针的代价大,对于长字符串来说就要老老实实的进行深拷贝了。如图:?
? ? ? ? 所以std::string的成员就是:?
class string
{
private:
union buf
{
char * _point;
char _local[16];
};
size_t _size;
size_t _capacity;
};? ? ? ? 当字符串的长度小于16个字节的时候,buf直接存放整个字符串;当字符串的长度大于16个字节的时候buf区域存放的就是一个指针,这个指针指向一个堆空间,堆空间中存放字符串的内容。这样做的好处就是当字符串较小的时候就不需要获取堆空间,开销小。?
3.最佳策略
? ? ? ? 以上三种方式,都不能解决所有可能遇到的字符串的情况,它们各有所长,又各有缺陷。所以只有将它们三者的优势结合在一起,才是最优的解决方案。
? ? ? ? 1.很短的字符串(0~22)用SSO,23字节表示字符串(包括'\0'),1个字节表示长度。
? ? ? ? 2.中等长度的字符串(23~255),字符串用eager copy,8字节字符串指针,8字节size,8字节的capacity。
? ? ? ? 3.很大长度的字符串(大于255)字符串用COW,8字节指针(字符串和引用计数),8字节size,8字节capacity。
? ? ? ? 这样可以使得每个string对象占据的空间都是24个字节。某些开源库中就是这样实现的。?
4.线程安全性
? ? ? ? 两个线程同时对同一个字符串进行操作的话,是不可能线程安全的,出于对性能的考虑,C++并没有为string实现线程安全,毕竟不是所有的程序都会使用到多线程。
? ? ? ? 但是两个线程同时对两个独立的string操作时,必须是线程安全的,COW计数实现这一点是通过原子对引用计数进行+1或者-1操作。
? ? ? ? CPU的原子操作虽然比mutex锁好多了,但是任然会带来性能的损失。原因如下:
- ? ? ? ? 阻止了CPU的乱性执行
- ? ? ? ? 两个CPU对同一个地址进行原子操作,都导致cache失效,从而需要重新从内存中加载缓存。
- ? ? ? ?系统通常会lock住比目标地址更大的一片区域,影响逻辑上不相关的地址访问?
所以这些也是COW的劣势。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- (每日持续更新)jdk api之FilePermission基础、应用、实战
- SPI 接口简介
- 微信公众号小说系统源码,漫画系统源码,可对接微信公众号 APP打包对接,附带系统图文搭建教程,自带采集规则
- 深入理解JVM虚拟机--3.3垃圾收集算法
- 【Seata源码学习 】 扫描@GlobalTransaction注解 篇一
- 嵌入式面试提问
- 高并发场景下底层账务优化方案
- Permission denied (publickey,gssapi-keyex,gssapi-with-mic).
- 垂直领域大模型算法团队招聘AIGC算法工程师(社招/实习)
- windows任意APP注册成服务(以nginx服务为例)