体验新时代的CNI--cilium
1.什么是cilium
Cilium 是一个开源项目,旨在为 Kubernetes 集群和其他容器编排平台等云原生环境提供网络、安全性和可观测性。
Cilium 的基础是一种新的 Linux 内核技术,称为 eBPF,它支持将强大的安全性、可见性和网络控制逻辑动态插入到 Linux 内核中。eBPF 用于提供高性能网络、多集群和多云能力、高级负载均衡、透明加密、广泛的网络安全功能、透明的可观测性等等。
截至2024/1/12,它在github上的star已经有17.5k,远远超过了calico和flannel,如果使用私有化的K8S部署,是一个值得去学习和落地使用的项目。
它的功能列表如下
本文主要对其作为CNI的角色和可观测性进行描述
1.1 安装(使用kubeasz)
笔者安装的是使用kubeasz安装K8S集群时一起安装的,对应到具体的脚本是使用的helm+operator方式。
版本没有很新,github的kubeasz支持的cilium最新版本到1.14,cilium官网已经是1.16,目前主要是体验cilium CNI
如需替代kube-proxy,L2 LB等还需要根据cilium官方文档确定支持的版本并修改hlem value。
1.1.1 安装自定义参数
config.yml配置文件 选项全部改为true,
cilium_ver: "1.13.2" cilium_connectivity_check: true cilium_hubble_enabled: true cilium_hubble_ui_enabled: true
hosts 修改集群网络插件,默认是calico CLUSTER_NETWORK="cilium"
1.1.2 安装后修改,开启hubble relay metrics
它在ansible脚本中是使用helm安装的,我们后续可以找到它的helm charts压缩包和value值进行修改
在我的测试环境的位置
helm charts位置
/etc/kubeasz/roles/cilium/cilium-1.13.2.tgz values位置
/etc/kubeasz/clusters/k8s-01/yml/cilium-values.yam
默认选项中cilium agent有对应的metrics端点 hubble relay的需要打开
具体可以参考helm charts里解压的默认值
参考的改value的片段
hubble: enabled: true metrics: ? enabled: ? - dns:query;ignoreAAAA ? - drop ? - tcp ? - flow ? - icmp ? - http ? enableOpenMetrics: true ? port: 9965 ? serviceMonitor: ? ? enabled: true ? ? interval: "30s"
使用helm upgrade更新cilium和hubble relay
helm upgrade -n kube-system cilium -f cilium-values.yaml /etc/kubeasz/roles/cilium/files/cilium-1.13.2.tgz
如出故障考虑回滚版本
helm rollback cilium 1 --namespace kube-system
说是hubble的metrics,但实际上还是在clilium agent上做的端点暴露,打开servicemonitor在Prometheus operator及需要的crd存在时可以直接被发现
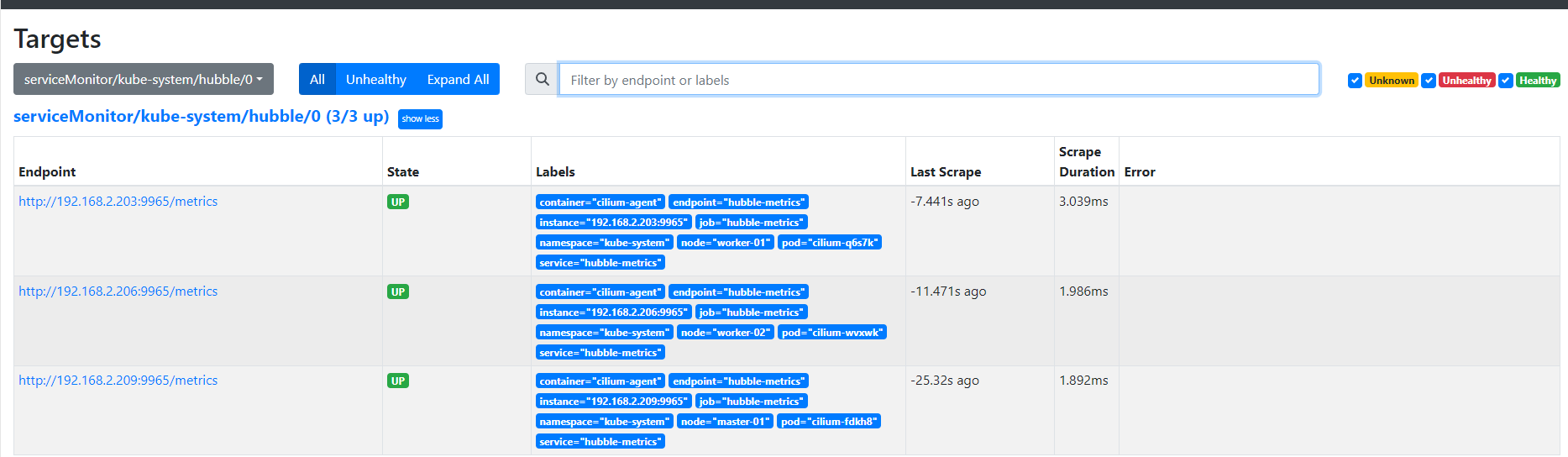
cilium agent本身会默认打开metrics端点,但pod本身未声明这个具名端口,podmonitor不可用,我这里选择手动添加cilium agent的service的的端口映射把未声明的端口暴露给servicemonitor的sd发现
1.1.3 cilium agent metrics发现和适配
定义服务,选择器为cilium agent的唯一标签
apiVersion: v1 kind: Service metadata: name: cilium-agent-metrics labels: ? app.kubernetes.io/name: cilium-agent namespace: kube-system spec: selector: ? app.kubernetes.io/name: cilium-agent ports: ? - name: metrics ? ? port: 9962 ? ? protocol: TCP ? ? targetPort: 9962 type: ClusterIP
定义servicemonitor,注意端口名和服务的具名端口和标签对应上即可自动发现
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: cilium-agent-service-monitor namespace: kube-system labels: ? app.kubernetes.io/name: cilium-agent spec: selector: ? matchLabels: ? ? app.kubernetes.io/name: cilium-agent endpoints: - port: metrics ? interval: 30s ? path: /metrics
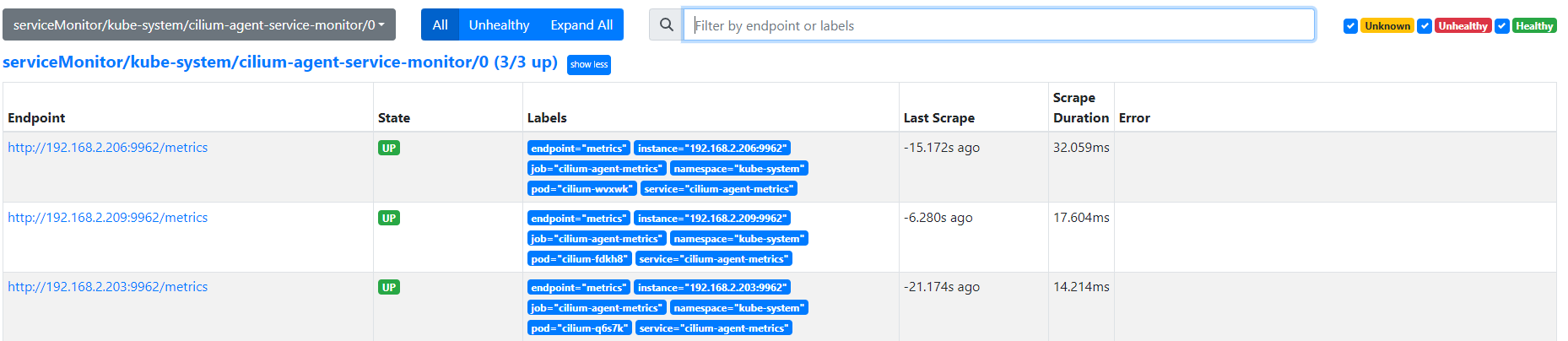
Prometheus确认已经采集到
2 metrics可观测性使用
在grafana添加cilium agent和hubble relay的grafana dashboard
在grafana的dashboard store找到对应的dashboard,但版本似乎已经没有继续更新,如果有空的part,需要拿grafana dashboard的promql和指标名到Prometheus查询是否有采集或是否已经改名。

cilium metrics
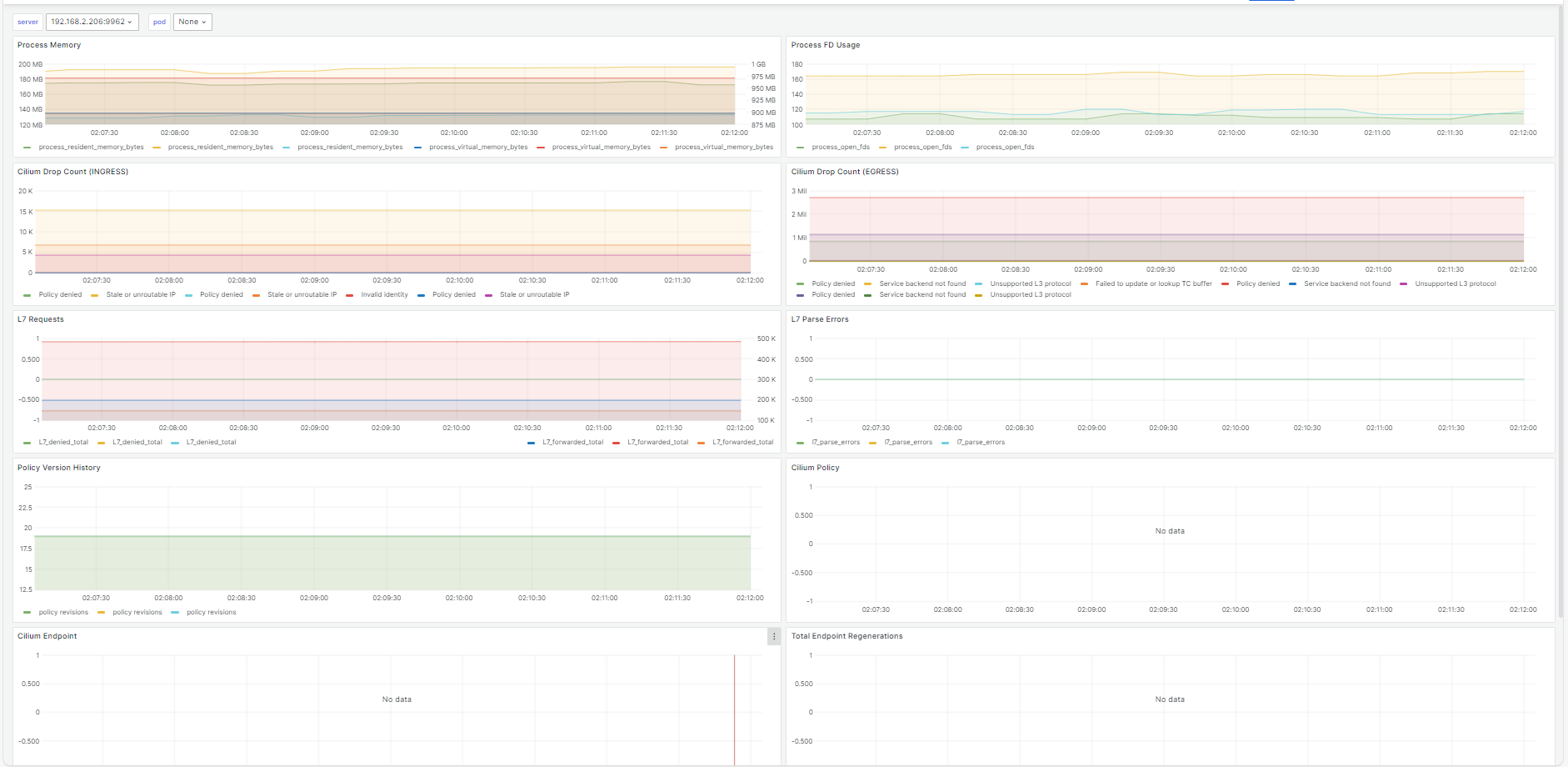
hubble relay metrics:
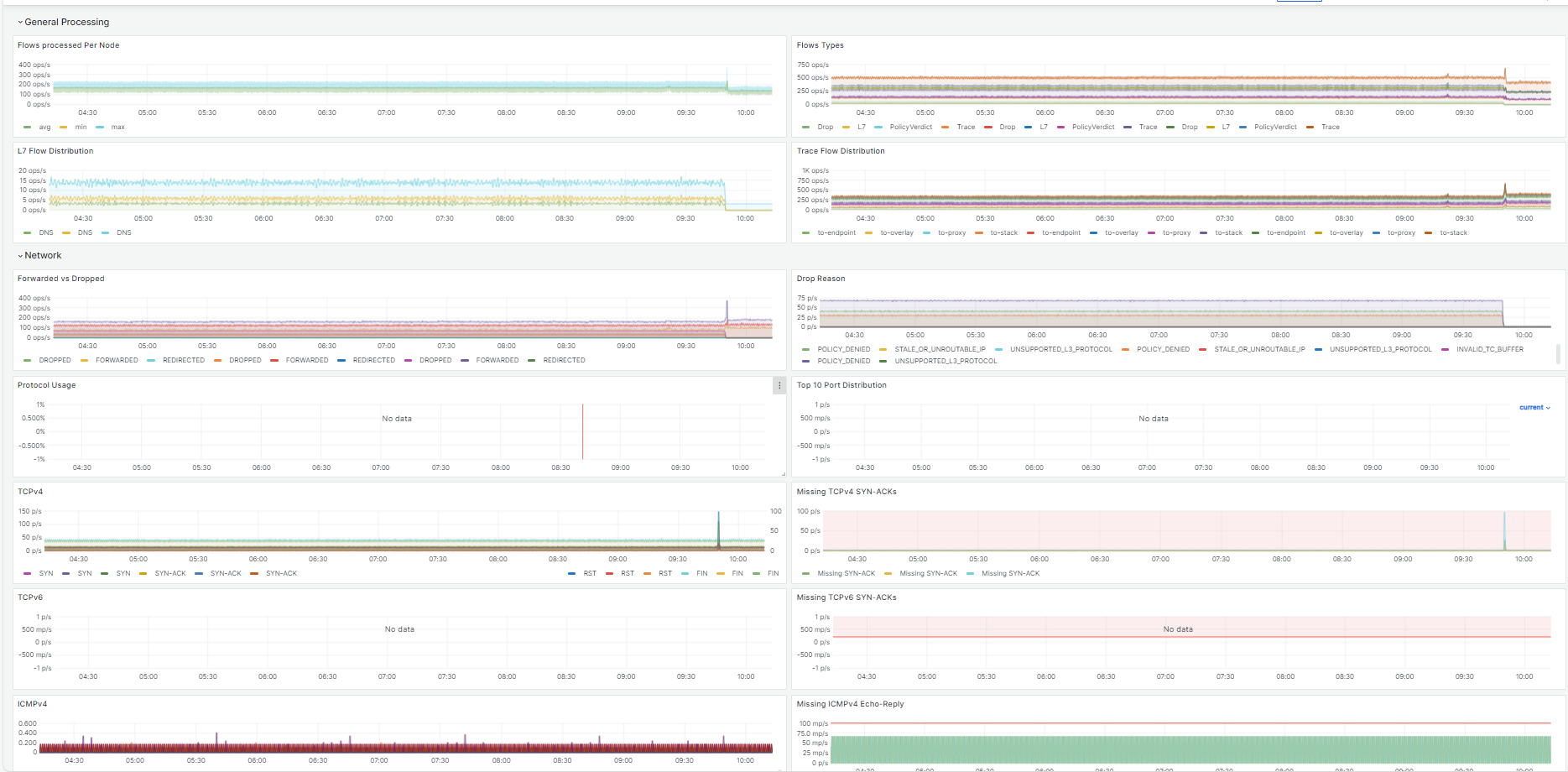
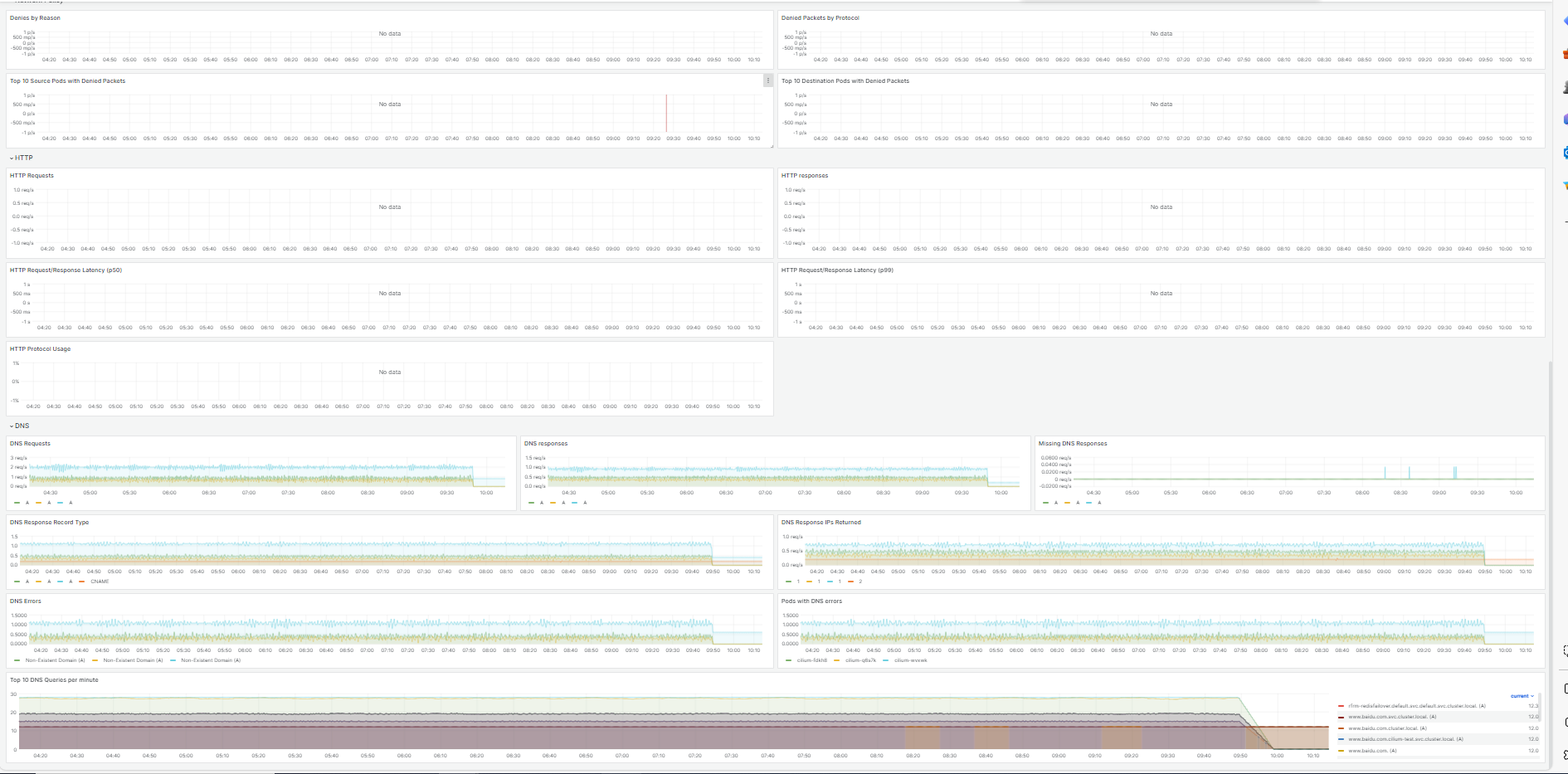
暂未开启ipv6和cilium网络策略,没有对应的指标
默认情况在cilium的dashboard中的7层流量相关指标并不能简单通过helm value的值简单开启
参见官方文档Layer 7 Protocol Visibility — Cilium 1.16.0-dev documentation
7层可见性
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "l7-visibility"
spec:
endpointSelector:
? matchLabels:
? ? "k8s:io.kubernetes.pod.namespace": default
egress:
?
- toPorts:
? - ports:
? ? - port: "53"
? ? ? protocol: ANY
? ? ? rules:
? ? ? dns:
? ? ? - matchPattern: "*"
- toEndpoints:
? - matchLabels:
? ? "k8s:io.kubernetes.pod.namespace": default
? ? toPorts:
? - ports:
? ? - port: "80"
? ? ? protocol: TCP
? ? - port: "8080"
? ? ? protocol: TCP
? ? ? rules:
? ? ? http: [{}]
如果存在需要进出K8S集群的端口流量,如oracle,ftp等需要额外定义egress,否则会被cilium的该策略限制,此处不做展开
而具体使用哪些指标和promQL做告警,还需要笔者深度的使用后再决定。
3 使用hubble ui
使用hubble ui 一个实时监控K8S集群流量的工具,可以视为一个在线tcpdump或wireshark
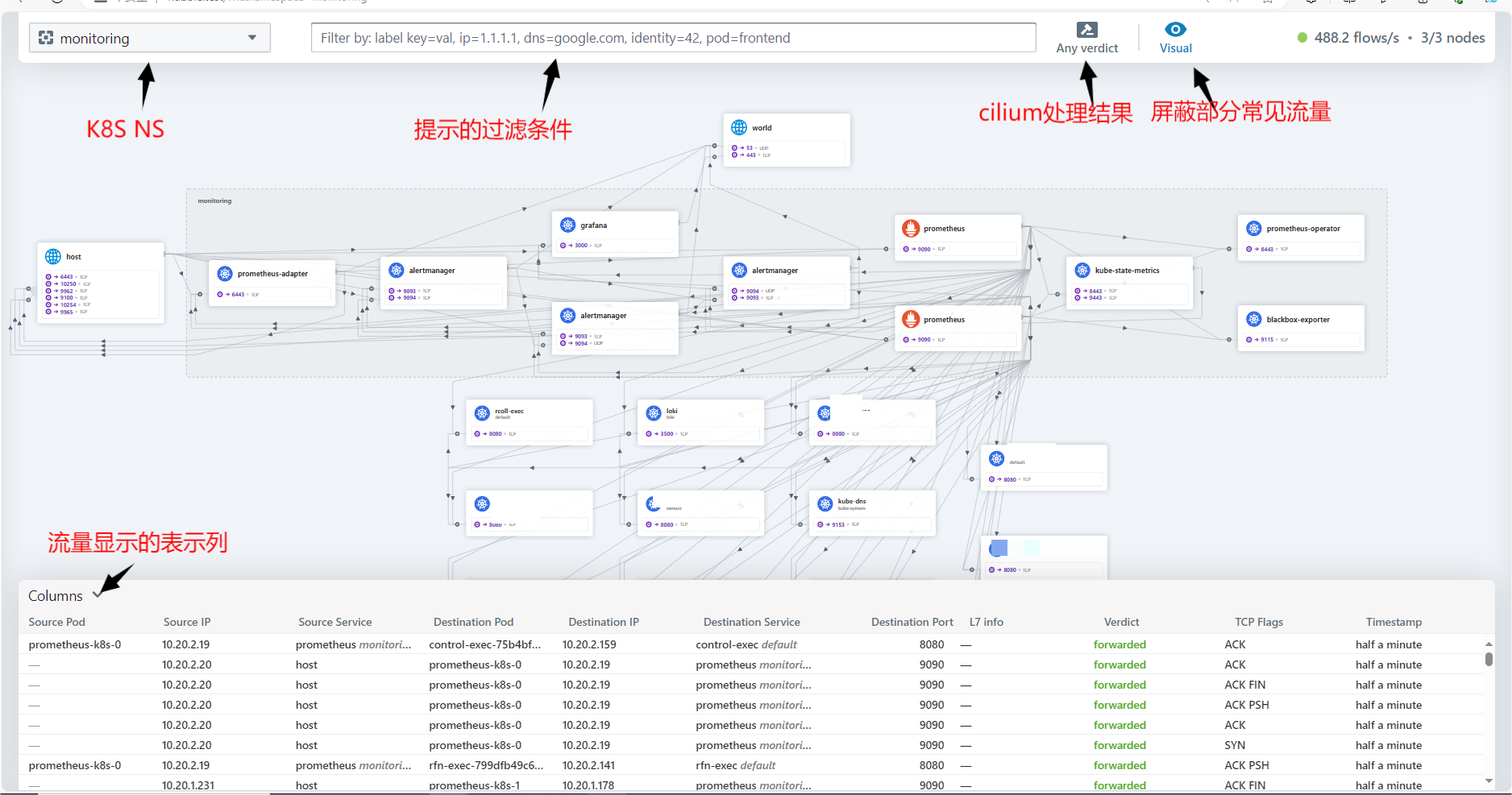
如需要cilium正确识别pod的名称,需要使用标准的推荐标签如app,否则可能可能被表示为uknown app。
点击对应的pod可以看到具体的网络流向
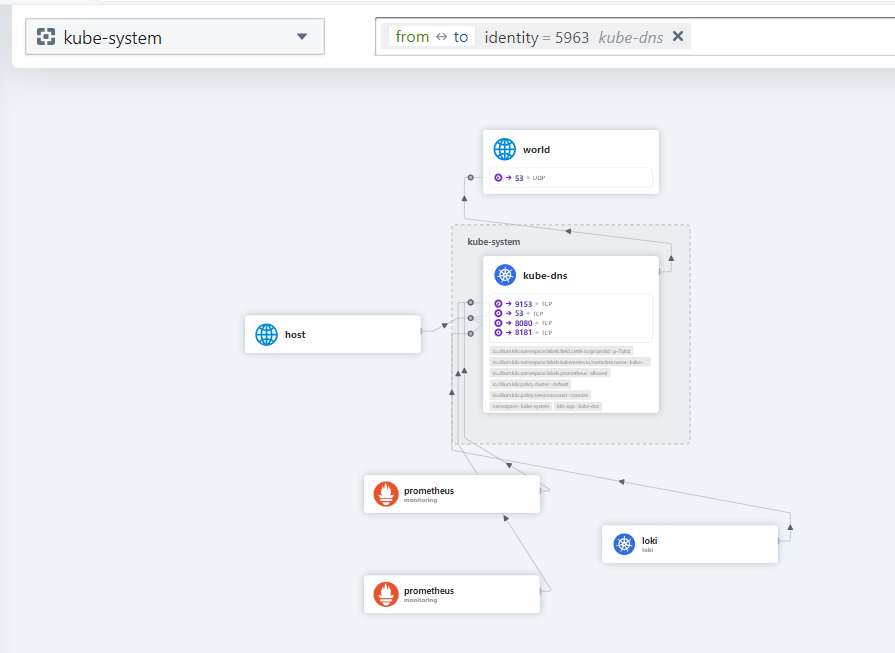
由于hubble UI显示的数据是实时的,我们可以针对一个ns打开hubble UI一段时间后,累积一定的监控数据后,选定一个指定的pod,观察其流量是否有合适的进入来判断pod的流量是否有异常。
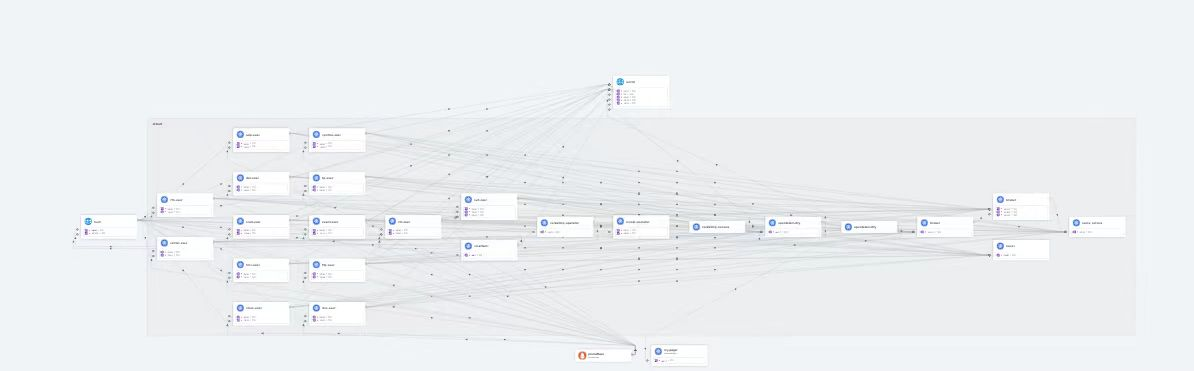
具体来说根据cilium实时hubble ui,包括前面提到的两个metrics到Prometheus的端点,加上部分异常指标的告警,相比于其他的CNI,我们可以获得很强的网络可见性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MySQL面试题 | 08.精选MySQL面试题
- 【EasyExcel实践】万能导出,一个接口导出多张表以及任意字段(可指定字段顺序)-简化升级版
- 【C++入门到精通】异常 | 异常的使用 | 自定义异常体系 [ C++入门 ]
- 本地jar安装到仓库
- 【推荐系统】推荐算法数学基础
- 黑马苍穹外卖学习Day6
- 交换机设备基本操作
- SpringIOC之ApplicationObjectSupport
- 管理Python虚拟环境的脚本
- Koa学习笔记