ceph之rados设计原理与实现第七章:在线数据恢复——Recovery和Backfill
由于每个写操作都需要产生和操作日志,所以处于效率考虑,必须定时对日志进行裁剪。
由于PG保存的日志条目有限,按照能否依靠日志进行数据恢复,存在两种数据恢复方式,分别为Recovery和Backfill。
Recovery指只需要修复副本(PG)上与权威日志不同步的那部分对象(即降级对象即可)。missing已经记录
Backfill指以PG全体对象为目标的数据迁移过程。例如所在OSD离线太久而期间产生大量客户端发起的读写请求,或者Ceph自身出于数据重平衡需要而执行Backfill。
1.Recovery
1.1 资源预留
为了防止集群中大量PG同时执行Recovery从而严重影响正常业务,需要对Recovery进行约束

为了实现上述约束,在PG正式开始执行Recovery任务之前,必须先由Primary主导,发起资源预留
所谓的资源预留:Primary(一个PG实例)必须先加入所属OSD的全局异步资源预留队列,如果OSD资源够,就会给队列头PG分配资源。
Primary得到OSD资源后,需要进一步通知所有参与本次Recovery的副本远程进行资源预留,所有副本都获得资源后,才能开始Recovery。
所有需要执行Recovery的PG也会进入op_shardedwq工作队列,与来自客户端的请求一同参与竞争。
1.2 对象修复
Pull:指Primary自身存在降级对象,由Primary按照missing_loc选择合适的副本去拉取降级对象的权威副本至本地,然后完成修复的方式
Push:指Primary感知到一个或者多个副本当前存在降级对象,主动推送每个降级对象的权威版本至副本,然后再由副本本地完成修复的方式。
无论是Pull还是Push进行修复,最终依据都是日志。
日志可以细分为以下几种类型:CLONE、DELETE、MODIFY、LOST_DELETE / LOST_REVERT
(1) 整对象拷贝
除了DELETE 、LOST_DELETE之外的操作,一律采用整对象拷贝的方式进行修复。
顾名思义,这种方式会完整从源端拷贝包括数据、扩展属性、omap在内的全部对象内容至目的端。
(2) 删除对象
对于DELETE 、LOST_DELETE操作,采用删除对象方式进行修复
虽然Recovery是在后台执行的,但是如果客户端正好访问某个降级对象,则还是需要先强制修复该对象,才能继续处理来自客户端的请求。
1.3 增量Recovery和异步Recovery
综上,当前Recovery有两大缺陷:一是修复手段单一并且粗糙(整对象拷贝),占用大量磁盘带宽和网络带宽;二是如果客户端访问降级对象,需要(完全)修复这些对象之后才能继续处理客户端请求,容易引起业务卡顿
相应的有两种方法改善,增量Recovery和异步Recovery
(1) 增量Recovery
重新设计日志系统,使之能够回溯历史操作的详细信息,这样后续可只修复降级对象与其权威版本之间差异部分。但是相应的代价是日志系统复杂会影响写性能,因为日志需要伴随写请求同步写入数据库。其次虽然修复量下降,但是修复难度会增加,一个极端的例子,例如针对一个对象反复执行不同的操作,后续想要基于为数众多的历史日志分析得出最佳修复方式绝非易事,反而不如整对象拷贝简单高效
(2) 异步Recovery
针对客户端写请求降级对象强制触发该降级对象执行数据恢复的策略改造,即只需要保证满足存储池最小副本数。这样数据可靠性仍然可以得到保证,而剩下的副本则可以采用类似Backfill的方式(但是仍然基于日志)异步在后台修复,不再阻塞来自客户端的写请求。
2 Backfill
Recovery后,才会执行Backfill,此时Primary(PG的一个实例)一定是权威版本。
同样,由Primary主导,先进行Backfill资源预留,资源预留成功后,PG开始正式执行Backfill。
Backfill最终效果是需要Backfill的副本获得Primary的一个完美的拷贝,但是PG的大小只受存储空间的限制,因此Backfill需要先扫描PG上所有对象,获得所有对象信息。
扫描的信息存储在backfill_info中

具体而言,如果Backfill任务初次被调度,Primary必须先通过ObjectStore扫描对象(遍历KV数据库存储的对象元数据)获得一个本次待执行Backfill对象的严格有序列表。然后再通知所有参与本次Backfill的副本也同步扫描,并将结果返回给自身汇总。
显然,每个副本收集到的对象信息,可能完全不一样。
具体而言,
相比Primary,副本上的对象信息的不一样可以分为四类:
1)缺少某些对象(Missing Object)
2)存在某些多余对象(Redundant Object)
3)对象存在,但与Primary版本号不一致,即对象已经过时了(Obsolete Object)
4)对象存在并且与Primary版本号一致(Normal Object)
对应的修复策略为:
1)拷贝对象
2)删除对象
3)修复对象
4)跳过对象
对于每个即将从头开始Backfill的副本,Primary会在Peering完成之后将其Info中的stat清零,此后,随着Backfill的推进,Primary会不断收集相关的统计信息并更新对应副本的stat。
1)拷贝或修复对象:等待拷贝或者修复完成后,再收集这些对象的统计信息并更新对应副本的stat
2)删除对象:不需要更新stat
3)跳过对象:由前面的分析,跳过的对象是正常对象,由于其相关统计已经被Primary擦除,因此仍需要重新计入副本的stat
Primary会通过一个名为last_backfill_started的指针来记录上次Backfill的实时进度。
达到最大并发Backfill对象数目限制之后,Primary将结束本次调度,由于Backfill业务优先级较低,后续有可能一直被其他业务特别是客户端业务抢占,这意味着Backfill两次调度的时间间隔基本不可预料。
为了防止两次调度之间,backfill_info当中残留的、等待Backfill的对象信息已经过时(例如在此期间客户端针对其中的某些对象又执行过写操作),当Backfill任务再次被调度时,必须由Primary确认是否需要重新扫描。
1)与上次扫描发生时Primary记录的最新日志版本号相比,当前最新日志版本号没有发生变化(例如系统处于空闲状态,无客户端访问),则无需重新扫描
2)上次扫描记录的最新日志版本号大于等于Primary当前保存的最老日志版本号,说明日志完整记录了两次扫描间所有写请求信息,此时可以直接通过遍历日志获得相关对象的最新版本信息
3)上次扫描记录的最新日志版本号比Primary当前保存的最老日志还要小,说明两次扫描间某些写请求信息已经缺失,需要Primary重新发起扫描。
举例:
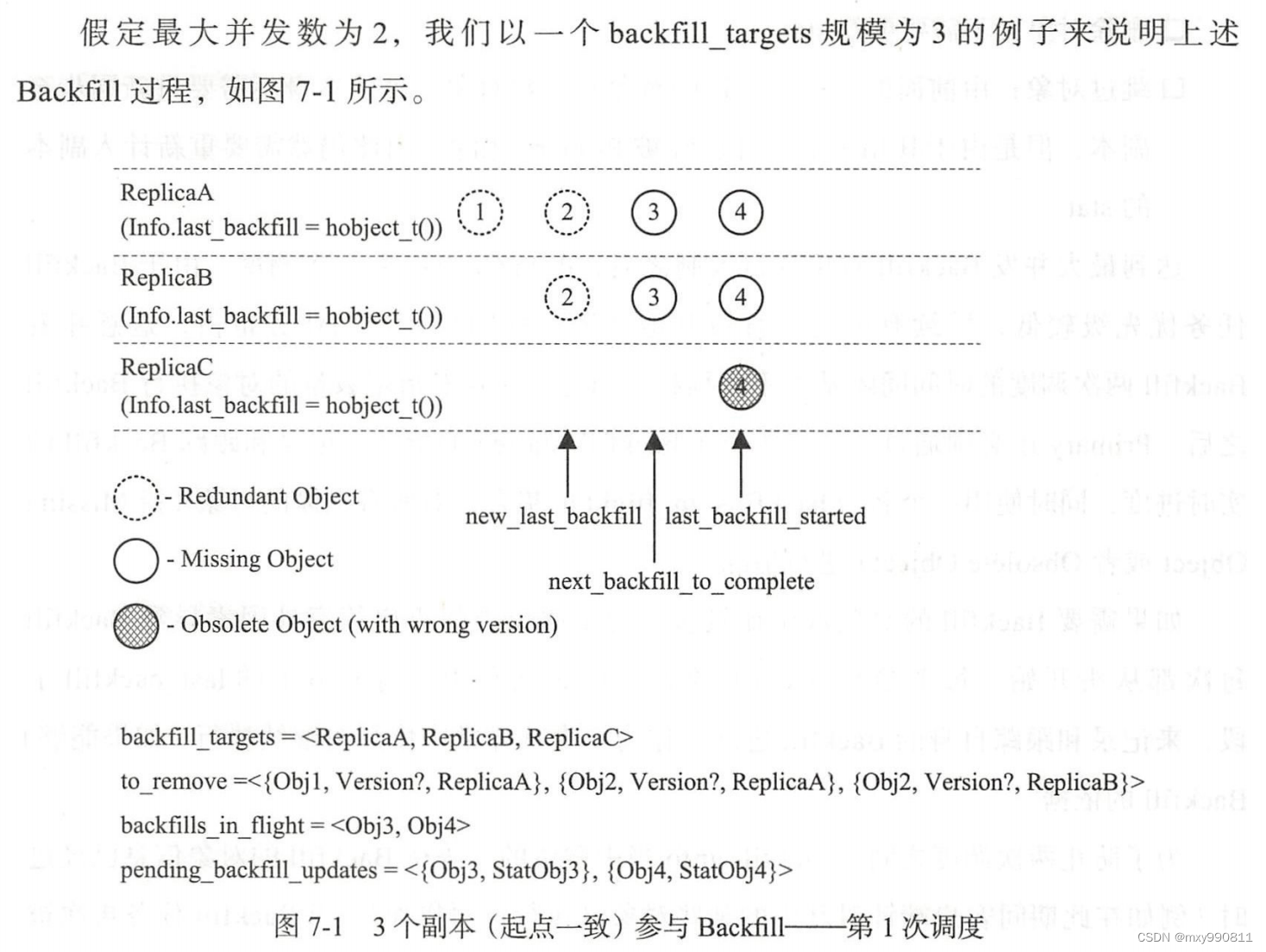
删除对象因为代价较小,第一次调度没有受到最大并发数限制,因此第一次调度Primary实际上一次性处理了4个对象
Obj1:通知ReplicaA删除
Obj2:通知ReplicaA和B删除
Obj3:通知ReplicaA和B修复
Obj4:通知ReplicaA、ReplicaB、ReplicaC修复

一些特殊情况如OSD正在Backfill,但是OSD下线在上电时间间隔不长,期间所有发生过的写请求,其对应的日志条目都可以从权威日志找到,那么可以正常完成Recovery后再从上次断点处(last_backfill_started)继续Backfill
Backfill完成后,Primary将向Monitor发送一个新的PG Temp变更请求(此请求携带的PG Temp为空),用于将Acting重新调整为Up。再次经过Peering后PG将最终进入Acting+Clean状态,此时可以删除不必要的副本,释放其占用的存储空间。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python常用的Xpath语法
- tomcat缺少awt支持的解决&java.lang.NoClassDefFoundError: Could not initialize class sun.awt.X11GraphicsEnvir
- 基于SSM的医学生在线学习交流平台
- 制作一个Python聊天机器人
- DevEco Studio 项目启动工程和Device Manage
- python通过代理(ssh tunnel)连接MongoDB
- Java Arrays.copyOfRange的用法
- QML基础类型之Size - 编程指南
- JavaScript高级程序设计读书记录(十三):期约与异步函数
- 五、Java核心数组篇