爬虫requests+综合练习
Day2 - 1.requests第一血_哔哩哔哩_bilibili
requests作用:模拟浏览器发请求
requests流程:指定url -> 发起请求 -> 获取响应数据 -> 持续化存储
爬取搜狗首页的页面数据
import requests
# 指定url
url = 'https://sogou.com'
# 发起请求
response = requests.get(url)
# 获取响应数据,text返回字符串形式的响应数据
page_txt = response.text
# 持久化存储
with open('./sogpu.html', 'w', encoding='utf-8') as fp:
fp.write(page_txt)简易网页采集器
输入关键词后,爬取搜索结果的页面信息

把url中多余的参数去掉
https://www.sogou.com/web?query=%E8%B5%B5%E6%B5%A9%E7%84%B6
这里的中文变成了乱码,无需处理,当然想手动换成中文也行
为了使关键词可变,需要处理url携带的参数:封装到字典中
再把url中的参数删干净https://www.sogou.com/web
import requests
url = 'https://www.sogou.com/web'
keyword = input()
param = {
'query': keyword
}
response = requests.get(url, params=param)
page_txt = response.text
filename = keyword+'.html'
with open(filename, 'w', encoding='utf-8') as fp:
fp.write(page_txt)UA伪装
此次案例中需要介绍一种反扒机制——UA检测
UA:User-Agent:请求载体的身份标识
UA检测:门户网站的服务器会检测对应请求的载体身份标识,如果检测到载体身份标识为某一款浏览器,则认为是正常的请求;否则认为是不正常的请求
UA伪装:将对应的User-Agent封装到headers字典中
f12或者检查页面,找到网络部分,先清楚网络日志再刷新页面,找到需要的请求对应的UA
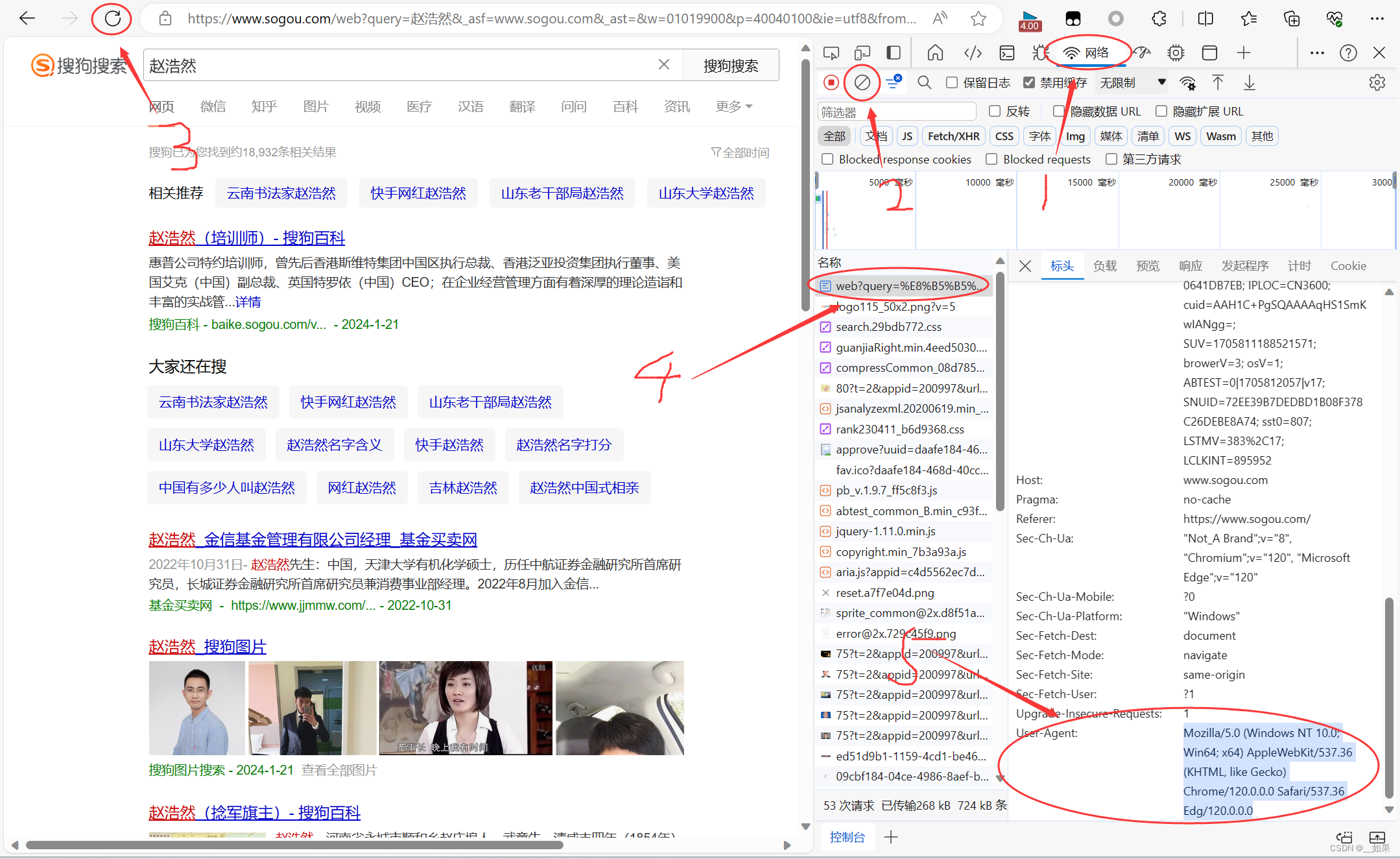
然后把这个headers字典放入get请求中
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
url = 'https://www.sogou.com/web'
keyword = input()
param = {
'query': keyword
}
response = requests.get(url, params=param, headers=headers)
page_txt = response.text
filename = keyword+'.html'
with open(filename, 'w', encoding='utf-8') as fp:
fp.write(page_txt)破解百度翻译
爬取百度翻译中,对应单词翻译的结果
由于我们不是想要爬取整个页面,而是爬取页面中的部分信息,经常需要用到数据解析
但不使用数据解析也能获取局部信息,这次我们就不使用
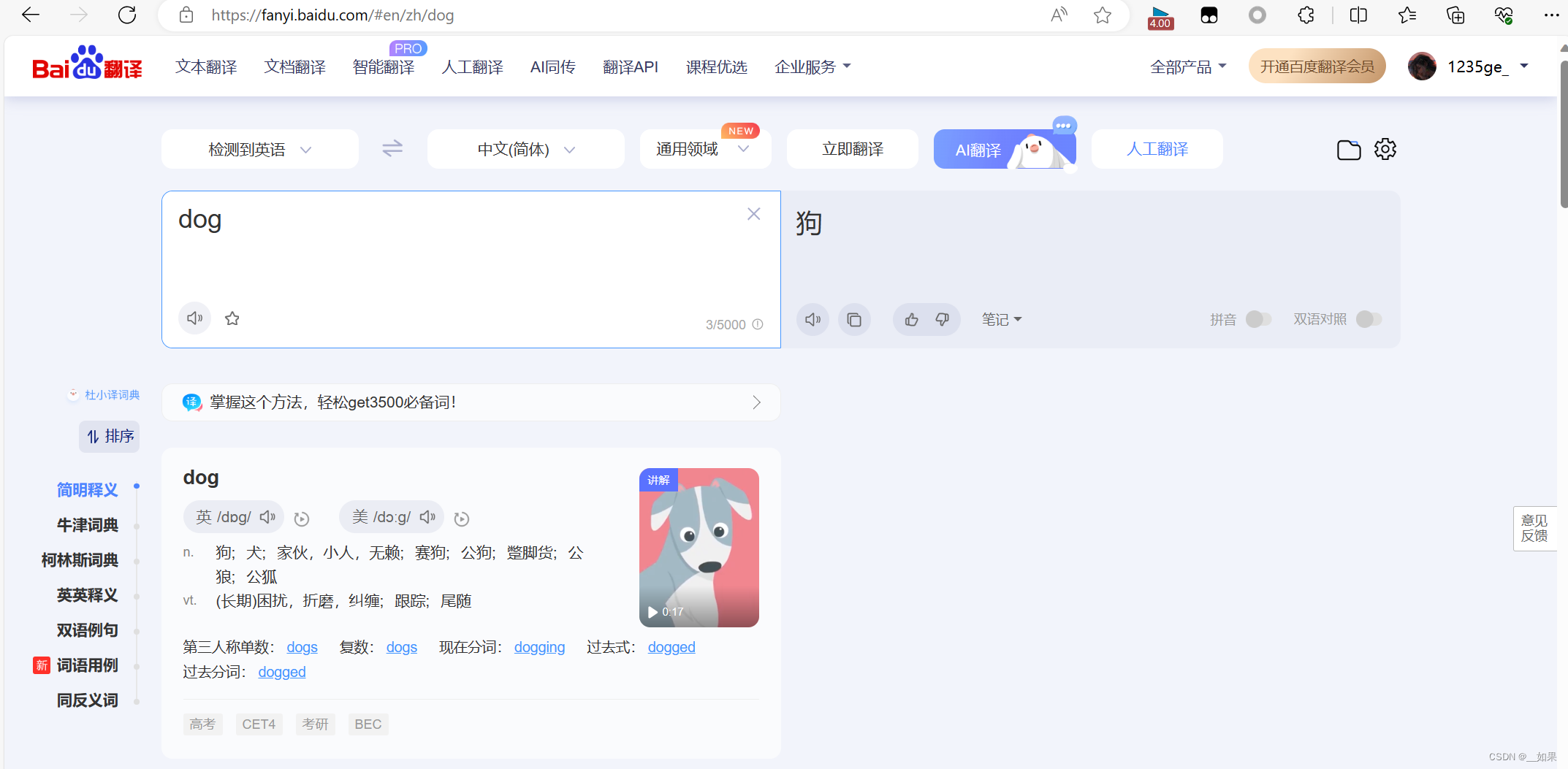
从上面两张图我们可以看出,输入单词后页面做了一个局部的刷新,我们知道局部的刷新是可以通过Ajax实现的,也就意味着我们在文本框中输入字符后,会自动进行Ajax的请求发送,Ajax请求成功后会对页面进行局部刷新
经过分析,我们是不是应该利用抓包工具,捕获一下对应的Ajax请求
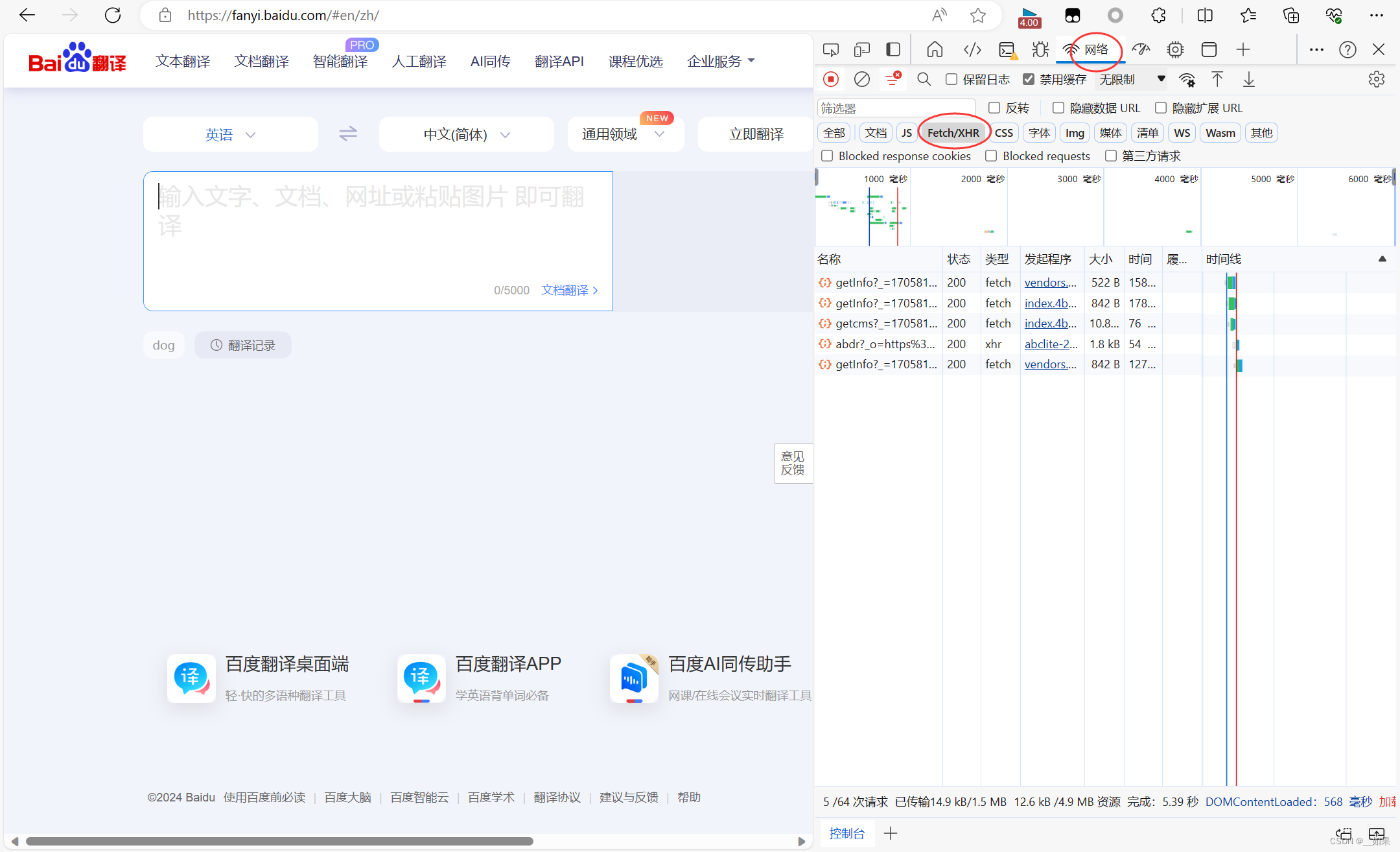
点击XHR,XHR中对应的是Ajax请求的数据包
输入dog
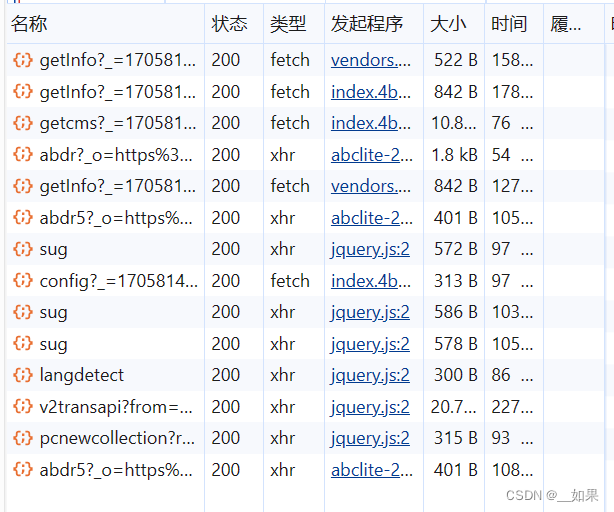
在xhr类型中一个个找
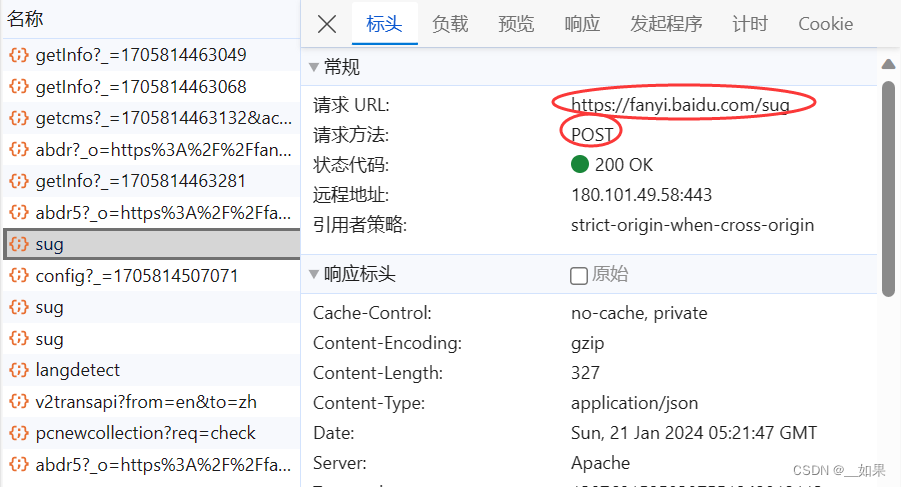
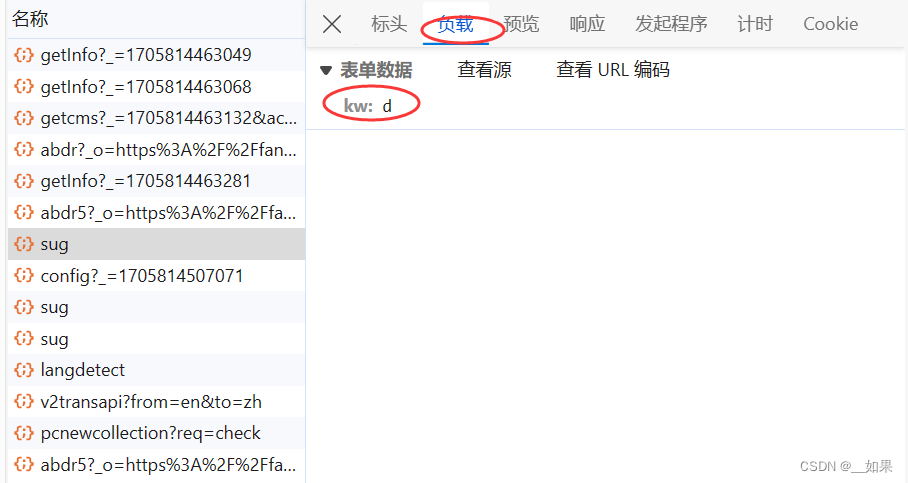
查看post请求携带的参数是d,不清楚是什么东西,所以接着往下看
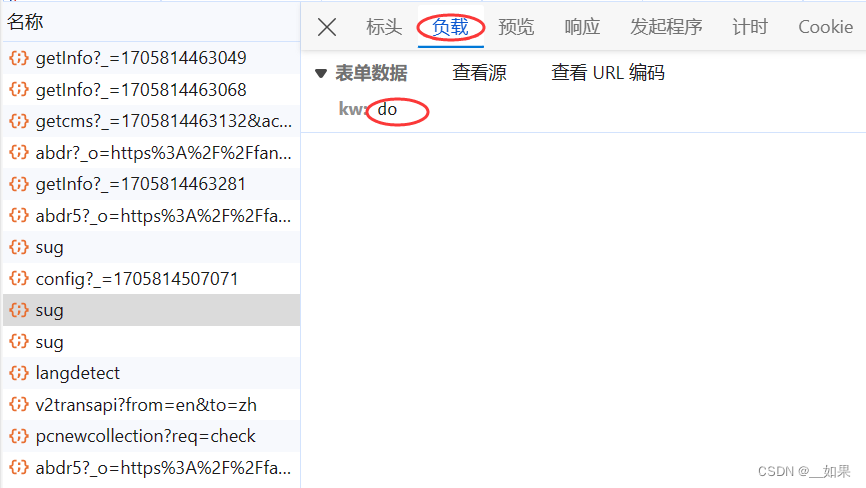
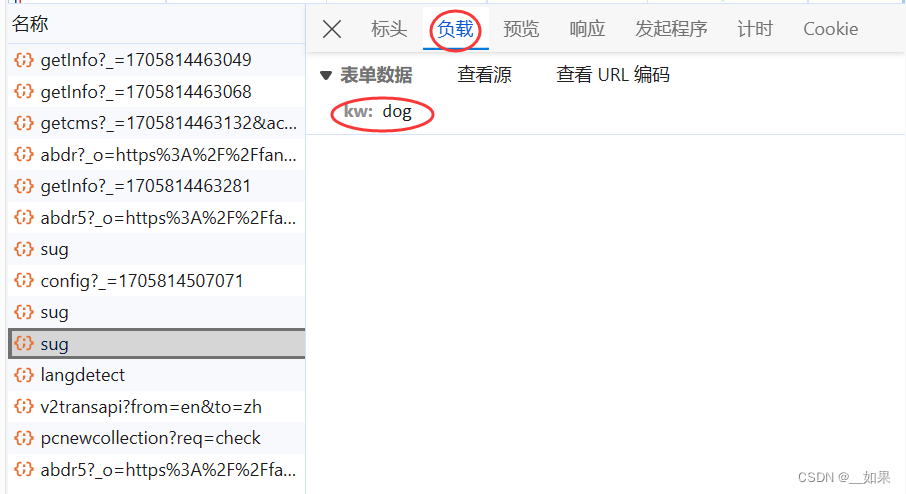
三个sug包对应的是每输入一个字符后的Ajax请求,我们需要的是dog的翻译结果,所以要抓最后一个sug包
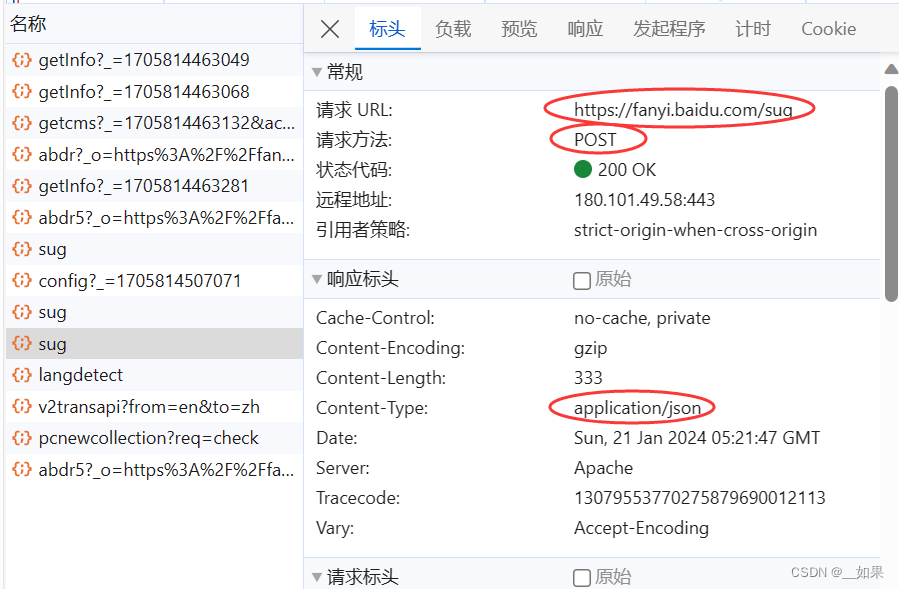
这样我们就拿到了请求的url,Content-Type这里是指我们输入一个字符后,服务器端响应回来的是一组json串
分析总结
(1)post请求(携带了参数)
(2)响应数据是一组json数据
import requests
import json
post_url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36 HBPC/12.1.3.303'
}
word = input()
data = {
'kw': word
}
response = requests.post(url=post_url, data=data, headers=headers)
# 响应数据是json数据,如果继续使用.text获取的是一组字符串形式的json,而.json返回的是一个obj,json是什么对象就是什么对象,在这里是字典
dict_obj = response.json()
# 由于是字典对象,所以不能直接write
filename = './' + word + '.json'
fp = open(filename, 'w', encoding='utf-8')
json.dump(dict_obj, fp, ensure_ascii=False) # 字典中有中文,不用ascii编码未完待续...
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Spring Cloud + Vue前后端分离-第11章 用户管理与登录
- Java函数式编程最佳实践
- 非隔离恒压ACDC稳压智能电源模块芯片推荐:SM7015
- 不同光照下HUD抬头显示器光干扰试验用太阳光模拟器
- STM32——高级定时器输出比较模式实验
- linux系统常用操作
- 【python_在列表开头插入一项】
- CAN FD数据脱机记录仪的在汽车应用上的优势
- 【算法优选】 动态规划之简单多状态dp问题——壹
- 瞬态抑制二极管(TVS)的注意事项与布局布线?|深圳比创达电子