Java学习苦旅(十八)——详解Java中的二叉树
本篇博客将详细讲解二叉树
树型结构
简介
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
-
有一个特殊的结点,称为根结点,根结点没有前驱结点
-
除根结点外,其余结点被分成M(M > 0)个互不相交的集合T1、T2、…、Tm,其中每一个集合 Ti (1 <= i<= m) 又是一棵与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继。
-
树是递归定义的。
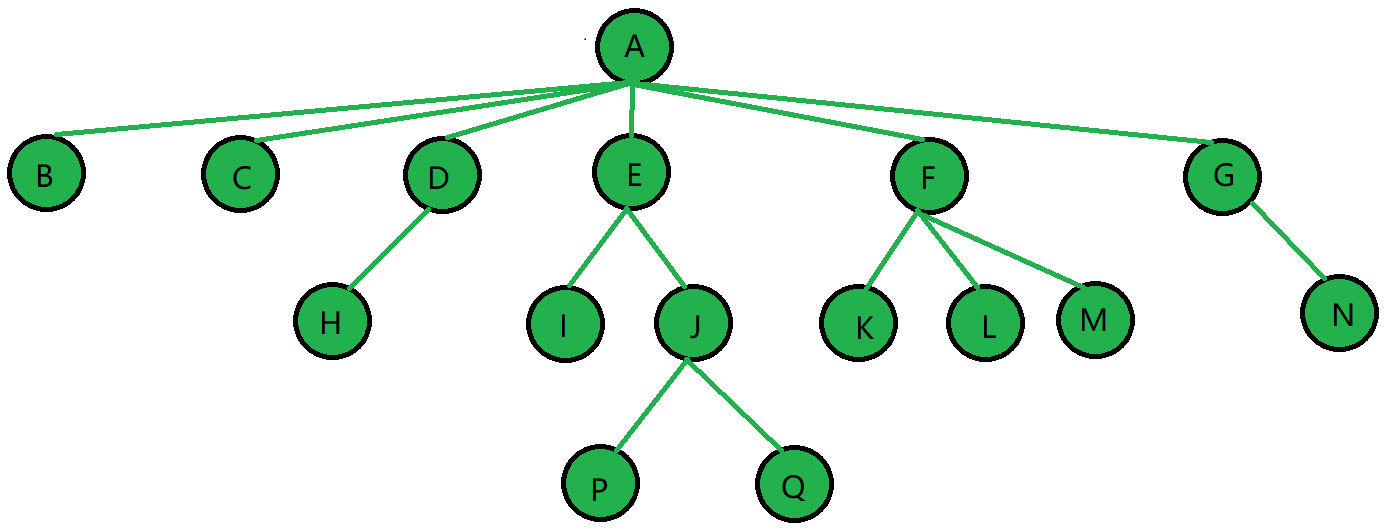
注意:树形结构中,子树之间不能有交集,否则就不是树形结构。
基本概念
结点的度:一个结点含有子树的个数称为该结点的度; 如上图:A的度为6
树的度:一棵树中,所有结点度的最大值称为树的度; 如上图:树的度为6
叶子结点或终端结点:度为0的结点称为叶结点; 如上图:B、C、H、I…等节点为叶结点
双亲结点或父结点:若一个结点含有子结点,则这个结点称为其子结点的父结点; 如上图:A是B的父结点
孩子结点或子结点:一个结点含有的子树的根结点称为该结点的子结点; 如上图:B是A的孩子结点
根结点:一棵树中,没有双亲结点的结点;如上图:A
结点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推
树的高度或深度:最大的深度是树的高度,如上图,树的高度为4
非终端结点或分支结点:度不为0的结点; 如上图:D、E、F、G…等节点为分支结点
兄弟结点:具有相同父结点的结点互称为兄弟结点; 如上图:B、C是兄弟结点
堂兄弟结点:双亲在同一层的结点互为堂兄弟;如上图:H、I互为兄弟结点
结点的祖先:从根到该结点所经分支上的所有结点;如上图:A是所有结点的祖先
子孙:以某结点为根的子树中任一结点都称为该结点的子孙。如上图:所有结点都是A的子孙
森林:由m(m>=0)棵互不相交的树组成的集合称为森林
表示形式
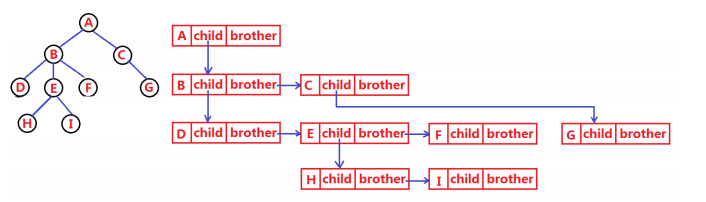
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,实际中树有很多种表示方式,如:双亲表示法,孩子表示法,孩子双亲表示法,孩子兄弟表示法等等。我们这里就简单的了解其中最常用的孩子兄弟表示法。
class Node {
int value;//树中存储的数据
Node firstChild;//第一个孩子引用
NOde nextBrother;//下一个兄弟引用
}
例如:
二叉树
概念
一棵二叉树是结点的一个有限集合,该集合:
-
要么为空。
-
要么是由一个根节点加上两棵被称为左子树和右子树的二叉树组成。
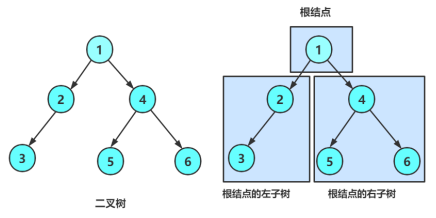
从上图可以看出:
-
二叉树不存在度大于2的结点。
-
二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树。
注意:对于任意的二叉树都是由以下几种情况复合而成的:
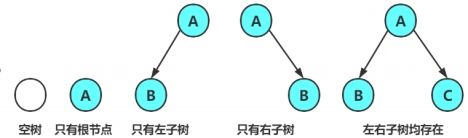
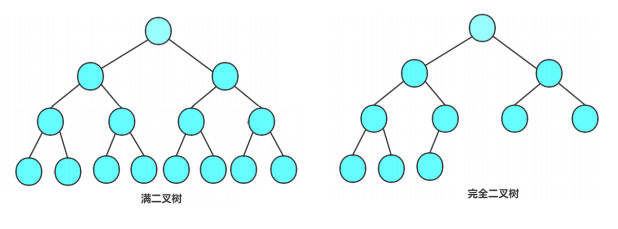
两种特殊的二叉树
-
满二叉树:一棵二叉树,如果每层的结点数都达到最大值,则这棵二叉树就是满二叉树。也就是说,如果一棵二叉树的层数为K,且结点总数是2K-1,则它就是满二叉树。
-
完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从0至n-1的结点一一对应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。
二叉树的性质
-
若规定根结点的层数为1,则一棵非空二叉树的第i层上最多有2i-1(i>0)个结点
-
若规定只有根结点的二叉树的深度为1,则深度为K的二叉树的最大结点数是2K-1(k>=0)
-
对任何一棵二叉树, 如果其叶结点个数为n0,度为2的非叶结点个数为n2,则有n0=n2+1
-
具有n个结点的完全二叉树的深度k为log2(n+1)上取整
-
对于具有n个结点的完全二叉树,如果按照从上至下从左至右的顺序对所有节点从0开始编号,则对于序号为i的结点有:
-
若i>0,双亲序号:(i-1)/2;i=0,i为根结点编号,无双亲结点
-
若2i+1<n,左孩子序号:2i+1,否则无左孩子
-
若2i+2<n,右孩子序号:2i+2,否则无右孩子
二叉树的存储
二叉树的存储结构分为:顺序存储和类似于链表的链式存储。
本篇博客先讲解链式存储。
二叉树的链式存储是通过一个一个的节点引用起来的,常见的表示方式有二叉和三叉表示方式,具体如下:
//孩子表示法
class Node {
int val;//数据域
Node left;//左孩子的引用
Node right;//右孩子的引用
}
//孩子双亲表示法
class Node {
int val;//数据域
Node left;//左孩子的引用
Node right;//右孩子的引用
Node parent;//当前节点的根节点
}
二叉树的简单创建
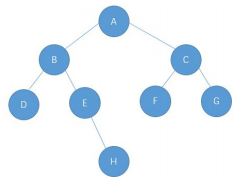
简单创建一个二叉树(不是真正创建二叉树的方式):
class BTNode {
public char val;
public BTNode left;
public BTNode right;
public BTNode(char val) {
this.val = val;
}
}
public class BinaryTree {
public BTNode createTree() {
BTNode A = new BTNode('A');
BTNode B = new BTNode('B');
BTNode C = new BTNode('C');
BTNode D = new BTNode('D');
BTNode E = new BTNode('E');
BTNode F = new BTNode('F');
BTNode G = new BTNode('G');
BTNode H = new BTNode('H' ;
A.left = B;
A.right = C;
B.left = D;
B.right = E;
C.left = F;
C.right = G;
E.right = H;
return A;
}
}
创建的二叉树为:
二叉树的遍历
前中后序遍历
学习二叉树结构,最简单的方式就是遍历。所谓**遍历(Traversal)是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问。**访问结点所做的操作依赖于具体的应用问题(比如:打印节点内容、节点内容加1)。 遍历是二叉树上最重要的操作之一,是二叉树上进行其它运算之基础。
在遍历二叉树时,如果没有进行某种约定,每个人都按照自己的方式遍历,得出的结果就比较混乱,如果按照某种规则进行约定,则每个人对于同一棵树的遍历结果肯定是相同的。如果N代表根节点,L代表根节点的左子树,R代表根节点的右子树,则根据遍历根节点的先后次序有以下遍历方式:
- NLR:前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点—>根的左子树—>根的右子树。
- LNR:中序遍历(Inorder Traversal)——根的左子树—>根节点—>根的右子树。
- LRN:后序遍历(Postorder Traversal)——根的左子树—>根的右子树—>根节点。
实现代码如下:
//前序遍历
void preOrder(Node root) {
if (root == null) {
return;
}
System.out.print(root.val + " ");
preOrder(root.left);
preOrder(root.right);
}
//中序遍历
void inOrder(Node root) {
if (root == null) {
return;
}
inOrder(root.left);
System.out.print(root.val + " ");
inOrder(root.right);
}
//后序遍历
void postOrder(Node root) {
if (root == null) {
return;
}
postOrder(root.left);
postOrder(root.right);
System.out.print(root.val + " ");
}
层序遍历
层序遍历是从所在二叉树的根节点出发,首先访问第一层的树根节点,然后从左到右访问第2层上的节点,接着是第三层的节点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
示例代码
public void levelOrder(Node root) {
Queue<Node> queue = new LinkedList<>();
if (root == null) {
return;
}
queue.offer(root);
while (!queue.isEmpty()) {
Node cur = queue.poll();
System.out.print(cur.val + " ");
if (cur.left != null) {
queue.offer(cur.left);
}
if (cur.right != null) {
queue.offer(cur.right);
}
}
}
结尾
本篇博客到此结束。
上一篇博客:Java学习苦旅(十七)——栈和队列
下一篇博客:Java学习苦旅(十九)——详解Java的堆和优先级队列
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Cannot read properties of null (reading ‘addEventListener‘) 解决方法
- 安装LLaMA-Factory微调chatglm3,修改自我认知
- Nest 框架:解锁企业级 Web 应用开发的秘密武器(下)
- 微软Office 2019 批量授权版
- Certum多域名dv证书保护几个域名
- chat-plus部署指南
- 【严重生产问题系列】批量调整业务数据脚本检查
- 【EI&SCOPUS双检索】2024电子、通信与智能科学国际会议(ECIS 2024)征稿通知!
- 科创板涨跌幅限制20%,上海怎么开参考表账户佣金费率最低?万一是哪家证券公司?
- 基于红外传感的野外变压站生物入侵检测系统(论文+源码)