爬虫响应cookie案例:某区ZF
发布时间:2023年12月27日
声明:
该文章为学习使用,严禁用于商业用途和非法用途,违者后果自负,由此产生的一切后果均与作者无关
一、找出需要加密的参数
- js运行 atob(‘aHR0cDovL3d3dy56am1hemhhbmcuZ292LmNuL2hkamxwdC9wdWJsaXNoZWQ/dmlhPXBj’) 拿到网址,F12打开调试工具,刷新页面,找到 hdjlpt/letter/pubList 请求,鼠标右击请求找到Copy>Copy as cUrl(cmd)
- 打开网站:https://spidertools.cn/#/curl2Request,把拷贝好的curl转成python代码,新建 zf.py,把代码复制到该文件
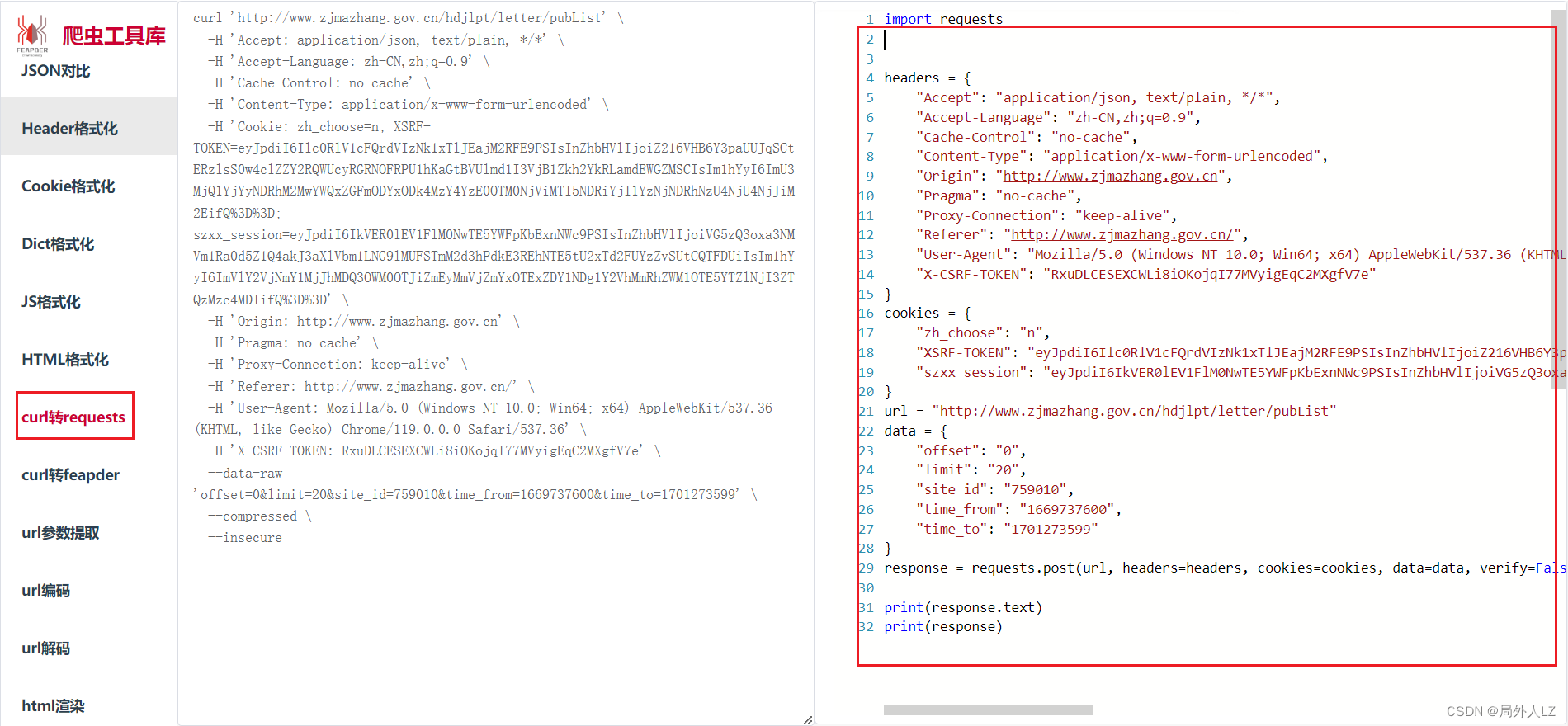
- 然后把代码中的header中的X-CSRF-TOKEN、cookie中的szxx_session分别注释运行文件,会发现数据未获取成功,说明这俩是加密参数
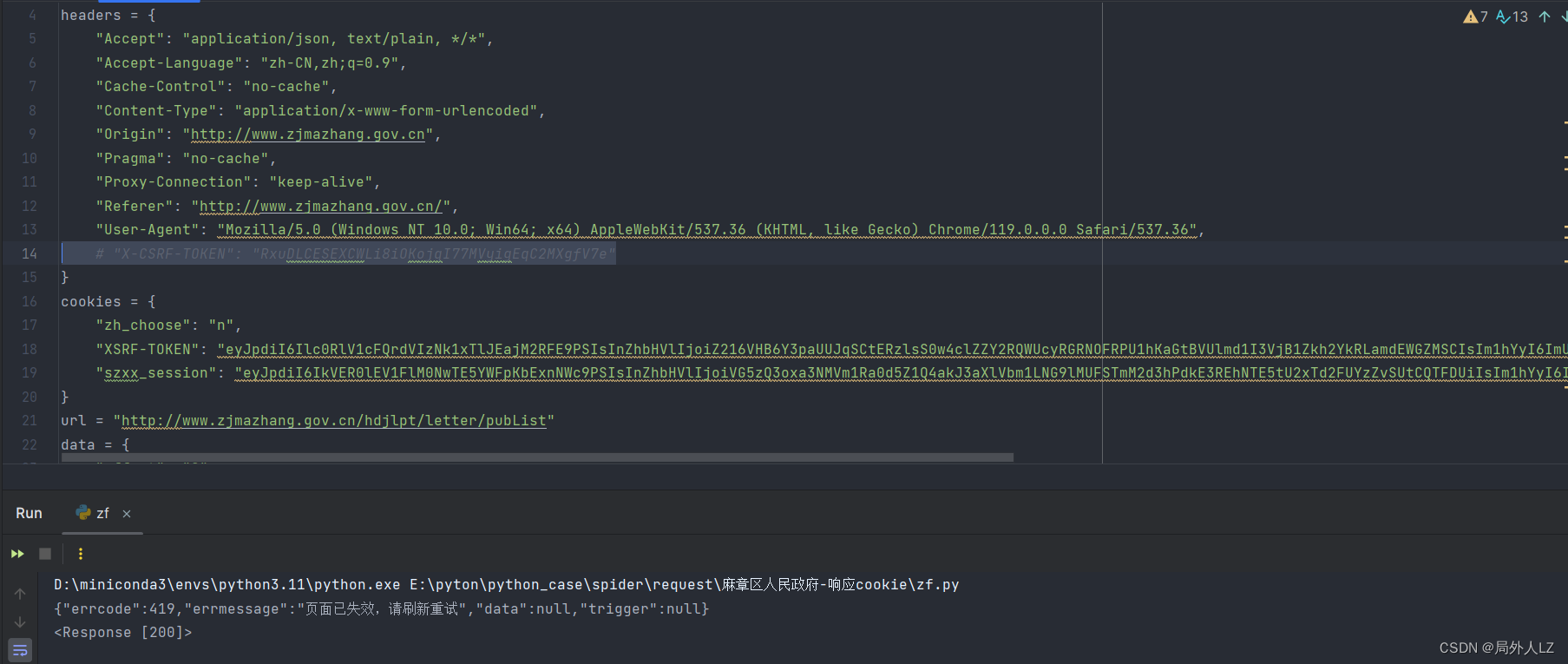
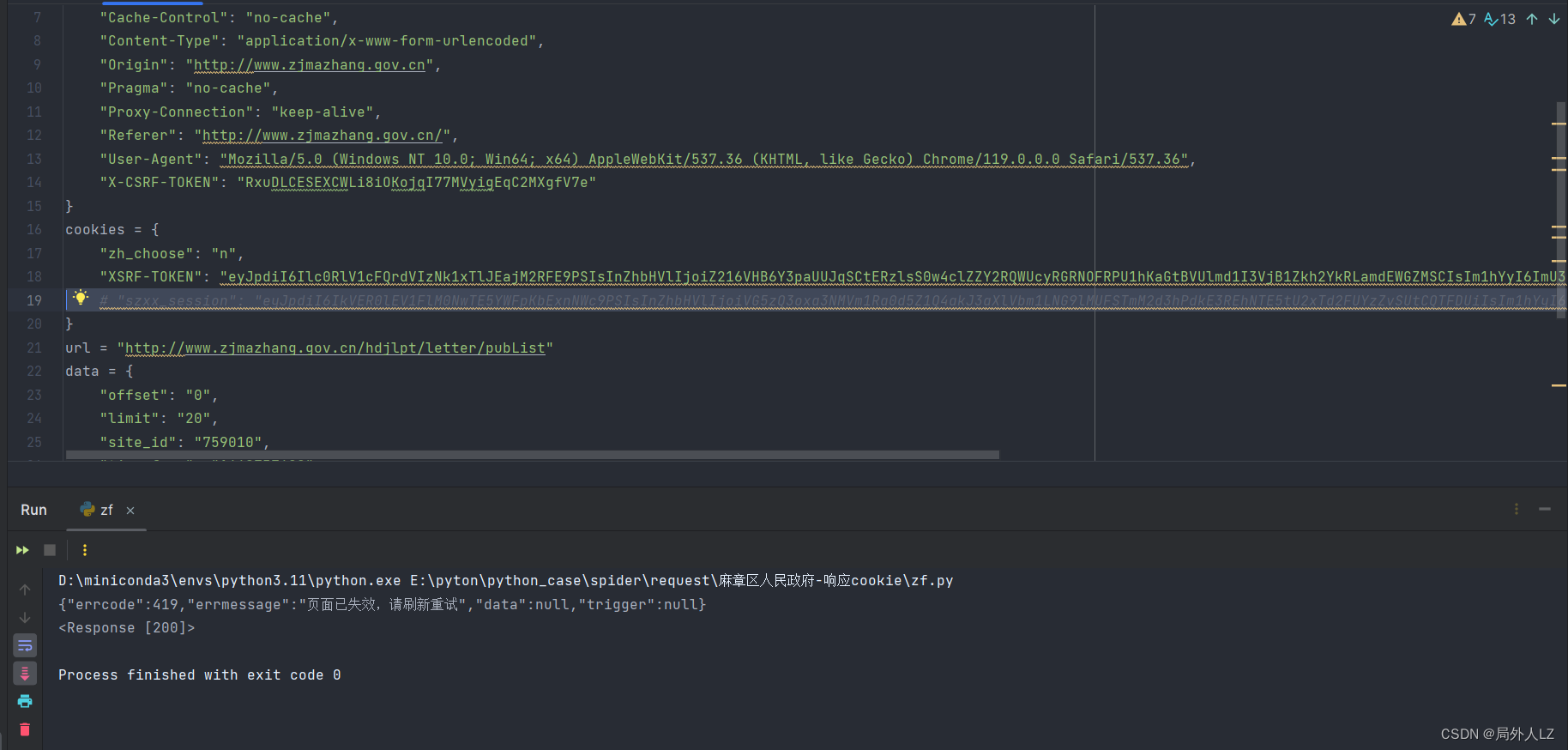
二、定位响应cookie生成位置
- 关键字szxx_session搜索,会发现szxx_session是由响应头set-cookie设置的cookie,Set-Cookie是服务器在客户端储存的一些信息,用于在后续的请求中传递和存储用户相关的信息或状态

- 切换到Application,清除浏览器的cookie,一定要先清除cookie,清除cookie后,刷新页面,关键字搜索szxx_session,找到第一次设置szxx_session的地方,hdjlpt/published?via=pc是第一次设置szxx_session的请求,分析hdjlpt/published?via=pc会发现请求、cookie、header都没加密参数,响应返回的是个html
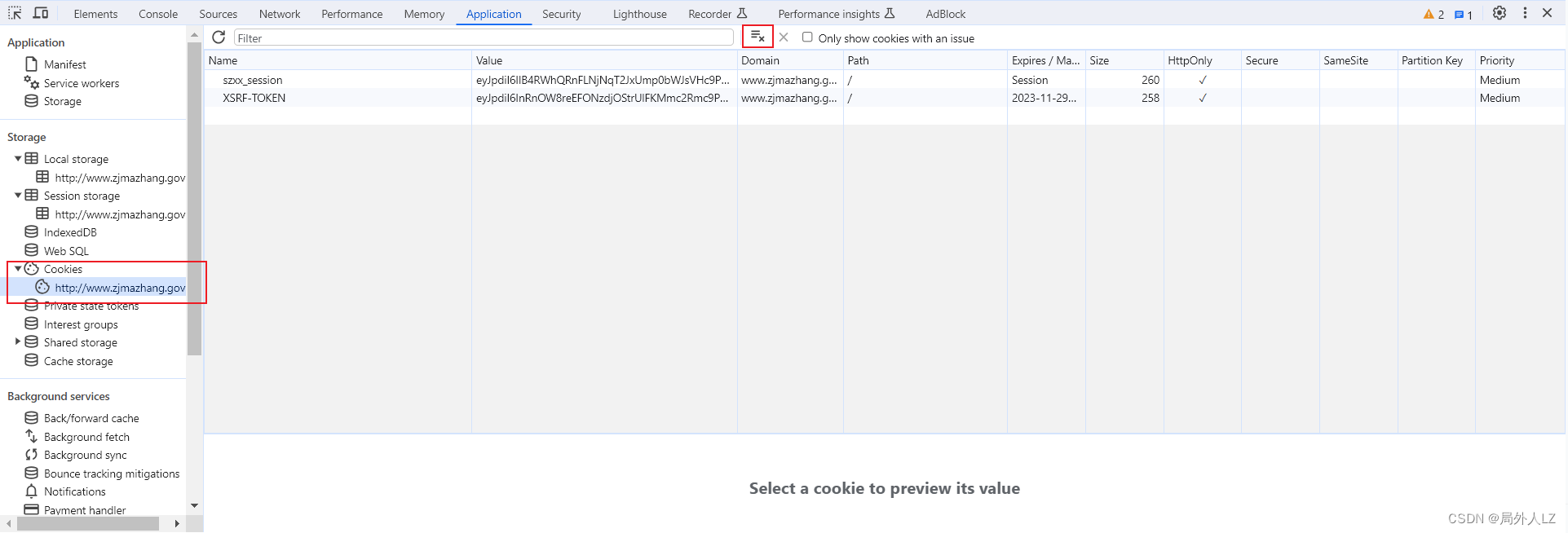
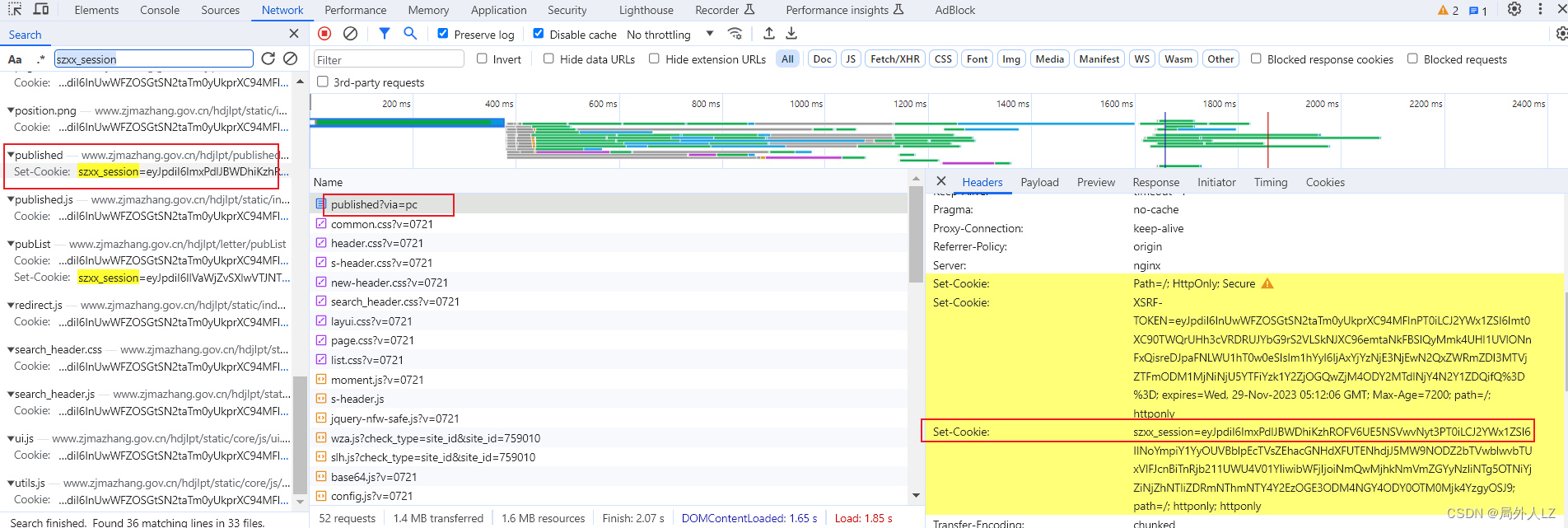
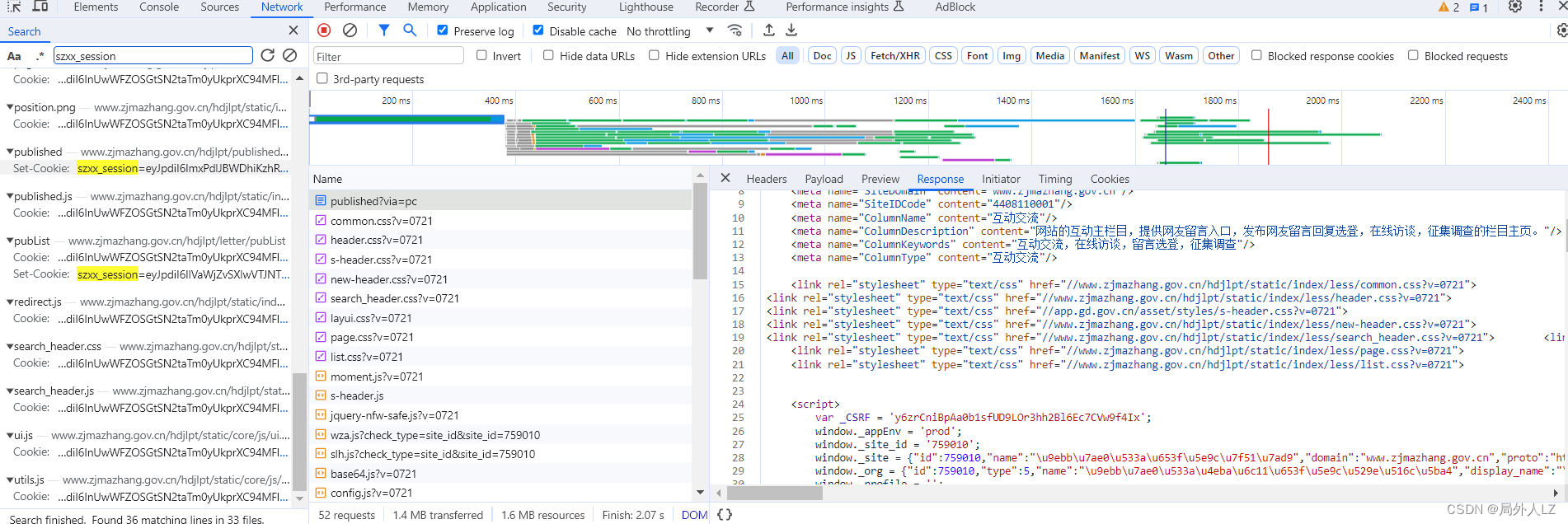
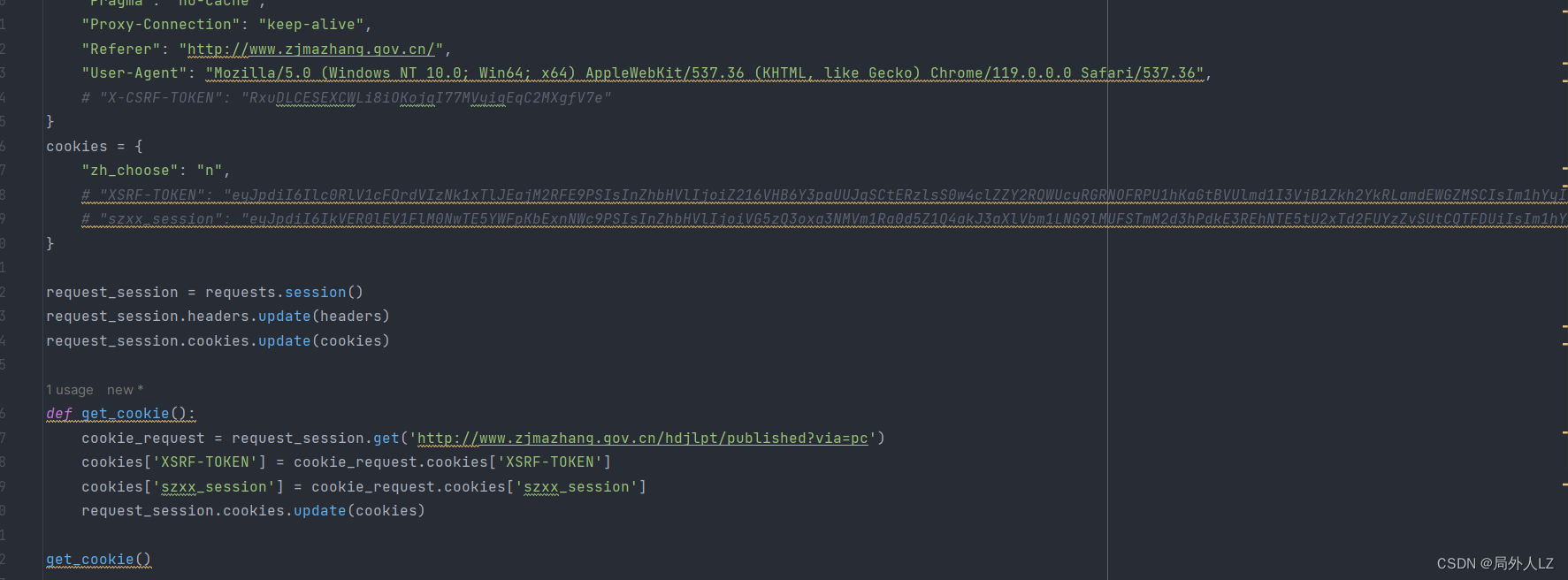
- 修改zf.py,注释掉之前的请求,添加获取get_cookie的请求,会发现szxx_session以从hdjlpt/published?via=pc中拿到
三、定位X-CSRF-TOKEN生成位置
- 关键字X-CSRF-TOKEN搜索,会发现X-CSRF-TOKEN的值是_CSRF,而_CSRF是hdjlpt/published?via=pc中html有个赋值的地方,找到返回的html,复制_CSRF值,通过关键字搜索会发现hdjlpt/letter/pubList中的值正是hdjlpt/published?via=pc中的html_CSRF
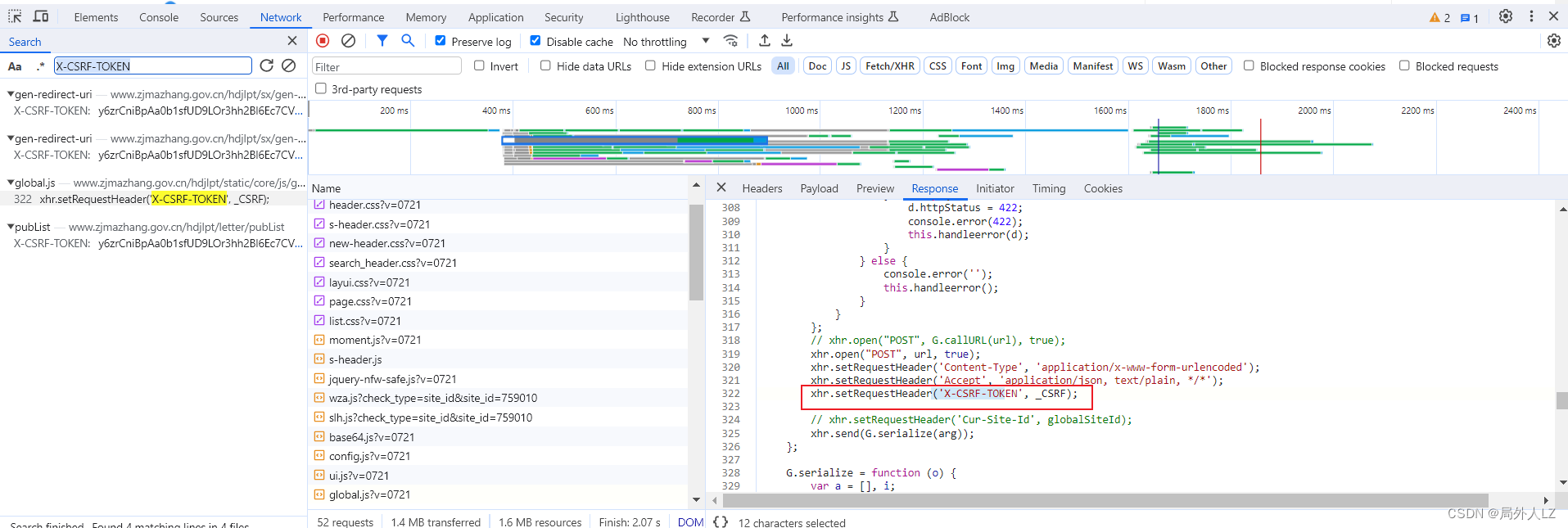
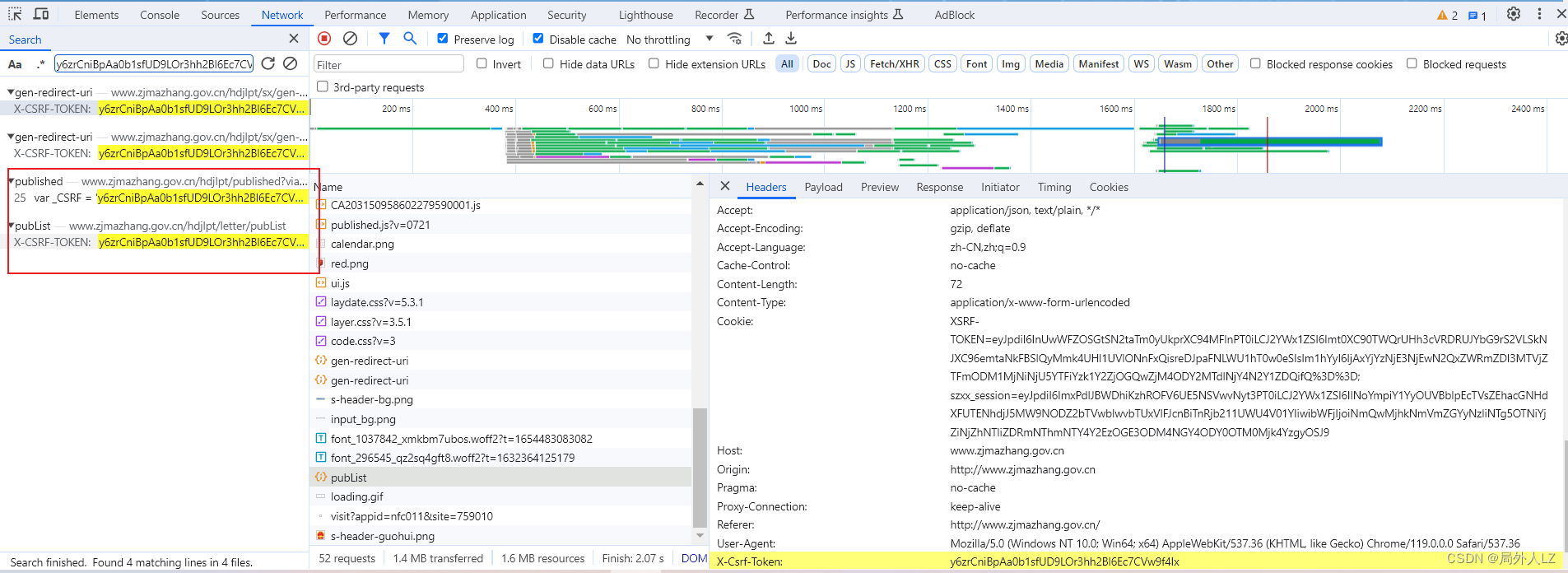
- 修改zf.py,运行文件会发现数据获取成功
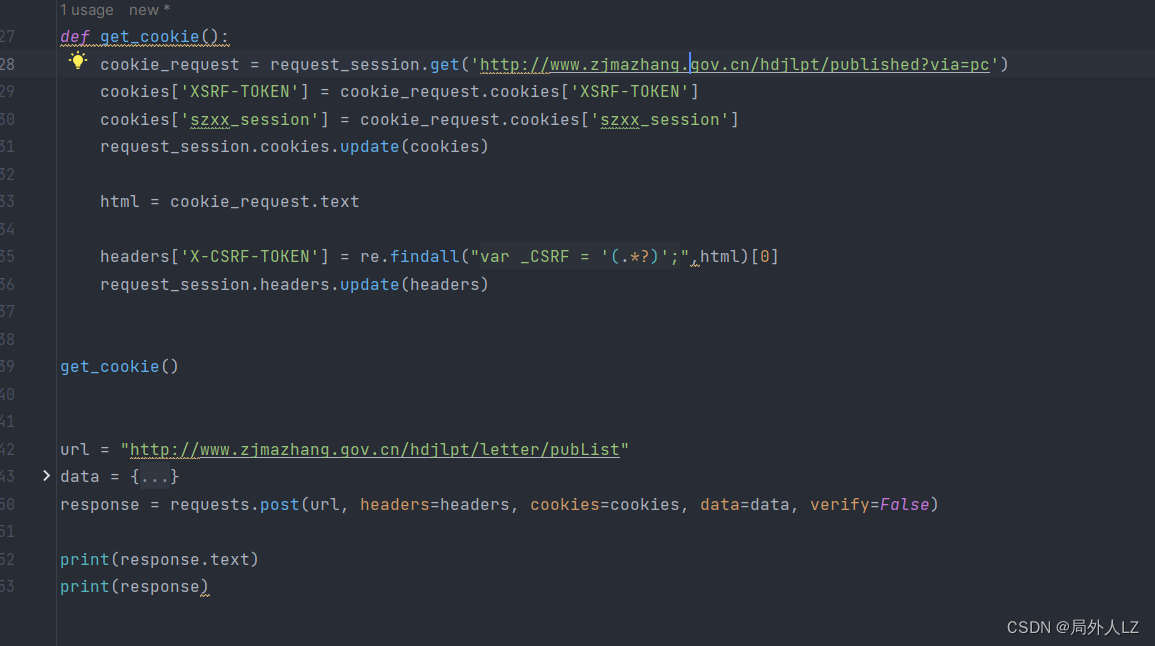
四、最终代码
import requests
import re
headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Content-Type": "application/x-www-form-urlencoded",
"Origin": "http://www.zjmazhang.gov.cn",
"Pragma": "no-cache",
"Proxy-Connection": "keep-alive",
"Referer": "http://www.zjmazhang.gov.cn/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
# "X-CSRF-TOKEN": "RxuDLCESEXCWLi8iOKojqI77MVyigEqC2MXgfV7e"
}
cookies = {
"zh_choose": "n",
# "XSRF-TOKEN": "eyJpdiI6Ilc0RlV1cFQrdVIzNk1xTlJEajM2RFE9PSIsInZhbHVlIjoiZ216VHB6Y3paUUJqSCtERzlsS0w4clZZY2RQWUcyRGRNOFRPU1hKaGtBVUlmd1I3VjB1Zkh2YkRLamdEWGZMSCIsIm1hYyI6ImU3MjQ1YjYyNDRhM2MwYWQxZGFmODYxODk4MzY4YzE0OTM0NjViMTI5NDRiYjI1YzNjNDRhNzU4NjU4NjJiM2EifQ%3D%3D",
# "szxx_session": "eyJpdiI6IkVER0lEV1FlM0NwTE5YWFpKbExnNWc9PSIsInZhbHVlIjoiVG5zQ3oxa3NMVm1Ra0d5Z1Q4akJ3aXlVbm1LNG9lMUFSTmM2d3hPdkE3REhNTE5tU2xTd2FUYzZvSUtCQTFDUiIsIm1hYyI6ImVlY2VjNmY1MjJhMDQ3OWM0OTJiZmEyMmVjZmYxOTExZDY1NDg1Y2VhMmRhZWM1OTE5YTZlNjI3ZTQzMzc4MDIifQ%3D%3D"
}
request_session = requests.session()
request_session.headers.update(headers)
request_session.cookies.update(cookies)
def get_cookie():
cookie_request = request_session.get('http://www.zjmazhang.gov.cn/hdjlpt/published?via=pc')
cookies['XSRF-TOKEN'] = cookie_request.cookies['XSRF-TOKEN']
cookies['szxx_session'] = cookie_request.cookies['szxx_session']
request_session.cookies.update(cookies)
html = cookie_request.text
headers['X-CSRF-TOKEN'] = re.findall("var _CSRF = '(.*?)';",html)[0]
request_session.headers.update(headers)
get_cookie()
url = "http://www.zjmazhang.gov.cn/hdjlpt/letter/pubList"
data = {
"offset": "0",
"limit": "20",
"site_id": "759010",
"time_from": "1669737600",
"time_to": "1701273599"
}
response = requests.post(url, headers=headers, cookies=cookies, data=data, verify=False)
print(response.text)
print(response)
文章来源:https://blog.csdn.net/randy521520/article/details/134754257
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 什么叫范数?
- 立仪科技光谱共焦位移传感器:应用领域的广泛性
- Metasequoia4 for Mac/win:带您进入三维模型游戏建模的新世界!
- 【浅谈】软件架构中轻量级与重量级的区别
- Rust之构建命令行程序(二):读取文件
- 【经典算法】有趣的算法之---蚁群算法梳理
- 新国大张阳教授团队开发精度远超AlphaFold的AI蛋白质互作结构预测算法
- AI人工智能与云原生:创新科技的完美结合
- 印尼小胖子表情包大全
- C 语言关于位运行符