FID score
FID score
什么是FID
Frechet Inception Distance 是FID的缩写,是评估生成图像质量的指标。
FID score 是作为对Inception Score 的改进提出的。inception score是根据表现很好的图片分类模型Inception v3分类生成图片集合的分类结果好坏得到的。这个分数结合了每个合成图像的条件类预测的置信度(quality)和预测类的边际概率的积分(diversity)。
quality可以这样理解,针对每个图片得到的结果是一个概率向量,那么就希望它所属于的那个类别的概率尽可能的大,而其他概率尽可能小;diversity也就是多样性,就是要使得将生成的图片集合的概率向量相加得到的概率分布(marginal distribution)尽可能贴近均匀分布。通过kl散度可以将两者进行融合,原理就是希望
p
(
y
∣
x
)
p(y|x)
p(y∣x)与
p
(
y
)
p(y)
p(y)之间的距离大一些,这样结果会好一些。
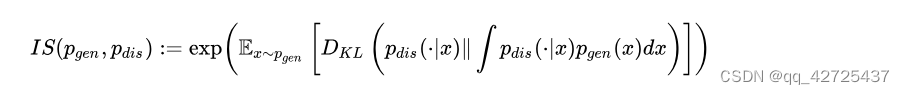
IS没有评估生成图片与真实图片的比较。FID就考虑了生成图片的统计数据与真实数据的统计数据之间的比较。
像inception score一样,FID得分也使用了Inception v3模型。具体来说,使用了模型的编码层(输出图像分类之前的最后一个池化层)来捕捉输入图像的计算机视觉特定特征。这些激活值是对真实和生成的图像集合计算得出的。
这些激活值被总结为一个多变量高斯分布,方法是计算图像的均值和协方差。然后,对真实和生成图像集合中的激活值计算这些统计数据。
然后使用frechet距离(也称为Wasserstein-2距离)计算这两个分布之间的距离。
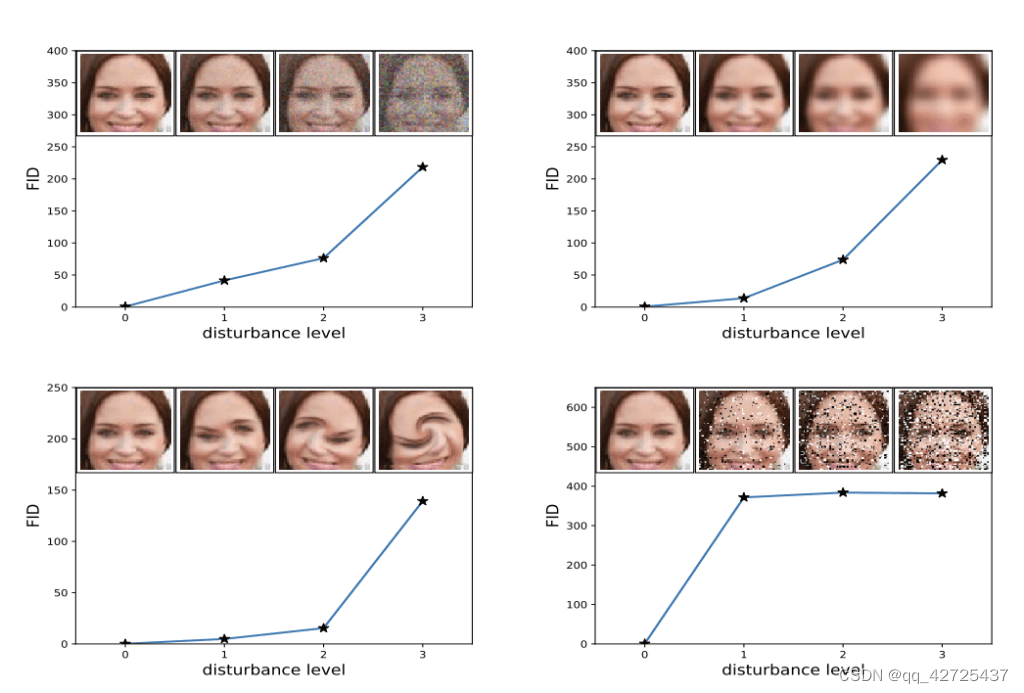
较低的FID表示图像质量更好;相反,较高的得分表示图像质量较低,这种关系可能是线性的。
怎么计算FID
FID得分的计算首先需要加载一个预训练的Inception v3模型。
模型的输出层被移除,输出取自最后一个池化层,即全局空间池化层。
这个输出层有2048个激活值,因此,每张图像被预测为2048个激活特征。这被称为图像的编码向量或特征向量。
然后,为问题领域中的一组真实图像预测出2048个特征向量,以提供真实图像表示方式的参考。然后可以为合成图像计算特征向量。
结果将是两组真实和生成图像的2048个特征向量。
然后,根据论文中的以下方程计算FID得分:
d
2
=
∣
∣
μ
1
–
μ
2
∣
∣
2
+
T
r
(
C
1
+
C
2
–
2
?
s
q
r
t
(
C
1
?
C
2
)
)
d^2 = ||\mu_1 – \mu_2||^2 + Tr(C_1 + C_2 – 2*sqrt(C_1*C_2))
d2=∣∣μ1?–μ2?∣∣2+Tr(C1?+C2?–2?sqrt(C1??C2?))
其中
μ
\mu
μ是均值,C是协方差矩阵
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!