Paper Reading: (InPL) 不平衡半监督学习中的分布内伪标记优先

简介
题目:《InPL: Pseudo-labeling the Inliers First for Imbalanced Semi-supervised Learning》, ICLR’23
? InPL:不平衡半监督学习中的分布内伪标记优先
日期:2023.2.2
单位:威斯康星大学麦迪逊分校
论文地址:https://openreview.net/forum?id=m6ahb1mpwwX
GitHub:-
- 作者
Zhuoran Yu

研究领域:之前是目标检测,今年发了两篇半监督相关的,一个是这篇,一个是人体姿态估计
Yin Li, https://www.biostat.wisc.edu/~yli/

Yong Jae Lee

副教授,威斯康星州麦迪逊 计算机科学大学系
- 摘要
最近最先进的不平衡半监督学习(SSL)方法依赖于具有一致性正则化的基于置信度的伪标记。为了获得高质量的伪标签,通常采用高置信度阈值。然而,已经表明,对于远离训练数据的样本,深度网络中基于softmax的置信度得分可以任意高,因此,即使是高置信度的未标记样本的伪标签也可能仍然不可靠。在这项工作中,我们为不平衡SSL的伪标记提供了一个新的视角。在不依赖模型置信度的情况下,我们建议测量未标记的样本是否可能“分布”;即接近于当前训练数据。为了确定未标记样本是“分布中”还是“分布外”,我们采用分布外检测文献中的能量分数。随着训练的进行,越来越多的未标记样本分布并有助于训练,组合的标记和伪标记数据可以更好地近似真实的类分布,以改进模型。实验表明,我们的基于能量的伪标记方法InPL虽然概念简单,但在不平衡SSL基准上显著优于基于置信度的方法。例如,它比CIFAR10-LT的绝对精度提高了约3%。当与最先进的长尾SSL方法相结合时,可以获得进一步的改进。特别是,在最具挑战性的场景之一中,InPL的准确率比最好的竞争对手提高了6.9%。
目标/动机
大多数方法都是为平衡SSL设置而设计的,其中每个类都有相似数量的训练样本,而大多数真实世界的数据自然是不平衡的,通常遵循长尾分布。
最先进的不平衡SSL方法建立在伪标记和一致性正则化框架的基础上,通过增加额外的模块来解决特定的不平衡问题(例如,使用每类平衡采样)。至关重要的是,这些方法仍然依赖于基于置信度的阈值处理来进行伪标记,其中只有预测类别置信度超过非常高阈值(例如0.95)的未标记样本才被伪标记用于训练。
尽管基于置信度的伪标记在平衡SSL中取得了成功,但在不平衡的长尾设置中面临两个主要缺点。首先,应用高置信度阈值会显著降低少数类别的伪标签召回率,导致类别失衡加剧。降低阈值可以提高尾部类别的召回率,但代价是降低其他类别的精度(见第4.4节中的分析)。其次,先前的研究表明,即使在分布外的样本上,深度网络中基于softmax的置信度得分也可以任意高。因此,在模型通常偏向多数类的长尾场景下,即使实例实际上来自尾部类,模型也可以预测头部类的高置信度分数,导致头部类的精度低。
考虑到使用置信度得分作为伪标记标准的缺点,试图设计一种更好的方法来确定是否应该对未标记的样本进行伪标记。
提出了一种新的伪标记方法,该方法解决了不平衡SSL中基于置信度的伪标记的缺点。将是否对未标记的实例进行伪标记,视为分布内与分布外分类问题,而不是依赖模型的预测置信度来决定。
用一个示例来说明InPL的思想

图1:我们用一个示例来说明InPL的思想,其中有一个头部类(绿色)和一个尾部类(红色)。(a) 在训练开始时,只有少数未标记的样本足够接近由初始标记数据形成的训练分布。请注意,使用基于置信度的方法,未标记的菱形样本将被添加为绿色类别的伪标签,因为模型对它的置信度非常高(0.97)。相反,我们的InPL忽略了它,因为它的能量分数太高,因此在现阶段被视为不分布。(b) 随着训练的进行,训练分布由初始标记数据和伪标记的“分布中”未标记数据演化而来,并且更多的未标记数据可以被包括在训练中。在这个例子中,使用我们的方法InPL,菱形样本最终将被伪标记为红色类别。
一个重要的insight是:如果无标注样本远离带标注数据,即使它的伪标签是高置信度的,也可能不可信。因此,作者借鉴了OOD领域的思想,将赋予伪标签的过程看做是区分伪标签是否分布内or分布外的数据(只是借鉴,非经典OOD的含义),所有人为标注的数据都是分布内数据,其余为分布外数据。自训练的过程实际上演变为逐步拓展分布范围的过程,每次都为最接近分布内的样本赋予伪标签。
为了确定“内部因素”,我们利用能量得分(LeCun et al.,2006),因为它简单且具有良好的经验性能。能量分数是一个非概率标量,从模型的logits中导出,理论上与数据样本的概率密度一致——较低/较高的能量反映了训练分布后出现概率较高/较低的数据,并已被证明对传统的分布外(OOD)检测有用(Liu et al.,2020)。在我们的不平衡SSL设置中,在每次训练迭代时,我们计算每个未标记样本的能量分数。如果未标记样本的能量低于某个阈值,我们用模型生成的预测类对其进行伪标记。(作者说,他们的工作是第一个从分布内与分布外的角度考虑不平衡SSL中的伪标记,也是第一个在不使用softmax分数的情况下执行伪标记的工作。
方法
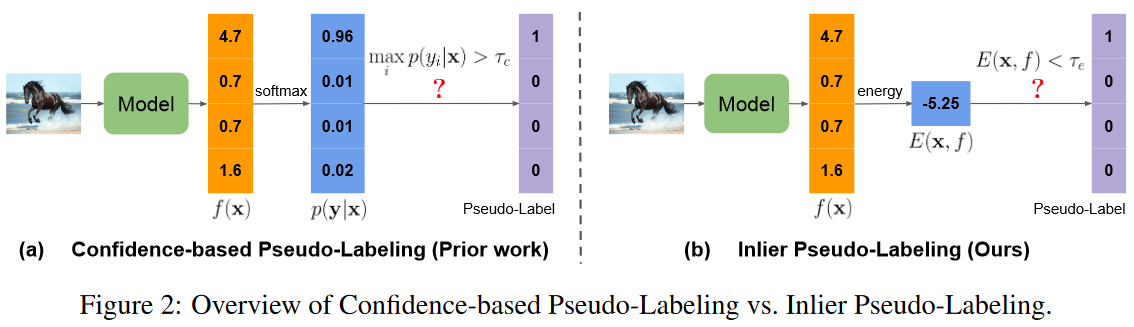
图2:基于置信度的伪标记与Inlier伪标记的概述。
基于置信度的伪标记框架的一致性正则化的Loss(最经典的方法):


本文取代了一个步骤——伪标记标准。将赋予伪标签的过程看做是区分伪标签是否分布内or分布外的数据。为了定义分布内样本,作者使用能量得分
这样的好处是:(1)简便,和模型置信度的指标具有相似的简洁性;(2)有效,这和概率密度函数是对应的,能够很好地反映样本是否符合训练集的分布;(3)使用广泛,在以往的OOD目标检测工作中得到广泛使用。能量得分公式如下:

x:输入数据,fi(x):指示第i类的对应logit值(f是分类器),K:类的总数,T:可调的温度。
计算每个未标记样本的能量分数,并且只有当相应的能量分数小于预定义阈值τe时才生成伪标记,这表明未标记样本接近当前训练分布。实际的伪标签是通过将ω(xb)的弱增广视图上的模型预测转换为独热伪标签来获得的。形式上,无监督损失定义为:
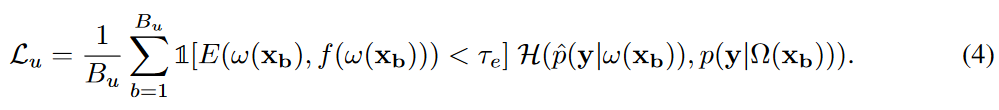
另外,为了解决长尾分布问题,将无监督损失计算中的交叉熵损失函数H(·),替换为自适应margin loss:
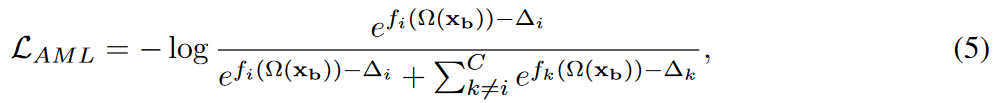
其中, fi(Ω(xb)):表示在强增广输入Ω(xb)上类i的对应logits。
margin 由
计算,其中~p是通过指数移动平均在每次迭代时更新的平均模型预测。
实验
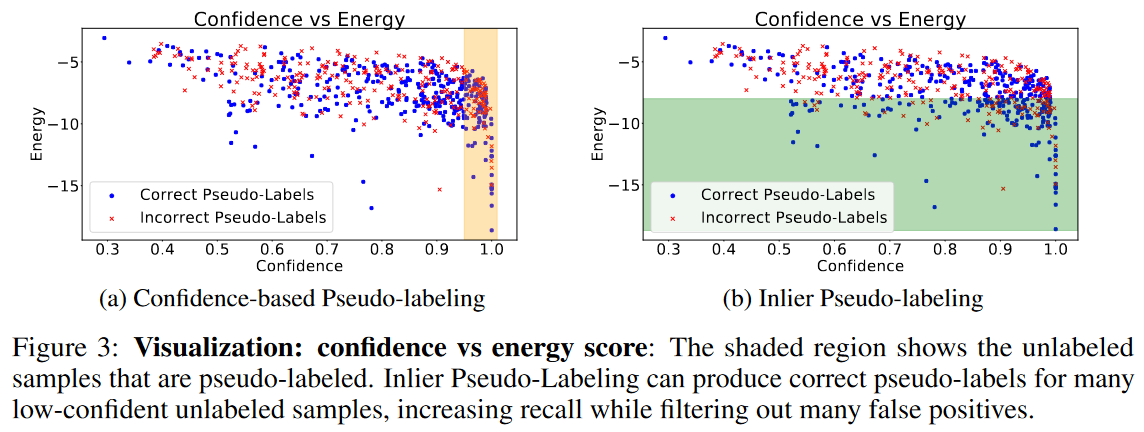
图3:可视化:置信度与能量得分:阴影区域显示了产生伪标签的未标记样本。Inlier伪标记可以为许多低置信度的未标记样本产生正确的伪标记,在过滤掉许多假阳性的同时提高召回率。
首先评估了InPL基于能量的伪标记相对于基于标准置信度的伪标记的有效性。为此,我们将InPL集成到FixMatch框架中(表示为FixMatch InPL),并将其与以下FixMatch变体进行比较。结果表明InPL在不平衡SSL中优于基于置信度的伪标记方法
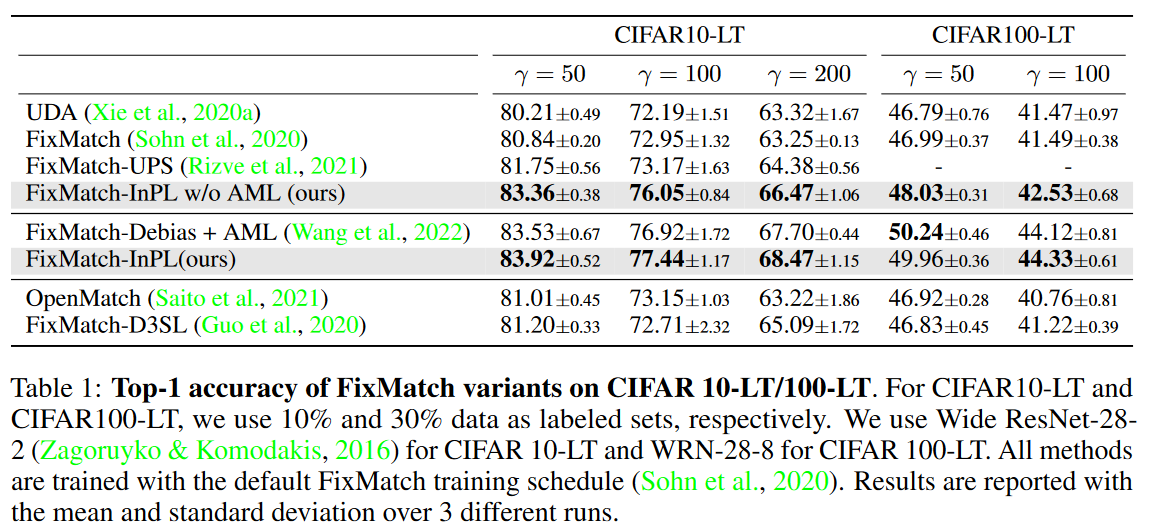
表1:CIFAR 10-LT/100-LT上FixMatch变体的前1位精度。对于CIFAR10-LT和CIFAR100-LT,我们分别使用10%和30%的数据作为标记集。我们将Wide ResNet-282用于CIFAR 10-LT,将WRN-28-8用于CIFAR100-LT。所有方法都使用默认的FixMatch训练计划进行训练。报告了3次不同运行的平均值和标准偏差结果。
接下来,我们将InPL与最先进的不平衡SSL方法进行比较。我们将InPL集成到ABC(Lee et al.,2021)中(ABC是一个最近为不平衡SSL设计的框架)与原始ABC以及其他最先进的不平衡SSL方法DARP、CREST、Adsh和DASO进行了比较。结果如表2和表3所示。结果表明,InPL在不同框架和评估设置的不平衡数据上实现了更好的性能。
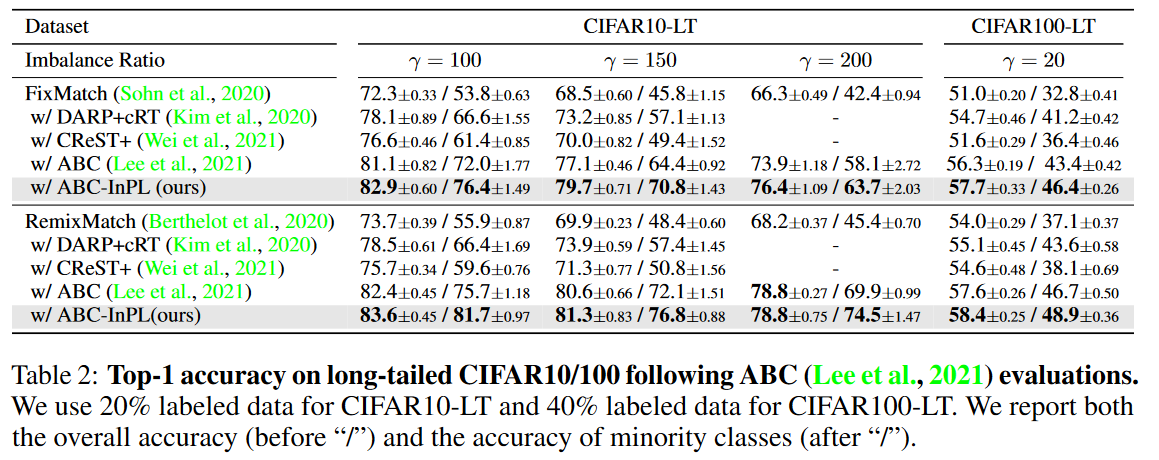
表2:ABC评估后,长尾CIFAR10/100的Top-1准确性。我们对CIFAR10-LT使用20%的标记数据,对CIFAR100-LT使用40%的标记数据。我们报告了总体准确度(在“/”之前)和少数类别的准确度(“/”之后)。
请注意,当将InPL集成到ABC框架中时,我们基于能量的伪标记仅应用于辅助类平衡分类器。原始分类器仍然使用基于置信度的伪标记进行训练,因为根据经验,我们发现使用基于能量的伪标记对两者都没有好处。
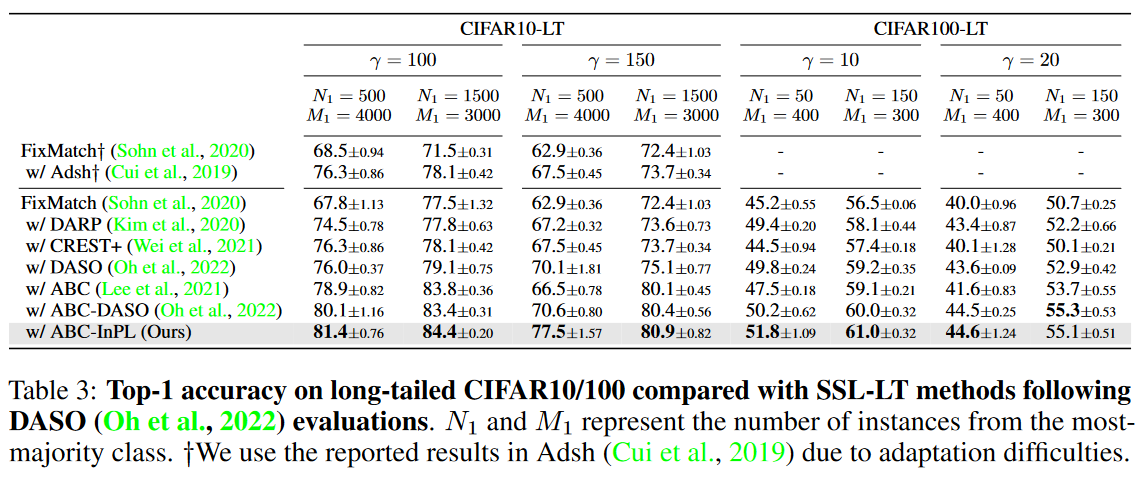
表3:DASO(Oh et al.,2022)评估后,与SSL-LT方法相比,长尾CIFAR10/100的Top-1准确性。N1和M1表示来自最大多数类的实例数。?由于适应困难,我们使用了Adsh(Cui et al.,2019)中报告的结果。

表4:ImageNet-127和ImageNet的结果。我们使用10%的样本数据作为ImageNet127的标记集,并使用ImageNet的每个类100个标签。我们的方法在两个数据集上都优于FixMatch中基于置信度的方法。
其他标准SSL数据集的结果可以在附录A.8中找到: 附录中的Table C

表C:CIFAR10、SVHN和STL10的前1位精度。?由于适应困难,我们从其原始论文(Xu et al.,2021)中报告了DASH的结果,该论文使用了不同的代码库。所有方法(包括我们的方法)在实验中使用相同的主干。
- InPL对于OOD例子的鲁棒性证明
我们从CIFAR10中每类采样4个标记的实例,并使用CIFAR10和SVHN的其余部分作为未标记的数据。
来自不同数据域的未标记实例存在于未标记集中。将InPL与基于置信度的方法UDA和FixMatch进行了比较。当大量OOD示例位于未标记集中时,两种方法的总体性能都会下降,但InPL显示出显著的优势。

表5:当在CIFAR10分类上训练模型时,来自SVHN的OOD样本出现在未标记集中时的结果。
(a)在未标记数据中类别不匹配的情况下的另一个OOD鲁棒性实验
(b)InPL在训练中始终包含较少的OOD示例。表明了InPL对真实异常值的鲁棒性。
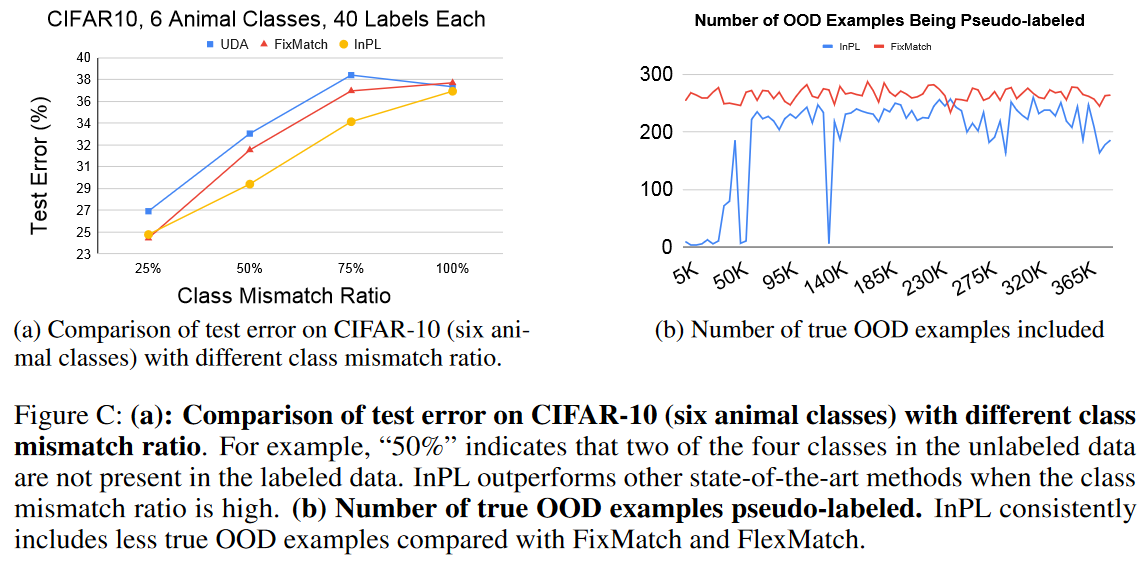
图C:(a):不同类别错配率的CIFAR-10(六个动物类别)的测试误差比较。例如,“50%”表示未标记数据中的四个类中有两个不存在于标记数据中。当类失配率高时,InPL优于其他最先进的方法。(b) 伪标记的真正OOD示例的数量。与FixMatch和FlexMatch相比,InPL始终包含更少真实的OOD示例
- 为什么InPL能很好地处理不平衡的数据?
对CIFAR10-LT提供了详细的伪标签精度和召回分析。在这里,我们将最频繁的三个类称为head类,将最不频繁的三种类称为tail类,将其余类称为body类。图4显示了我们模型预测的伪标签在所有类(a,c)以及尾部类(b,d)上的精度和召回率。头部和身体类别的分析见附录A.4(Fig B)。
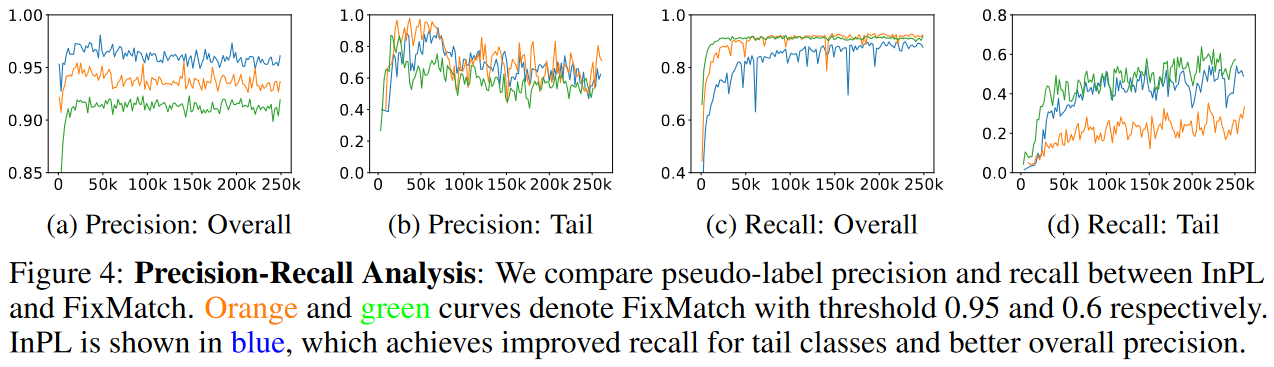
图4:精度-召回分析:我们比较了InPL和FixMatch之间的伪标签精度和召回率。橙色和绿色曲线分别表示阈值为0.95和0.6的FixMatch。InPL以蓝色显示,这提高了尾部类的召回率和更好的整体精度。
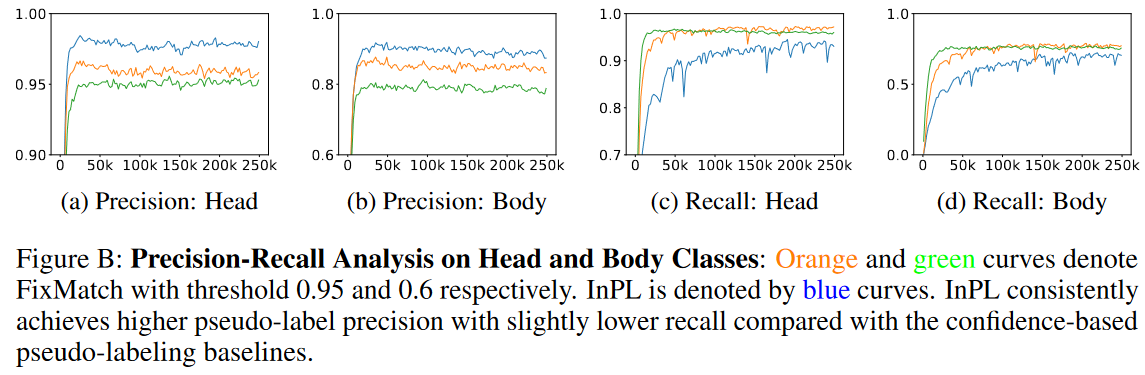
图B:head和body类别的精密召回分析:橙色和绿色曲线分别表示阈值为0.95和0.6的FixMatch。InPL由蓝色曲线表示。与基于置信度的伪标记基线相比,InPL始终以略低的召回率实现更高的伪标记精度。
- 消融实验
包括阈值和温度的选择、自适应margin损失

图A:消融研究:(A)和(b):不平衡率为100的CIFAR10-LT下,不同能量阈值对FixMatch框架和ABC框架的影响。对于ABC框架,使用ReMixmatch基础。(c) :在FixMatch框架下,能量函数中的温度参数对CIFAR10-LT的影响。
 > 表A:FixMatch与CIFAR10-LT上各种置信阈值的比较。使用一次10%的标记数据和具有相同随机种子的不平衡率100来生成结果。
> 表A:FixMatch与CIFAR10-LT上各种置信阈值的比较。使用一次10%的标记数据和具有相同随机种子的不平衡率100来生成结果。

表B: AML对ABC框架的影响
总结
- Conclusion
在这项工作中,我们提出了一种新的“分布内与分布外”的观点,用于不平衡SSL中的伪标记,以及我们基于能量的伪标记方法(InPL)。重要的是,我们的方法根据从模型输出中得出的未标记样本的能量分数来选择未标记样本进行伪标记。我们展示了我们的方法可以很容易地集成到最先进的不平衡SSL方法中,并取得了很好的效果。我们进一步证明,我们的方法对分布外的样本具有稳健性,并在平衡的SSL基准测试中保持竞争力。一个限制是能量分数缺乏可解释性;能量分数具有不同的尺度并且更难解释。设计更好地理解它的方法将是未来有趣的工作。总的来说,我们相信我们的工作已经表明了基于能源的方法对不平衡SSL的前景,并希望它将推动这方面的进一步研究。
Appendix
本文件通过描述对主要论文的补充:
(1)用于半监督学习的长尾数据集的构建(附录A.1);
(2) 主论文中每个实验的训练细节(附录A.2);
(3) 超参数选择的消融研究(附录A.3);
(4) 对伪标签进行更精确的召回分析(附录A.4);
(5) 具有不同阈值的FixMatch的前1准确性(附录A.5);
(6) 更多关于真实OOD示例在未标记集合中呈现的真实评估的结果(附录A.6);
(7) InPL中自适应裕度损失的贡献(附录A.7);
(8) 关于标准SSL基准的额外结果(附录A.8);
(9) 置信度得分与能量得分的理论比较。
我将附录内容和正文中相关的实验进行了归并
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- HarmonyOS—开发环境诊断的功能
- 基于node 安装express后端脚手架
- 打开这个地方,就能让你的手机网速提升好几倍,赶紧来试试!
- 【网站项目】基于jsp的个人交友网站源码
- 大数据之数据血缘采集方案(附代码示例)
- 算法训练第一天_Leetcode704二分查找27移除元素
- 洗车场洗车废水处理设备处理效果
- Kafka如何处理消费者之间的消息偏斜和负载均衡问题
- Python | 动态生成文件的绝对路径
- zabbix的API调用