OOD DCA视频异常检测中的分而治之:全面回顾和新方法
| paper | code |
|---|---|
| Divide and Conquer in Video Anomaly Detection: A Comprehensive Review and New Approach | 视频异常检测中的分而治之:全面回顾和新方法 |
????????摘要 — 视频异常检测是一项复杂的任务,“分而治之”原则通常被认为是解决复杂问题的有效方法。值得注意的是,最近的视频异常检测方法揭示了分而治之哲学的应用(尽管与传统用法截然不同),产生了令人印象深刻的结果。本文从六个维度系统地回顾了这些文献,旨在加强分而治之策略在视频异常检测中的应用。此外,基于从这篇综述中获得的见解,提出了一种将人体骨骼框架与视频数据分析技术相结合的新方法。该方法在上海科技大学数据集上实现了最先进的性能,超越了所有现有的先进方法。
介绍
????????本文旨在研究分而治之(DAC)方法在VAD领域的应用。近年来,DAC方法作为解决复杂问题的有效方法,在越来越多的关于VAD的文献中被发现。分而治之方法的基本概念是将一个问题分解为多个独立的子问题,分别解决每个子问题,然后合并结果以达到最终解决方案。由此,我们可以提供以下定义:
????????定义 1.在视频异常检测中,“分而治之”方法是指将问题沿特定维度分解为多个独立的子问题。每个子问题都根据其各自的维度独立提供异常分数/结果,然后合并这些分数/结果,以获得视频的总体异常分数/结果。
????????然而,需要澄清的是,本文所研究的VAD中的分而治之方法与传统方法不同,特别是在其划分子问题的角度上。在传统的分而治之方法中,重点通常放在问题的规模上,解决搜索和排序等基本任务。然而,VAD是一项复杂的任务,可以从多个角度划分为子问题,例如时间和空间维度,以及不同的模态。前者是指将问题分为时间异常检测和空间异常检测,每个子问题独立处理不同的信息。后者是指从原始视频数据中提取各种模态,例如RGB、光流和人体骨骼,将每种模态的处理视为一个单独的子问题。这种情况与多模态融合中的后期融合相对应[1]。
????????观察近年来VAD的研究,我们注意到越来越多的论文取得了出色的性能,证明了其方法设计中分而治之的方法。因此,我们认为合理应用分而治之方法可以提高异常检测性能(表I中各种参考文献中的“消融实验”证实了这一观点)。为了探索更有效的分而治之方法的应用方法,我们对采用分而治之方法的文献进行了回顾,重点关注如何从不同角度利用它来提高异常检测性能。认识到现有文献中采用分而治之方法的复杂性,我们引入了一种六维分类方法,该方法涵盖输入数据模态、训练焦点、建模过程、建模分支、输出数据模态和测试焦点。这使我们能够有效地对这些研究进行分类。此外,根据我们的综述结果,我们假设,当从模态角度划分子问题时,不同模态之间数据特征的显着差异应该导致不同的建模技术。不同模态之间数据特征的显著差异应导致每种模态采用不同的建模技术。通过充分利用每种模式数据的固有特征,并随后合并其结果,可以增强取得卓越成果的潜力。为了验证这一观点,我们引入了一种新的方法,该方法集成了两种具有代表性的现有方法:一种基于人类骨骼信息,称为STG-NF [12],另一种基于RGB数据,称为Jigsaw [10]。我们在四个数据集上进行了实验,以全面评估我们提出的方法的优势和局限性。
????????本文的贡献总结如下:
????????1.在VAD领域内建立分而治之方法的定义,并对VAD文献进行全面回顾,从六个不同维度证明这种方法的应用。
????????2.借鉴审查结果,从基于模式的划分的角度提出“通过汇总不同模式的结果,同时充分利用其个人数据,可能实现卓越结果”的观点。
????????3.为了验证上述观点,设计了一种融合了植根于人体骨骼信息和RGB数据的技术的新方法。该方法在上海科技大学[13]数据集上的AUC得分为87.72,超过了目前所有最先进的方法。
TAXONOMY(分类学,生物分类法)
????????鉴于视频异常检测任务的复杂性,不同的方法在采用分而治之的方法时表现出不同的策略。为了系统地对现有方法中的分而治之策略进行分类,我们引入了一种六维分类方案。
????????1.输入数据模态:输入数据是否包含多个模态。
????????2.训练重点:训练数据是否由不同的实体组成。
????????3.建模过程:是否采用明显不同的建模技术对输入数据进行建模。
????????4.建模分支:建模过程中的分支数。
????????5.输出数据模态:输出数据是否包含多个模态。
????????6.测试重点:测试数据是否涉及不同的实体。
????????汇总结果如表 I 所示,其中,除了从自然数集中获取值的“建模分支”维度外,其他维度的值为 0 或 1。在这种情况下,0 表示否定,类似于“否”,而 1 表示肯定,类似于“是”。

????????从表I可以看出,目前关于根据数据模式或根据训练测试焦点将问题划分为子问题的文献很少,分别只有参考文献[9]和[6]。此外,我们注意到,该方法[9]采用基于数据模态的分而治之的策略,在三个常用数据集上实现了最高或接近最高的性能,如表III所示。经过分析[9],很明显,它没有使用过于复杂的建模技术,而完全依赖于简单的方法,如高斯混合模型(GMM)和K最近邻模型(KNN)进行建模。因此,我们将其性能改进归因于模态分而治之方法的使用。不同的数据模式对异常表现出不同程度的敏感性(捕获异常的难度)。只要识别出每个相应模态中易于检测的异常,融合来自不同模态的异常检测结果就可以获得更全面的异常检测结果。基于此,我们认为,通过使用精心设计的模型对单模态数据进行彻底探索,有可能进一步提高模型的异常检测性能。为了验证这一假设,我们采用了一种基于模态的分而治之的方法,提出了一种将基于人体骨骼的方法与基于RGB数据的方法相结合的新方法。
方法
A. 概述

????????图1 - 方法概述:该方法由两个分支组成。一个分支使用通过目标检测机制处理的视频数据进行异常识别,而另一个分支则利用骨骼数据建模进行异常检测。最终,将两个分支的结果进行集成聚合,以得出最终的异常检测结果。
????????为了验证本文提出的观点,我们从模态角度划分问题,将其分为两个子问题:基于人体骨骼结构的视频异常检测和基于RGB数据的视频异常检测。为了充分挖掘单模态数据的潜力,我们选择了两种近年来表现出卓越性能的方法:依赖于RGB数据的Jigsaw[10]和基于骨骼数据的STG-NF [12]。由于篇幅所限,我们对这两种方法进行了概述。整体框架如图 1 所示。
B. 基于RGB的方法
????????该方法采用归一化流程来估计人类骨骼数据的密度,从而生成用于异常检测的对数似然分数。基本假设是正常个体驻留在高密度区域,而异常存在于低密度区域。该方法包括三个步骤:1)骨架序列提取:给定一个视频,首先使用AlphaPose[14]提取骨骼数据。然后,应用OSNet [15]跟踪来获取一系列人类骨骼数据。最后,将此序列划分为固定时间段。2) 建模骨架序列:将这些骨架序列段输入到时空图归一化流中,以便直接建模并输出相应的对数似然分数。3) 获取异常分数:从每帧内的每个骨骼序列片段中选择最小对数似然分数作为该帧的异常分数。有关详细信息,请参阅参考文献 [12]。
C. 基于骨架的方法
????????这种方法采用自监督学习框架,通过解决时空拼图游戏来检测异常情况。该方法包括三个步骤:1)构建时空立方体:给定一个视频,首先利用YOLOv3[16]在每一帧中进行前景对象检测,生成一系列边界框。然后,对于帧及其相邻帧中的每个检测到的对象,根据对象的边界框提取一系列图像图块。这些图像块的大小被调整为固定大小,并沿时间维度堆叠,形成以对象为中心的时空立方体。2)解谜:将每个时空立方体的时间或空间维度洗牌,并将它们输入到一个完全卷积的网络中,以重建立方体的正确序列。3) 获取异常分数:从每帧内的每个时空立方体中选择最小异常分数作为该帧的异常分数。有关详细信息,请参阅参考文献 [10]。
D. 异常分数
????????由于基于骨骼的方法只能检测与人类相关的异常,而基于RGB的方法可以检测与人类相关和不相关的异常,因此我们设计了两种融合方法(取决于测试的不同重点):
- STG-NF 检测与人类相关的异常,而 Jigsaw 检测与人类无关的异常。
- STG-NF 检测与人类相关的异常,而 Jigsaw 检测与人类相关的和非与人类相关的异常。
????????具体来说,这意味着当 Jigsaw 仅检测到与人类无关的异常时,人类的边界框是人类的边界框将从测试数据集中删除。从两个分支获得异常分数后,将它们的值相加以产生最终的异常分数。

实验
A. 实验环境
????????a) 数据集:为了全面测试我们方法的性能,我们选择了四个具有不同特征的数据集进行实验。一些示例如图 2 所示。
????????UCSD Ped2 [17]:这个单场景行人数据集在密集的人群中捕捉远处的摄像机镜头,包括滑板、骑自行车和大型卡车等异常情况。其独特特征包括小型目标和拥挤的环境。
????????香港中文大学大道 [18]:这个单场景数据集以校园环境为背景,捕捉了突然奔跑、扔包和嬉戏行为等异常情况。该数据集值得注意的方面是正面摄像头角度、相对密集的人群和明显的遮挡。
????????上海科技大学[13]:一个包含13个不同场景的多场景校园数据集,它既包括与人类相关的异常,如跳跃和骑自行车,也包括与人类无关的异常,如大型车辆的存在。值得注意的功能包括不同的场景、角度、照明条件和较少的人群遮挡实例。
????????UBnormal [19]:这个合成生成的多场景数据集包括 29 个场景,包含 22 种异常类型和 660 个事件。该数据集提出了极具挑战性的异常情况,例如违反交通规则、睡眠和盗窃。它的独特之处在于场景的多样性(包括雾和烟雾条件)和广泛的异常类别。
????????b) 评估指标:为了评估模型的性能,本研究采用帧级 Micro-AUC [20](ROC 曲线下面积)作为主要衡量标准。具体来说,这涉及按顺序连接测试集中所有视频的帧并计算 AUC。值越高表示模型性能越好。
????????c) 实施细节:Jigsaw 和 STG-NF 论文并不能提供所有四个数据集的完整结果。因此,对于缺失的结果,我们使用他们的开源代码进行了补充实验,结果如表III所示。为在UBnormal数据集上进行实验,Jigsaw的过滤器设置为0.8,样本长度为9。STGNF 对 Ped2 和 Avenue 数据集进行了实验,两者的分割长度均设置为 24。其他参数与[10]和[12]中引用的原始论文保持一致。在人类缺席的情况下,异常分数设置为 0,例如在 Ped2 的最后两个测试视频中。
B. 实验结果与分析
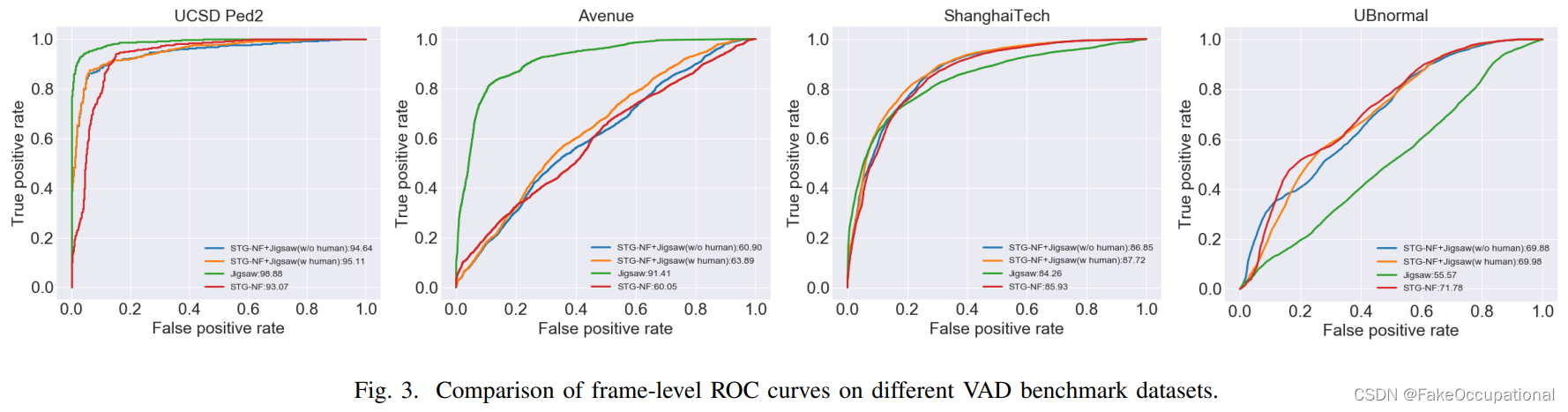
????????我们对本文提出的方法与其他 18 种最先进的方法进行了全面比较,无论它们是否采用分而治之的策略。比较结果列于表三,排名前两位的表现以粗体突出显示。此外,我们在图 3 中描绘了帧级 ROC 曲线。值得注意的是,与所有其他先进技术相比,本研究中引入的方法在上海科技大学数据集上表现出显着的性能提升,实现了令人印象深刻的 87.73% 的 AUC。据我们所知,这是上海科技大学数据集上有史以来最出色的表现。然而,必须承认,与预融合拼图和STG-NF方法相比,融合方法仅在上海科技大学数据集上表现出性能优势。在其余三个数据集(Ped2、Avenue 和 UBnormal)上,融合方法未能超越原始性能。深入研究根本原因,我们认为这种观察到的现象与我们的猜想完全一致。当不同的建模方法应用于不同的数据模式时,只有对每种模式的信息进行彻底探索,才有可能通过模态聚合实现增强的结果。如果至少一种方法表现出低于标准的性能,则随后的结果融合可能会不理想。详细地说,合并后的结果之所以能够在上海科技大学数据集上表现出色,是因为合并前的方法(Jigsaw和STG-NF)的单独表现值得称赞,分别为84.26%和85.93%。 相比之下,在其他数据集上,Jigsaw 或 STG-NF 都存在明显较差的实例,例如 STG-NF 在 Ped2 上为 93.07%,在 Avenue 上为 60.05%,或 Jigsaw 在 UBnormal 上为 55.57%。
????????两种方法之间的巨大性能差异主要归因于数据集的特征,如数据集部分所述。在 Ped2 和 Avenue 数据集中,密集的人群场景和大量的遮挡阻碍了密集的人群场景和大量的遮挡阻碍了对人类骨骼的成功检测和追踪。在UBnormal数据集上,异常类型的动态场景和丰富的语义信息使得在不依赖粗粒度视觉线索的情况下有效检测异常具有挑战性。此外,我们在上海科技大学数据集上可视化了三种方法性能不佳的实例,如图 4 所示。第一行展示了各个视频中的关键帧,而下一行(从左到右)展示了 STG-NF、Jigsaw 和我们提出的方法在相应视频上的异常检测结果。从这些图例中可以明显看出,一旦异常变得微妙,所有三种方法的检测都会动摇。这凸显了我们的方法中采用的分而治之的策略不是最优的,因此需要探索卓越的建模技术和分区策略。
????????最后,在比较本研究中设计的两种融合方法后,很明显,在所有数据集中,Jigsaw在检测所有异常方面的性能超过了其在单独检测非人类相关异常方面的性能。这意味着对于涉及人类的异常在STG-NF和拼图检测结果的融合产生了互补的信息。然而,这也意味着STG-NF对骨骼数据的探索并不详尽。
总结
????????在本文中,我们从六个角度全面回顾了视频异常检测领域采用分而治之方法的最新研究。基于此,我们提出了“具有显着特征差异的不同模态应该以不同的方式建模,并且通过充分利用单个模态信息,汇总每个模态的结果应该会产生更好的结果。为了验证这一点,在四个数据集上进行了实验,该观点在上海科技大学数据集上得到了初步确认,所提方法在上海科技大学数据集上取得了最先进的性能。请注意,我们的主要贡献不是来自提出一种全新的方法,而是来自提出一种关于VAD的新观点——采取分而治之的方法。我们真诚地希望我们的工作能够有益于该领域的未来研究。
????????
????????
????????
????????
????????
????????
????????
????????
????????
????????
????????
????????
????????
????????
????????
????????
????????
????????
????????
CG
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 软件测试|使用Python绘制小提琴图
- 化妆刷适合用超声波清洗机洗吗?超声波清洗机可以洗什么物品?
- 云服务器ECS_GPU云服务器_AIGC_弹性计算-阿里云
- Java工具类——json字符串格式化处理
- Ubuntu20.04安装ROS2 Foxy
- Invalid bound statement (not found): com.itheima.mapper.UserMapper.selectAll
- 外汇天眼:Options与OneTick合作,共同打造全球SAAS分析平台
- PHP中excel带图片数据导入
- UML中的实现关系
- 【没有哪个港口是永远的停留~论文解读】Polarized Self-Attention