如何本地部署虚拟数字克隆人 SadTalker
环境:
Win10
SadTalker
问题描述:
如何本地部署虚拟数字克隆人 SadTalker

解决方案:
SadTalker:学习逼真的3D运动系数,用于风格化的音频驱动的单图像说话人脸动画
单张人像图像🙎 ♂?+音频🎤=会说话的头像视频🎞
一、底层安装
安装 Anaconda、python 和 git
1.下载安装Anaconda
conda是一个开源的软件包管理系统和环境管理系统,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。 conda是为 python程序创建的,适用于 Linux,OS X和Windows,也可以打包和分发其他软件。conda分为Anaconda和MiniConda。Anaconda是包含一些常用包的版本,Miniconda则是精简版,一般建议安装Anaconda,本文也以安装Anaconda为例
 next一直往下直到完成(需要一点时间)
next一直往下直到完成(需要一点时间)
2.安装Git
next一直往下直到完成
3.安装python
next一直往下直到完成
二、创建环境并安装需求
D盘新建SadTalker文件夹
1.git再这里打开
2.安装 ffmpeg
下载 ffmpeg-6.1-full_build,解压到D:\SadTalker\
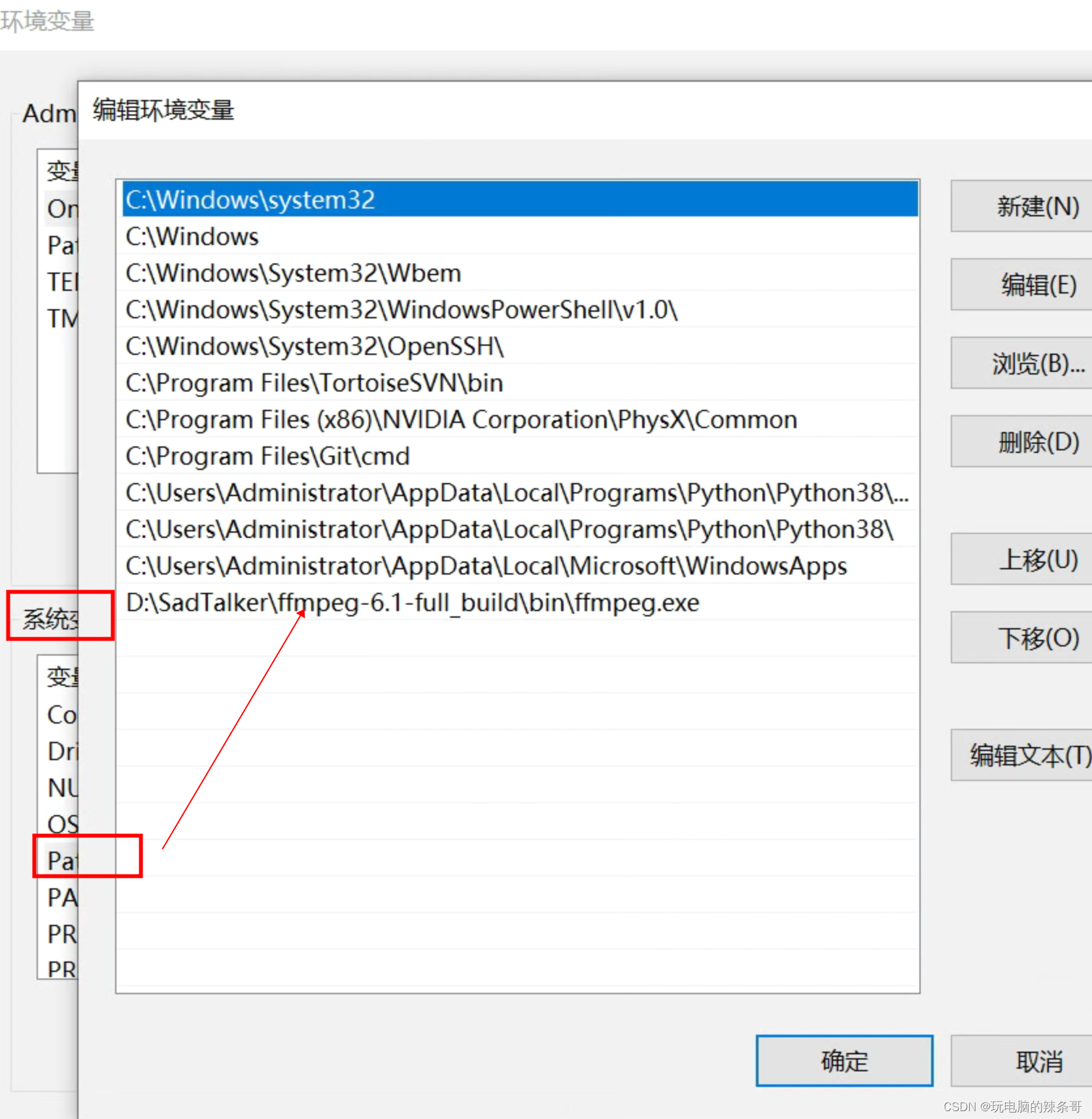
cmd设置环境变量
setx path "%path%;D:\SadTalker\ffmpeg-6.1-full_build\bin\ffmpeg.exe" /M
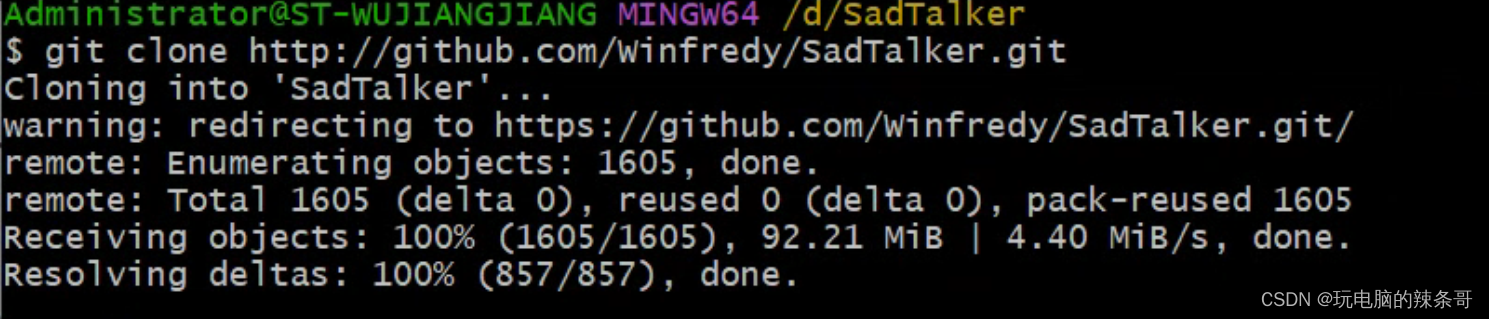
3.通过运行 git clone https://github.com/Winfredy/SadTalker.git 下载 SadTalker 存储库
git clone https://github.com/Winfredy/SadTalker.git
失败
 去掉https后面s
去掉https后面s
git clone http://github.com/Winfredy/SadTalker.git
5.在下载部分下载检查点和 gfpgan 模型。
Run start.bat from Windows Explorer as normal, non-administrator, user, and a Gradio-powered WebUI demo will be started.
从Windows资源管理器正常运行 start.bat ,非管理员,用户和Gradio驱动的WebUI演示将启动。
三、下载模型
Pre-Trained Models 预训练模型
1.checkpoints
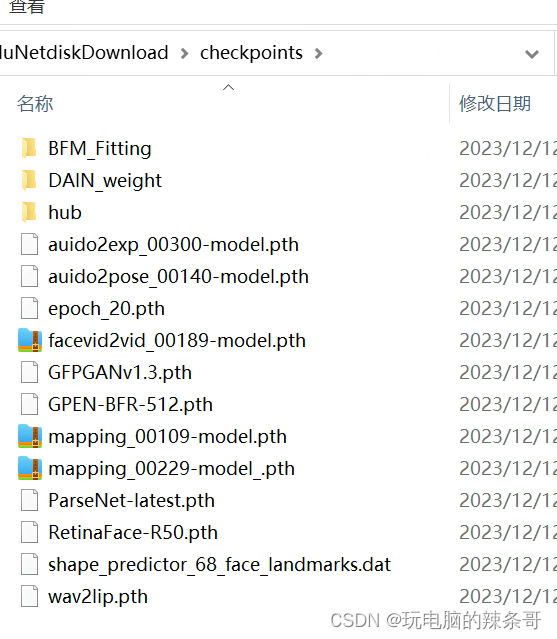
移到到SadTalker文件夹
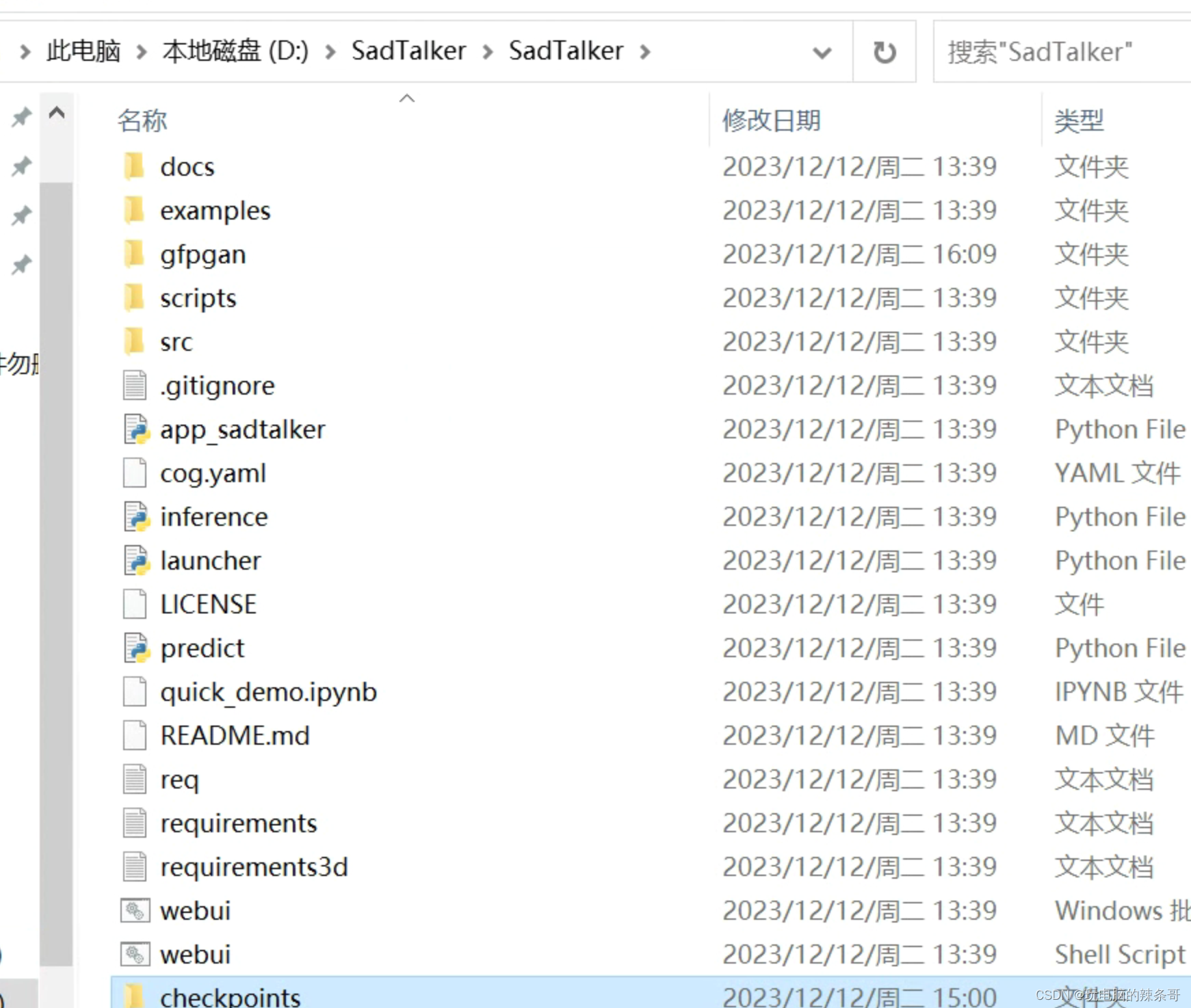
2.GFPGAN Offline Patch GFPGAN 离线补丁
解压到SadTalker文件夹
四、Quick Start 快速上手
1.打开SadTalker目录,点击webui.bat等待安装部署
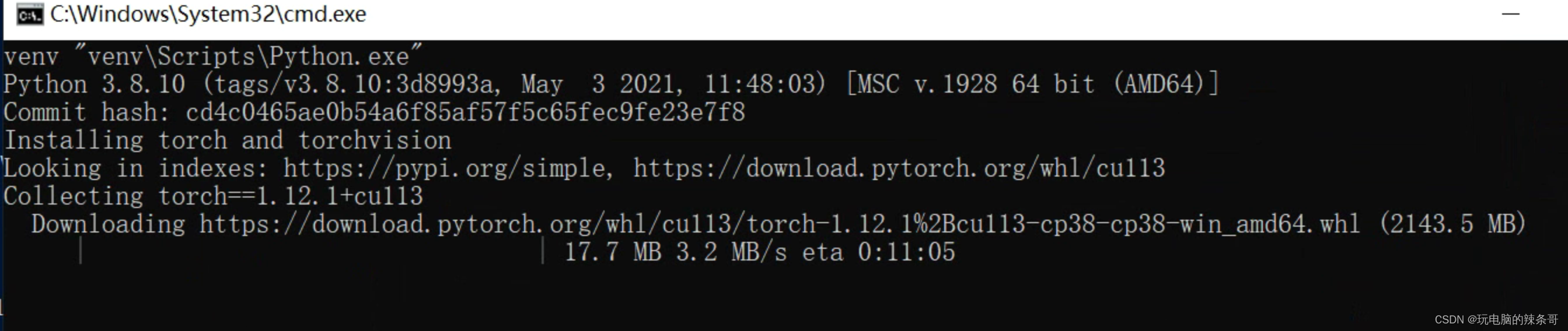
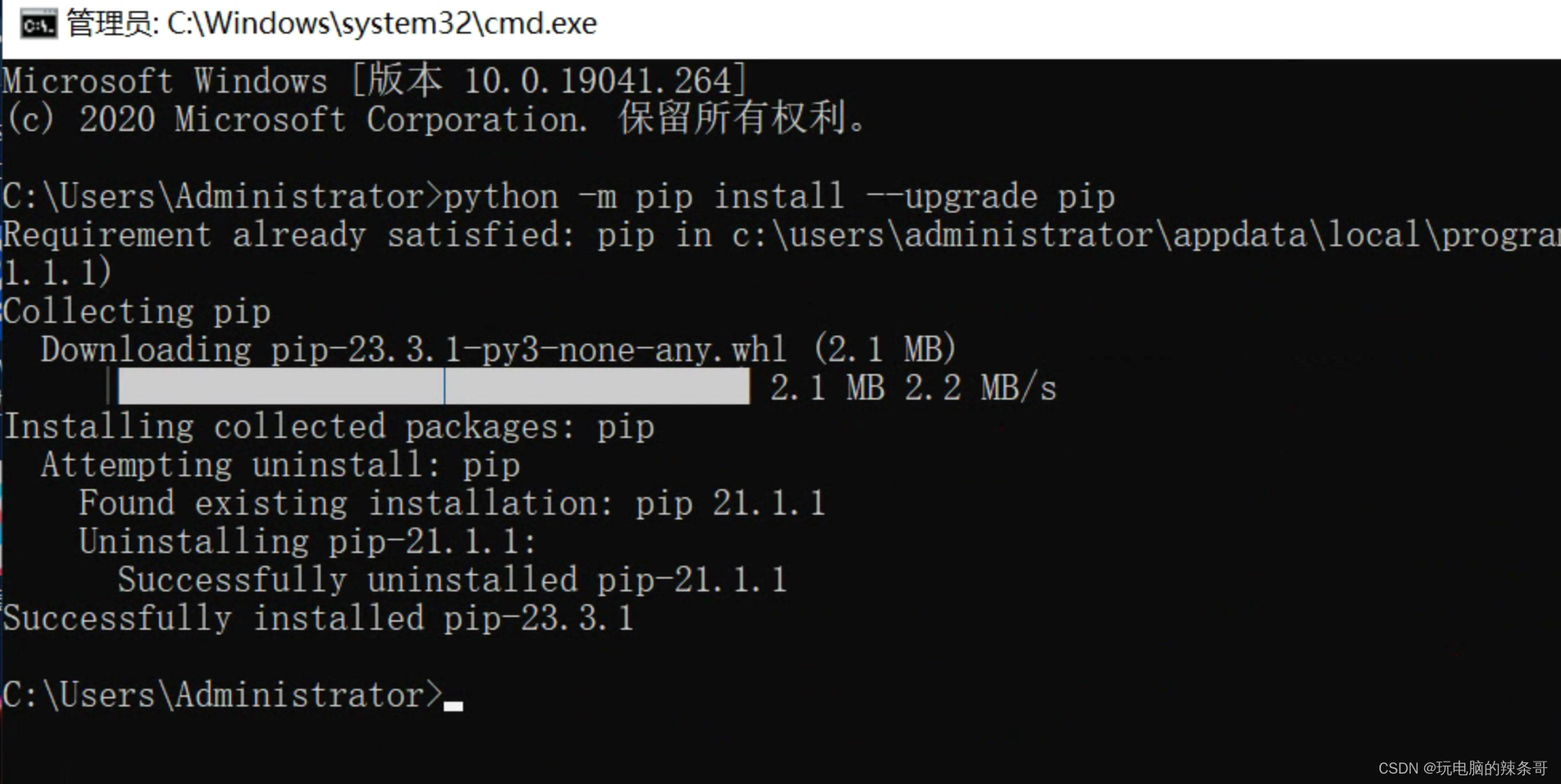
中途报错
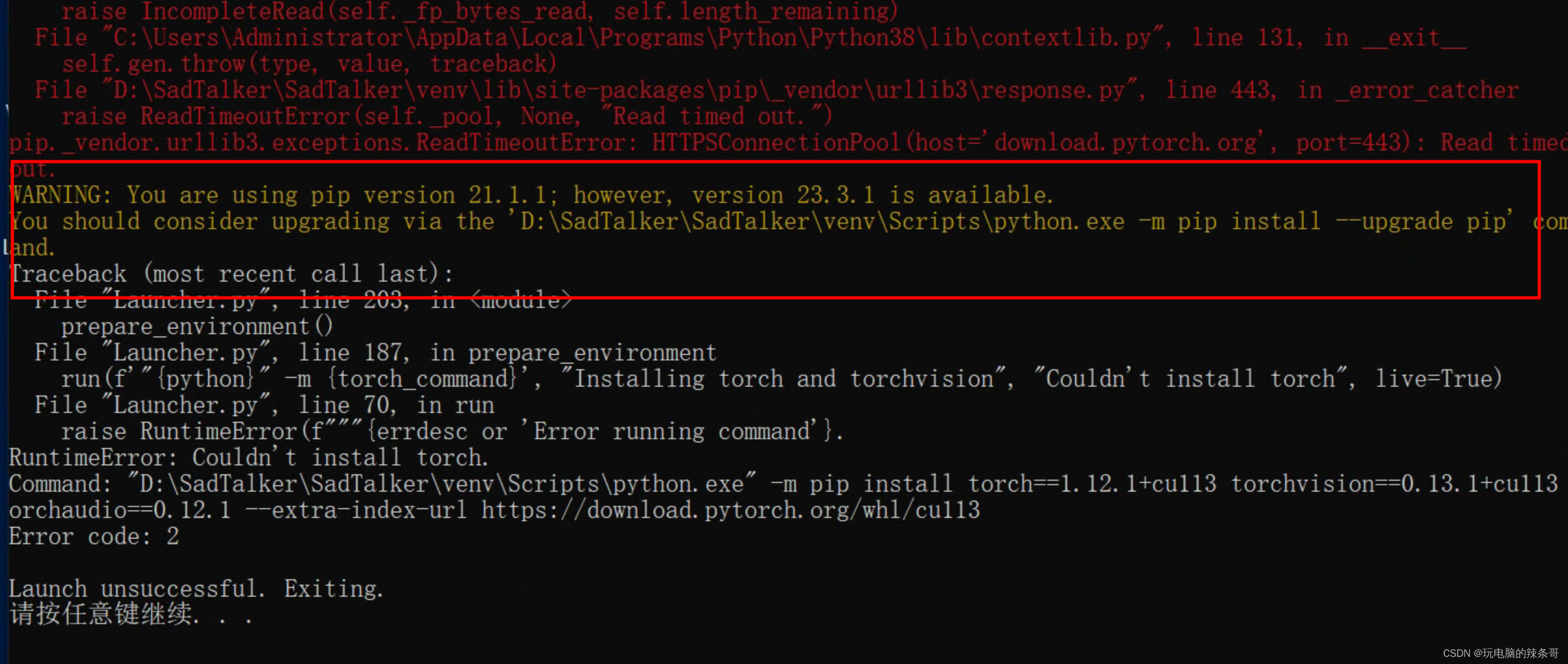 升级一下
升级一下
python -m pip install --upgrade pip
下载相关文件
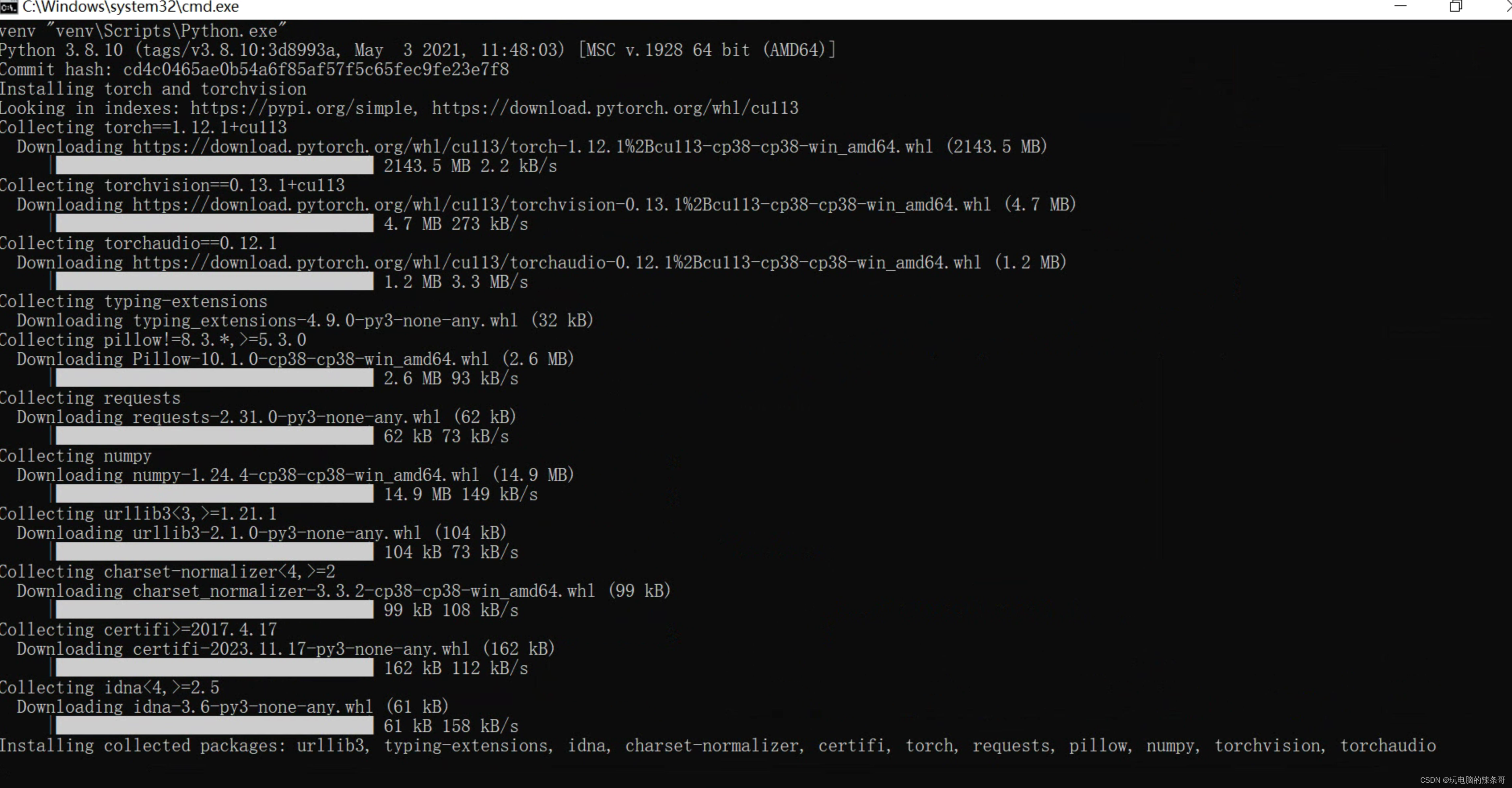 首次使用,自动安装
首次使用,自动安装

就好了,最终看到这个界面
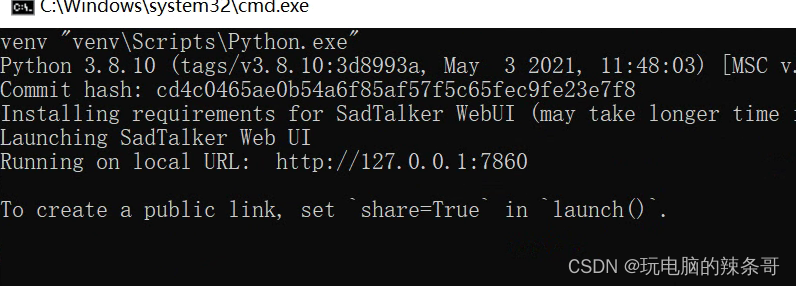
浏览器访问http://127.0.0.1:7860即可
CLI usage CLI 用法
Animating a portrait image from default config:
从默认配置对人像图像进行动画处理:
python inference.py --driven_audio <audio.wav> \
--source_image <video.mp4 or picture.png> \
--enhancer gfpgan
The results will be saved in results/$SOME_TIMESTAMP/*.mp4.
结果将保存在 results/$SOME_TIMESTAMP/*.mp4 中。
Full body/image Generation:
全身/图像生成:
Using --still to generate a natural full body video. You can add enhancer to improve the quality of the generated video.
用于 --still 生成自然的全身视频。您可以添加 enhancer 以提高生成的视频的质量。
python inference.py --driven_audio <audio.wav> \
--source_image <video.mp4 or picture.png> \
--result_dir <a file to store results> \
--still \
--preprocess full \
--enhancer gfpgan
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 发明专利如何挖掘
- 理解 JavaScript 中构造函数、原型、实例、原型链之间的关系
- 【并发编程】Park & Unpark 你看看不亏
- 丢掉破解版,官方免费了!!!
- 2024年【危险化学品经营单位主要负责人】考试报名及危险化学品经营单位主要负责人考试资料
- Python输入输出流学习笔记
- 详解Med-PaLM 2,基于PaLM 2的专家级医疗问答大语言模型
- 佳成智能授权世强硬创代理,光栅产品可有效屏蔽99%干扰信号
- 十分钟带你学会用python3网络爬虫抓取猫眼电影排行!
- Redis为什么那么快?