Java集合
本章目标:
-
集合层次结构
-
Collection接口
-
List ArrayList LinkedList Vector
-
Set HashSet TreeSet LinkedHashSet
-
Map
本章内容
一、层次结构
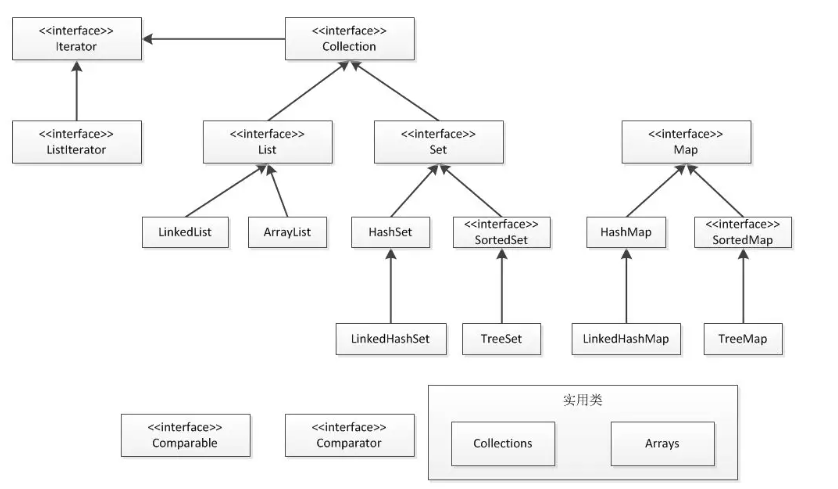
1、Collection:以单个元素为单位进行存放
-
List:有序集合,每个元素都有一个和存入顺序吻合的索引编号,并且,我们可以依靠位置编号对集合中的元素进行操作
-
ArrayList:实现类
-
LinkedList
-
Vector
-
-
Set:无序集合,每个元素没有位置编号,程序员也不能用位置编号对集合中的元素进行操作,不能存入重复值
-
HashSet
-
LinkedHashSet
-
-
TreeSet
-
2、Map:以键值对为单位进行存放
-
HashMap
LinkedHashMap
-
TreeMap
-
Hashtable
二、Collection
存放若干个独立元素
增加操作
?boolean add(Object element) :增加一个元素
?boolean addAll(Collection collection) :将集合中的所有元素进行增加
移除操作
?boolean remove(Object element) :移除一个元素,依靠equals方法进行 比对。注意。你的元素类型有没有重写equals方法,如果有重写,那就调用重写过的equals,没有重写,调用Object类的equals
void clear() :清空所有元素
?void removeAll(Collection collection):将在集合中的元素移除, 依靠equals方法进行 比对
?void retainAll(Collection collection) :将不在集合中的元素移除, 依靠equals方法进行 比对
查询操作:
?int size() :集合实际元素的个数
?boolean isEmpty() :判断集合是否为空
?boolean contains(Object element) :判断集合中有没有包含一个元素
?boolean containsAll(Collection collection) :判断集合中有没有包含另一个集合中的元素
?Iterator iterator() :得到迭代器
三、List
数据结构:
逻辑存储结构
线性的:每个元素有0或者1个前驱元素,有0个或者1个后继元素
树结构:每个元素有一个或0个前驱元素,有0个多个后继元素
图结构:每个元素有多个或0个前驱元素,有0个多个后继元素
物理存储结构
线性存储:元素在内存中是连续存放的
链式存储:元素在内存中不是连续存放的
List: 有序集合,可以放入重复(equals进行判断)元素,会按照存入的顺序给每个元素编号,遍历的时候也可以依靠编号进行遍历
void add(int index, Object element): 在指定位置index上添加元素element boolean addAll(int index, Collection c): 将集合c的所有元素添加到指定位置index Object get(int index): 返回List中指定位置的元素 int indexOf(Object o): 返回第一个出现元素o的位置,否则返回-1 int lastIndexOf(Object o) :返回最后一个出现元素o的位置,否则返回-1 Object remove(int index) :删除指定位置上的元素 Object set(int index, Object element) :用元素element取代位置index上的元素,并且返回旧的元素
注意:比较对象是按照equals来进行比较的
以下为List接口下的方法使用实例
1、ArrayList
-
常用API
构造方法
List<String> l=new ArrayList<>(l1);//参数为一个集合 new ArrayList<>(5);//数组的初始容量为5 new ArrayList<String>();//数组的初始容量为10
-
底层:底层是一个Object类型的数组,初始的默认长度10,也可以指定长度,初始长度如果满了,底层进行自动扩容,扩容为原来的1.5倍oldCapacity + (oldCapacity >> 1)。10—->15—->22,如果对集合中的元素个数可以预估,那么建议预先指定一个合适的初始容量,可以减少扩容的次数
List l =new ArrayList();
线程不安全,性能高。
-
优点:查找效率高,向末尾添加、删除元素也可以
-
缺点:增加 、删除牵扯到数组的扩容和移动,效率低
2、LinkedList:
-
常用API:
-
构造方法
LinkedList():无参数
LinkedList(Collection c):带集合类型的参数
-
其他方法(实现类独有的方法)
addFirst:给链表头添加元素
addLast:给链表末尾添加元素
LinkedList<String> l =new LinkedList(); //new LinkedList<String>(); l.add("11111"); l.add("22222"); l.addLast("44444"); l.add("55555"); l.addFirst("33333"); for(String e:l){ System.out.println(e); }
-
-
底层是一个链表(双向)结构,添加的元素和前后元素的地址信息会封装成一个Node类型的对象,放到集合中,不是线性存储,内存中是链式存储,不连续的空间。
以下为Node类型的源代码
private static class Node<E> { ? ? ? ?E item; ? ? ? ?Node<E> next; ? ? ? ?Node<E> prev; ? ? ? ?Node(Node<E> prev, E element, Node<E> next) { ? ? ? ? ? ?this.item = element; ? ? ? ? ? ?this.next = next; ? ? ? ? ? ?this.prev = prev; ? ? ? } ? } -
优点:增加、删除效率高
-
缺点:查找效率低
3、Vector
-
常用API
构造方法
Vector()
Vector(初始容量)
Vector((初始容量,扩容数量)
向向量序列中添加元素
addElement(Object obj)
insertElementAt(Object obj, int index)
修改或删除向量序列中的元素
Void setElementAt(Object obj, int index)
boolean removeElement (Object obj)
Void removeElementAt (int index)
Void removeAllElements ()
查找向量序列中的元素
Object elementAt(int index)
boolean contains (Object obj)
int indexOf (Object obj, int start_index)
int lastIndexOf (Object obj, int start_index)
-
底层是一个Object类型的数组,初始的默认长度为10,默认扩容的时候扩容为原来的2倍 ,如果自己指定扩容的长度,那么就是就容量加指定的,如果没有指定,就是旧容量的2倍。
-
线程安全,性能低
4、对照区别
-
ArrayList和LinkedList的区别:底层结构 优点 缺点
-
ArrayList和Vector的区别:底层结构 扩容方式 线程安全
四、Set
无序集合(输出的顺序与添加的顺序不一致),存入的元素在逻辑上没有位置编号,也不能依靠编号去操作元素
1、HashSet
-
常用API:
增加操作 ?boolean add(Object element) :增加一个元素 ?boolean addAll(Collection collection) :将集合中的所有匀速进行增加 移除操作 ?boolean remove(Object element) :移除一个元素,依靠equals方法进行 比对 void clear() :清空所有元素 ?void removeAll(Collection collection):将在集合中的元素移除, 依靠equals方法进行 比对 ?void retainAll(Collection collection) :将不在集合中的元素移除, 依靠equals方法进行 比对 查询操作: ?int size() :集合实际元素的个数 ?boolean isEmpty() :判断集合是否为空 ?boolean contains(Object element) :判断集合中有没有包含一个元素 ?boolean containsAll(Collection collection) :判断集合中有没有包含另一个集合中的元素 ?Iterator iterator() :得到迭代器
-
特点
-
输出是无序的:和存入顺序不一定一致
-
不能放入重复元素:两个对象用equals方法比较返回true,并且两个对象拥有相同的哈希码,也就是hashCode方法要有相同的返回值
-
可以放入null元素
-
HashSet的典型应用场景就是去除重复元素
-
-
底层存储结构:
HashSet的底层是一个HashMap,只是将HashMap中的值设置为一 个常量,用所有的键组成了一个HashSet
2、LinkedHashSet: HashSet的子类,底层有一个链表结构,按照添加顺序维护顺序 ,输出顺序和存入顺序是一致的
3、TreeSet
-
常用api
增加操作 ?boolean add(Object element) :增加一个元素 ?boolean addAll(Collection collection) :将集合中的所有匀速进行增加 移除操作 ?boolean remove(Object element) :移除一个元素,依靠equals方法进行 比对 void clear() :清空所有元素 ?void removeAll(Collection collection):将在集合中的元素移除, 依靠equals方法进行 比对 ?void retainAll(Collection collection) :将不在集合中的元素移除, 依靠equals方法进行 比对 查询操作: ?int size() :集合实际元素的个数 ?boolean isEmpty() :判断集合是否为空 ?boolean contains(Object element) :判断集合中有没有包含一个元素 ?boolean containsAll(Collection collection) :判断集合中有没有包含另一个集合中的元素 ?Iterator iterator() :得到迭代器
-
特点
-
输出有序(排序输出)
-
不能放入null对象
-
不能放入重复对象(比较对象的大小,如CompareTo方法的返回值为0)
-
TreeSet的典型应用场景就是自带排序功能
-
-
自然排序
new TreeSet();
要求元素对应的类型实现Comparable接口,调用Treeset的无参数构造的时候采用自然排序的方式
public class Cat implements Comparable<Cat>{ ? ?private String catName; ? ?private int catAge; ? ?public Cat() { ? ? ? ?// TODO Auto-generated constructor stub ? } ? ?public Cat(String catName, int catAge) { ? ? ? ?super(); ? ? ? ?this.catName = catName; ? ? ? ?this.catAge = catAge; ? } ? ?public String getCatName() { ? ? ? ?return catName; ? } ? ?public void setCatName(String catName) { ? ? ? ?this.catName = catName; ? } ? ?public int getCatAge() { ? ? ? ?return catAge; ? } ? ?public void setCatAge(int catAge) { ? ? ? ?this.catAge = catAge; ? } ? ?@Override ? ?public String toString() { ? ? ? ?return "Cat [catName=" + catName + ", catAge=" + catAge + "]"; ? } ? ?@Override ? ?public int compareTo(Cat o) { ? ? ? ?// TODO Auto-generated method stub ? ? ? ?return this.catAge-o.catAge; ? } } public class CatTreeSetTest { ? ?public static void main(String[] args) { ? ? ? ?Set<Cat> s = new TreeSet<Cat>(); ? ? ? ?s.add(new Cat("heimao",2)); ? ? ? ?s.add(new Cat("baimao",3)); ? ? ? ?s.add(new Cat("haomao",1)); ? ? ? ?for(Cat c:s){ ? ? ? ? ? ?System.out.println(c); ? ? ? } ? } } -
比较器排序(Comparator):
new TreeSet(Comparator com);
单独实现一个比较器类,比较器类实现Comparator接口,重写compare(o1,o2)方法.然后创建Treeset的时候将比较器作为构造方法的参数传入,不要求元素类型实现Comparable接口
public class Stu { ? ?private String name; ? ?private int age; ? ?public Stu() { ? ? ? ?// TODO Auto-generated constructor stub ? } ? ?public Stu(String name, int age) { ? ? ? ?super(); ? ? ? ?this.name = name; ? ? ? ?this.age = age; ? } ? ?public String getName() { ? ? ? ?return name; ? } ? ?public void setName(String name) { ? ? ? ?this.name = name; ? } ? ?public int getAge() { ? ? ? ?return age; ? } ? ?public void setAge(int age) { ? ? ? ?this.age = age; ? } ? ?@Override ? ?public String toString() { ? ? ? ?return "Stu [name=" + name + ", age=" + age + "]"; ? } } public class StuSetTest { ? ?public static void main(String[] args) { ? ? ? ?Set<Stu> s = new TreeSet<>((o1,o2)->o2.getAge()-o1.getAge()); ? ? ? ?s.add(new Stu("zs", 1)); ? ? ? ?s.add(new Stu("zs", 2)); ? ? ? ?s.add(new Stu("zs", 2)); ? ? ? ?for(Stu e:s){ ? ? ? ? ? ?System.out.println(e); ? ? ? } ? } } -
判断重复元素的依据 compareTo或者compare方法的返回值进行比较排序,方法如果返回0,认为两个对象是相等的,不会重复存储。
-
存储结构:TreeSet的底层是用TreeMap进行实现,TreeMap中所有的键构成了TreeSet.
五、Map
存放键值对
1、常用的API
-
put(key,value)
-
get(key)
-
keySet():得到所有的键,返回Set
-
values():得到所有的值,返回Collection
-
entrySet():Set>,HashMap底层将每一个键值对封装为Entry类型的对象
-
containsKey(key): 判断key是否存在 注意查找依据
-
containsValue(value)::注意查找依据
-
size():键值对的个数
-
remove(key):根据键移除键值对
api实例代码
HashMap<String,String> m = new HashMap<String,String>(); //存放键值对 m.put("002", "22222"); m.put("001", "11111"); m.put("003", "33333"); m.put("004", "44444"); m.put(null, "44444"); m.put(null, "55555"); m.put(null, null); //依靠键找值 //System.out.println(m.get("001")); //获取所有的键 Set<String> keys = m.keySet(); for(String key:keys ){ System.out.println(key); } //获取所有值 Collection<String> values = m.values(); for(String v:values){ System.out.println(v); } //键和值一起获取(Map集合会将put的每一个键值对封装为一个Entry类型的对象) Set<Entry<String, String>> entrySet=m.entrySet(); for(Entry<String, String> es:entrySet){ System.out.println(es.getKey()+"==="+es.getValue()); } //判断有没有包含一个键(equals hashcode) System.out.println(m.containsKey("001")); //判断是否包含某一个值 System.out.println(m.containsValue("11111")); //有几个键值对 System.out.println(m.size()); //依靠键移除键值对 m.remove("001"); System.out.println(m.size());
2、HashMap特点
可以放入NULL值,NULL键
不能放入重复键(依靠equals和hashcode进行判断)
键是无序的(所有的键构成了一个hashSet)
底层结构:数组加链表|数组加红黑树,数组的默认容量为16,当数组的元素个数达到16*扩容因子(0.75)的进行扩容,扩容为原来的2倍之后,要重新进行hash运算,重新放置元素
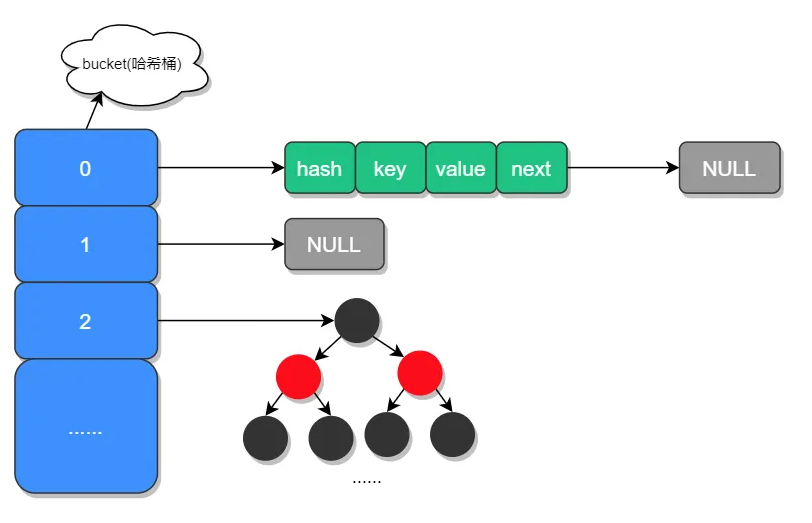
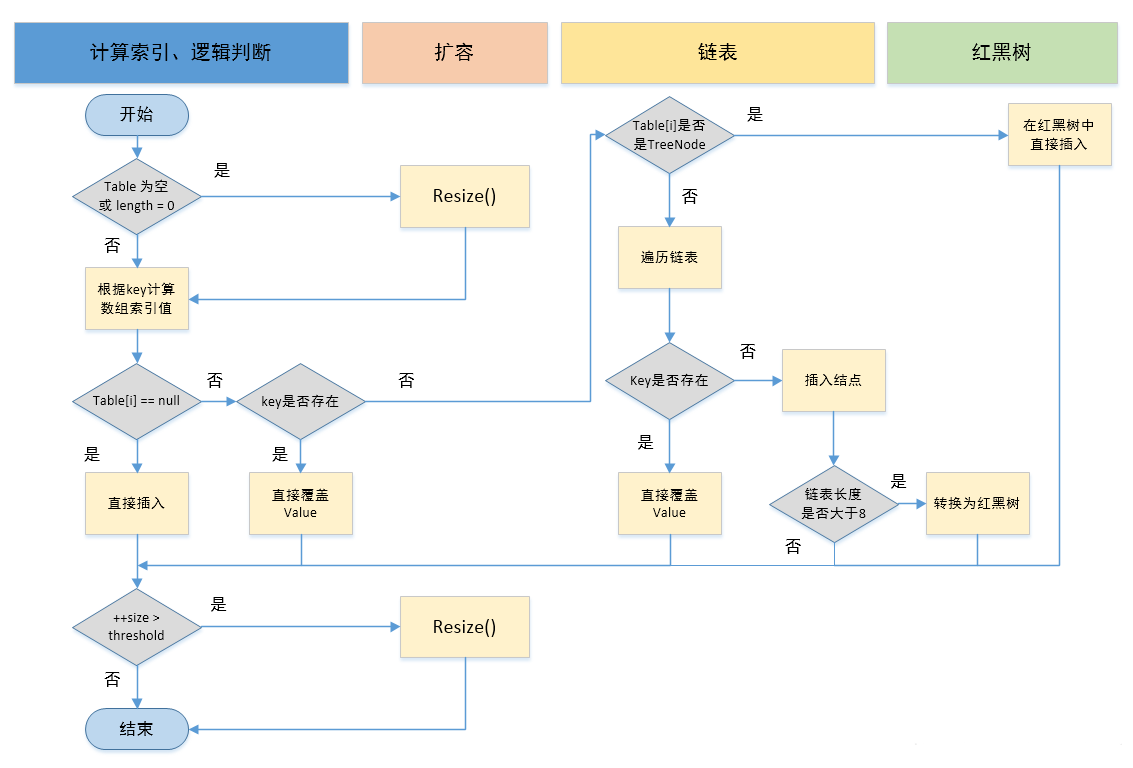
3、HashMap put流程:
根据键的hash码(调用键的hashcode方法)进行哈希运算(hash()),得到一个整数哈希值(不是数组的下标位置)`
判断哈希表是否为空或者长度是否为0,如果是,要对数组进行初始化(初始化为16),如果否,进入3`
根据1得到的哈希值计算数组索引(与运算(n - 1) & hash),得到一个和数组存储位置匹配的索引i(确定到桶的位置)`
判断i号位置是否为null,如果null,就将键和值封装为一个Entry(Node)类型的对象进行插入,如果不为null,进入5`
判断key是否存在(使用equals进行判断,在一个桶里面判断),如果存在,覆盖原有的值,如果不存在,进入6`
判断i号位置是否为一个树结构,如果是一个树结构,在树中进行插入,如果不是树结构,进入7`
为链表结构,对链表进行遍历,判断key是否存在,存在就覆盖,不存在就在链表中插入新的节点`
链表中插入新节点后,如果i号位置的元素个数大于等于8且hash表的长度大于等于64,i号位置的所有元素转换为树结构,反之,新节点正常插入结束`
size++`
判断是否要进行扩容,如果需要扩容,就执行Resize()进行扩容`
结束`
4、HashMap注意事项
-
为什么HashMap的长度为什么要设计成2的n次方?
提高效率:为了方便将去余运算转换为位运算 hash%长度== (n - 1) & hash
尽量让计算到的位置均匀
-
为什么设计扩容因子
为了减少一个桶里元素碰撞的概率,本质就是不要让一个桶中的元素个数太多
-
根据key怎么找到值的(get(key))?
根据key的哈希码先找到桶的位置,然后再在一个桶中用equals方法进行比对键,找到对应的节点,获取其值。
-
为什么使用hash码相关的集合的时候,重写equals方法的时候建议也重写hashCode方法
如果equals返回true.但是哈希码不一样,有可能会放到不同的桶中,不同的桶中就存在了键重复的元素了,有漏洞,最终目的是为了让equals返回true的两个对象能放到一个桶中,保证键不重复
5、LinkedHashMap:输出顺序和存入顺序一致
6、TreeMap
-
按照键进行排序(无参数构造TreeMap(),自然排序,TreeMap(Comparator),按照自定义比较器进行排序)
-
不能放入null键,可以放入null值
-
键不能重复(判断的依据是比较的大小如果相同,调用compareTo或者compare()方法返回值如果为0,就认为是相同的对象)
-
底层为红黑树结构。
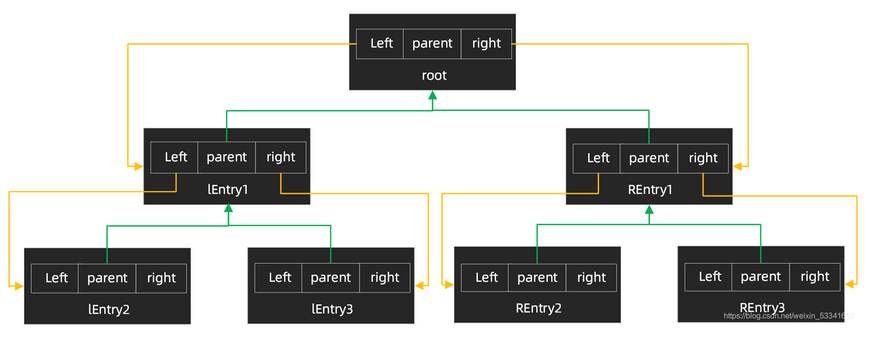
其中,每一个节点都是一个Entry类型的对象,该对象中封装了一些几个属性
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
}
TreeMap的put流程如下:可以自己描述
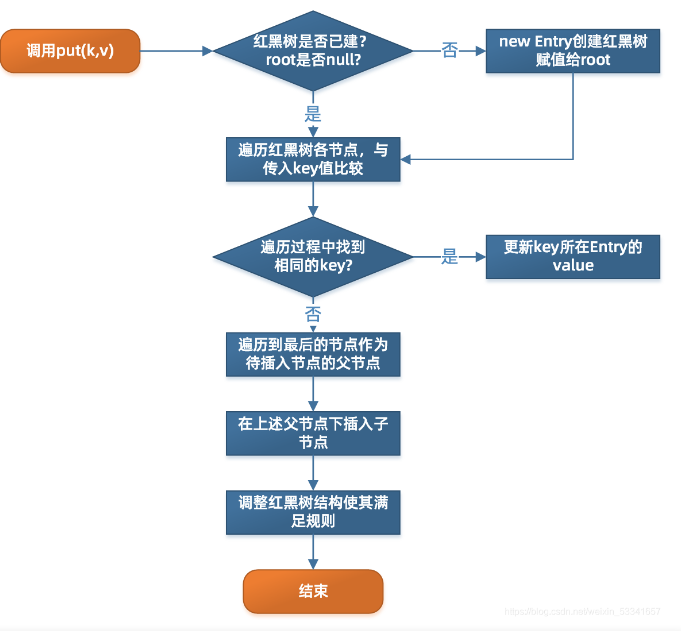
7、Hashtable
Hashtable<String, String> table = new Hashtable<String,String>();
table.put("001", "1111");
table.put("002", "2222");
table.put("003", "3333");
table.put("004", "4444");
table.put("005", null);
Set<Entry<String, String>> s =table.entrySet();
for(Entry<String, String> e:s){
System.out.println(e);
}
HashMap和Hashtable的区别:
-
根据hash码计算存储位置的过程和算法是不同的(hashMap最后进行位运算,hashtable最后进行取余的运算)。
-
Hashtable不能放入null键,null值,但是HashMap可以放入null键 null值
-
Hashtable初始的默认长度是11,HashMap是16.
-
Hashtable线程安全,效率低,HashMap线程不安全,效率高
-
扩容方式不同,HashMap扩容为原来的2倍,Hashtable扩容为原来的二倍加1
int** newCapacity = (oldCapacity << 1) + 1;
六、迭代器
1、Iterable:接口,规定实现类或子接口必须要有提供迭代器的能力
iterator方法:返回迭代器对象
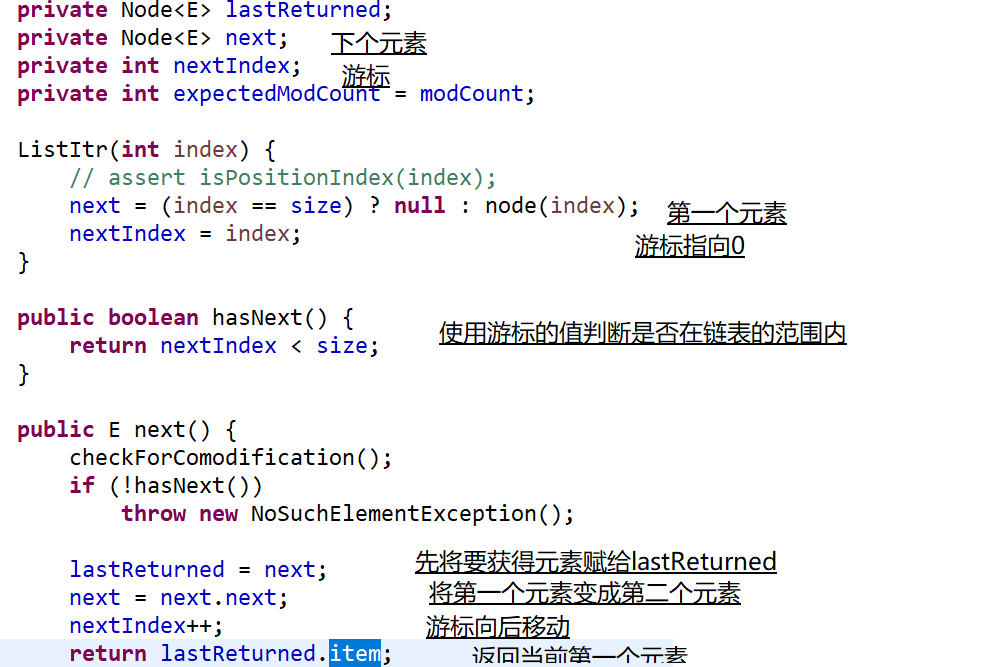
2、Iterator接口:迭代器的类型,迭代器使用Iterable接口中iterator方法返回的是Iterator类型 的对象
-
方法:hasNext next
-
实现该接口的实现类基本是各个集合中的内部类 迭代器的实现类是以不同集合中的内部类的形式存在的,因为集合的结构不同,对迭代器的具体实现也不同。
以下为Iterable和Iterator的关系图

支持删除行为:删除当前遍历到的元素(迭代器对象.remove()),迭代器在迭代的时候不支持集合本身的修改行为(add|remove),否则,会引发 java.util.ConcurrentModificationException
为什么迭代器不支持集合本身结构修改行为: modCount:集合的一个属性,每次修改add或者remove的时候,都会修改modCount的值,modCount属性的属性值就代表了集合的修改次数 得到迭代器的时候会有一个modCount(代表集合结构修改的次数),在得到迭代器的时候会记录这个次数, 如果在迭代过程中修改集合结构,modCount就变化了,和当时记录的modcount的数量就不一样了,会引发ConcurrentModificationException。本质上是为了保证迭代器在迭代过程中集合的结构是稳定的
1、java中迭代器的实现符合迭代器的设计模式
目前 java中的collection接口的集合都是符合迭代器设计模式的
-
抽象集合接口(Iterable(抽象接口))
-
集合的具体实现类实现Iterable(必须拥有给外界提供迭代器(Iterator)的能力)(ArrayList)
-
抽象迭代器接口(Iterator)
-
具体的迭代器实现类(实现Iterator,体现为不同集合中的内部类)
import java.util.Iterator;
public class MyList<T> implements Iterable<T> {
private Object element_data[];
private int initCapcity;//默认的初始容量
private int size;//表示就是实际容量
public MyList() {
// TODO Auto-generated constructor stub
this(10);
}
public MyList(int initCapcity) {
// TODO Auto-generated constructor stub
this.initCapcity=initCapcity;
element_data = new Object[initCapcity];
}
public void add(T e){
element_data[size++] = e;
}
//根据索引返回元素
public T get(int index){
return (T)element_data[index];
}
public int size(){
return size;
}
//iterator对Able接口中方法的重写
@Override
public Iterator<T> iterator() {
// TODO Auto-generated method stub
return new MyItr();
}
//内部类(迭代器实现类定义为一个集合中的内部类)
//内部类可以为私有(可以直接访问外部类的属性)
private class MyItr<T> implements Iterator<T>{
private int cursor;//代表迭代器内部的指针
//返回集合中有没有下一个元素
@Override
public boolean hasNext() {
// TODO Auto-generated method stub
return cursor<size;
}
//每调用一次next方法,指针都会移动一次,返回的是指针指向的位置的元素
@Override
public T next() {
// TODO Auto-generated method stub
T e=(T)element_data[cursor];
cursor++;//表示指针移动
return e;
}
}
}
七、Collections
Arrays
集合相关的而一个帮助类(List)
1、sort(List)方法的使用(含义:对集合进行排序)。Dog必须实现Comparable接口
2、sort(List,Comparator),自定义比较器排序
3、reverse(List)方法的使用(含义:反转集合中元素的顺序)。
4、binarySearch(List,Object)方法的使用(含义:查找指定集合中的元素,返回所查找元素的索引,要求集合中的元素是Comparable类型,查找方式为按照排序之后的顺序再进行位置查找,找不到返回-1
5、copy(List m,List n)方法的使用(含义:将集合n中的元素全部复制到m中,并且覆盖相应索引的元素)。
6、fill(List list,Object o)方法的使用(含义:用对象o替换集合list中的所有元素)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 智能门锁人脸识别好用监控不好用是怎么回事?
- DEX,ELF,XML,ARSC文件结构or工具
- 零基础学Python之保留字与标识符、变量与常量。超详细,你值得拥有。
- 测试之新员工光临的规律
- 如何用AI帮你写年会贺词
- Docker使用及部署python项目
- RK3568驱动指南|第十篇 热插拔-第119章使用mdev挂载U盘和T卡实验
- 静态HTTP:如何优化性能
- 【无标题】
- KBP210-ASEMI小功率家用电源KBP210