【C++】带你学会使用C++线程库thread、原子库atomic、互斥量库mutex、条件变量库condition_variable
C++线程相关知识讲解
前言
其实我前面是在讲Linux的时候已经讲过线程了,只不过Linux中讲的线程库是pthread库,是POSIX标准的线程库,并不是C++语言级别的线程库,本篇要讲的是C++官方提供的线程库。
如果对于线程还不太了解的同学可以看看我前面Linux阶段讲的线程:
- 【Linux】详解线程第一篇——由单线程到多线程的转变
- 【Linux】详解线程第二篇——用黄牛抢陈奕迅演唱会门票的例子来讲解【 线程互斥与锁 】
- 【Linux】详解线程第三篇——线程同步和生产消费者模型
- 【Linux】线程详解完结篇——信号量 + 线程池 + 单例模式 + 读写锁
本篇主要是填一下我前面C++博客中没有讲线程相关部分的坑,有三个,一个是专门介绍线程,一个是智能指针部分关于线程的坑,再一个是单例模式中关于线程的坑。
正式开始
C++官方为啥要提供线程库
- 为什么C++官方要专门提供线程库呢?
因为平台。
不同平台提供出来的线程库是不一样的,比如说Windows提供的线程库和Linux提供的线程库相关的接口是不同的。像我前面讲Linux中的pthread,创建线程的接口是pthread_create,而Windows下创建线程用的接口是CreateThread:
如果你是第一次看到Windows的线程相关的接口可能会感觉很吓人,里面很多字段都不认识,没关系,都是纸老虎,很多都是宏定义或者是typedef的,比如说返回值HANDLE,其实就是void*:
好了,不过多介绍这些东西,这里只是提一嘴不同平台提供的线程库接口不大一样,记住这一点就行。如果想要在Windows下也用pthread库也是可以的,只不过还要安装东西,有点麻烦,我就不演示了,我们平时如果想在vs下写多线程相关的东西就直接用Windows提供的多线程相关的库,用的时候引一下windows.h就行。


不过两个平台下的线程库用起来还是大同小异的,大方向都一样,但还是有差别,那如果要跨平台的话就会很烦,所以C++为了解决这样的问题,就提供了C++语言级别的thread等线程相关的库,其实底层做法还是调用不同平台的接口,只不过条件编译的时候把不属于当前机器平台的代码屏蔽掉了,如果是用Linux的机器,那底层还就是用Linux的那一套,Windows的那一套在条件编译的时候就去掉了,如果是Windows的机器也是同理的。
本篇就根据cplusplus官网(Reference)中的文档来着重讲解C++提供的线程相关的库,核心的库有四个:
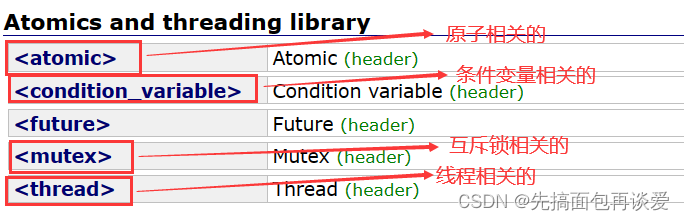
不论是Windows下的还是Linux下的线程库都是面向过程的,而C++中是面向对象的,这一点光说的话体会不到,还是用代码来说话能体会出来。
下面就来介绍介绍这四个库中一些比较重要的接口。
thread
构造函数
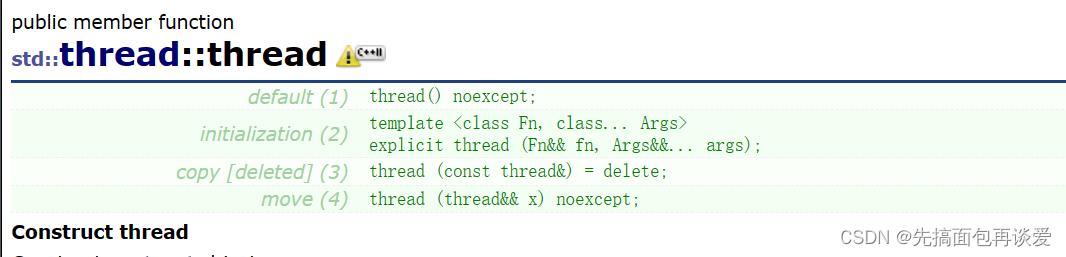
这里看起来是提供了四个,实际上是三个,因为拷贝构造直接给禁掉了,因为线程不存在拷贝这一说,不能说创建一个线程A后再新起一个线程B来拷贝线程A,没有这种说法的,同样的拷贝赋值也是被禁掉的。
- 无参构造
thread() noexcept;
后面加个noexcept就是当你明确你的接口不会抛异常时就在函数后面指明noexcept,这个函数就不会参与异常处理的相关工作,因此可能在性能上更高效。如果不加就默认可能抛异常,不过noexcept重点是表名函数是否可能抛异常,而不是出于对性能的考虑。
无参构造就是创建一个线程,但是不给这个线程提供可执行的对象,也就是不给线程提供它要执行的函数。
那无参构造有用吗?
有用,比如说我前面Linux中写过一个简易的线程池,如果用C++写一个线程池就可以用这个无参构造,先把线程创建出来,不执行具体的东西,等有任务的时候再去执行。
这样用构造函数来创建对象就和pthread中的用法很不一样了,pthread里面创建线程后后续相应的工作都要通过线程的id来实现,但是C++中是吧线程看作对象,创建好后就用这个对象来执行后续工作。可能你看到这里有点看不懂,没关系,等会给代码演示的时候就懂了。
- 有参构造
template <class Fn, class... Args>
explicit thread (Fn&& fn, Args&&... args);
是个函数模版,没错,类中还能定义函数模版。
来回顾一下pthread库中是如何创建一个线程的:
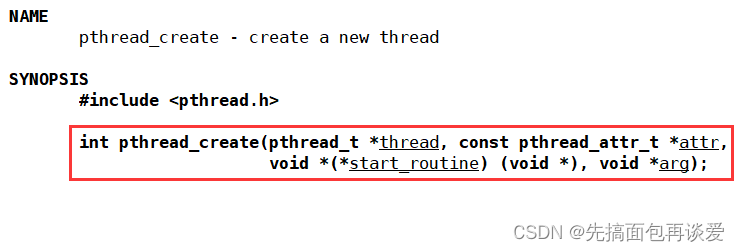
不详细介绍,主要说一下第三个参数和第四个参数,这里创建线程的时候是第三个参数给一个函数指针,然后第四个参数会传给函数指针所指向的函数。(不懂的同学可以看我最开始给出的线程详解第一篇)不过这样用起来有点麻烦。
C++中不推荐继续使用C中的那一套函数指针的玩法了,所以搞出来了仿函数、lambda表达式以及对函数、仿函数和lambda进行包装的包装器。这里有参构造用的是模版,那就意味着不仅可以穿函数指针,还可以传仿函数这些东西。
参数里面用到了万能引用(也可叫引用折叠,就是两个&&的参数),就是无论传左值还是右值都能变成左值,这里就不细说这一点了,我前面C++11的博客中讲过的,不懂得同学可以看我这篇博客:【C++】C++11中比较重要的内容介绍
还有可变参数args,会自动推导参数的个数和类型。
用有参构造创建线程的时候其实就是让线程去执行fn函数,并将args传给fn函数。
explicit是为了不让进行隐式类型转换,不细说了,不懂的同学看我这篇:【C++】类和对象(下篇)
等会给代码演示有参构造。
这里简单提一嘴,类模版里面也是可以定义函数模版的:
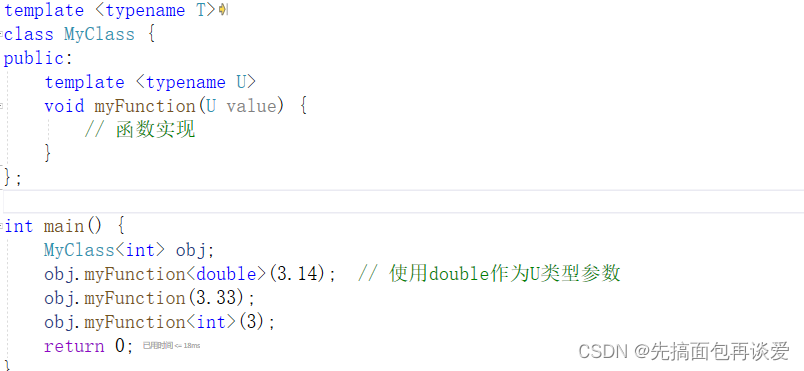
在同一类型的类中,根据函数模版生成的函数都是属于这个类的:
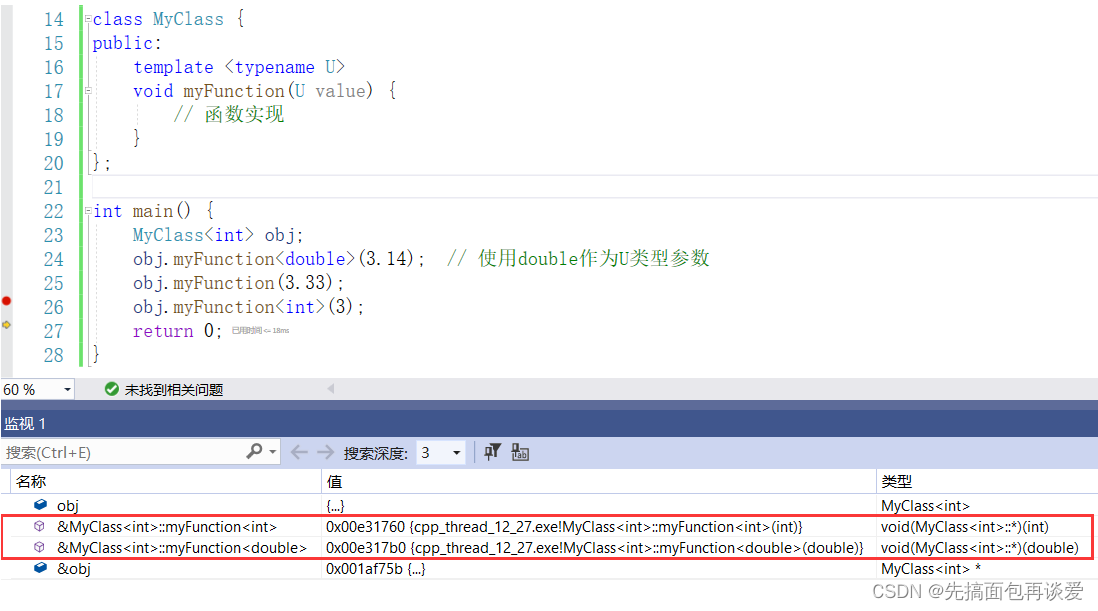
如果我再生成一个char类型的类:
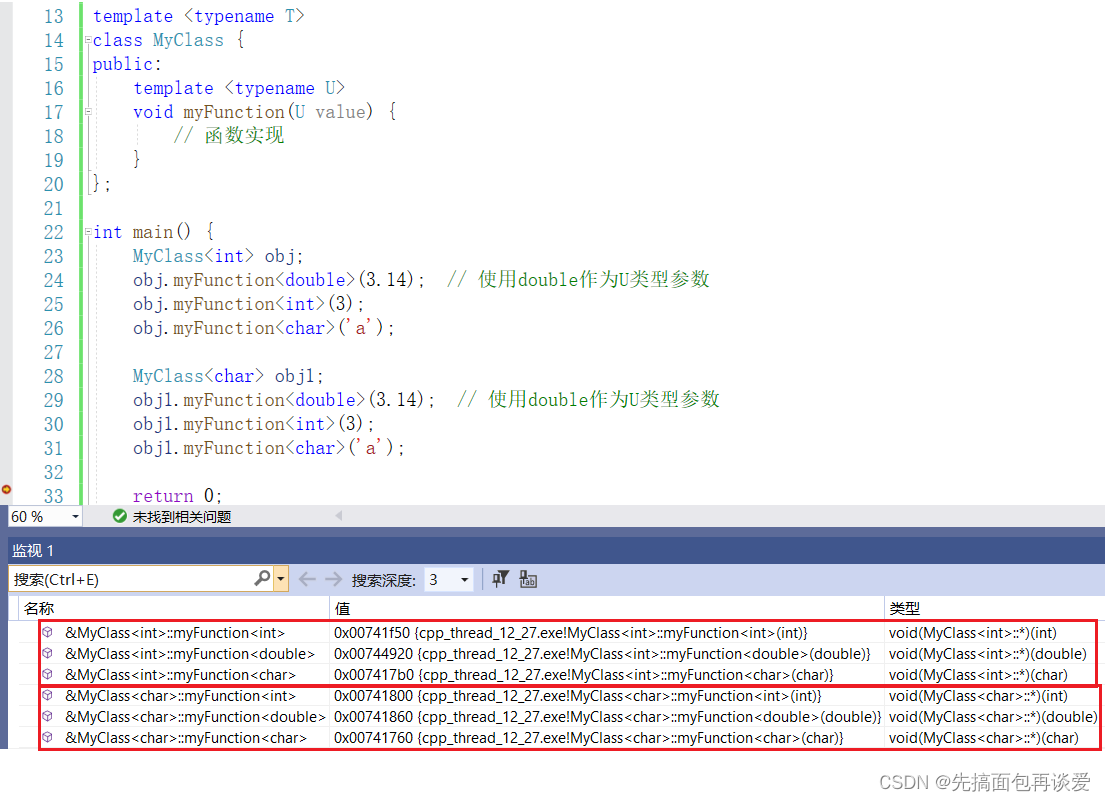
同样的道理。
- 移动构造
移动构造就不细说了,就是为了效率的,传右值效率高,具体的内容可以看我前面C++11的博客。
代码演示
这里就先用一下cplusplus官网中给的例子(先不要细看):
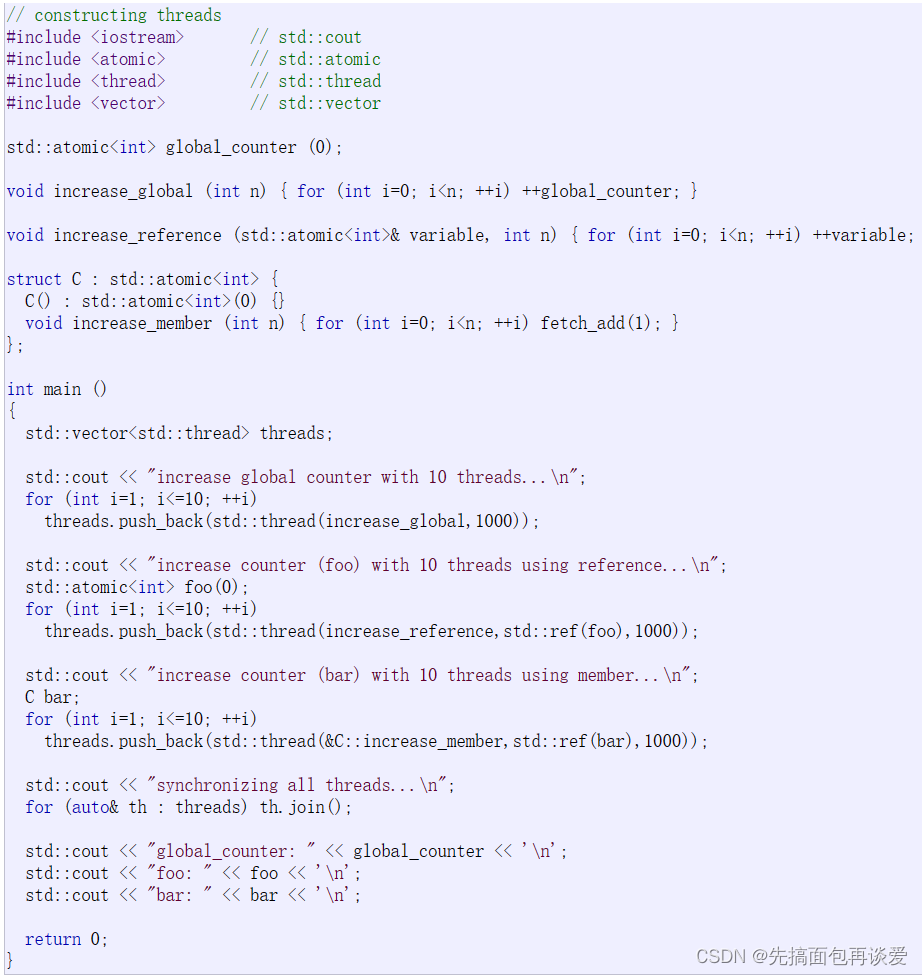
把最开始的那个有参构造拿出来讲讲:
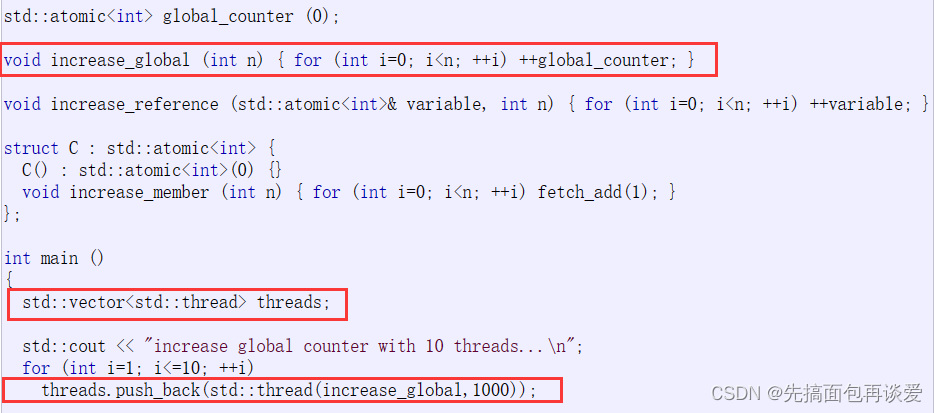
这里先创建了一个vector容器,vector中存放的是thread类对象,for循环里创建了10个匿名的线程对象,每个线程对象要执行的就是increase_global这个函数,参数给的是1000,调用push_back的时候会识别到thread对象为匿名对象,就会直接调用右值引用版本的push_back,效率更高,push_back里面在定位new的时候也是调用移动构造来创建对象。
注意不能先创建线程对象然后再用直接创建好的对象进行push_back:
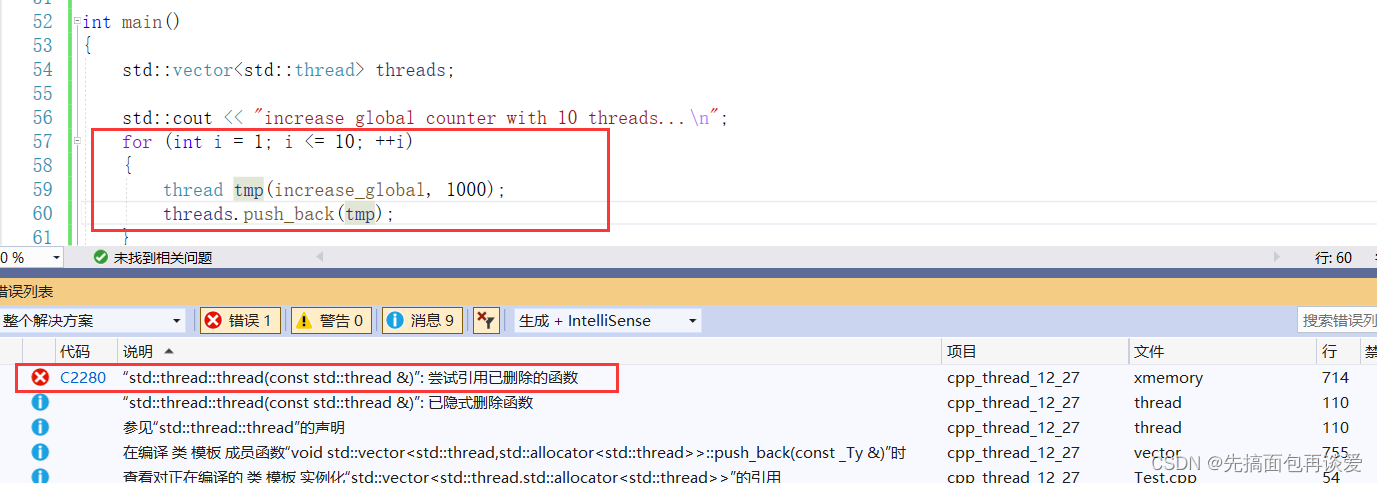
这里push_back调用的时候没事,只不过里面在进行定位new调用构造函数的时候就会出问题,因为tmp传到push_back里面后会变成左值,此时定位new就会调用拷贝构造,而拷贝构造已经删掉了,所以就会出错。
如果真想要用新建对象来push_back的话也可以,加上move就好了:
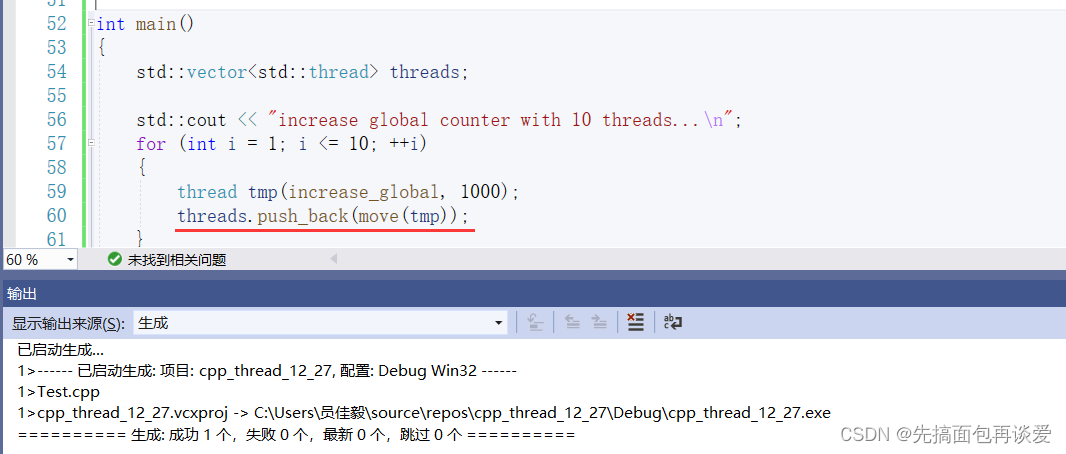
move之后就会变成右值,这样push_back就还会调用右值引用的版本,定位new的时候也就会调用移动构造:
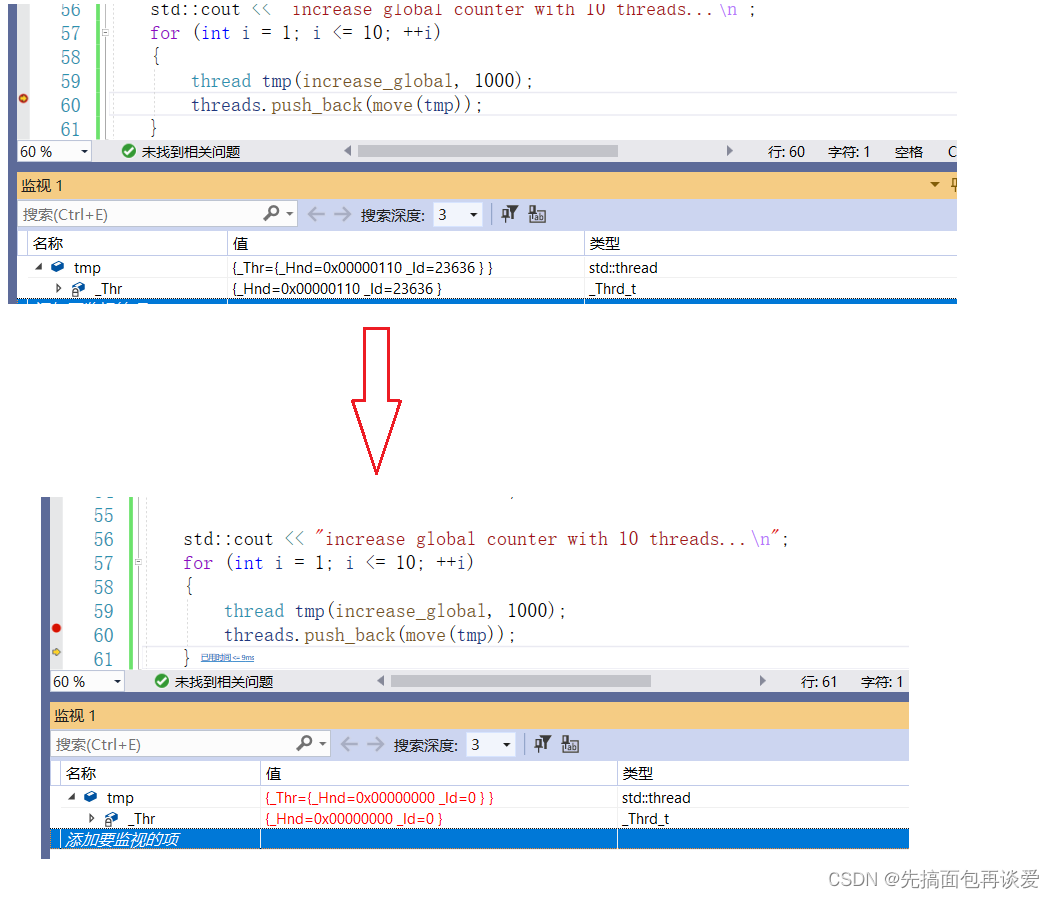
剩下的两个push_back的例子中用到了atomic库,因为还没讲atomic,就先不说这两个push_back的例子了。
然后就是对所有的线程进行join等待:

可以看到大致用法还是和pthread的那一套很像的,还是传函数来让从线程去执行,主线程创建完从线程之后也是要对每个从线程进行join等待。
前面说了pthread那一套创建完线程后如果后续要对从线程进行后续操作就要通过线程的id来实现,其实C++thread库里面也可以获取到线程的id,用get_id函数就行:

只不过是封装到了thread类中。
代码演示
见过猪跑了,来吃点猪肉。我来写点线程相关的代码看看。
最简单的创建线程并让线程执行某个函数:
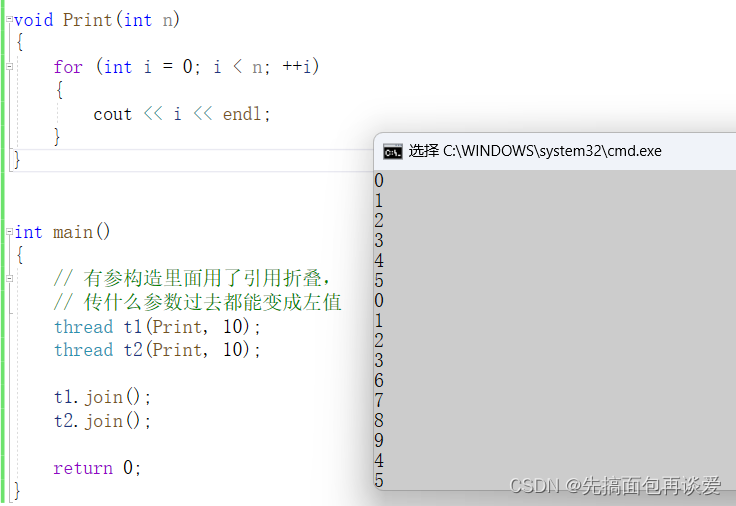
打印出来的结果有交错,因为不是原子操作,所以工作中碰到了多线程相关的问题就会非常头疼。
如果现在想看一下这些数都是哪个线程打印的话,能直接在Print中调用get_id()吗?
不太行,thread的get_id是一个成员函数,线程对象可以调用get_id,但是在Print函数中没法调用,因为Print中并没有执行该方法的线程对象。
不过有this_thread命名空间:
this_thread
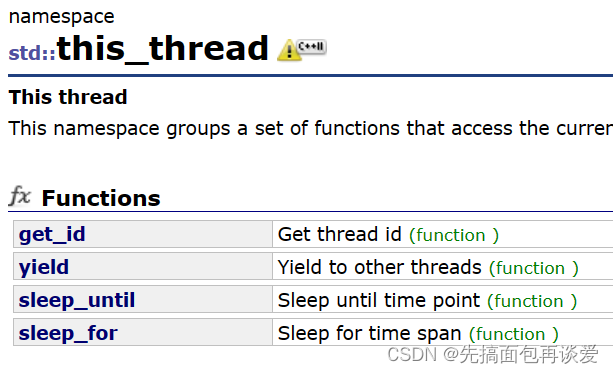
thread命名空间中封装了四个函数,分别是get_id,yield,sleep_until和sleep_for。函数功能等会介绍,先来说说get_id。
get_id()

用法就是不管是那个执行流执行this_thread中的某个函数,都是当前执行流的线程在执行的。
比如说哪个线程调用了this_thread::get_id(),就会打印这个线程的id,演示一下:
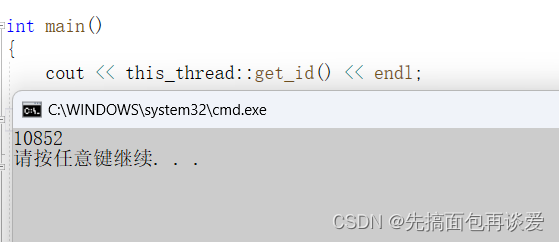
上面主线程调用了this_thread::get_id(),就会返回主线程的id。同理如果是从线程调用的话就会获得到其id,我们来放到Print中试试:
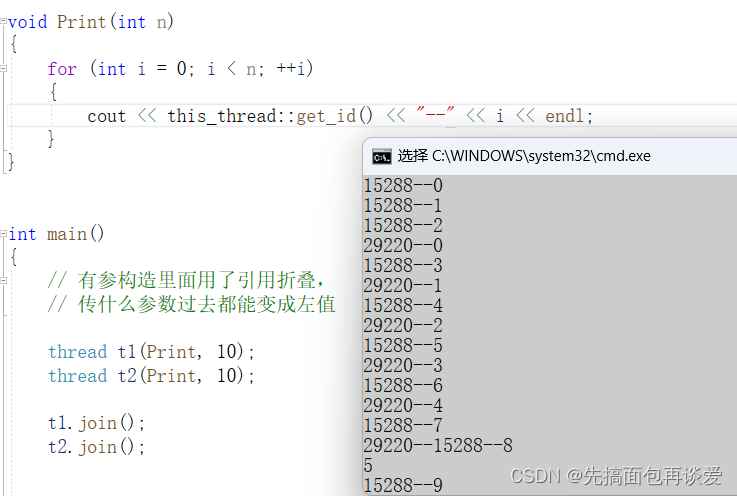
前面我讲pthread的时候说过,这里因为cout不是原子的,所以打印的结果可能会有穿插。
这个get_id就说到这,来说说其他三个。
yield()

这个单词有产出、产量的意思,不过这里thread库中是屈服、让步的意思,就是当前线程调用这个函数的时候会将当前线程的时间片让出来,让其他线程先执行。
说个yield的使用场景,假如B线程想要去执行某件事时必须要满足一个前提条件,当这个前提条件还未满足的时候就不执行某件事,那就先调用yield来让出当前的时间片让其他线程去跑(比如说A线程),假如A线程执行完后才能让B线程执行,那就搞一个原子的bool事件(假如说这个bool的事件起名为ready,初始情况下为false),A线程执行完之后将这ready改为true,此时B检测到后就可以执行其代码了,来看看cplusplus官网下面给的示例(不要细看,过一眼,等会给批注):

因为我还没讲atomic原子库,这里就简单介绍一下,后面再细说,atomic也是一个类,你可以理解为当一个变量被atomic修饰之后,这个变量就变成原子的了,对其做一些普通的运算操作(加减乘除按位与等)都是原子的,可以多线程并发,是线程安全的。
上面的代码加点批注:

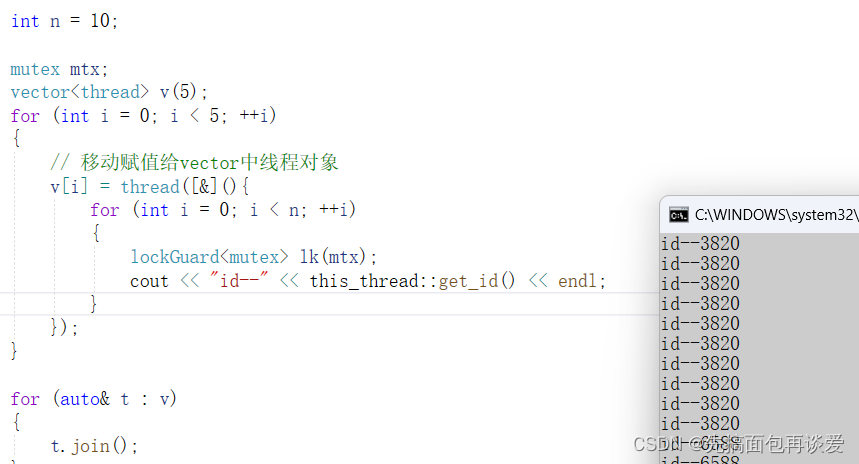
可惜我不会搞动图,这里运行起来后是10个线程同时开始并发打印的。
注意一点,for循环中让是个线程去执行count1m都调用的是移动赋值,因为最开始是数组直接开好空间了,构造已经调用了,而vector中push_back是在调用定位new,所以还会调用构造,如果说vector提前把空间开好,不用push_back也是会调用移动赋值的。
反正记住yield就是让当前线程让出时间片,然后去重新排队等时间片去。
sleep_until和sleep_for
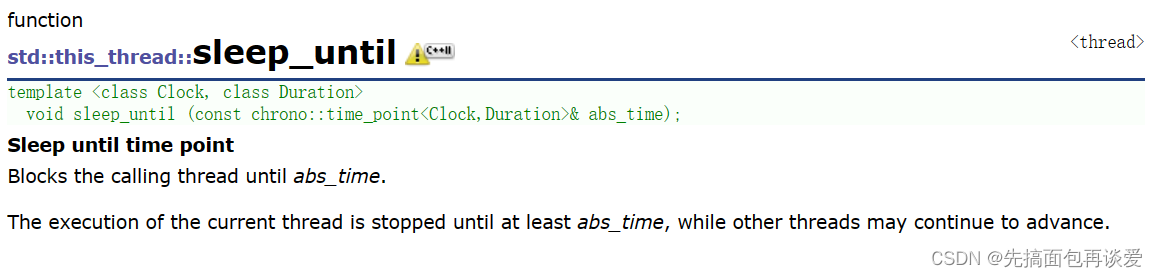
sleep_until这个函数就是让线程sleep到一个绝对的时间点:
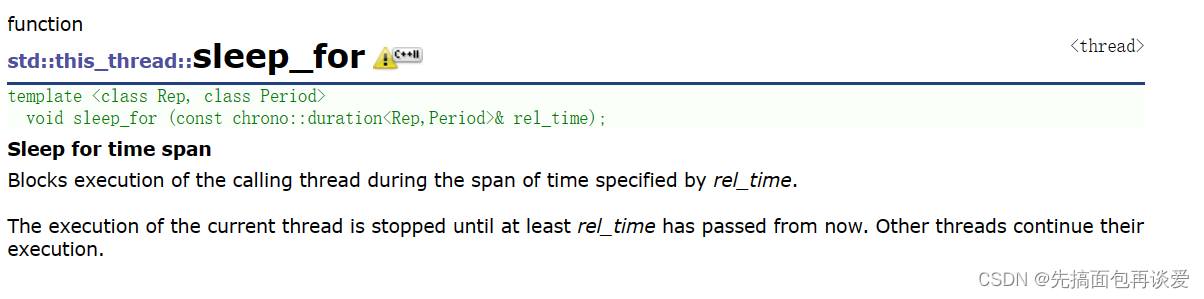
sleep_for就是让线程sleep一个时间段,比如说1s、500ms等:
这两个函数都要用到时间相关的类或者函数。
先来看看chrono:

chrono这个也是个命名空间,不过还是在std下的命名空间。
sleep_until睡到绝对时间用的相对较少一点,sleep_for睡一段时间用的多一点,不过怎样,都来看看官网给的例子。
sleep_for:
运行:
里面传不同的类型能代表不同的单位,比如说这里用的seconds就是s,还有其他的单位:

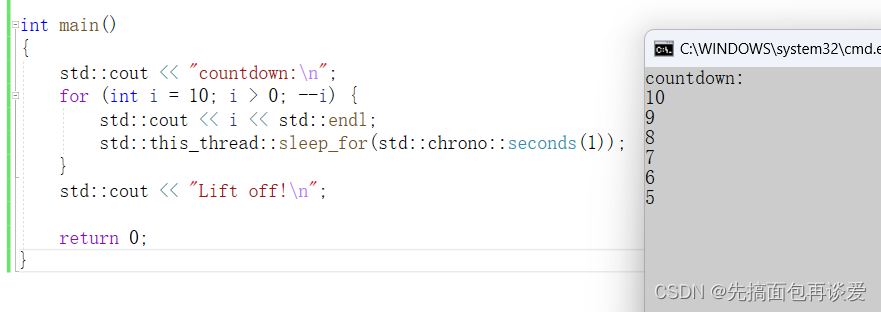
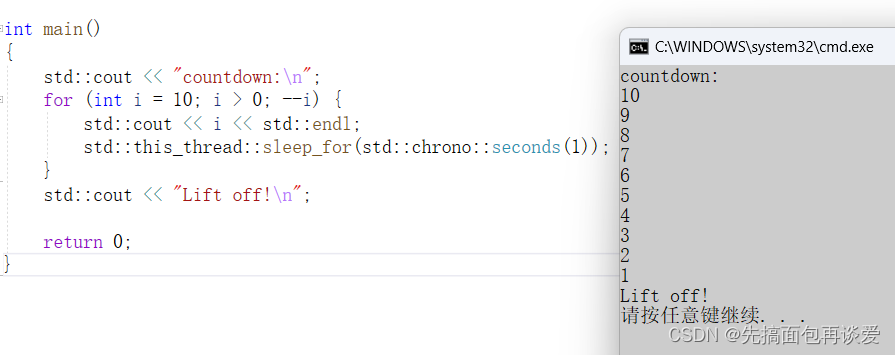
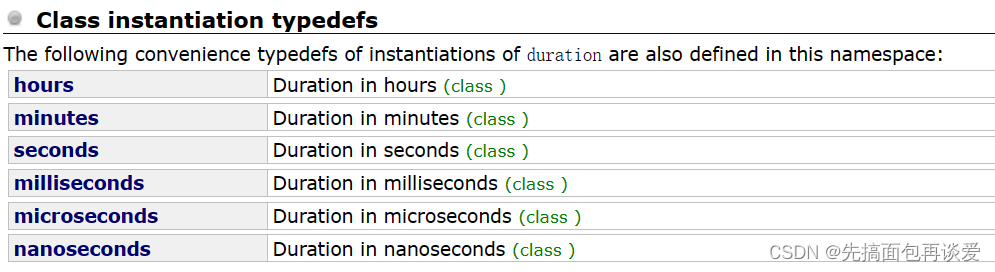
我来改一下我前面的代码:
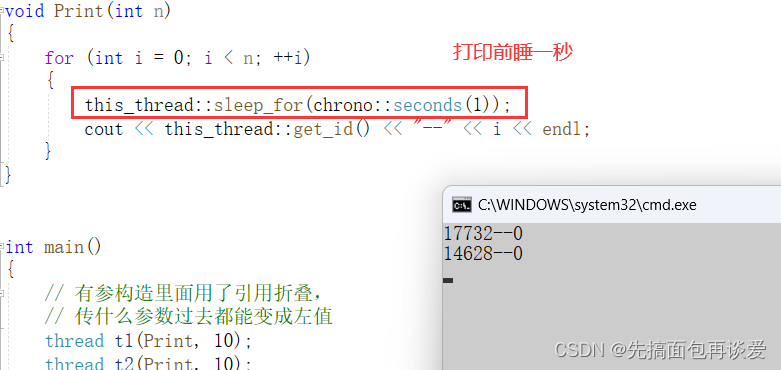
这样就能进行简单的时间控制。
如果嫌s太快的话可以用毫秒(milliseconds):
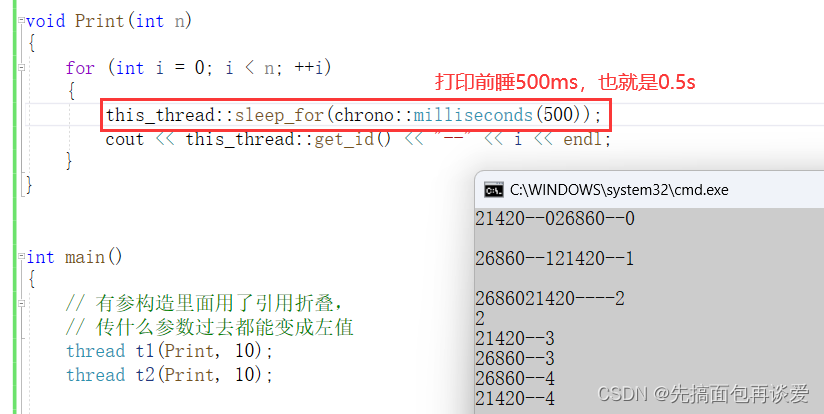
像seconds这样的类型都是内嵌类型,而且sleep_for一般都是用ms、s这两个级别的时间的,其他的就有点太快了。
sleep_until:
运行结果:

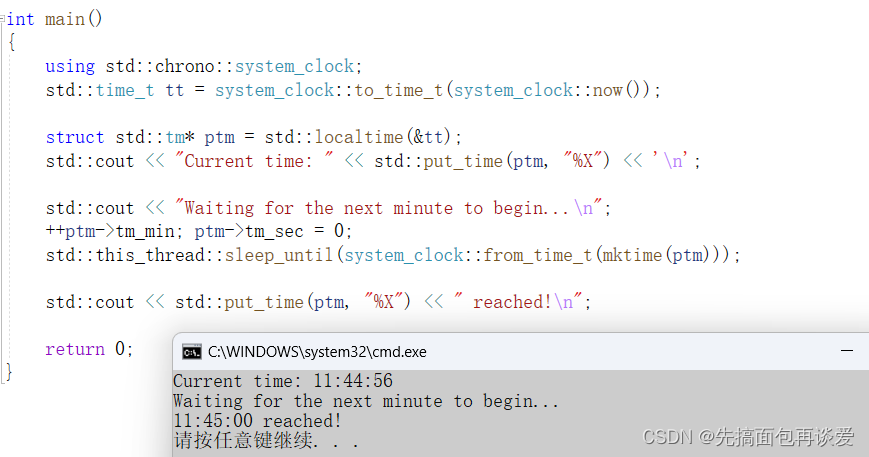
这里就是通过修改ptm中的tm_min和tm_sec来修改sleep_until到哪个时刻。这个就不细讲了,想了解的同学可以自己看看文档。
mutex
要是想加互斥锁,那就要用到mutex库。
这里也是对锁相关的接口进行了封装,封装成了mutex类:

在我前面讲pthread的时候,如果想要加锁,用的是pthread_mutex相关的接口先搞一个锁变量,然后再用pthread_mutex的接口来对锁进行其他操作。
C++这里是创建mutex对象,然后再调用成员就行了。
一共就这几个:

来看看mutex的构造函数:
构造函数
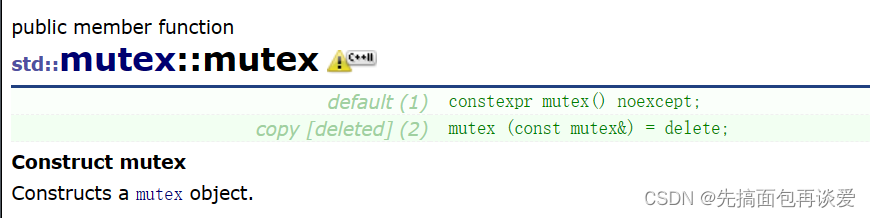
只有一个无参构造,拷贝构造delete了,同样的锁也不存在复制的这一说法。
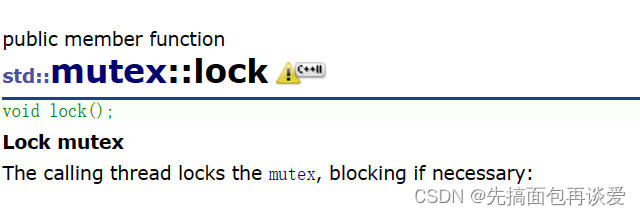
lock和unlock
然后最重要的就是lock和unlock接口了:

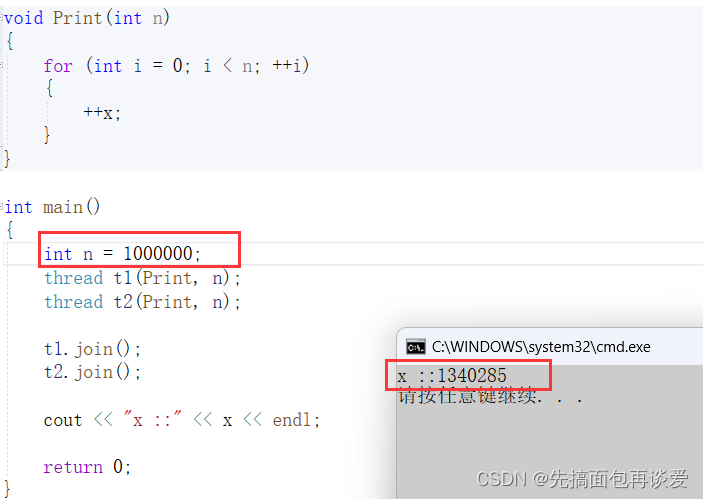
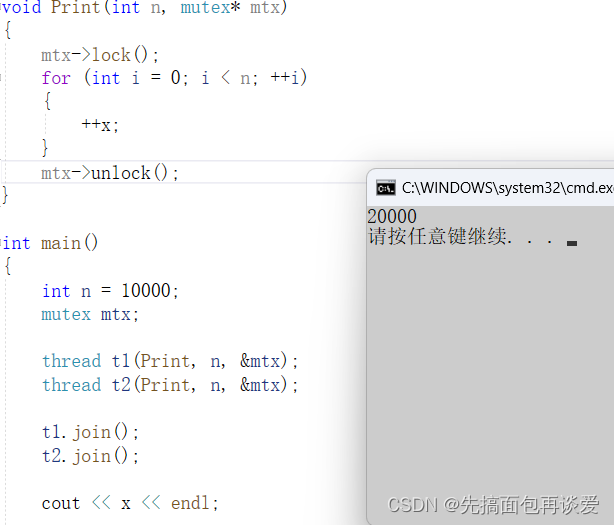
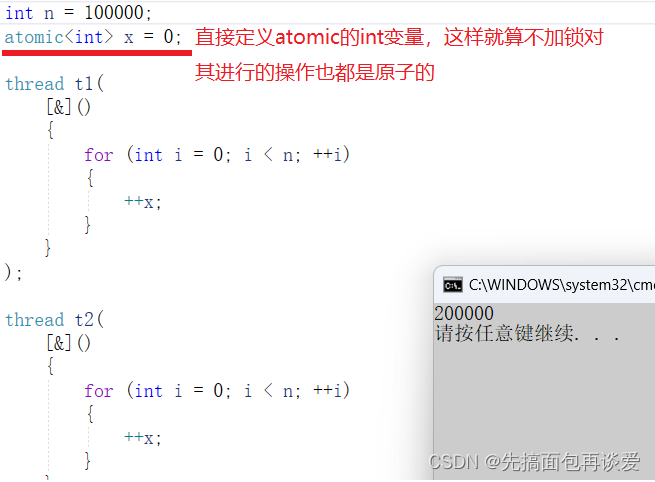
来个例子,假如说我现在要让两个线程对一个全局变量x做++操作:
#include<mutex>
int x = 0;
void Print(int n)
{
for (int i = 0; i < n; ++i)
{
++x;
}
}
int main()
{
int n = 10;
thread t1(Print, n);
thread t2(Print, n);
t1.join();
t2.join();
return 0;
}
如果不加上锁的话可能会出问题,尤其是在n很大的情况下:
上锁
全局锁
想要解决就在外面加锁:
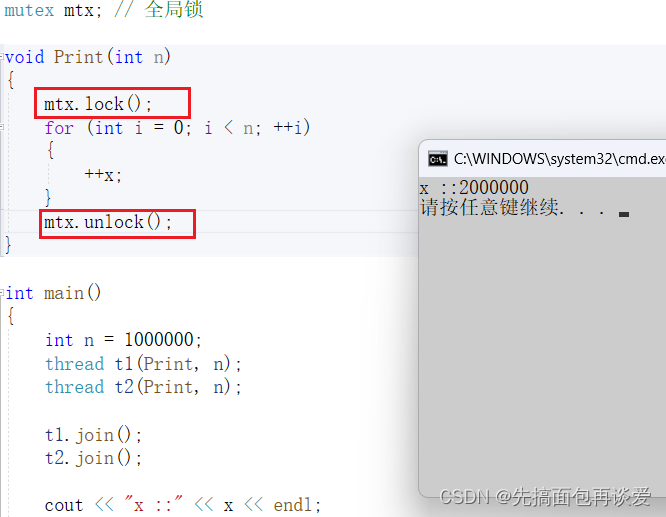
这样就不会出问题。
也可以在++x两边加锁:
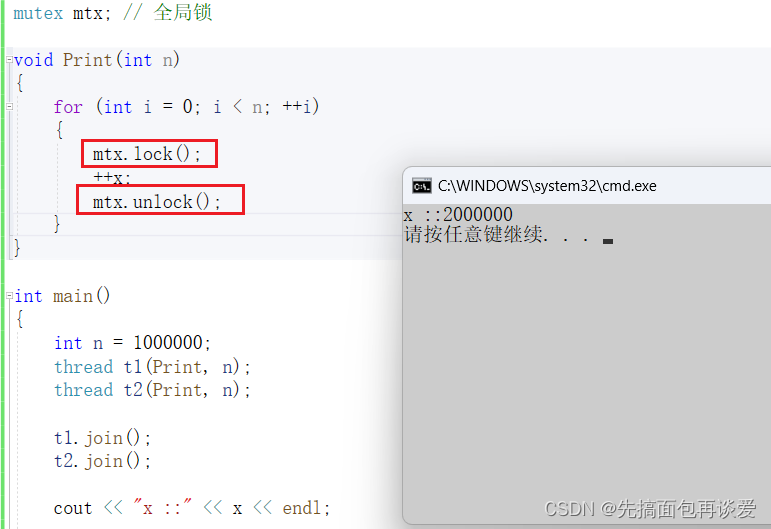
那这两种方式哪一种更快呢?
如果按照我前面说讲pthread的时候说的,加锁粒度要细,那应该是第二种更快,因为第二种看起来粒度更细一点。
来分析一下,假如说有两个线程t1和t2:

加在for两边的
一个线程for循环跑完之后另一个线程才会拿到锁,所以只有当一个线程将for串行执行完并解锁后另一个线程才能拿到锁继续执行其for循环。
加在++x两边的
一个线程抢到锁后(假如说是t1先抢到锁),那么t1只会跑一次++x就直接解锁了,然后就轮到t2线程跑,t2线程跑完++x后又解锁,然后又轮到刚刚的t1线程跑……
有没有感觉加在++x两边的方式很麻烦?
假如说有两个线程的话,那么每个线程只会执行一条代码就直接解锁,然后换成另一个线程来跑,那这样会有很多的时间会浪费到线程的上下文切换上,从而就会有很多的时间浪费。
如果不信的话我可以用一些时间函数来展示一下二者的时间相差:
void Print(int n)
{
// 并行执行的
/*for (int i = 0; i < n; ++i)
{
mtx.lock();
++x;
mtx.unlock();
}*/
// 串行执行的
/*mtx.lock();
for (int i = 0; i < n; ++i)
{
++x;
}
mtx.unlock();*/
}
int main()
{
int n = 1000000;
// 获取开始时间
chrono::high_resolution_clock::time_point begin = chrono::high_resolution_clock::now();
thread t1(Print, n);
thread t2(Print, n);
t1.join();
t2.join();
// 获取结束时间
chrono::high_resolution_clock::time_point end = chrono::high_resolution_clock::now();
cout << endl << "x ::" << x << endl;
// begin和end的时间差
chrono::duration<double> time_span = chrono::duration_cast<chrono::duration<double>>(end - begin);
cout << "time cost::" << time_span.count() << "seconds" << endl << endl;
return 0;
}
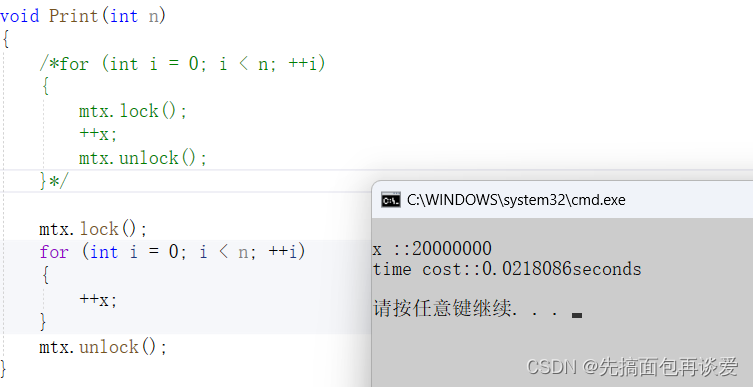
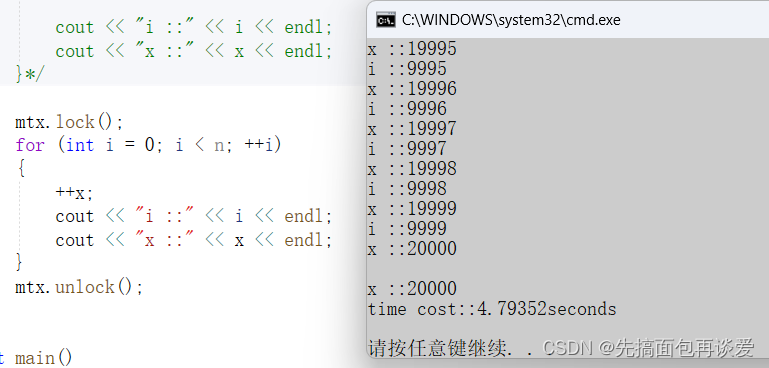
上面的time_span.count()返回值是以s为单位的数值,下面就简单演示一下n为一千万时的情况:
for两边的:
++x两边:
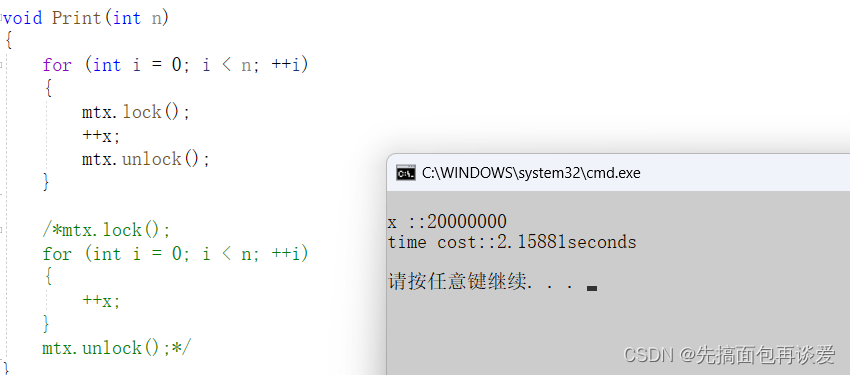
显而易见,加在for两边的更快,二者相差了几乎一百倍。而这相差的一百倍的时间都是线程切换所消耗的时间。
这里主要原因是加锁范围中的执行代码太少了,所以二者相差的时间不是在代码执行上,而是在线程切换上。
如果我在其中加上两个打印,那就没啥区别了:
++x的:
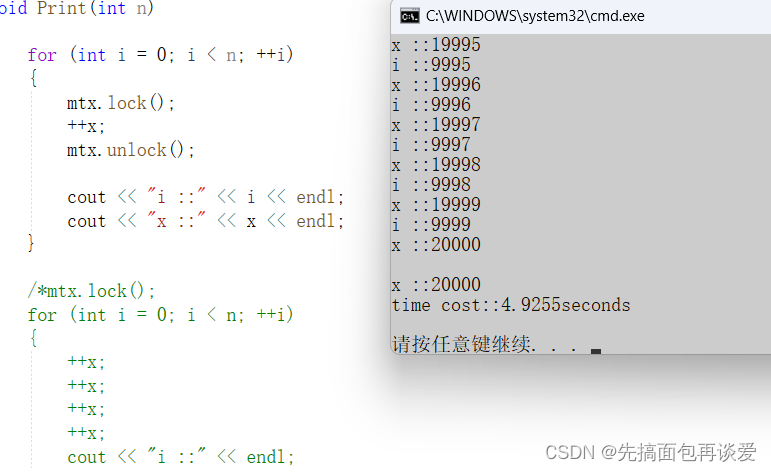
for两边的:
这里也只是假设的情况,实际上可能不是打印,而是其他的业务逻辑,比如说向数据库发一条sql让它执行啥的,那这样比打印消耗的时间就更多了,那么此时更推荐的就是加在++x两边的了。
所以虽然说加锁粒度要小,但是遇到循环执行的代码的时候一定要谨慎加锁。
但是全局的锁尽量少用,如果是在一个.h中定义个全局变量,多个.cpp文件引用了这个.h文件,就会出现冲突的情况,要么封装一下,要么用一个局部变量作为参数传给线程要执行的函数方法。
局部锁
演示一下局部锁传参的使用方式:

如果这里直接编译的话会出错:
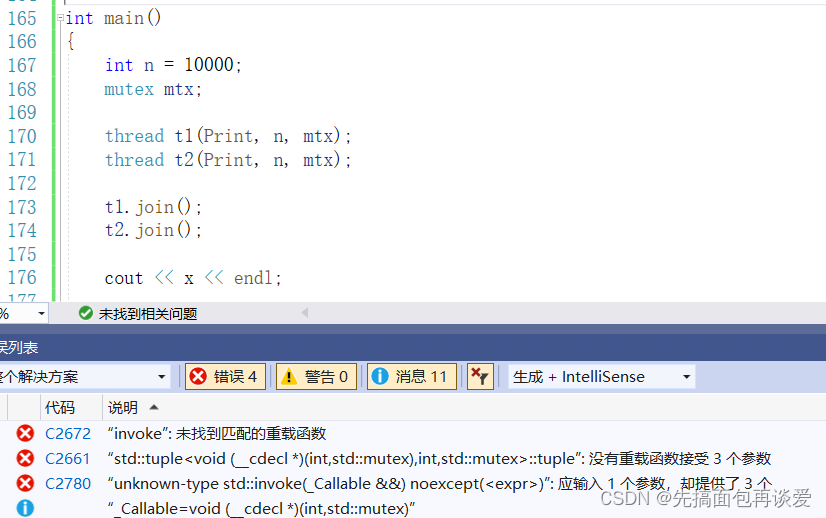
前面说了mutex拷贝构造delete了,锁不能进行拷贝,所以这里编译是会报错的。
那么就要传引用了,但是如果是给引用的话还是不行:
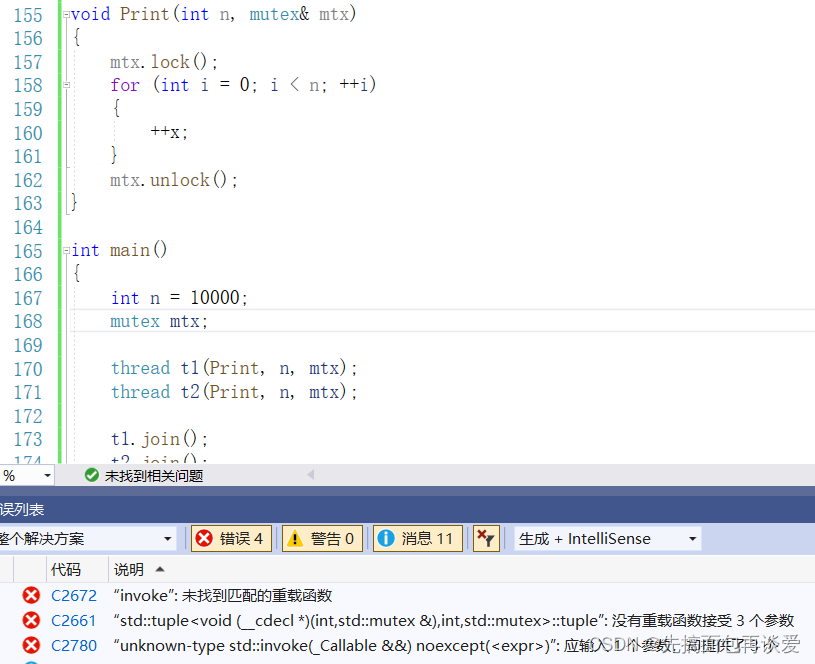
我这里用的是vs2019,vs2013下面是能通过的,不过13下还是会有问题(传引用过去参数不会变成引用,而是另一个拷贝,算是一个bug,具体原因要看看thread构造函数的底层实现,我这里就不细说了)。
vs2019下面是直接禁用了引用,不过也不是完全禁用,需要我们在传参的时候加上ref:
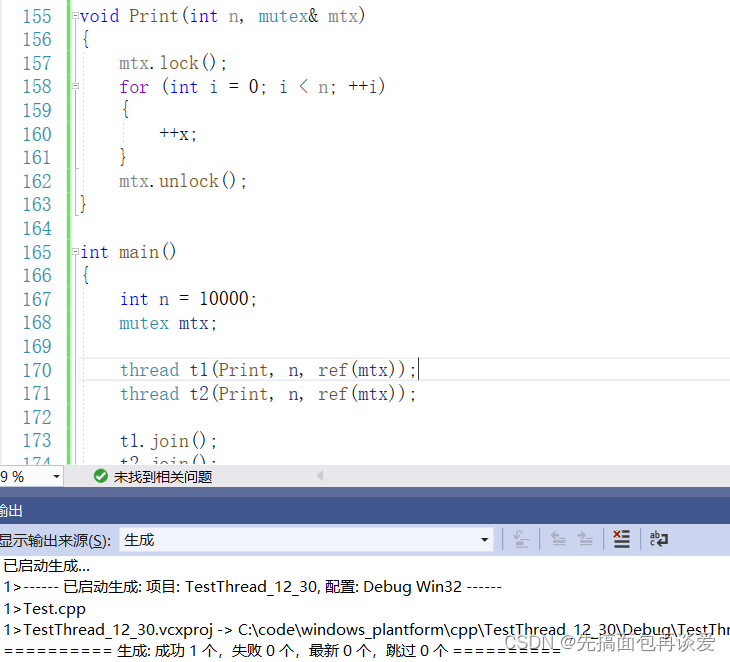
查一下ref:

可以看到是一个函数模版,这个函数作用就是把传过去的东西强制变为左值引用,如果你正好是用引用接收或者是auto接收的话就会变成引用:
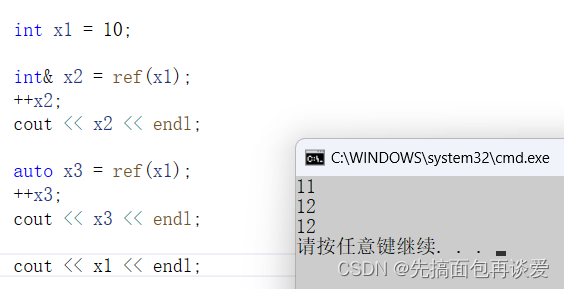
但是如果不是引用接收就是拷贝了:
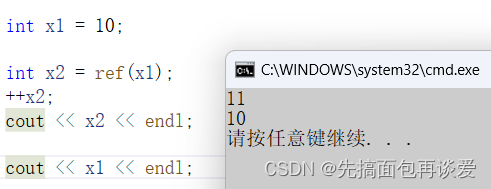
再说回刚刚的锁,局部锁传给线程执行的函数的时候一定要加上ref,这样才能传过去,不过也可以用指针来传:
这里了解一下局部锁传给线程执行方法就行。
lambda表达式
如果不想传函数指针呢?用lambda会很方便(如果你不太懂lambda,可以看看我这篇博客:
【C++】C++11中比较重要的内容介绍):

再多搞几个线程的话可以直接cv,但是有点麻烦,如果线程较多(比如说线程池),那就可以搞一个vector,里面放线程就行:
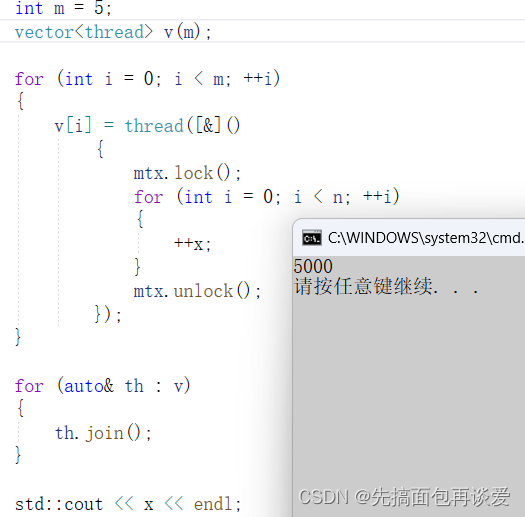
注意这里v[i] = thread(lambda)中调用的是移动赋值。
上面vector<\thread> v(m),第二个参数不能给成lambda(像int这样的可以将m个元素都初始化为某一个值):
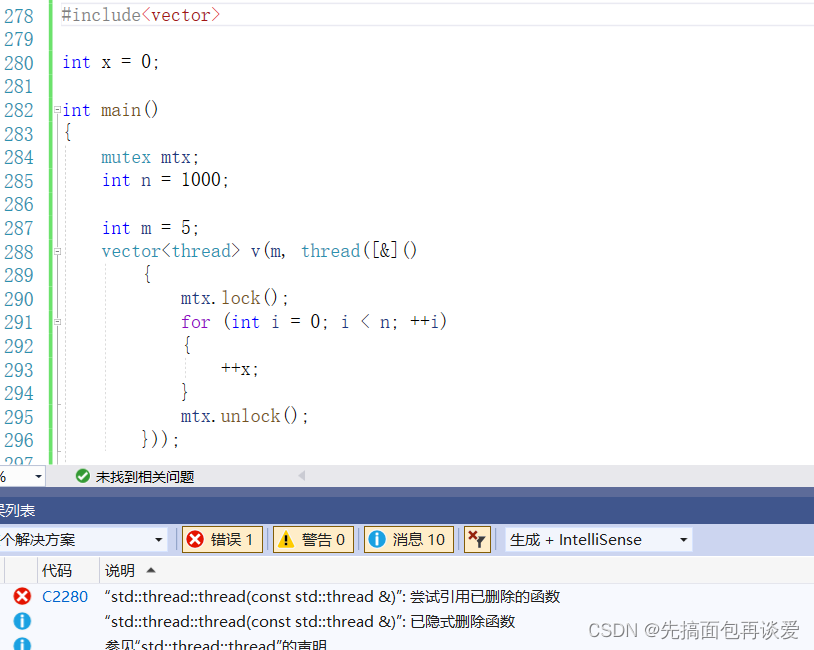
因为vector中没有提供第二个参数为右值的构造函数:
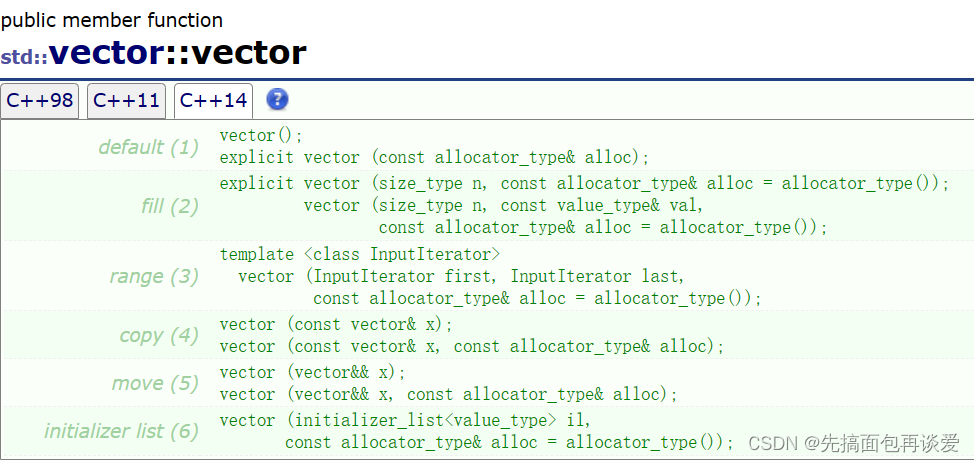
这里我的vs19默认支持的是C++14,可以看到这里是没有第二个参数为右值的版本的。
try_lock

这个try_lock会返回一个bool值,来表示当前线程是否能抢到锁,能了就会让当前线程获取到锁,不能就返回false,并不会阻塞。不会像lock一样当某个线程占用锁了其他线程想获取锁就会阻塞。
就记住try_lock不会让线程因为抢锁而阻塞就行。
其他锁
时间锁
关于锁mutex,除了互斥锁,还有time锁:
就是在普通互斥锁的基础上加了两个接口,分别是try_lock_for和try_lock_until,正常加锁后需要我们手动解锁,用这两个接口可以自动解锁。
-
try_lock_for就是指定锁用多少时间,在这个时间之后如果没有手动解锁时就会自动解锁。

-
try_lock_until就是到达某一个时刻的时候如果还没有解锁就会自动解锁。

这个了解一下就行,平时用的不多。
递归版本专用锁recursive_mutex
还有一个递归版本专用的锁,如果在递归函数中用普通的互斥锁会造成死锁的现象,互斥锁在第二次执行递归函数的时候,申请同一个锁的时候,锁的状态是被占有的,此时就算是自己占用的所也检查不到,这样就会死锁,而用recursive_mutex就不会死锁。
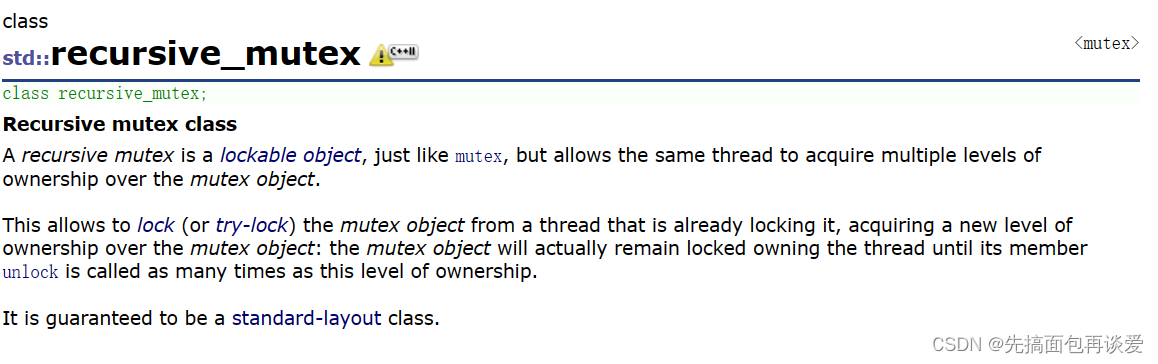
当使用recursive_mutex时,如果线程申请的锁被占用了,那么就会先识别一下锁是被那个线程所占用,如果是自己那就让这个线程继续执行,如果不是申请锁的线程占用该锁就会让这个线程阻塞,这样recursive_mutex在递归中就很好用。
锁的异常处理
凡是有后续处理动作的操作都很怕异常,比如说malloc和free,二者之间的操作可能会抛异常,new和delete也是,包括这里的lock和unlock。
如果你对于异常处理不太熟悉的话可以看我这篇:
【C++】异常
比如说:

如果加锁和解锁之间抛了异常就会死锁,就和内存泄漏一样,java中也是存在这样的问题的,想要手动解决就要加上try catch:
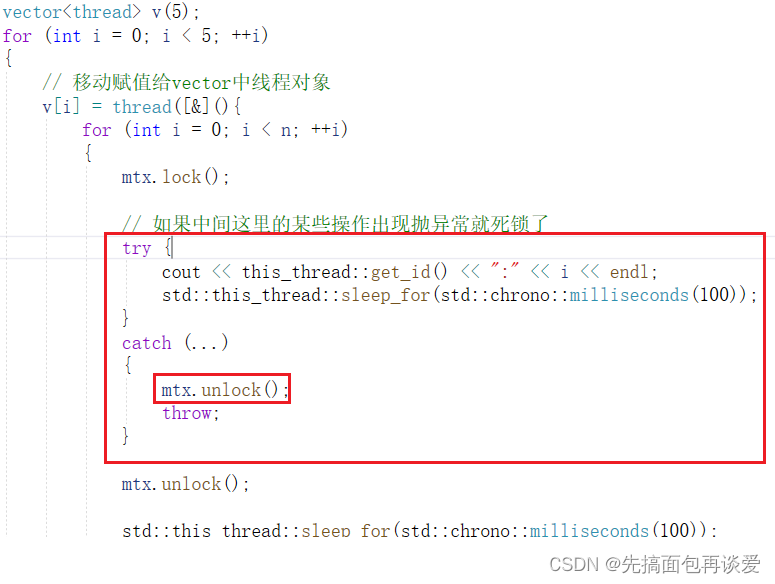
上面catch(…)表示接收所有异常,然后解锁,throw后面没有跟任何东西,表示直接将捕捉到的异常抛出去。
但是这种方式就有点挫,最好的方式是搞一个智能锁,像智能指针一样,利用好RAII。
比如说我这里写一个lockGuard类:

这里写的是类模版,因为锁不止mutex一种,前面也介绍了别的锁,这些锁也可以用这里的lockGuard,但如果这样写的话是有点问题的,因为锁的拷贝构造删除了,所以_lock(lk)这里是不行的:
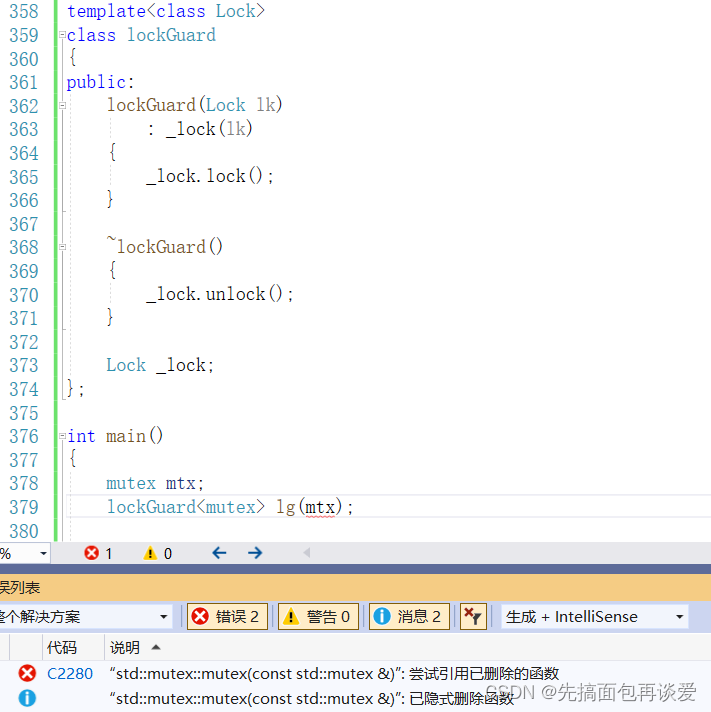
那如何解决呢?
可以将Lock _lock改为Lock& _lock,然后把构造函数中的Lock也改成引用:
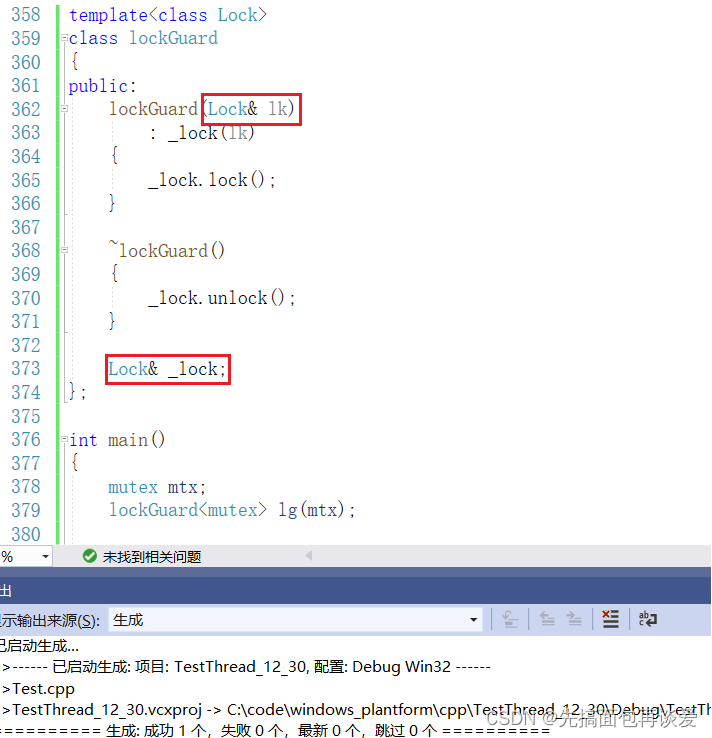
这样就OK了。
前面类和对象的博客中讲过,有三种成员必须在初始化列表初始化:
- 没有默认构造函数的
- const成员
- 引用成员
这里就是引用成员的场景。
这就是RAII,资源获得即初始化。用一用:
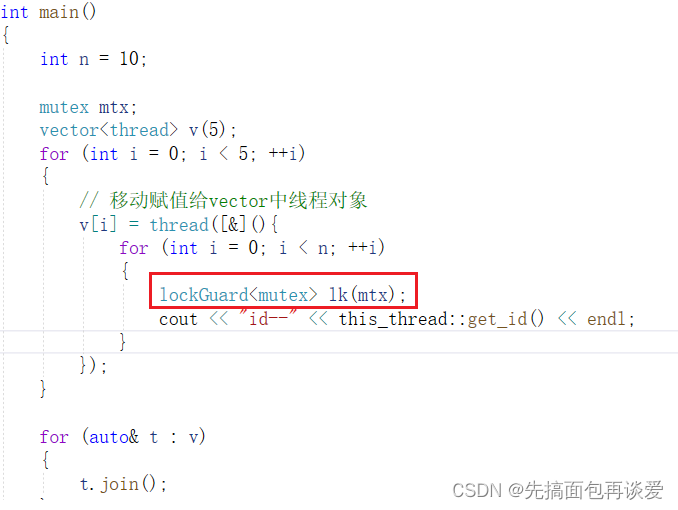
运行:
完全ok。
lock_guard
其实库中也是实现了和这里一样的lock_guard的:

也是个类模版,用法和刚刚的一模一样,刚刚的就算是一个简易的模拟实现吧。
这个类中只有构造和析构:


一般就是直接用第一个构造就行。
如果说想要对单行的操作进行加锁,就可以用{}实现,通过控制lock_guard对象的生命周期来自动加锁和解锁,比如说我如果多条语句中执行对某一条++x加锁,那就可以这样: 
所以要锁那一部分就可以加上局部域的括号就行。
unique_lock
还有一个unique_lock:

同理,就像unique_ptr一样,这里只不过是智能锁的另一种方式,不过里面的接口更多一点:
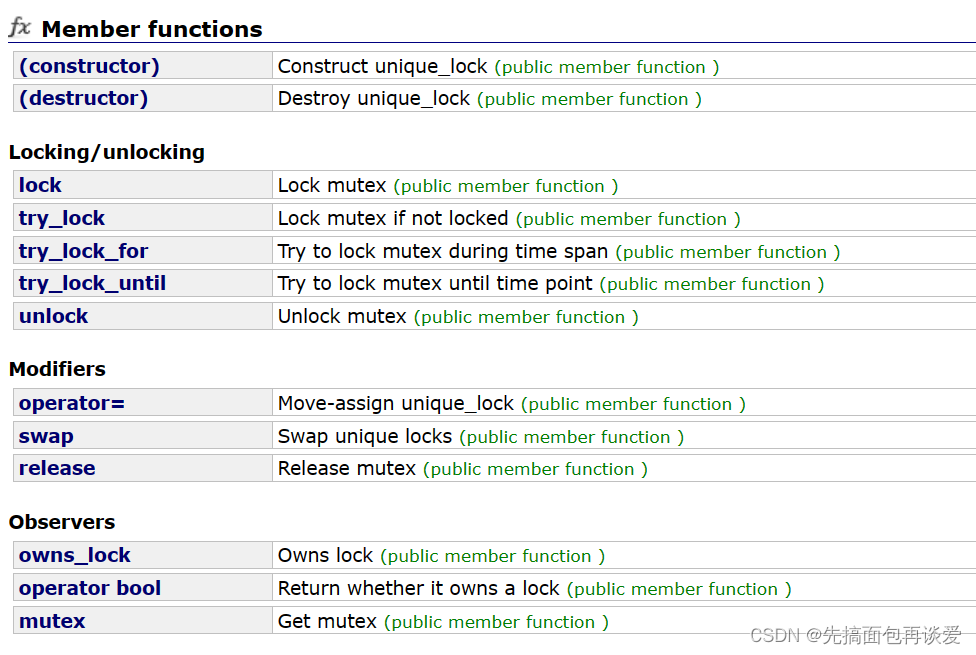
不仅可以自动加锁解锁,还可以手动加锁解锁,具体的就不细说了。
再来讲讲原子操作。
原子操作atomic
上面的++x时是给x加锁保护了的,这样能够保证++x的执行一定是串行的,同一时刻下最多只能有一个线程在加锁区域内执行,但是如果把锁去掉就会产生线程不安全问题,因为++x不是原子操作,前面我讲Linux的时候也说过,++操作对应的汇编会有三条(取数,加一,放回),所以不是原子的。
那么想要解决多线程并发执行++x的问题,就有两种方式,一种方式就是刚刚讲的加锁,另一种方式就是原子操作。
CAS原子操作,由系统提供的atomic就是对CAS操作进行了封装。
关于CAS我就不做过多介绍了,不懂的同学可以看这一篇:并发编程-原子操作CAS
无锁编程
什么是无锁编程呢?
讲一个例子,比如说无锁队列(具体实现不说,只是说一下大致逻辑)。一个队列,想要在多线程情况下对这个队列进行push、pop操作的时候要对push和pop加锁,比如说多线程并发进行入队的时候如果入队节点没有放到尾节点指针的时候就会再试。估计我讲的这点你没有听懂,没关系,往下看就行。
有人觉得加锁效率比较低,就可以考虑无锁编程来实现一个无锁队列,其实也就是用CAS来实现不加锁而达到线程安全的目的。
可以认为CAS是CPU直接支持的一种指令,比如说++操作,++是先获取、再修改、再放回,三步操作不是原子的,有CAS时能保证一个线程正在执行++这三步操作的时候其他线程获取不到变量x,或者尽管获取到x的时候放回去会失败。
我来画一个进行CAS的++操作的图解:
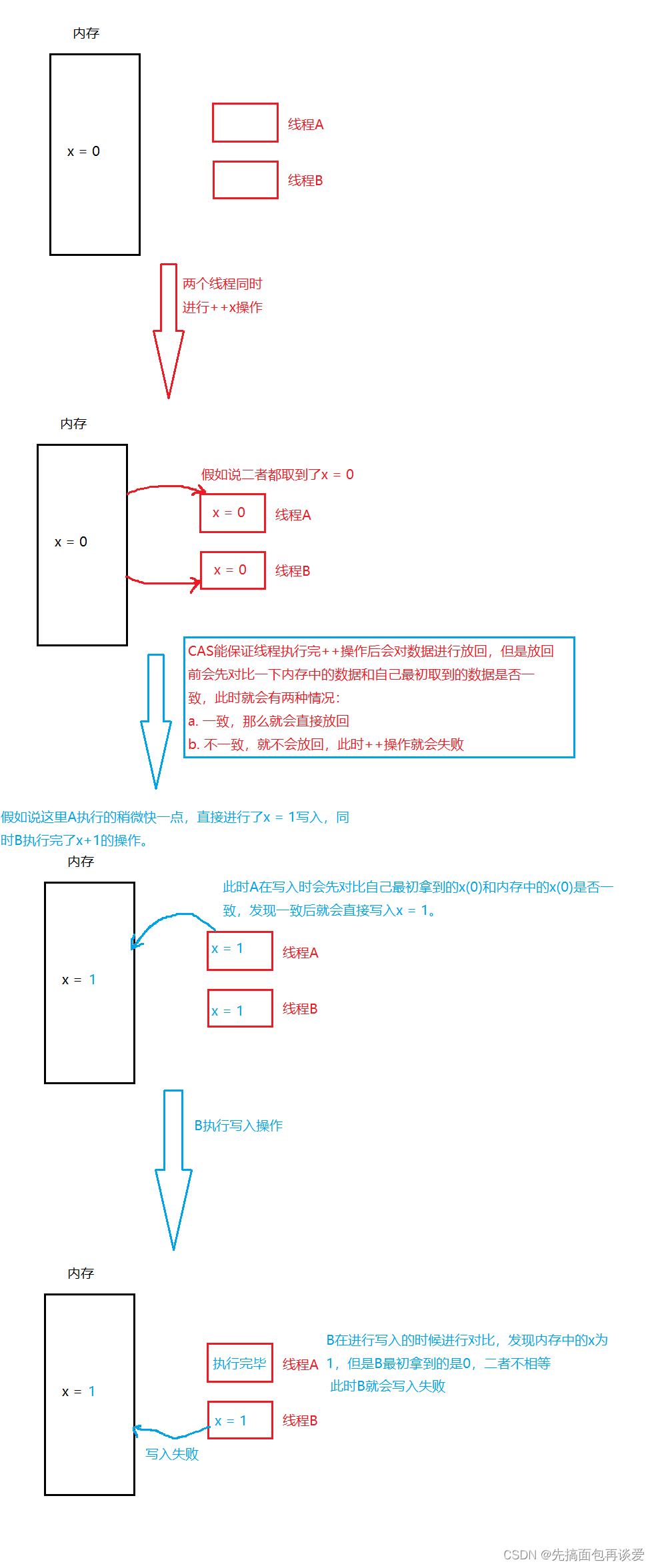
CAS利用CPU指令保证了操作的原子性,以达到锁的效果,循环这个指令知道成功为止,自旋锁(自旋锁就是锁被占用时,其他线程来了不会休眠,而是重复的去检查锁的状态是否从被占有变为未被占有,被占有的时候就继续检查,未占有了就获取这个锁)也是用CAS来实现的,Linux和Windows下都提供了相关的CAS操作的接口,如g++/gcc下的CAS:
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval, ...)
type __sync_val_compare_and_swap (type *ptr, type oldval type newval, ...)
Windows下的CAS接口:
InterlockedCompareExchange ( __inout LONG volatile *Target,
__in LONG Exchange,
__in LONG Comperand);
这样不同平台下的CAS操作接口不一样,也是会有兼容性问题,所以C++11中也搞了CAS接口:
template< class T >
bool atomic_compare_exchange_weak( std::atomic* obj,
T* expected, T desired );
template< class T >
bool atomic_compare_exchange_weak( volatile std::atomic* obj,
T* expected, T desired );
就是封装了aotomic类模版,类中就有:
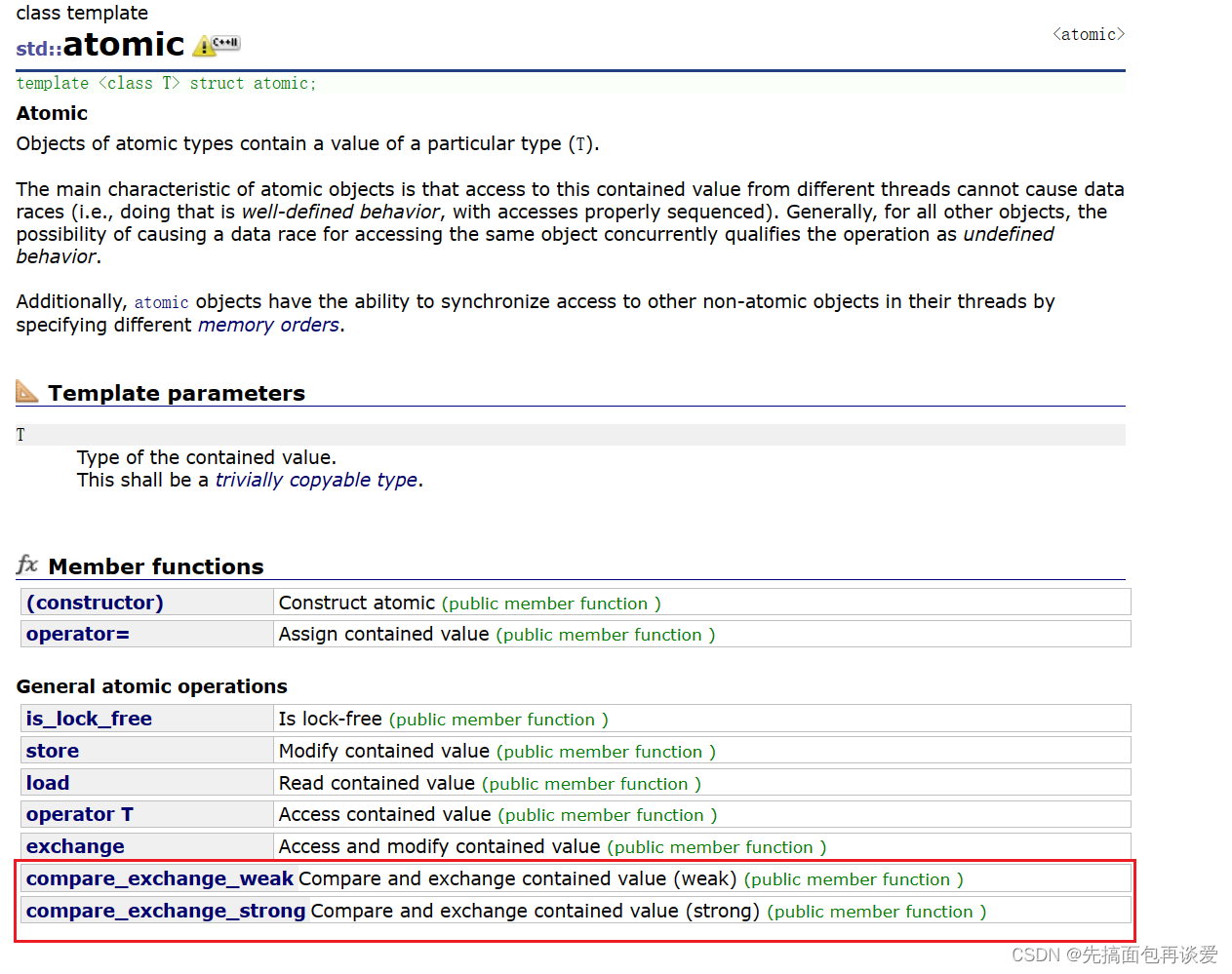
但一般不会直接用。
注意atomic是类模版,模版参数放的是你想要进行操作的数据类型。
构造函数
就两个:

拷构删掉了。
直接上例子吧。
例子演示
演示一下atomic的操作:
说一下,atomic中重载了++操作,不仅重载了++,还有别的:
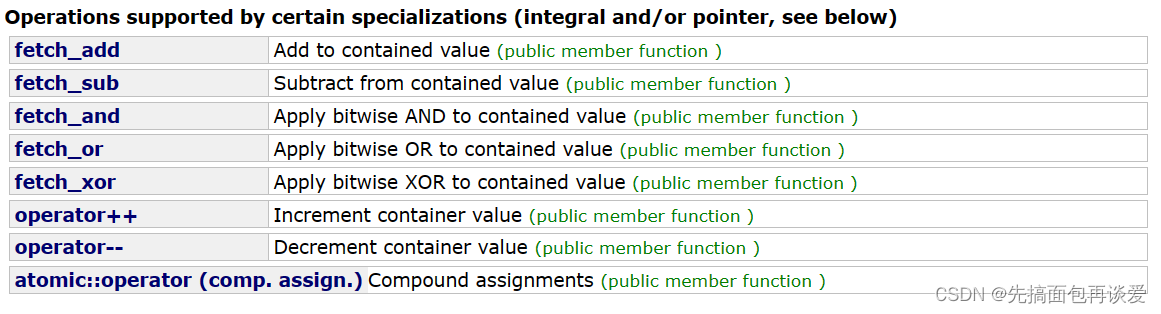
这些操作里面就是用不同平台下的CAS来实现对应的原子操作的。
但是C++不会因为单次写回失败而停止,而是进行多次对比,当原数与获取到的数相同的时候就再写入,那么这里两个线程都并发执行,每次都是只有一个线程执行++操作成功,另一个线程失败,失败了就再次尝试,我再来画一个演示图:
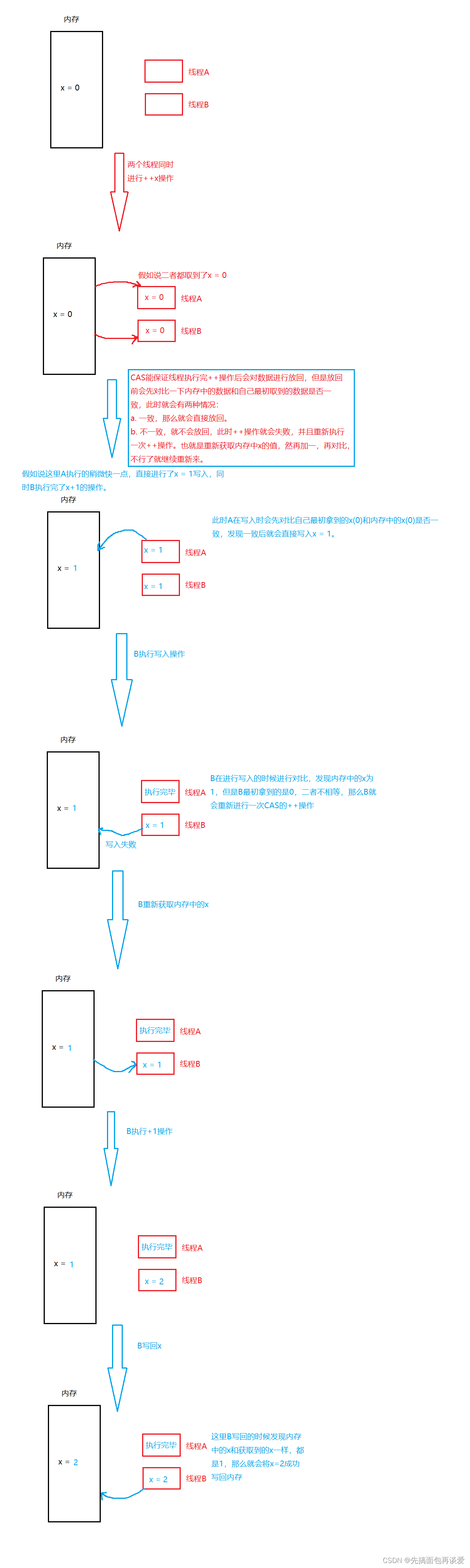
这样如果线程多了也是会有一定的消耗的,不过要比互斥锁高效一点,互斥锁是要排队、阻塞、上下文切换,消耗更大。
所以如果现实中如果是要对变量值进行调整,可以不要加锁,就用atomic处理就很舒服。
这里给一篇无锁队列的文章:无锁队列的实现 ,这一篇是陈皓大佬写的,感兴趣的老铁可以看看。
简单的数据结构可以实现无锁,但是复杂的就很难实现了,无锁的概念并不是真的没有锁,只是换了一种方式。
atomic中+=、-=、&=的时候都提供了运算符重载,用起来很方便。
条件变量condition_variable
条件变量,前面讲Linux的时候在POSIX也学过了,无非还是面向对象,给封装了一下。
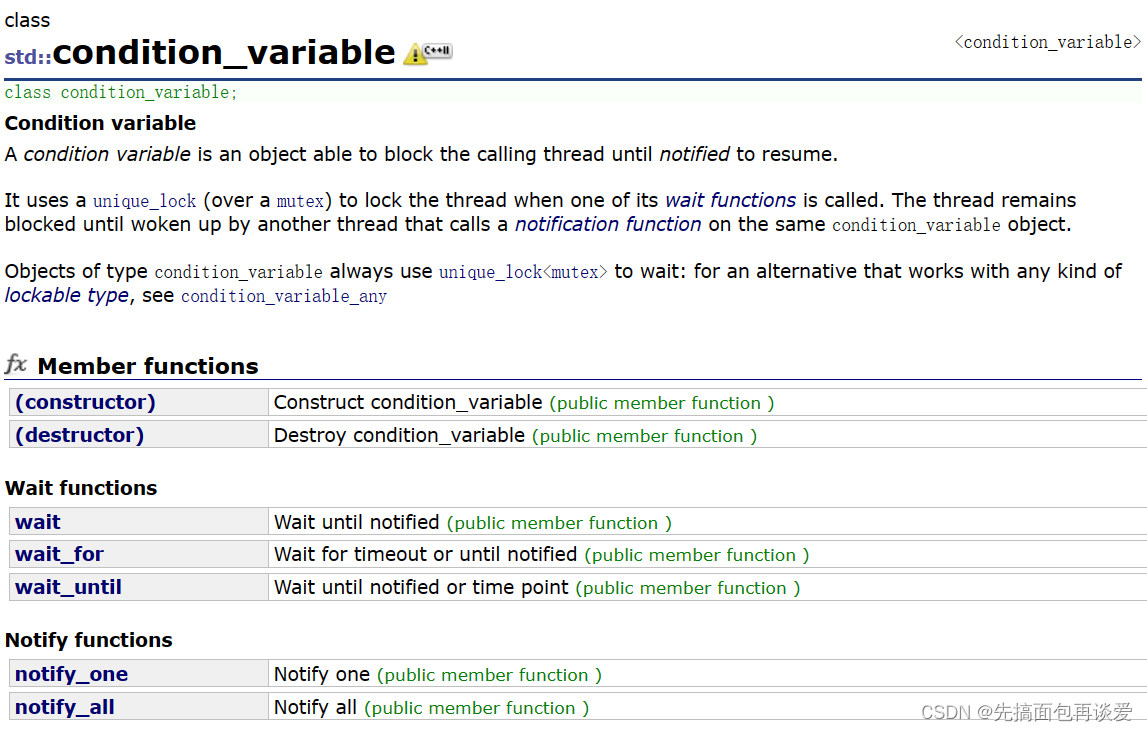
其实就两个重要的接口,wait和notify,还是那样子用,哪个线程调用wait就进入对应条件变量的队列中,别的线程调用notify就唤醒对应条件变量中的一个(notify_one)或者全部(notify_all)线程。
关于wait
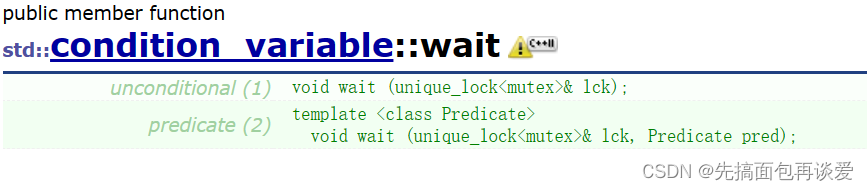
可以看到有两个,一个是只有一个参数unique_lock的,一个是多了一个Predicate先决条件的。
先来说这个只有一个lck的wait,就是直接让调用该函数的线程阻塞,把这个线程放到对应条件变量的队列中,只有当其他线程调用notify的函数的时候才会将这个阻塞的线程唤醒。传unique_lock试听为如果当前调用wait的线程上锁了就要先解锁才能进入阻塞状态,不然就占着锁不放了,那别的线程要锁的时候就要不到,从而出现死锁,所以调用wait会自动先解锁,然后再让线程进入阻塞状态。
第二个wait带了个先决条件,这个先决条件就是一个函数对象,函数对象的返回值要为bool类型的,这第二个wait执行的大致逻辑是这样的:
while (!pred()) wait(lck);
如果函数返回false,就会进入while中,直接调用第一个wait,这样就会使得线程阻塞,此时线程就不会向下执行。就算是其他线程唤醒了这个wait的线程,还是会先循环上去判断一下pred()是否为true,如果pred()还是false就还是会进入while中调用第一个wait,那么就又会导致线程阻塞,这就是先决条件pred。
那么只有同时pred()返回值为true且其他线程调用notify唤醒了当前线程的时候才会让线程跳出while循环去执行下面的语句,不然线程就是一直阻塞的状态。
这里的先决条件用处非常大,至于有多大等会写代码的时候就知道了。
关于notify
就是one和all的区别。
- 调用one的时候就唤醒一个在对应条件变量队列中的线程。
- 调用all的时候就唤醒所有在对应条件变量队列中的线程。
一道面试题
我就直接用这个面试题的例子来演示一下条件变量相关的代码。
【面试题】让两个线程交错打印0 ~ 100,一个打印奇数,一个打印偶数
你自己先构思构思。
说两种方法,两个线程我就用t1和t2来表示,假设让t1打印偶数数,让t2打印奇数。
① yield让出时间片
当t1遇到奇数的时候就让出时间片,只有遇到偶数的时候才打印;
t2遇到偶数的时候也让出时间片,只有遇到奇数的时候才打印。
实现:
// 方法一:让时间片法
int main()
{
int n = 100;
int i = 0;
thread t1(
[&]()
{
for (; i <= n; ++i)
{
// 不是偶数就让出时间片
while(i % 2 != 0)
this_thread::yield();
cout << "thead1 ==>" << i << endl;
}
}
);
thread t2(
[&]()
{
for (; i <= n; ++i)
{
// 不是奇数就让出时间片
while(i % 2 != 1)
this_thread::yield();
cout << "thead2 ==>" << i << endl;
}
}
);
t1.join();
t2.join();
return 0;
}
执行:
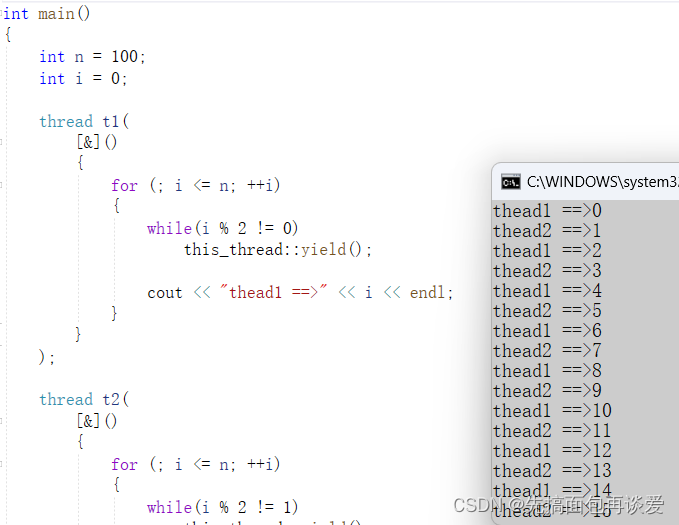
可以实现。这里本质上用的是自旋锁的方式,条件不满足就先让出时间片,等条件满足了再操作。
不过这里会有一点线程安全问题,一个线程在i % 2判断的时候可能另一个线程进行了++操作。
所以这个方法,不太对。但是也可以实现题目所给要求。
② 条件变量
其实这道题的主要思想是想让我们实现一个线程去通知另一个线程。
t1执行完了其任务就通知t2执行,同理t2执行完了就通知t1取执行,也就是生产者消费者模型,用条件变量去解决问题。
假设现在再多一个规定,必须让t1线程打印奇数,t2线程打印偶数。
那这样的话这里就不能用只有一个参数的wait,因为第一个wait无法控制两个线程执行的先后顺序,需要用带先决条件的wait才能控制,先判断一下可以影响谁先执行进而就能控制哪个线程打印奇数,哪个线程打印偶数。
代码:
int main()
{
int n = 100;
int i = 0;
mutex mtx; // 注意条件变量一定是要和锁搭配使用的
condition_variable cv; // 条件变量
bool ready = false; // 用于先决条件的变量
thread t1(
[&]()
{
while (i < n)
{
unique_lock<mutex> lck(mtx); // 上锁
// 先决条件为!ready,只有当ready是false的时候才会执行后续代码
cv.wait(lck, [&]() {return !ready; });
// 被唤醒后修改先决条件,防止当前线程连续打印
ready = true;
cout << "t1 ==>" << i << endl;
++i;
cv.notify_one(); // 操作完后通知另一个线程
}
}
);
thread t2(
[&]()
{
while (i < n)
{
unique_lock<mutex> lck(mtx);
// 先决条件为ready,只有当ready是true的时候才会执行后续代码
cv.wait(lck, [&]() {return ready; });
// 被唤醒后修改先决条件,防止当前线程连续打印
ready = false;
cout << "t2 ==>" << i << endl;
++i;
cv.notify_one();// 操作完后通知另一个线程
}
}
);
t1.join();
t2.join();
return 0;
}
执行结果:
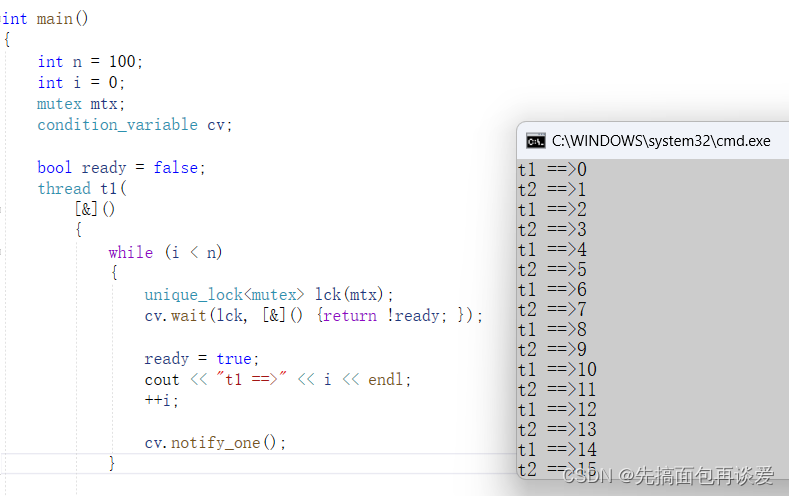
完全ok。
简单说一下,初始ready为false,那么t1执行wait的时候while(!prev())prev是!ready,两个!就是ready,ready为false,那就会跳出while循环不执行单参数的wait,进而执行后续代码,同时t2也会执行先决条件的wait,而此时ready为false,!ready为true,那就会进入while循环中执行单参数wait,此时t2就会阻塞。而t1执行完毕后修改ready为true,再通知t2去执行。
此时t1再循环上去后发现!!ready ? true,那么就会进入while循环中执行wait,此时就会阻塞。而t2在执行先决条件的wait时发现!ready ? false,就会跳出循环,进而执行后续代码,修改ready为false,通知t1执行。如此循环即可实现交错打印。
如果想让t2先执行,直接把开头定义的ready改为true就可以,无论谁先抢到锁通过对先决条件的控制就可以实现让特定线程先执行打印,而且不存在单个线程连续打印的问题。因为某个线程调用先决条件的wait成功后会修改先决条件ready,这样就不会出现本次执行完毕下一次先决wait还成立的情况,从而就不会出现单个线程连续打印的情况。
这里的条件变量还可以实现多个线程交替运行的场景,比如说把ready改为char类型的,把ready = 1、ready = 2、ready = 3 …… 作为先决条件,这样每次执行一个线程,就能达到轮流执行的效果。
通过这里就可以看出多线程的水很深,想要把握住还是有不小的难度的。
智能指针部分的坑
再回到我智能指针的部分, 前面说过,C++中很怕抛异常,尤其是在new/malloc时,需要手动delete/free,如果在开空间后抛异常可能会因为粗心而导致内存泄漏,所以就搞了智能指针来避免这个问题,如果跑了异常就自动释放空间,任何智能指针都有两个基本特征:
- RAII(资源获得即初始化),也就是构造中将指针拷贝给其中的成员,析构中释放所指空间。
- 像指针一样使用,类中重载*和->。
不一样的地方就在对象拷贝、复制的处理:
- auto_ptr:管理权限转移,很挫,不推荐,会导致被拷贝的对象悬空
- unique_ptr:不允许拷贝,不过需要拷贝的场景解决不了。
- shared_ptr:支持拷贝,通过引用计数支持拷贝,但是我前面模拟实现出来的shared_ptr有点问题,就是不支持多线程的shared_ptr的拷贝。
这里要讲的就是shared_ptr中的这个问题。
先来看看我原先写的代码:
namespace FangZhang
{
// 下面的这四个struc都是仿函数,专门用来释放不同指针的空间的
template<class T>
struct Delete
{
void operator()(T* ptr)
{
delete ptr;
}
};
template<class T>
struct DeleteArray
{
void operator()(T* ptr)
{
delete[] ptr;
}
};
template<class T>
struct Free
{
void operator()(T* ptr)
{
free(ptr);
}
};
struct CloseFile
{
void operator()(FILE* pf)
{
fclose(pf);
}
};
// shared_ptr
template<class T, class D = Delete<T>>
class shared_ptr
{
public:
// 构造
shared_ptr(T* ptr = nullptr)
:_ptr(ptr)
, _count(new int(1))
{}
// 拷构
shared_ptr(const shared_ptr<T>& sp)
:_ptr(sp._ptr)
, _count(sp._count)
{
++(*_count);
}
// 专门释放空间的函数
void Release()
{
D()(_ptr);
delete(_count);
}
// 拷赋
shared_ptr<T>& operator=(const shared_ptr<T>& sp)
{
// 判断一下当前所维护的指针是否和sp所维护的指针相同
if (_ptr != sp._ptr)
{
// 不相同了就先让当前指针对应的引用计数--
if (--(*_count) == 0)
{
// 当引用计数变为0的时候就先释放掉当前维护指针的空间和引用计数的空间
Release();
}
// 维护新的指针
_ptr = sp._ptr;
_count = sp._count;
++(*_count);
}
return *this;
}
// 返回引用计数的值
int use_count()
{
return *_count;
}
// 析构
~shared_ptr()
{
if (--(*_count) == 0)
{
Release();
}
}
// 重载*
T& operator*()
{
return *_ptr;
}
// 重载->
T* operator->()
{
return _ptr;
}
// 获取原生指针
T* getPtr()const
{
return _ptr;
}
private:
T* _ptr; // 原生指针
int* _count; // 引用计数
};
}
上面就是我原先实现的shared_ptr,只要知道shared_ptr实现原理就是在堆上开一个对应的引用计数就行。
我先来一个多线程的例子,来看看有什么问题:
int main()
{
// 这里创建了两个shared_ptr,维护的是同一个指针,所以对应引用计数应该为2
FangZhang::shared_ptr<double> sp1(new double(1.11));
FangZhang::shared_ptr<double> sp2(sp1);
vector<thread> v(2);
int n = 10; // 这里我等会不断修改n的值,来看看会有什么问题
for (auto& t : v)
{
t = thread([&](){
/* 线程执行方法中,每次都是拷贝一下sp1,不过是局部对象,每次都会销毁,所以这
里其实sp1对应的引用计数应该一直是2,最后执行完后按理说是不会变的。++(*sp)会
不断修改sp1中double类型成员的值,所以这里最后*sp应该是2*n + 1.11
*/
for (size_t i = 0; i < n; ++i)
{
FangZhang::shared_ptr<double> sp(sp1);
++(*sp);
}
});
}
for (auto& t : v)
{
t.join();
}
// 执行完毕后打印引用计数和*sp1的值
cout << sp1.use_count() << endl;
cout << *sp1 << endl;
return 0;
}
那么我这里先让n = 10试试:
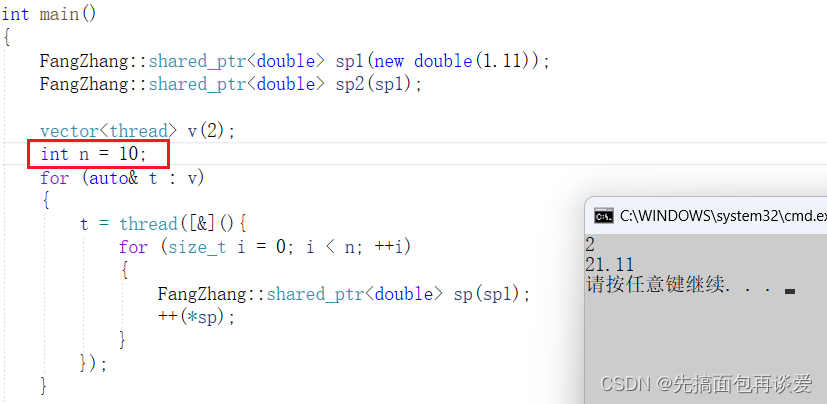
目前看起来是正确的。
n = 100试试:
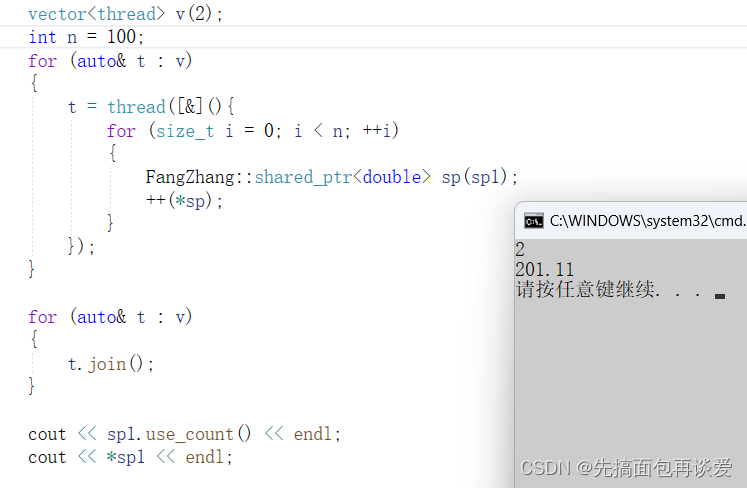
好像还是没问题。
但是我再运行一次:
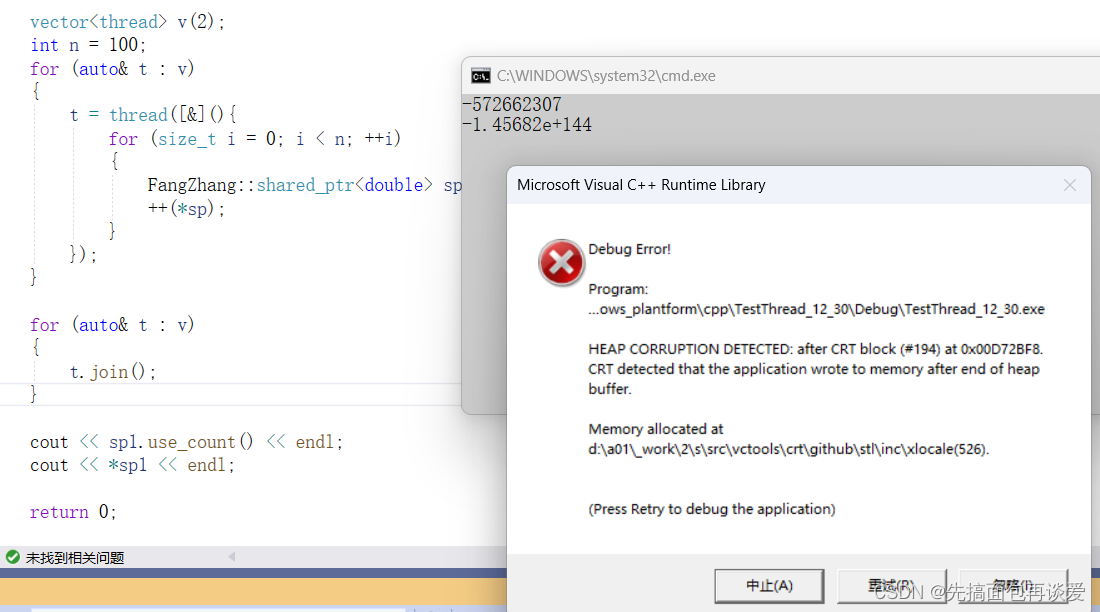
直接崩掉了。。。而且打印的结果还很奇怪。
再运行试试:
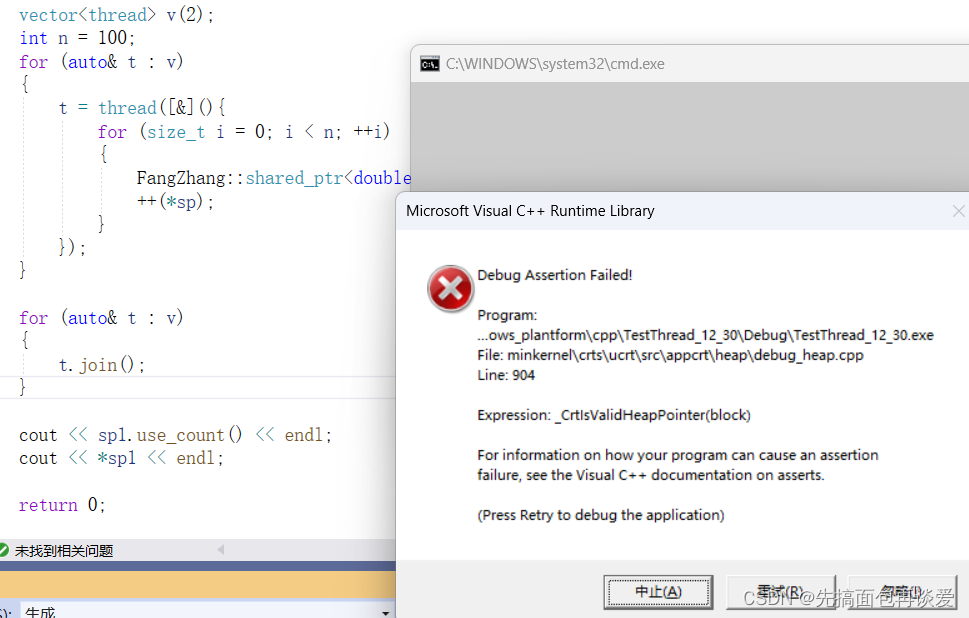
这次崩的更彻底,直接都不打印了。
如果我把n开的更大一点,直接开到10000:
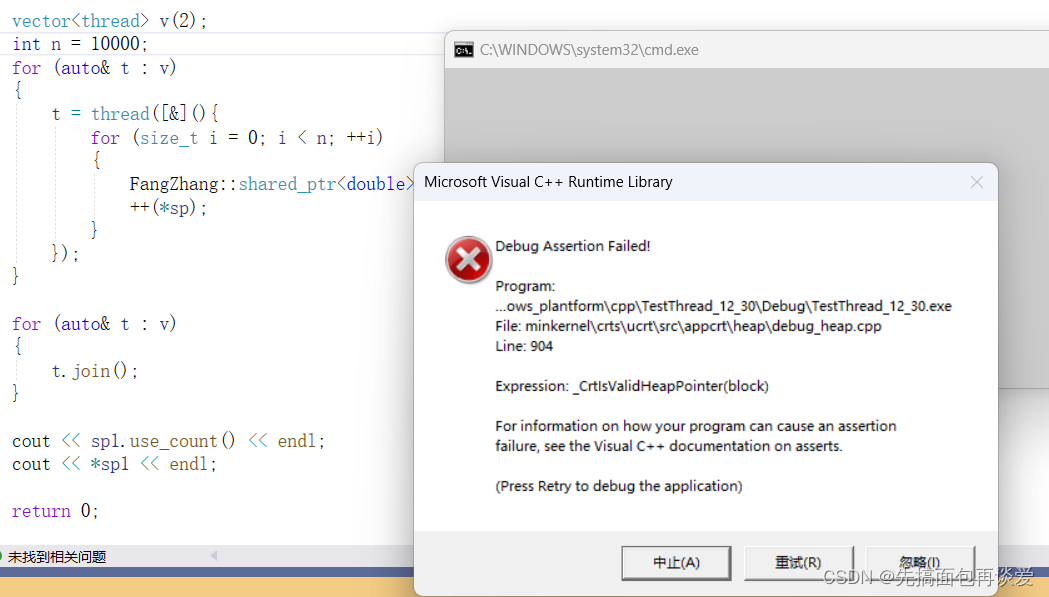
第一次运行就崩了。
问题就在我这里模拟实现的shared_ptr在多线程进行拷贝的时候引用计数是在堆上创建的,每次拷贝都会让引用计数的值加一,去掉一个维护的时候都会让引用计数的值减一,没有进行加锁保护,不是线程安全的。而且进行++(*sp)的时候没有进行加锁保护,也不是线程安全的。
所以这里需要对其中引用计数的操作进行加锁保护。只要是对引用计数进行++或者–都要加锁。
怎么搞呢?直接在类内加一个锁成员就行。

注意这里要给成指针,拷贝构造的时候要拷贝另一个shared_ptr对象的锁,此时mutex没有拷贝构造,就会报错。
专门搞一个用来++(*count)的函数:

构造和拷构:
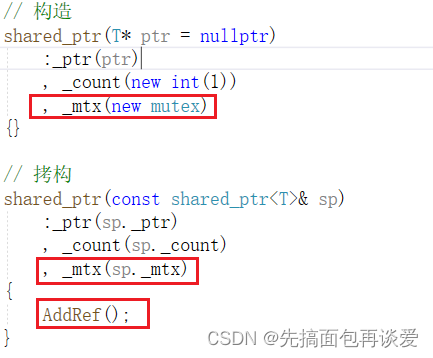
拷赋:

析构:

只有最后一个shared_ptr才需要释放锁。
整体大方向就是这样给引用计数加锁。
不过可以看到,我这里代码写的有点冗余了,我来改改,直接把flag什么的放到Release这个函数里面:
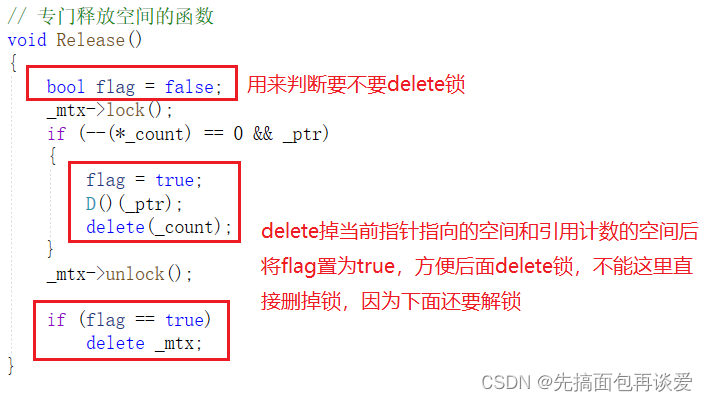
然后拷赋和析构就成了这样:
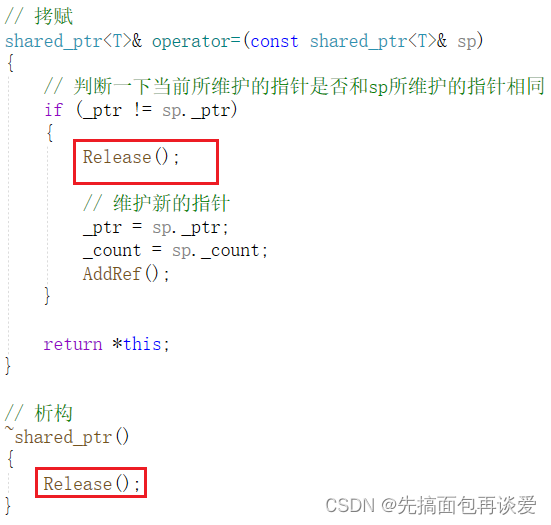
剩下的就没啥要改了。
来测试一下:
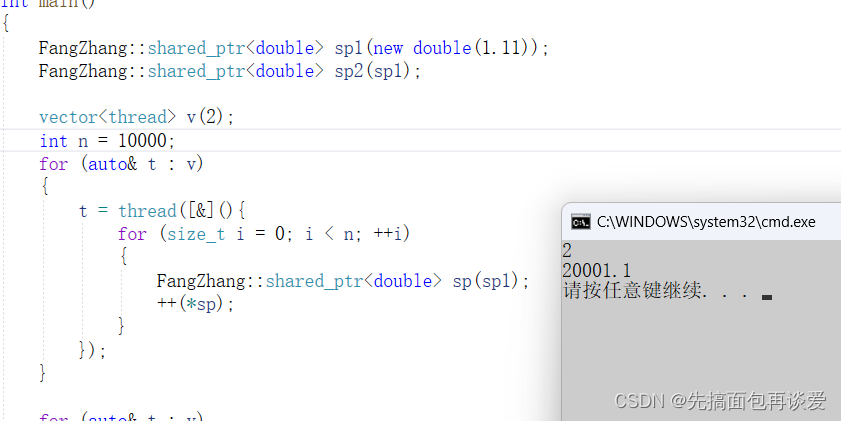
这会10000次拷贝都没啥问题了,引用计数可以保护的很好,不过++(*sp)还是可能出问题,我多运行几次还是会出问题:
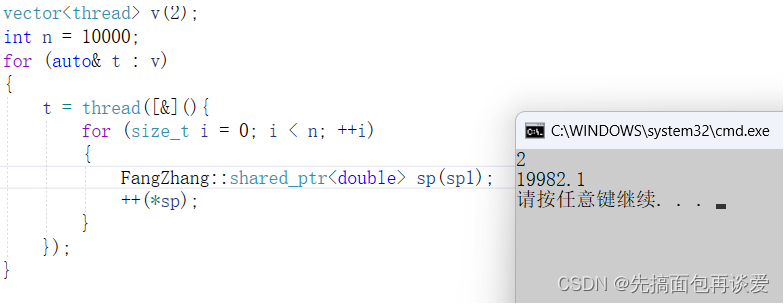
最后打印*sp应该是20001.1的,这里出错了,主要是++(*sp)没有加锁,这里没法在shared_ptr类中解决这个问题,类中只能是给*sp加锁,但是给*sp加锁没用,得给++加锁,所以要在外面加:
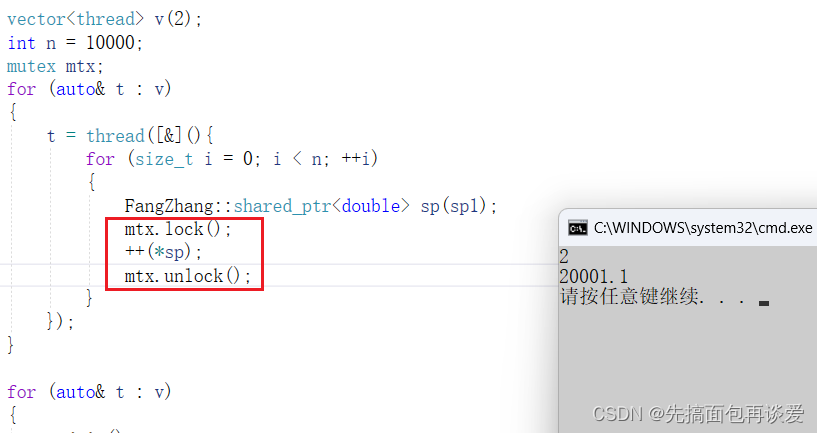
这样就没事了。
故shared_ptr拷贝构造是线程安全的,而我们在实际访问资源操作的时候手动加锁。std中的shared_ptr也是这样的,所以shared_ptr通过引用计数支持了拷贝,但是需要对引用计数的改变加锁保护。
前面讲Linux线程的时候也说过,STL不是线程安全的,所以不要觉得STL是大佬写的就是线程安全的了,STL主要注重的是效率方面的问题,性能达到极致才是主要的,而并不是线程安全的,所以我们在多线程场景下用STL的时候要我们自己来加锁保护,比如多个线程用一个容器,那访问容器的时候就是要加锁保护。
单例模式的坑
再来补充一下前面单例模式中留下的坑,前面讲单例模式的时候说到了懒汉和饿汉的问题。
如果你不太懂单例模式,可以看看我这篇:【C++】特殊类的设计
来简单回顾一下这两个单例模式。
饿汉
饿汉就是一上来就创建一个单例对象,也就是main之前就创建,再静态区创建一个如静态的成员对象,或者是创建一个指针去new,如果对象比较大就可以去new。
特点就是静态成员在main前就创建,而main前是没有多线程的,而实际上写代码的时候可以在饿汉的类中写多线程相关的代码,但是千万不要这样作。
饿汉模式有缺点:
- 对象初始化有点麻烦,影响程序启动速度。
- 多个单例类,如果创建的时候有依赖顺序是无法控制的。
为解决这两个问题,就给出了懒汉模式。
懒汉模式
来先回顾一下懒汉的代码:
class Singleton
{
public:
static Singleton* GetInstance()
{
if (_pInstance == nullptr)
{
_pInstance = new Singleton;
}
return _pInstance;
}
private:
// 构造函数私有
Singleton(){};
// C++11 去掉拷构和拷赋
Singleton(Singleton const&) = delete;
Singleton& operator=(Singleton const&) = delete;
// 静态的成员对象
static Singleton* _pInstance;
};
Singleton* Singleton::_pInstance = nullptr;
只有在使用对象的时候才会去创建对象,但会有新的问题,多线程使用懒汉模式单例对象时,第一次调用GetInstance存在竞争问题,一个调了去new对象,其他线程调了也去new就不行了,看图:

当多线程并行执行的时候,if中可能会有多个线程在执行new操作,每次new的时候前面线程new的空间就找不到了,_pInstance只能找到最后一个线程开出来的空间,想要解决这个问题还是要加锁。
需要在类内搞一个成员锁:

这里搞成静态的,就能保证这个Singleton中只有这一把锁,多个线程执行的时候只会去抢着一把锁。
在GetInstance中用unique_lock:

这里虽然是能保证了new不会内存泄漏,但是还是有个小问题,只有在第一次进行new的时候才需要加锁,后续直接获取_pInstance就行了,但是这里的代码是每个线程进来之后都要进行加锁,然后再解锁,如果每个线程都这样,效率就会有一定的影响。
如果我把锁放到了new的两边行不?也就是这样:

答案是肯定不行。
因为多线程并发的时候还是会有多个线程进入if中,此时只不过是new的更慢了一点,还是会出现内存泄漏。
那如何解决这里的效率问题呢?
再加一层if即可:

我来带你捋一捋。
首先,如果是多线程并发,假如说就两个线程吧,t1和t2,t1和t2首次调用GetInstance的时候可能会同时进入第一层if中,但此一定是有一个线程先抢到锁,假如说t1抢到了,那么t2就要等锁,t1抢到锁后进入第二层if中判断_pInstance为空,那就会new一个Singleton,然后再解锁,此时t2拿到锁,一判断_pIncetance不为空,那就不会new了。
后续如果t1和t2再调用GetInstance的时候就直接通过第一层if判断_pInstance不为空,那么就直接返回_pInstance了,不会再进行加锁解锁的操作。
这样问题就解决了。
说说指令重排问题
new操作,可以分为三步进行:
- 通过operator new开空间
- 使用placement new(定位new)调用构造函数
- 返回指针
其实第三步都可以不用说了,直接改成用指针赋值吧。
CPU可能会进行指令优化,优化后可能会变成先operator new开空间,然后再赋值,最后再调用一下构造,那么如果当t1在最后将要执行构造的时候时间片到了,调度走了,那么t2来的时候一看_pInstance是非空的,就会直接拿到_pInstance,就出问题了,不过一般编译器指令重排都是非常靠谱的,不需要考虑这种情况。如果是真想解决乱序执行的话,可以用内存栅栏(也叫内存屏障),除非是特别重要的东西不能乱需处理时才会机上lfnece啥的,一般不需要考虑。编译器不会做这种无端的优化。
懒汉模式相对于饿汉模式会复杂一点,不过更推荐用懒汉,饿汉的坑有点多。
其实懒汉还有这样的写法:
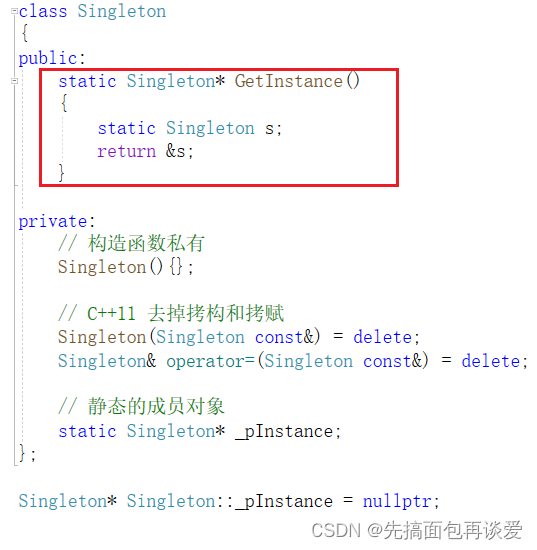
这种写法很巧妙,局部静态对象是在第一次调用其所在函数的时候进行初始化,后续就一直是这个静态对象了,返回其地址就是刚刚写法中的_pInstance,不用创建任何成员变量就能实现,但是这里有个小bug:C++11之前不能这样写,C++11之前的局部静态对象构造函数调用初始化并不能保证线程安全的原子性,但是C++11的时候修复了这个问题,所以这种写法只能在支持C++11之后的编译器上玩。
这些就是本片中的内容,本篇主要讲的是C++中有关线程池的部分,捎带着填了一下我前面博客中一留下来的坑。
到此结束。。。
到此结束。。。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 专攻代码型闪存芯片赛道,芯天下授权世强硬创代理全线产品
- Java可视化物联网智慧工地综合云平台源码 私有化部署
- Unity2D学习笔记 | 《勇士传说》教程 | (五)
- uniapp 微信小程序请求拦截器 接口封装
- 【LeetCode每日一题】410. 分割数组的最大值
- Vue-前端学习随笔-对于Vue生命周期的理解
- 为什么需要消息中间件?
- 大模型日报-20240113
- PythonAnywhere中运行GitHub代码步骤
- ssm/php/node/python公司配件库存管理系统设计与实现