计算机体系结构——多处理机系统
一、概述
重要概念
评估指标
通信延迟
通信延迟=发送开销+跨越时间+传输延迟+接收开销
跨越时间
数字信号从发送方的线路端传送到接收方的线路端所经过的时间。
传输时间
全部的消息量除以线路带宽。
多处理机的架构
根据多处理机系统中处理器个数的多少可将多处理机的类型分为
第一类为集中式共享存储器结构;
第二类为分布式存储器结构;
每一类代表了一种存储器的结构和互连策略。
二、分布式存储器多处理机系统
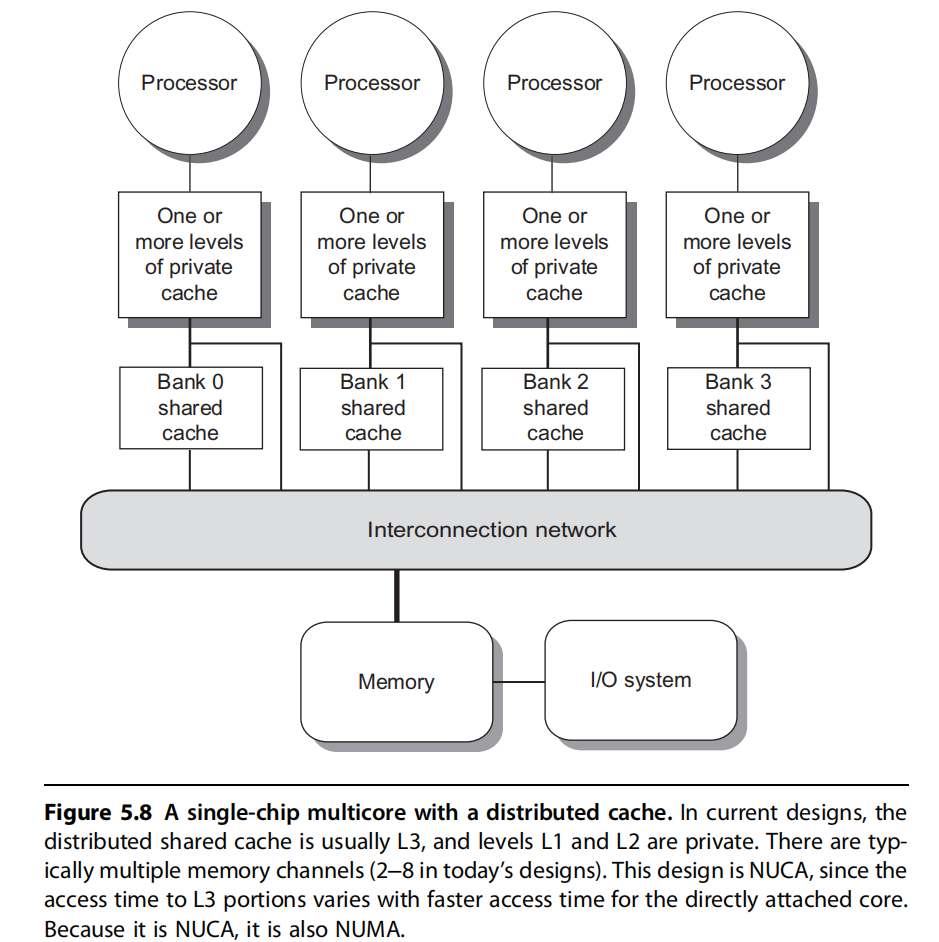
处理器的规模较大,存储器分布到各个处理器上,而非采用集中式。系统中每个结点包含了处理器、存储器、I/O以及互连网络接口。
分布式存储器架构的特征
将存储器分布到各结点有两个优点:
第一,如果大多数的访问是针对本结点的局部存储器,则可降低对存储器和互连网络的带宽要求。
第二,对局部存储器的访问延迟低。
分布式存储器结构最主要的缺点:
处理器之间的通信较为复杂,且各处理器之间访问延迟较大。
地址空间的组织方案
共享地址空间的机器
可利用load和store指令中的地址隐含地进行数据通信,因而可称为共享存储器机器。
(1) 与常用的集中式多处理机使用的通信机制兼容。
(2) 当处理器通信方式复杂或程序执行动态变化时,易于编程;同时在简化编译器设计方面占有优势。
(3) 当通信数据较小时,通信开销较低,带宽利用较好。
(4) 通过硬件控制的Cache减少了远程通信的频度,减少了通信延迟以及对共享数据的访问冲突。
多个地址空间的机器
根据简单的网络协议,通过传递消息来请求某些服务或传输数据,从而完成通信。因而这种机器常称为消息传递机器。
三、集中式存储的多处理机系统
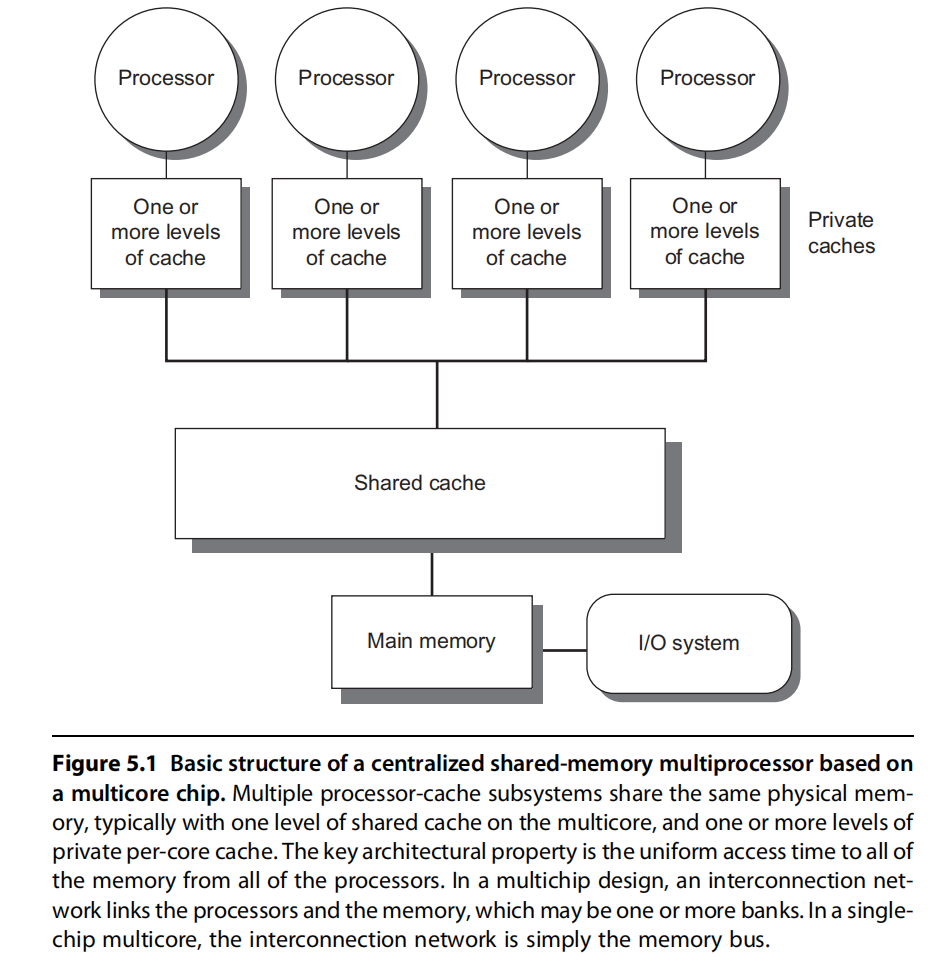
由几个到几十个处理器构成的MIMD机器。各处理器通过大容量的Cache和总线互连,共享一个单独的物理存储器。又称为对称式共享存储器结构机器或者UMA机器。
支持对共享数据和私有数据的Cache缓存的优势
私有数据缓冲在Cache中降低了平均访存时间和对存储器带宽的要求,使程序的行为类似于单机。共享数据的Cache缓存可降低访存时间和对存储器带宽的要求,还可减少多个处理器同时读共享数据所产生的冲突。
四、多处理机间的数据一致性
多处理机存储系统一致性的特征
若一个存储系统满足以下三点,则称该存储系统是一致的。
(1) 处理器P对X单元进行一次写之后又对X单元进行读,读和写之间没有其他处理器对X单元进行写,则读的返回值总是写进的值。
(2) 一个处理器对X单元进行写之后,另一处理器对X单元进行读,读和写之间无其他写,则读X单元的返回值应为写进的值。
(3) 对同一单元的写是顺序化的,即任意两个处理器对同一单元的两次写,从所有处理器看来顺序都应是相同的。
跟踪共享数据状态的技术
决定了多处理机间数据交换的组织方式。
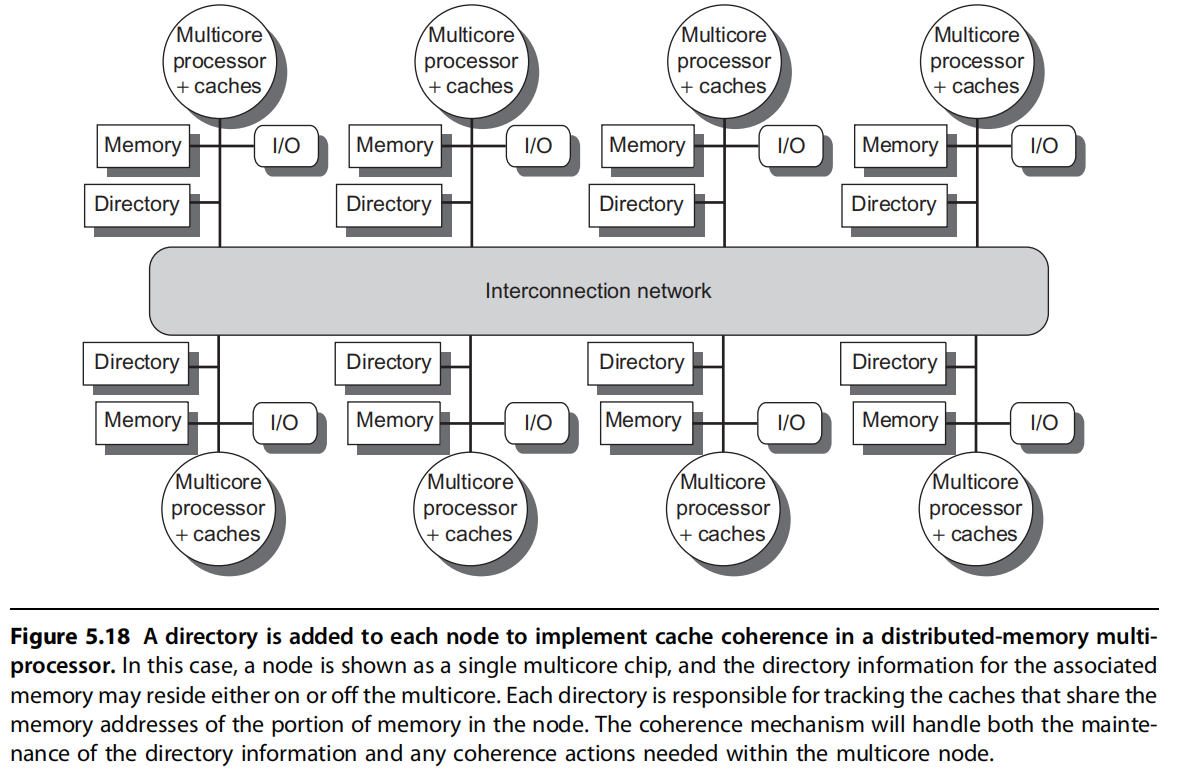
目录协议
用一种专用的存储器所记录的数据结构,它记录着可以进入Cache的每个数据块的访问状态、该块在各个处理器的共享状态以及是否修改过等信息。
目录的特征
目录是一种专用的存储器所记录的数据结构,记录着可以进入Cache的每个数据块的访问状态,详见下一节。
宿主结点:存放有存储器块和对应地址目录项的结点。
目录承担了一致性协议操作的主要功能:
发往一个目录的消息会产生两种不同类型的操作
更新目录状态
发送消息(从而能够)满足请求服务
目录项可能接收到三种不同的请求
读失效、写失效、数据写回
实现方式
在每个节点增加了目录存储器用于存放目录,cache的每一块在目录中对应有一项;
每一个目录项主要包含的状态:
- 目录对应存储块当前状态:有无该块,块是否共享还是独占写状态
- 是否共享(shared)
在一个或多个处理器上有这个块的拷贝,且主存中的值是最新值(所以Cache均相同) - 未缓冲
所有处理器的Cache都没有此块的拷贝。 - 修改位
仅有一个处理器上有此块的拷贝,且已对此块进行了写操作,而主存的拷贝仍是旧的,这个处理器称为该块的拥有者。
- 位向量,共有N(处理器的个数)位,每一位对应于一个处理器的局部Cache,用于指出该Cache中有无该存储块的拷贝。
当此块被共享时,每个位指出与之对应的处理器是否有此块的拷贝;当此块为专有时,可根据位向量来寻找此块的拥有者
CPU请求时块的状态变化
1)当一个块处于未缓冲状态,对此块发出的请求及处理操作为:
读失效:将存储器数据送往请求方处理器,且本处理器成为此块的唯一共享节点,本块状态转为共享。
写失效:将存储器数据送往请求方处理器,此块成为调整为modified。
2)当一个块处于共享状态,mem中的数据是其当前最新值,对此块发出的请求及处理操作为:
读失效:将存储器数据送往请求方处理器,并将其纳入共享集合(在位向量中标记)。
写失效:将数据送往请求方处理器,对共享集合中所有的处理器发送写作废消息,且将共享集合置为仅含有此处理器,本块状态变为modified
3)当一个块处于modified状态,且本块最新值保存在共享集合指出的拥有者处理器中,对此块发出的请求及处理操作为:
读失效:将“取数据”消息发往拥有者处理器,使该块的状态变为共享,并将数据送回目录结点写入存储器,进而把该数据返送请求方处理器,将请求方处理器加入共享集合。
写失效:本块将有一个新的拥有者
数据写回:拥有者处理器的Cache要替换此块时必须将其写回,从而使存储器中有最新拷贝(宿主结点实际上成为拥有者),此块成为非共享,共享集合为空。
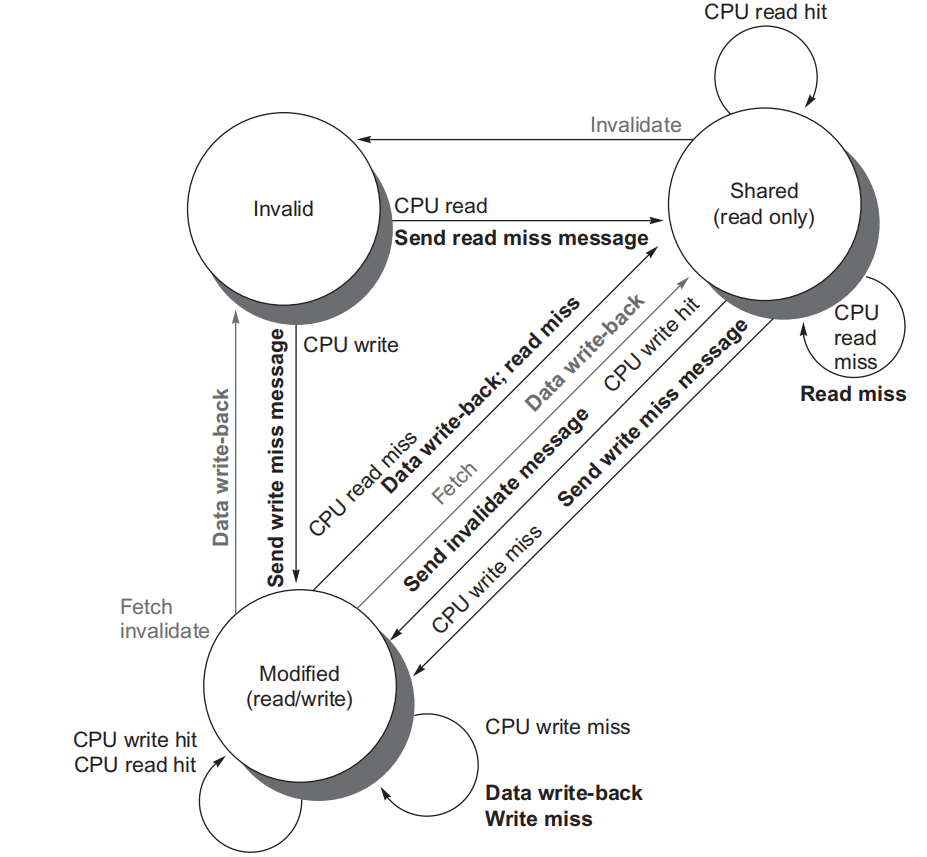
监听协议
当物理存储器中的数据块被调入Cache时,其共享状态信息与该数据块一起放在该Cache中。系统中没有集中的状态表。这些Cache通常连在共享存储器的总线上,各个Cache控制器通过监听总线来判断它们是否有总线上请求的数据块。
(1)小规模多处理机中实现写作废协议的关键利用总线进行作废操作,每个块的有效位使作废机制的实现比较容易。
(2)写直达Cache,因为所有写的数据同时被写回主存,则从主存中总可以取到最新的数据值。
(3)对于写回Cache(没有立刻更新),得到数据的最新值会困难些,因为最新值可能在某个cache中,也可能在主存中。
(4)在写回Cache条件下的实现技术:
1)用Cache中块的标志位实现监听过程
2)给每个Cache块加一个特殊的状态位说明其是否为共享
3)因为每次总线任务均要检查Cache的地址位,这可能与CPU对Cache的访问冲突(因为一个Cache访问需要监听总线比对地址,CPU也要访问Cache,也要对地址进行操作;一边挂CPU一边挂总线,从而造成冲突)
通过下列两种技术之一降低冲突:
复制标志位(CPU操作一套,总线一套;并行操作)
采用多级包含Cache(每级Cache都有自己的标志位,CPU操作第一级Cache的标识,总线操作三级Cache的标识)
cache一致性协议
决定了在多处理机系统中某数据组织方式下实现cache一致性的准则。
写作废协议
在一个处理器写某个数据项之前保证它对该数据项有唯一的访问权。
写更新协议
当一个处理器写某数据项时,通过广播使其他Cache中所有对应的该数据项副本进行更新。
多处理机间的同步
原子操作
原子交换
可以一条指令完成。
将一个存储单元的值和一个寄存器的值进行交换,且交换是不可分的。
这个存储单元可以称为同步锁,假设0代表锁可用,1代表锁不可用;交换后可以表示存储单元的锁被寄存器所对应的进程占用
测试并置(test_and_set)
可以一条指令完成。
先测试一个值,如果符合条件则修改其值。(存储单元里对应的锁是0,读出来(测试)发现是0(满足条件),空闲,就占用这个锁;然后+1,修改其值)。
fetch and increment
可以一条指令完成。
返回存储单元的值并自动增加该值(读出来0自动加1)
lr和sc指令
两条指令完成。
先链取,再条件存——成功返回1,失败返回0,从第二条指令的返回值可以判断该指令对的执行是否成功,即如果取回来是0,则其他线程仍在占用,本线程占用失败;如果返回值是1 ,表示本线程占用成功。
实现多处理机的旋转锁
指处理器环绕一个锁不停地旋转而请求获得该锁。处理器环绕一个锁不停地旋转(测试)而请求获得该锁。当锁的占用时间很少以及加锁过程延迟很低时可采用旋转锁。
只要敢占这个锁,同步锁在这里同步的处理机进程数量很多的时候,自旋锁阻塞处理器,在循环中等待锁被释放,旋转锁开销会很大
栅栏同步
并行循环程序中一个常用的同步操作。
栅栏强制所有到达该栅栏的进程进行等待,直到全部的进程到达栅栏,然后释放全部的进程,从而形成同步。栅栏的典型实现是用两个旋转锁:一个用来记录到达栅栏的进程数,另一个用来封锁进程直至最后一个进程到达栅栏。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 关于pycharm无法进入base界面的问题
- 在Github逛街
- LVM究竟有多强大?原理和企业实战案例全解析
- MindSpore Serving与TGI框架 の 对比
- 【重学C语言】一、C语言简介
- 【2058错误】sql软件链接数据库 mysql 报错误2058
- 系统学习Python——装饰器:函数装饰器-[装饰器状态保持方案:类实例属性]
- Java guava partition方法拆分集合&自定义集合拆分方法
- 接口测试到底怎么做,5分钟时间看完这篇文章彻底搞清楚
- QT (C++)定位内存越界(踩内存)问题