《现代C++语言核心特性解析》笔记草稿
仅供学习记录之用,谢绝转发

第1章 新基础类型(C++11~C++20)
1.1 整数类型long long
更多笔记
“在C++中应该尽量少使用宏,用模板取而代之是明智的选择。C++标准中对标准库头文件做了扩展,特化了long long和unsigned long long版本的numeric_ limits类模板。这使我们能够更便捷地获取这些类型的最大值和最小值”。
1.2 新字符类型char16_t和char32_t
1.2.1 字符集和编码方法
1.2.2 使用新字符类型char16_t和char32_t
“char utf8c = u8’a’在C++11标准中实际上是无法编译成功的,因为在C++11标准中u8只能作为字符串字面量的前缀,而无法作为字符的前缀。这个问题直到C++17标准才得以解决”。
“char utf8c = u8’好’是无法通过编译的,因为存储“好”需要3字节,显然utf8c只能存储1字节,所以会编译失败。”
1.2.3 wchar_t存在的问题
1.2.4 新字符串连接
1.2.5 库对新字符类型的支持
“C11在中增加了4个字符的转换函数,在C++17标准中已经不被推荐使用了,所以应该尽量避免使用它们。”
1.3 char8_t字符类型 【c++20】
“C++20标准新引入的类型char8_t可以解决以上问题,它可以代替char作为UTF-8的字符类型。char8_t具有和unsigned char相同的符号属性、存储大小、对齐方式以及整数转换等级。引入char8_t类型后,在C++17环境下可以编译的UTF-8字符相关的代码会出现问题”
1.4 总结
第2章 内联和嵌套命名空间(C++11~C++20)
2.1 内联命名空间的定义和使用
2.2 嵌套命名空间的简化语法 【c++17】
C++17标准允许使用一种更简洁的形式描述嵌套命名空间:
 “在C++20中,我们可以这样定义内联命名空间:
“在C++20中,我们可以这样定义内联命名空间:

2.3 总结
第3章 auto占位符(C++11~C++17)
3.1 重新定义的auto关键字
“在C++11中静态成员变量是可以用auto声明并且初始化的,不过前提是auto必须使用const限定符”
“遗憾的是,const限定符会导致i常量化,显然这不是我们想要的结果。幸运的是,在C++17标准中,对于静态成员变量,auto可以在没有const的情况下使用“。
“按照C++20之前的标准,无法在函数形参列表中使用auto声明形参(注意,在C++14中,auto可以为lambda表达式声明形参)”
3.2 推导规则
3.3 什么时候使用auto
3.4 返回类型推导【c++14】
“C++14标准支持对返回类型声明为auto的推导,例如:”
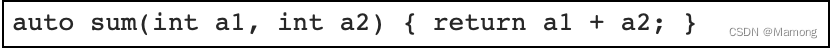
3.5 lambda表达式中使用auto类型推导
3.6 非类型模板形参占位符【c++17】
“C++17标准对auto关键字又一次进行了扩展,使它可以作为非类型模板形参的占位符。”
3.7 总结
第4章 decltype说明符(C++11~C++17)
4.1 回顾typeof和typeid
“在C++11标准发布以前,GCC的扩展提供了一个名为typeof的运算符。通过该运算符可以获取操作数的具体类型。”
“C++标准还提供了一个typeid运算符来获取与目标操作数类型有关的信息。获取的类型信息会包含在一个类型为std::type_info的对象里。我们可以调用成员函数name获取其类型名,成员函数name返回的类型名在C++标准中并没有明确的规范,所以输出的类型名会因编译器而异。”
 “另外,还有3点也需要注意。”
“另外,还有3点也需要注意。”
“1.typeid的返回值是一个左值,且其生命周期一直被扩展到程序生命周期结束。”
“2.typeid返回的std::type_info删除了复制构造函数,若想保存std::type_info,只能获取其引用或者指针”
“3.typeid的返回值总是忽略类型的 cv 限定符,也就是typeid(const T)== typeid(T))。”
“虽然typeid可以获取类型信息并帮助我们判断类型之间的关系,但遗憾的是,它并不能像typeof那样在编译期就确定对象类型。”
4.2 使用decltype说明符
“C++11标准引入了decltype说明符,使用decltype说明符可以获取对象或者表达式的类型,其语法与typeof类似”
“auto是返回类型的占位符,参数类型分别是T1和T2,我们利用decltype说明符能推断表达式的类型特性,在函数尾部对auto的类型进行说明,如此一来,在实例化sum函数的时候,编译器就能够知道sum的返回类型了。”
“上述用法只推荐在C++11标准的编译环境中使用,因为C++14标准已经支持对auto声明的返回类型进行推导了”。“auto作为返回类型的占位符还存在一些问题,下面的例子中,auto被推导为值类型,而不是需要的引用类型。
 “如果想正确地返回引用类型,则需要用到decltype说明符:
“如果想正确地返回引用类型,则需要用到decltype说明符:

4.3 推导规则
“decltype(e)(其中e的类型为T)的推导规则有5条。
1.如果e是一个未加括号的标识符表达式(结构化绑定除外)或者未加括号的类成员访问,则decltype(e)推断出的类型是e的类型T。如果并不存在这样的类型,或者e是一组重载函数,则无法进行推导。
2.如果e是一个函数调用或者仿函数调用,那么decltype(e)推断出的类型是其返回值的类型。
3.如果e是一个类型为T的左值,则decltype(e)是T&。
4.如果e是一个类型为T的将亡值,则decltype(e)是T&&。
5.除去以上情况,则decltype(e)是T。”
4.4 cv限定符的推导
“通常情况下,decltype(e)所推导的类型会同步e的cv限定符”
“当e是未加括号的成员变量时,父对象表达式的cv限定符会被忽略,不能同步到推导结果。当e是加括号的数据成员时,父对象表达式的cv限定符会同步到推断结果。”
4.5 decltype(auto) 【c++14】
“在C++14标准中出现了decltype和auto两个关键字的结合体:decltype(auto)。它的作用简单来说,就是告诉编译器用decltype的推导表达式规则来推导auto。另外需要注意的是,decltype(auto)必须单独声明,也就是它不能结合指针、引用以及cv限定符。”
“使用decltype(auto)消除返回类型后置的语法”

4.6 decltype(auto)作为非类型模板形参占位符 【c++17】
“在C++17标准中decltype(auto)也能作为非类型模板形参的占位符,其推导规则和上面介绍的保持一致”

4.7 总结
第5章 函数返回类型后置(C++11)
5.1 使用函数返回类型后置声明函数
“使用传统函数声明语法的foo1无法将函数指针类型作为返回类型直接使用,所以需要使用typedef给函数指针类型创建别名bar,再使用别名作为函数foo1的返回类型。而使用函数返回类型后置语法的foo2则没有这个问题。同样,auto作为返回类型占位符,在->后声明返回的函数指针类型int(*)(int)即可。”

5.2 推导函数模板返回类型
“C++11标准中函数返回类型后置的作用之一是推导函数模板的返回类型,当然前提是需要用到auto和decltype说明符”

5.3 总结
第6章 右值引用(C++11 C++17 C++20)
6.1 左值和右值
在C++中所谓的左值一般是指一个指向特定内存的具有名称的值(具名对象),它有一个相对稳定的内存地址,并且有一段较长的生命周期。而右值则是不指向稳定内存地址的匿名值(不具名对象),它的生命周期很短,通常是暂时性的。基于这一特征,我们可以用取地址符&来判断左值和右值,能取到内存地址的值为左值,否则为右值。
x++是右值,因为在后置++操作中编译器首先会生成一份x值的临时复制,然后才对x递增,最后返回临时复制内容。而++x则不同,它是直接对x递增后马上返回其自身,所以++x是一个左值。
“对于值类型x,在函数返回的时候编译器并不会返回x本身,而是返回x的临时复制,此时返回的是右值。”
“通常字面量都是一个右值,但字符串字面量是左值,因为编译器会将字符串字面量存储到程序的数据段中,程序加载的时候也会为其开辟内存空间,所以我们可以使用取地址符&来获取字符串字面量的内存地址”
6.2 左值引用
“左值引用传参时,可以免去创建临时对象的操作”
“常量左值引用除了能引用左值,还能够引用右值”
“虽然在结果上const int &x = 11和const int x = 11是一样的,但是从语法上来说,前者是被引用了,所以语句结束后11的生命周期被延长,而后者当语句结束后右值11应该被销毁。”
6.3 右值引用
“右值引用是一种引用右值且只能引用右值的方法。右值引用是在类型后添加&&”
“右值引用的特点之一是可以延长右值的生命周期,从而减少对象复制,提升程序性能。”
6.4 右值的性能优化空间
“很多情况下右值都存储在临时对象中,当右值被使用之后程序会马上销毁对象并释放内存。这个过程可能会引发一个性能问题”
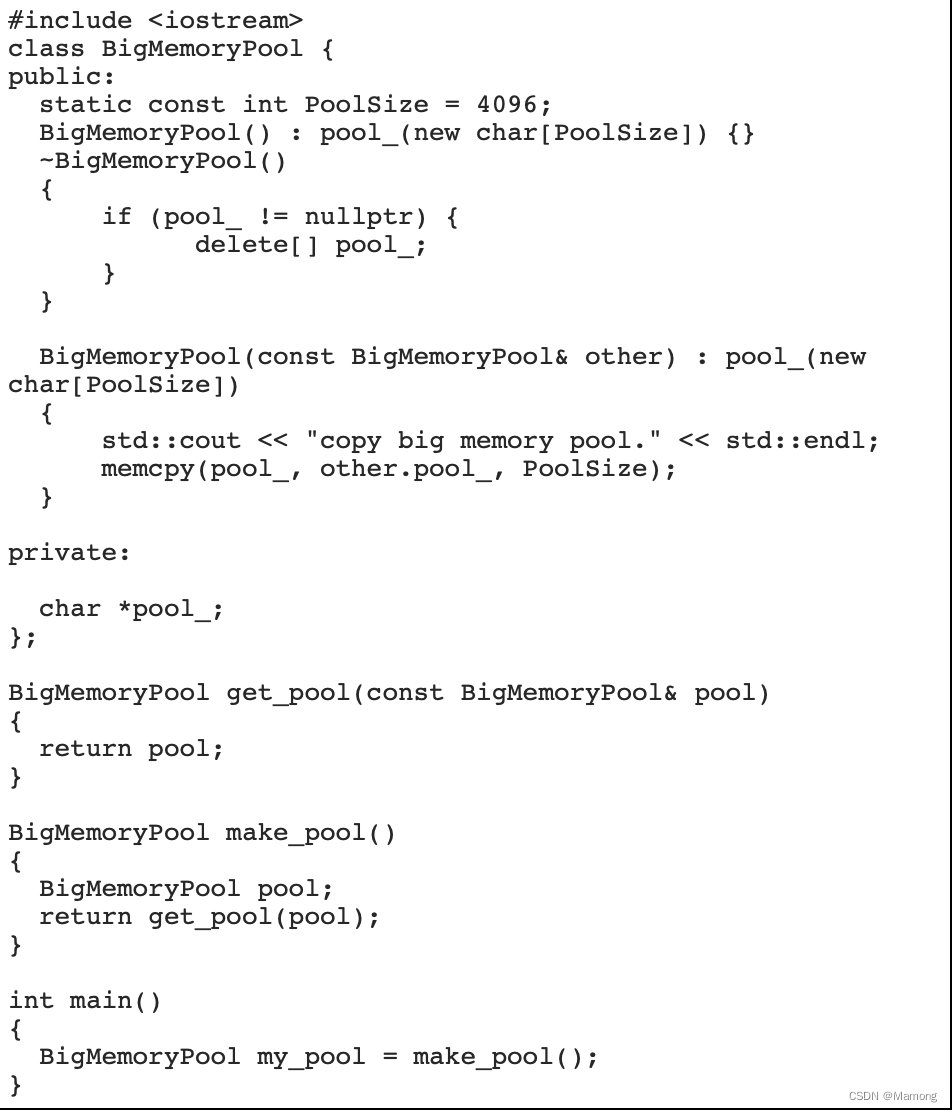 “以上代码同样需要加上编译参数-fno-elide-constructors,编译运行程序会在屏幕上输出字符串:”
“以上代码同样需要加上编译参数-fno-elide-constructors,编译运行程序会在屏幕上输出字符串:”
“copy big memory pool.
copy big memory pool.
copy big memory pool.”
“可以看到BigMemoryPool my_pool = make_pool();调用了3次复制构造函数。
1.get_pool返回的BigMemoryPool临时对象调用复制构造函数复制了pool对象。
2.make_pool返回的BigMemoryPool临时对象调用复制构造函数复制了get_pool返回的临时对象。
3.main函数中my_pool调用其复制构造函数复制make_pool返回的临时对象。”
6.5 移动语义
“如果有办法能将临时对象的内存直接转移到my_pool对象中,不就能消除内存复制对性能的消耗吗?好消息是在C++11标准中引入了移动语义,它可以帮助我们将临时对象的内存移动到my_pool对象中,以避免内存数据的复制。”

“在上面的代码中增加了一个类BigMemoryPool的构造函数BigMemoryPool (BigMemoryPool&& other),它的形参是一个右值引用类型,称为移动构造函数。它接受的是一个右值,其核心思想是通过转移实参对象的数据以达成构造目标对象的目的,也就是说实参对象是会被修改的。在移动构造函数中没有了复制构造中的内存复制,取而代之的是简单的指针替换操作。它将实参对象的pool_赋值到当前对象,然后置空实参对象以保证实参对象析构的时候不会影响这片内存的生命周期。”
“编译运行这段代码,其输出结果如下:
copy big memory pool.
move big memory pool.
move big memory pool.
可以看到后面两次的构造函数变成了移动构造函数,因为这两次操作中源对象都是右值(临时对象),对于右值编译器会优先选择使用移动构造函数去构造目标对象。当移动构造函数不存在的时候才会退而求其次地使用复制构造函数。在移动构造函数中使用了指针转移的方式构造目标对象,所以整个程序的运行效率得到大幅提升。”
“除移动构造函数能实现移动语义以外,移动赋值运算符函数也能完成移动操作,继续以BigMemoryPool为例,在这个类中添加移动赋值运算符函数:”

这段代码编译运行的结果是:
copy big memory pool.
move big memory pool.
move(operator=) big memory pool.”
“可以看到赋值操作my_pool = make_pool()调用了移动赋值运算符函数,这里的规则和构造函数一样,即编译器对于赋值源对象是右值的情况会优先调用移动赋值运算符函数,如果该函数不存在,则调用复制赋值运算符函数”
最后有两点需要说明一下。
1.同复制构造函数一样,编译器在一些条件下会生成一份移动构造函数,这些条件包括:没有任何的复制函数,包括复制构造函数和复制赋值函数;没有任何的移动函数,包括移动构造函数和移动赋值函数;也没有析构函数。编译器生成的移动构造函数和复制构造函数并没有什么区别。
2.虽然使用移动语义在性能上有很大收益,但是却也有一些风险,这些风险来自异常。”
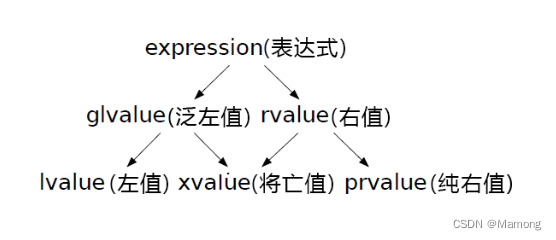
6.6 值类别
“值类别是C++11标准中新引入的概念,具体来说它是表达式的一种属性,该属性将表达式分为3个类别,它们分别是左值(lvalue)、纯右值(prvalue)和将亡值(xvalue)”
“C++98的时候,已经有了一些关于左值和右值的概念了”
“C++11中右值引用的出现,值类别被赋予了全新的含义。”
C++11中由于引入了移动语义,其根据一个表达式的两个独立的属性划分了值的类型。这两个属性分别是:
是否具有身份“Identity”:即,是否可以确定两个表达式指向同一个“对象(object)”,这里注意对象在C++标准中是“一片内存”区域的代称。即,这个表达式是否表示了一个内存区域
是否可以被移动:即,移动构造函数,移动赋值函数,以及其他实现移动语义的函数(比如一个参数接受一个右值引用)是否可以绑定到这个表达式上。
根据这个标准,可以划分出四种值类型:
有身份,不可被移动:称其为左值,lvalue
有身份,可被移动:称其为“临期值”,eXpiring value, xvalue
没有身份,可被移动:称其为“纯右值”,prvalue
没有身份,不可被移动:这样的东西显然没意义
同时,最为重要的,C++11将有身份的值被称为泛化左值,glvalue;可被移动的值被称为右值,rvalue. 因此,概念上说,glvalue都将在某一时间占用一定的空间,而rvalue都可以被移动,但rvalue也可能占据存储空间。
C++17标准规定,表达式首先被分为了泛左值(glvalue)和右值(rvalue),其中泛左值被进一步划分为左值和将亡值,右值又被划分为将亡值和纯右值。”
C++17 为了进一步支持copy elision,C++17将纯右值,以及纯右值初始化出来的对象分离开来(即prvalue变xvalue的过程,temporary metarialization). 也因此,C++17中,prvalue不再是可被移动的了,这样一来,就得到了下面的示意图:
“1.所谓泛左值是指一个通过评估能够确定对象、位域或函数的标识的表达式。简单来说,它确定了对象或者函数的标识(具名对象)。
2.而纯右值是指一个通过评估能够用于初始化对象和位域,或者能够计算运算符操作数的值的表达式。
3.将亡值属于泛左值的一种,它表示资源可以被重用的对象和位域,通常这是因为它们接近其生命周期的末尾,另外也可能是经过右值引用的转换产生的。
剩下的两种类别就很容易理解了,其中左值是指非将亡值的泛左值,而右值则包含了纯右值和将亡值。”
“产生将亡值的途径有两种,第一种是使用类型转换将泛左值转换为该类型的右值引用。比如static_cast<BigMemoryPool&&>(my_pool)。
第二种在C++17标准中引入,我们称它为临时量实质化,指的是纯右值转换到临时对象的过程。“
推荐阅读:C++中的左值右值(值类)
6.7 将左值转换为右值
“在C++11标准中可以在不创建临时值的情况下显式地将左值通过static_cast转换为将亡值,通过值类别的内容我们知道将亡值属于右值,所以可以被右值引用绑定。值得注意的是,由于转换的并不是右值,因此它依然有着和转换之前相同的生命周期和内存地址。它的最大作用是让左值使用移动语义。”
“在C++11的标准库中还提供了一个函数模板std::move帮助我们将左值转换为右值,这个函数内部也是用static_cast做类型转换。只不过由于它是使用模板实现的函数,因此会根据传参类型自动推导返回类型,省去了指定转换类型的代码。另一方面从移动语义上来说,使用std::move函数的描述更加准确。所以建议读者使用std::move将左值转换为右值而非自己使用static_cast转换”
6.8 万能引用和引用折叠

万能引用既可以绑定左值也可以绑定右值,甚至const和volatile的值都可以绑定。
“所谓的万能引用是因为发生了类型推导,在T&&和auto&&的初始化过程中都会发生类型的推导。万能引用能如此灵活地引用对象,实际上是因为在C++11中添加了一套引用叠加推导的规则——引用折叠。”

“只要有左值引用参与进来,最后推导的结果就是一个左值引用。只有实际类型是一个非引用类型或者右值引用类型时,最后推导出来的才是一个右值引用。”
6.9 完美转发
“万能引用最典型的用途被称为完美转发。对于万能引用的形参来说,如果实参是给左值,则形参被推导为左值引用;反之如果实参是一个右值,则形参被推导为右值引用,所以下面的代码无论传递的是左值还是右值都可以被转发,而且不会发生多余的临时复制”
“和移动语义的情况一样,显式使用static_cast类型转换进行转发不是一个便捷的方法。在C++11的标准库中提供了一个std::forward函数模板,在函数内部也是使用static_cast进行类型转换,只不过使用std::forward转发语义会表达得更加清晰,std::forward函数模板的使用方法也很简单”
6.10 针对局部变量和右值引用的隐式移动操作
“新标准的编译器在某些情况下将隐式复制修改为隐式移动”
“对于局部变量也有相似的规则,只不过大多数时候编译器会采用更加高效的返回值优化代替移动操作”
“对于左值要调用复制构造函数。要实现移动语义,C++20标准规定在这种情况下可以隐式采用移动语义完成赋值。具体规则如下。
可隐式移动的对象必须是一个非易失或一个右值引用的非易失自动存储对象,在以下情况下可以使用移动代替复制。
1.return或者co_return语句中的返回对象是函数或者lambda表达式中的对象或形参。
2.throw语句中抛出的对象是函数或try代码块中的对象。”
6.11 总结
第7章 lambda表达式(C++11~C++20)
7.1 lambda表达式语法
7.2 捕获列表
7.2.1 作用域
“捕获列表中的变量存在于两个作用域——lambda表达式定义的函数作用域以及lambda表达式函数体的作用域。前者是为了捕获变量,后者是为了使用变量。另外,标准还规定能捕获的变量必须是一个自动存储类型。简单来说就是非静态的局部变量。”
如果该变量是const非volatile的整型或枚举类型,并且已经常量表达式初始化,那么不需要在捕获列表中捕获;如果声明为constexpr那么就算不是int也能直接捕获。还需注意的是,如果前面捕获了一堆东西,但是在lambda中没有进行使用,相当于你什么都没有捕获。
/** 没有进行使用 */
int a;
int b;
int c;
int d;
auto f = [=]()
{
return 1;
};
std::cout << sizeof f << std::endl; // 输出 1
/** 对a,b进行使用,返回 a + b 的大小 */
int a;
int b;
int c;
int d;
auto f = [=]()
{
int w = a + b;
return w;
};
std::cout << sizeof f << std::endl; // 输出 8
7.2.2 捕获值和捕获引用
7.2.3 特殊的捕获方法
7.3 lambda表达式的实现原理
“lambda表达式在编译期会由编译器自动生成一个闭包类,在运行时由这个闭包类产生一个对象,我们称它为闭包。在C++中,所谓的闭包可以简单地理解为一个匿名且可以包含定义时作用域上下文的函数对象。"
7.4 无状态lambda表达式
C++标准对无状态的lambda表达式(即没有捕获任何外部的参数)进行了优化,它可以隐式的转化为函数指针,这样减少类的创建,减少性能开销。
7.5 在STL中使用lambda表达式
7.6 广义捕获【c++14】
c++11中只能捕获lambda表达式定义上下文的变量,而无法捕获表达式结果以及自定义捕获变量名。
 “第二个场景是在异步调用时复制this对象,防止lambda表达式被调用时因原始this对象被析构造成未定义的行为”
“第二个场景是在异步调用时复制this对象,防止lambda表达式被调用时因原始this对象被析构造成未定义的行为”
 以上代码使用初始化捕获,将*this复制到tmp对象中,然后在函数体内返回tmp对象的value。由于整个对象通过复制的方式传递到lambda表达式内,因此即使this所指的对象析构了也不会影响lambda表达式的计算。
以上代码使用初始化捕获,将*this复制到tmp对象中,然后在函数体内返回tmp对象的value。由于整个对象通过复制的方式传递到lambda表达式内,因此即使this所指的对象析构了也不会影响lambda表达式的计算。
7.7 泛型lambda表达式 【c++14】
“C++14标准让lambda表达式具备了模版函数的能力,我们称它为泛型lambda表达式。“泛型lambda表达式更多地利用了auto占位符的特性,而lambda表达式本身并没有什么变化”

7.8 常量lambda表达式和捕获*this 【c++17】
“如果在lambda表达式中用到了大量this指向的对象,那我们就不得不将它们全部修改,一旦遗漏就会引发问题。为了更方便地复制和使用*this对象,C++17增加了捕获列表的语法来简化这个操作,具体来说就是在捕获列表中直接添加[*this],然后在lambda表达式函数体内直接使用this指向对象的成员”
7.9 捕获[=, this] 【c++20】
“我们知道[=]可以捕获this指针,相似的,[=,*this]会捕获this对象的副本。但是在代码中大量出现[=]和[=,*this]的时候我们可能很容易忘记前者与后者的区别。为了解决这个问题,在C++20标准中“引入了[=, this]捕获this指针的语法,它实际上表达的意思和[=]相同,目的是让程序员们区分它与[=,*this]的不同”
7.10 模板语法的泛型lambda表达式 【c++20】
C++20之后,在捕获列表之后加入,达到泛型编程的作用。

7.11 可构造和可赋值的无状态lambda表达式 【c++20】
无状态lambda表达式其实是一个函数指针,因此lambda表达式的默认构造函数和赋值构造函数都被删除了。“C++20标准允许了无状态lambda表达式类型的构造和赋值”
auto f = [](auto x, auto y)
{
return x > y;
};
/** map的比较中需要传入一个类型并作为模板传入模板 */
// 构造允许
std::map<std::string, int, decltype(f)> Map1, Map2;
// 赋值允许
Map2 = Map1;
7.12 总结
第8章 非静态数据成员默认初始化(C++11 C++20)
8.1 使用默认初始化 【c++11】
“在C++11以前,对非静态数据成员初始化需要用到初始化列表,当类的数据成员和构造函数较多时,编写构造函数会是一个令人头痛的问题。C++11标准提出了新的初始化方法,即在声明非静态数据成员的同时直接对其使用=或者{}(见第9章)初始化。在此之前只有类型为整型或者枚举类型的常量静态数据成员才有这种声明默认初始化的待遇”。
“在初始化的优先级上有这样的规则,初始化列表对数据成员的初始化总是优先于声明时默认初始化。”
8.2 位域的默认初始化 【c++20】
“在C++20中我们可以对数据成员的位域进行默认初始化了”
8.3 总结
第9章 列表初始化(C++11 C++20)
9.1 回顾变量初始化

“一般来说,我们称使用括号初始化的方式叫作直接初始化,而使用等号初始化的方式叫作拷贝初始化(复制初始化)。”
“new运算符和类构造函数的初始化列表就属于直接初始化,而函数传参和return返回则是拷贝初始化。”
9.2 使用列表初始化
“C++11标准引入了列表初始化,它使用大括号{}对变量进行初始化,和传统变量初始化的规则一样,它也区分为直接初始化和拷贝初始化”
“可以使用列表初始化对标准容器进行初始化了”
9.3 std::initializer_list详解
“标准容器之所以能够支持列表初始化,离不开编译器支持的同时,它们自己也必须满足一个条件:支持std::initializer_list为形参的构造函数。“std::initializer_list简单地说就是一个支持begin、end以及size成员函数的类模板”
9.4 使用列表初始化的注意事项
9.4.1 隐式缩窄转换问题
“在C++中哪些属于隐式缩窄转换呢?在C++标准里列出了这么4条规则。
1.从浮点类型转换整数类型。
2.从long double转换到double或float,或从double转换到float,除非转换源是常量表达式以及转换后的实际值在目标可以表示的值范围内。”
3.从整数类型或非强枚举类型转换到浮点类型,除非转换源是常量表达式,转换后的实际值适合目标类型并且能够将生成目标类型的目标值转换回原始类型的原始值。
4.从整数类型或非强枚举类型转换到不能代表所有原始类型值的整数类型,除非源是一个常量表达式,其值在转换之后能够适合目标类型。”

9.4.2 列表初始化的优先级问题
“如果有一个类同时拥有满足列表初始化的构造函数,且其中一个是以std::initializer_list为参数,那么编译器将优先以std::initializer_ list为参数构造函数。”
9.5 指定初始化 【c++20】
“为了提高数据成员初始化的可读性和灵活性,C++20标准中引入了指定初始化的特性。该特性允许指定初始化数据成员的名称,从而使代码意图更加明确。”
“当初始化的结构体的数据成员比较多且真正需要赋值的只有少数成员的时候,这样的指定初始化就非常好用了”
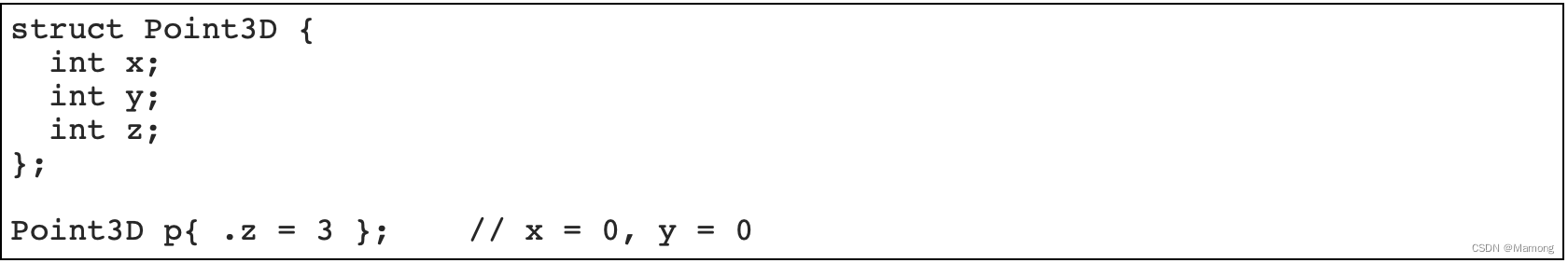 并不是什么对象都能够指定初始化的:
并不是什么对象都能够指定初始化的:
“1.它要求对象必须是一个聚合类型”。当类满足一下所有条件时,才是聚合类:所有成员都是public的;没有定义任何构造函数;没有类内初始值;没有基类,也没有virtual函数。
“2.指定的数据成员必须是非静态数据成员。”
“3.每个非静态数据成员最多只能初始化一次”
“4.非静态数据成员的初始化必须按照声明的顺序进行。”
“5.针对联合体中的数据成员只能初始化一次,不能同时指定”
“6.不能嵌套指定初始化数据成员。”
“7.在C++20中,一旦使用指定初始化,就不能混用其他方法对数据成员初始化了”
“8.最后再来了解一下指定初始化在C语言中处理数组的能力,当然在C++中这同样是被禁止的”:

9.6 总结
第10章 默认和删除函数(C++11)
10.1 类的特殊成员函数
“C++标准规定,在没有自定义构造函数的情况下,编译器会为类添加默认的构造函数。像这样有特殊待遇的成员函数一共有6个(C++11以前是4个),具体如下。”
“1.默认构造函数。
2.析构函数。
3.复制构造函数。
4.复制赋值运算符函数。
5.移动构造函数(C++11新增)。
6.移动赋值运算符函数(C++11新增)。”
该特性的存在也给我们带来了一些麻烦。
1.声明任何构造函数都会抑制默认构造函数的添加。
2.一旦用自定义构造函数代替默认构造函数,类就将转变为非平凡类型。
3.没有明确的办法彻底禁止特殊成员函数的生成(C++11之前)。”
10.2 显式默认和显式删除
“C++11标准提供了一种方法能够简单有效又精确地控制默认特殊成员函数的添加和删除,我们将这种方法叫作显式默认和显式删除。显式默认和显式删除的语法非常简单,只需要在声明函数的尾部添加=default和=delete,它们分别指示编译器添加特殊函数的默认版本以及删除指定的函数”。
“=default可以添加到类内部函数声明,也可以添加到类外部。这里默认构造函数的=default就是添加在类内部,而复制构造函数的=default则是添加在类外部。提供这种能力的意义在于,它可以让我们在不修改头文件里函数声明的情况下,改变函数内部的行为”。
“=delete与=default不同,它必须添加在类内部的函数声明中,如果将其添加到类外部,那么会引发编译错误。”
10.3 显式删除的其他用法
“显式删除不仅适用于类的成员函数,对于普通函数同样有效。只不过相对于应用于成员函数,应用于普通函数的意义就不大了”
“显式删除还可以用于类的new运算符和类析构函数。显式删除特定类的new运算符可以阻止该类在堆上动态创建对象,换句话说它可以限制类的使用者只能通过自动变量、静态变量或者全局变量的方式创建对象”
“显式删除类的析构函数在某种程度上和删除new运算符的目的正好相反,它阻止类通过自动变量、静态变量或者全局变量的方式创建对象,但是却可以通过new运算符创建对象。原因是删除析构函数后,类无法进行析构。所以像自动变量、静态变量或者全局变量这种会隐式调用析构函数的对象就无法创建了,当然了,通过new运算符创建的对象也无法通过delete销毁”
10.4 explicit和=delete
“在类的构造函数上同时使用explicit和=delete是一个不明智的做法,它常常会造成代码行为混乱难以理解,应尽量避免这样做。”
10.5 总结
第11章 非受限联合类型(C++11)
11.1 联合类型在C++中的局限性
“过去的C++标准规定,联合类型的成员变量的类型不能是一个非平凡类型,也就是说它的成员类型不能有自定义构造函数”
11.2 使用非受限联合类型
“为了让联合类型更加实用,在C++11标准中解除了大部分限制,联合类型的成员可以是除了引用类型外的所有类型。”
“在C++11中如果有联合类型中存在非平凡类型,那么这个联合类型的特殊成员函数(6个)将被隐式删除,也就是说我们必须自己至少提供联合类型的构造和析构函数”。
“比较推荐让联合类型的构造和析构函数为空,也就是什么也不做,并且将其成员的构造和析构函数放在需要使用联合类型的地方。”
 “上面的代码用了placement new的技巧来初始化构造x3和x4对象,在使用完对象后手动调用对象的析构函数。通过这样的方法保证了联合类型使用的灵活性和正确性。”
“上面的代码用了placement new的技巧来初始化构造x3和x4对象,在使用完对象后手动调用对象的析构函数。通过这样的方法保证了联合类型使用的灵活性和正确性。”
placement new分配一个对象的过程如下: ①使用new引用一个已经分配好的内存 @调用对象类的构造函数在该内存地址上创建对象
“联合类型的静态成员不属于联合类型的任何对象,所以并不是对象构造时被定义的,不能在联合类型内部初始化。实际上这一点和类的静态成员变量是一样的,当然了,它的初始化方法也和类的静态成员变量相同”。
11.3 总结
第12章 委托构造函数(C++11)
12.1 冗余的构造函数
“一个类有多个不同的构造函数在C++中是很常见的”,存在几个问题:
“首先,类需要在每个构造函数的初始化列表中初始化构造所有的成员变量”
“其次,在构造函数主体中也有相同的情况,一旦类的构造过程需要依赖某个函数,那么所有构造函数的主体就需要调用这个函数”
“过去C++没有提供一种复用同类型构造函数的方法,也就是说无法让一个构造函数将初始化的一部分工作委托给同类型的另外一个构造函数。”
12.2 委托构造函数
“C++11标准支持了委托构造函数:某个类型的一个构造函数可以委托同类型的另一个构造函数对对象进行初始化。”
“委托构造函数的语法非常简单,只需要在委托构造函数的初始化列表中调用代理构造函数即可”
“它们的执行顺序是先执行代理构造函数的初始化列表,接着执行代理构造函数的主体,最后执行委托构造函数的主体”
“委托构造函数的语法很简单,不过想合理使用它还需注意以下5点。”
“1.每个构造函数都可以委托另一个构造函数为代理。”
“2.不要递归循环委托!”
“3.如果一个构造函数为委托构造函数,那么其初始化列表里就不能对数据成员和基类进行初始化”
“4.委托构造函数的执行顺序是先执行代理构造函数的初始化列表,然后执行代理构造函数的主体,最后执行委托构造函数的主体”
“5.如果在代理构造函数执行完成后,委托构造函数主体抛出了异常,则自动调用该类型的析构函数。因为C++标准规定(规则3也提到过),一旦类型有一个构造函数完成执行,那么就会认为其构造的对象已经构造完成,所以发生异常后需要调用析构函数”
12.3 委托模板构造函数
“委托模板构造函数是指一个构造函数将控制权委托到同类型的一个模板构造函数”

12.4 捕获委托构造函数的异常
“当使用Function-try-block(c++98语法)去捕获委托构造函数异常时,其过程和捕获初始化列表异常如出一辙。如果一个异常在代理构造函数的初始化列表或者主体中被抛出,那么委托构造函数的主体将不再被执行,与之相对的,控制权会交到异常捕获的catch代码块中”

12.5 委托参数较少的构造函数
我们通常是将参数较少的构造函数委托给参数较多的构造函数。从参数较多的构造函数委托参数较少的构造函数,这种情况通常发生在构造函数的参数必须在函数体中使用的场景”
12.6 总结
第13章 继承构造函数(C++11)
13.1 继承关系中构造函数的困局
“面对基类中大量的构造函数,我们不得不在派生类中定义同样多的构造函数,目的仅仅是转发构造参数,因为派生类本身并没有需要初始化的数据成员。”
13.2 使用继承构造函数
“C++中可以使用using关键字将基类的函数引入派生类”
“C++11的继承构造函数正是利用了这一点,将using关键字的能力进行了扩展,使其能够引入基类的构造函数”
“使用继承构造函数虽然很方便,但是还有6条规则需要注意。
1.派生类是隐式继承基类的构造函数,所以只有在程序中使用了这些构造函数,编译器才会为派生类生成继承构造函数的代码。”
“2.派生类不会继承基类的默认构造函数和复制构造函数。因为在C++语法规则中,执行派生类默认构造函数之前一定会先执行基类的构造函数。同样的,在执行复制构造函数之前也一定会先执行基类的复制构造函数。所以继承基类的默认构造函数和默认复制构造函数的做法是多余的”
“3.继承构造函数不会影响派生类默认构造函数的隐式声明,也就是说对于继承基类构造函数的派生类,编译器依然会为其自动生成默认构造函数的代码。”
“4.在派生类中声明签名相同的构造函数会禁止继承相应的构造函数。”
“5.派生类继承多个签名相同的构造函数会导致编译失败”。(多重继承的时候)
“6.继承构造函数的基类构造函数不能为私有”
此外,“早期的编译器(比如GCC 6.4)在继承基类构造函数时,不会继承默认参数,而是在派生类中注入带有各种参数数量的构造函数的重载集合”
13.3 总结
第14章 强枚举类型(C++11 C++17 C++20) 124
14.1 枚举类型的弊端 124
14.2 使用强枚举类型 129
14.3 列表初始化有底层类型枚举对象 131
14.4 使用using打开强枚举类型 133
14.5 总结 135
第15章 扩展的聚合类型(C++17 C++20)
15.1 聚合类型的新定义 【c++17】
“聚合类型还需要满足常规条件:”
1.没有用户提供的构造函数。
2.没有私有和受保护的非静态数据成员。
3.没有虚函数。
“C++17标准对聚合类型的定义做出了大幅修改,即从基类公开且非虚继承的类也可能是一个聚合,也就是需要额外满足以下条件:
4.必须是公开的基类,不能是私有或者受保护的基类。
5.必须是非虚继承。
“基类是否是聚合类型与派生类是否为聚合类型没有关系,只要满足上述5个条件,派生类就是聚合类型。”
“在标准库<type_traits>中提供了一个聚合类型的甄别办法is_aggregate,它可以帮助我们判断目标类型是否为聚合类型”
15.2 聚合类型的初始化
15.3 扩展聚合类型的兼容问题 139
15.4 禁止聚合类型使用用户声明的构造函数 140
15.5 使用带小括号的列表初始化聚合类型对象 142
15.6 总结 143
第16章 override和final说明符(C++11)
16.1 重写、重载和隐藏
“1.重写(override)的意思更接近覆盖,在C++中是指派生类覆盖了基类的虚函数,这里的覆盖必须满足有相同的函数签名和返回类型,也就是说有相同的函数名、形参列表以及返回类型。”
“2.重载(overload),它通常是指在同一个类中有两个或者两个以上函数,它们的函数名相同,但是函数签名不同,也就是说有不同的形参。”
“3. 隐藏(overwrite)是指基类成员函数,无论它是否为虚函数,当派生类出现同名函数时,如果派生类函数签名不同于基类函数,则基类函数会被隐藏。”
16.2 重写引发的问题
“C++语法对重写的要求很高,稍不注意就会无法重写基类虚函数。更糟糕的是,即使我们写错了代码,编译器也可能不会提示任何错误信息,直到程序编译成功后,运行测试才会发现其中的逻辑问题”
16.3 使用override说明符
“C++11标准提供了一个非常实用的override说明符,这个说明符必须放到虚函数的尾部,它明确告诉编译器这个虚函数需要覆盖基类的虚函数,一旦编译器发现该虚函数不符合重写规则,就会给出错误提示。
16.4 使用final说明符
“在C++中,我们可以为基类声明纯虚函数来迫使派生类继承并且重写这个纯虚函数。但是一直以来,C++标准并没有提供一种方法来阻止派生类去继承基类的虚函数。C++11标准引入final说明符解决了上述问题,它告诉编译器该虚函数不能被派生类重写。final说明符用法和override说明符相同,需要声明在虚函数的尾部。”
“有时候,override和final会同时出现。这种情况通常是由中间派生类继承基类后,希望后续其他派生类不能修改本类虚函数的行为而产生的”
“最后要说明的是,final说明符不仅能声明虚函数,还可以声明类。如果在类定义的时候声明了final,那么这个类将不能作为基类被其他类继承”
16.5 override和final说明符的特别之处
“为了和过去的C++代码保持兼容,增加保留的关键字需要十分谨慎。因为一旦增加了某个关键字,过去的代码就可能面临大量的修改。所以在C++11标准中,override和final并没有被作为保留的关键字,其中override只有在虚函数尾部才有意义,而final只有在虚函数尾部以及类声明的时候才有意义。它们仍然可以作为函数名,但是不建议这么做。”
16.6 总结
第17章 基于范围的for循环(C++11 C++17 C++20)
17.1 烦琐的容器遍历
通常遍历一个容器里的所有元素会用到for循环和迭代器,但我们真正关心的只是容器里的元素。
17.2 基于范围的for循环语法
“C++11标准引入了基于范围的for循环特性,该特性隐藏了迭代器的初始化和更新过程,让程序员只需要关心遍历对象本身,其语法也比传统for循环简洁很多”
 “范围声明是一个变量的声明,其类型是范围表达式中元素的类型或者元素类型的引用。而范围表达式可以是数组或对象,对象必须满足以下2个条件中的任意一个。”
“范围声明是一个变量的声明,其类型是范围表达式中元素的类型或者元素类型的引用。而范围表达式可以是数组或对象,对象必须满足以下2个条件中的任意一个。”
1.对象类型定义了begin和end成员函数。
2.定义了以对象类型为参数的begin和end普通函数。
“为了让范围声明更加简洁,推荐使用auto占位符。对于复杂的对象使用引用,而对于基础类型使用值,因为这样能够减少内存的复制。”
17.3 begin和end函数不必返回相同类型 【c++17】
“C++17标准对基于范围的for循环的实现进行了改进,不再要求begin和end函数的返回类型是相同类型”
17.4 临时范围表达式的陷阱【c++20】
“无论是C++11还是C++17标准,基于范围的for循环伪代码都是由以下这句代码开始的:”

“对于这个赋值表达式来说,如果range_expression是一个纯右值,那么右值引用会扩展其生命周期,保证其整个for循环过程中访问的安全性。但如果range_ expression是一个泛左值,右值引用无法扩展其生命周期,导致for循环访问无效对象并造成未定义行为。”
将数据复制出来是一种解决方法:

为此,在C++20标准中,基于范围的for循环增加了对初始化语句的支持:

17.5 实现一个支持基于范围的for循环的类
17.6 总结
第18章 支持初始化语句的if和switch(C++17)
18.1 支持初始化语句的if
“在C++17标准中,if控制结构可以在执行条件语句之前先执行一个初始化语句。语法如下:”

“在初始化语句中声明的变量能够在if的作用域继续使用。事实上,该变量的生命周期会一直伴随整个if结构,包括else if和else部分。”
“else if中声明的变量的生命周期只存在于else if以及后续存在的else if和else语句,而无法在之前的if中使用。”
18.2 支持初始化语句的switch
“和if控制结构一样,switch在通过条件判断确定执行的代码分支之前也可以接受一个初始化语句。”
“switch初始化语句声明的变量的生命周期会贯穿整个switch结构,这一点和if也相同,所以变量lk能够引用到任何一个case的分支中。”
18.3 总结
第19章 static_assert声明 161
19.1 运行时断言 161
19.2 静态断言的需求 162
19.3 静态断言 163
19.4 单参数static_assert 164
19.5 总结 165
第20章 结构化绑定(C++17 C++20) 166
20.1 使用结构化绑定【c++17】

“C++11必须指定return_multiple_values函数的返回值类型,另外,在调用return_multiple_values函数前还需要声明变量x和y,并且使用函数模板std::tie将x和y通过引用绑定到std::tuple<int&, int&>上。对于第一个问题,我们可以使用C++14中auto的新特性来简化返回类型的声明,要想解决第二个问题就必须使用C++17标准中新引入的特性——结构化绑定。所谓结构化绑定是指将一个或者多个名称绑定到初始化对象中的一个或者多个子对象(或者元素)上,相当于给初始化对象的子对象(或者元素)起了别名,请注意别名不同于引用”

20.2 深入理解结构化绑定
20.3 结构化绑定的3种类型
“结构化绑定可以作用于3种类型,包括原生数组、结构体和类对象、元组和类元组的对象”
20.3.1 绑定到原生数组
“绑定到原生数组即将标识符列表中的别名一一绑定到原生数组对应的元素上。所需条件仅仅是要求别名的数量与数组元素的个数一致”
20.3.2 绑定到结构体和类对象
“首先,类或者结构体中的非静态数据成员个数必须和标识符列表中的别名的个数相同;其次,这些数据成员必须是公有的(C++20标准修改了此项规则,详情见20.5节);这些数据成员必须是在同一个类或者基类中;最后,绑定的类和结构体中不能存在匿名联合体”
20.3.3 绑定到元组和类元组的对象
“1.需要满足std::tuple_size::value是一个符合语法的表达式,并且该表达式获得的整数值与标识符列表中的别名个数相同。
2.类型T还需要保证std::tuple_element<i, T>::type也是一个符合语法的表达式,其中i是小于std::tuple_size::value的整数,表达式代表了类型T中第i个元素的类型。
3.类型T必须存在合法的成员函数模板get()或者函数模板get(t),其中i是小于std::tuple_size::value的整数,t是类型T的实例,get()和get(t)返回的是实例t中第i个元素的值。”
“标准库中除了元组本身毫无疑问地能够作为绑定目标以外,std::pair和std::array也能作为结构化绑定的目标,其原因就是它们是满足上述条件的类元组。”
20.4 实现一个类元组类型
20.5 绑定的访问权限问题 【c++20】
“C++20标准规定结构化绑定的限制不再强调必须为公开数据成员,编译器会根据当前操作的上下文来判断是否允许结构化绑定。”
20.6 总结
第21章 noexcept关键字(C++11 C++17 C++20)
21.1 使用noexcept代替throw
“异常处理是C++语言的重要特性,在C++11标准之前,我们可以使用throw (optional_type_list)声明函数是否抛出异常,并描述函数抛出的异常类型。理论上,运行时必须检查函数发出的任何异常是否确实存在于optional_ type_list中,或者是否从该列表中的某个类型派生。如果不是,则会调用处理程序std::unexpected。
“但实际上,由于这个检查实现比较复杂,因此并不是所有编译器都会遵从这个规范。此外,大多数程序员似乎并不喜欢throw(optional_type_list)这种声明抛出异常的方式,因为在他们看来抛出异常的类型并不是他们关心的事情,他们只需要关心函数是否会抛出异常,即是否使用了throw()来声明函数。”
“throw并不能根据容器中移动的元素是否会抛出异常来确定移动构造函数是否允许抛出异常。针对这样的问题,C++标准委员会提出了noexcept说明符。
“noexcept只是告诉编译器不会抛出异常,但函数不一定真的不会抛出异常。这相当于对编译器的一种承诺,当我们在声明了noexcept的函数中抛出异常时,程序会调用std::terminate去结束程序的生命周期。”
“另外,noexcept还能接受一个返回布尔的常量表达式,当表达式评估为true的时候,其行为和不带参数一样,表示函数不会抛出异常。反之,当表达式评估为false的时候,则表示该函数有可能会抛出异常。这个特性广泛应用于模板当中”
“C++标准委员会又赋予了noexcept作为运算符的特性。noexcept运算符接受表达式参数并返回true或false。因为该过程是在编译阶段进行,所以表达式本身并不会被执行。而表达式的结果取决于编译器是否在表达式中找到潜在异常”
21.2 用noexcept来解决移动构造问题
21.3 noexcept和throw() 【c++11,17,20】
“如果一个函数在声明了noexcept的基础上抛出了异常,那么程序将不需要展开堆栈,并且它可以随时停止展开。另外,它不会调用std::unexpected,而是调用std::terminate结束程序。而throw()则需要展开堆栈,并调用std::unexpected。这些差异让使用noexcept程序拥有更高的性能。在C++17标准中,throw()成为noexcept的一个别名,也就是说throw()和noexcept拥有了同样的行为和实现。另外,在C++17标准中只有throw()被保留了下来,其他用throw声明函数抛出异常的方法都被移除了。在C++20中throw()也被标准移除了,使用throw声明函数异常的方法正式退出了历史舞台。”
21.4 默认使用noexcept的函数
“C++11标准规定下面几种函数会默认带有noexcept声明。
1.默认构造函数、默认复制构造函数、默认赋值函数、默认移动构造函数和默认移动赋值函数。有一个额外要求,对应的函数在类型的基类和成员中也具有noexcept声明,否则其对应函数将不再默认带有noexcept声明。另外,自定义实现的函数默认也不会带有noexcept声明”
“2.类型的析构函数以及delete运算符默认带有noexcept声明,请注意即使自定义实现的析构函数也会默认带有noexcept声明,除非类型本身或者其基类和成员明确使用noexcept(false)声明析构函数,以上也同样适用于delete运算符”
21.5 使用noexcept的时机
“那么哪些函数可以使用noexcept声明呢?这里总结了两种情况。
1.一定不会出现异常的函数。通常情况下,这种函数非常简短,例如求一个整数的绝对值、对基本类型的初始化等。
2.当我们的目标是提供不会失败或者不会抛出异常的函数时可以使用noexcept声明。对于保证不会失败的函数,例如内存释放函数,一旦出现异常,相对于捕获和处理异常,终止程序是一种更好的选择。另外,对于保证不会抛出异常的函数而言,即使有错误发生,函数也更倾向用返回错误码的方式而不是抛出异常。”
21.6 将异常规范作为类型的一部分【c++17】
“fp是一个指向确保不抛出异常的函数的指针,而函数foo则没有不抛出异常的保证。在C++17之前,它们的类型是相同的。C++17标准将异常规范引入了类型系统。”
“类型系统引入异常规范导致noexcept声明的函数指针无法接受没有noexcept声明的函数,但是反过来却是被允许的”
“最后需要注意的是模板带来的兼容性问题”
21.7 总结
第22章 类型别名和别名模板(C++11 C++14)
22.1 类型别名
“为了让代码看起来更加简洁,往往会使用typedef为较长的类型名定义一个别名”。
“C++11标准提供了一个新的定义类型别名的方法,该方法使用using关键字,具体语法如下:
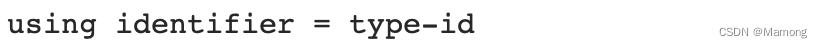 “使用typedef定义函数类型别名和定义其他类型别名是有所区别的,而使用using则不存在这种区别,这让使用using定义别名变得更加统一清晰”。
“使用typedef定义函数类型别名和定义其他类型别名是有所区别的,而使用using则不存在这种区别,这让使用using定义别名变得更加统一清晰”。
22.2 别名模板【c++14】
“事实上using还承担着一个更加重要的特性——别名模板。所谓别名模板本质上也应该是一种模板,它的实例化过程是用自己的模板参数替换原始模板的模板参数,并实例化原始模板。定义别名模板的语法和定义类型别名并没有太大差异,只是多了模板形参列表:”


“虽然别名模板有很多typedef不具备的优势,但是C++11标准库中的模板元编程函数都还是使用的typedef和类型嵌套的方案。不过这种情况在C++14中得到了改善,在C++14标准库中模板元编程函数已经有了别名模板的版本。当然,为了保证与老代码的兼容性,typedef的方案依然存在。别名模板的模板元编程函数使用_t作为其名称的后缀以示区分”。
22.3 总结
第23章 指针字面量nullptr(C++11)
23.1 零值整数字面量
“在C++标准中有一条特殊的规则,即0既是一个整型常量,又是一个空指针常量”。二义性导致下面这个函数重载的例子出现问题:

23.2 nullptr关键字
“C++标准委员会在C++11中添加关键字nullptr表示空指针的字面量,它是一个std::nullptr_t类型的纯右值。nullptr不允许运用在算术表达式中或者与非指针类型进行比较(除了空指针常量0)。它还可以隐式转换为各种指针类型,但是无法隐式转换到非指针类型。注意,0依然保留着可以代表整数和空指针常量的特殊能力,保留这一点是为了让C++11标准兼容以前的C++代码。”
23.3 总结
第24章 三向比较(C++20)
24.1 “太空飞船”(spaceship)运算符 202
24.2 三向比较的返回类型 202
24.2.1 std::strong_ordering 203
24.2.2 std::weak_ordering 204
24.2.3 std::partial_ordering 205
24.3 对基础类型的支持 206
24.4 自动生成的比较运算符函数 207
24.5 兼容旧代码 210
24.6 总结 211
第25章 线程局部存储(C++11)
25.1 操作系统和编译器对线程局部存储的支持
“线程局部存储是指对象内存在线程开始后分配,线程结束时回收且每个线程有该对象自己的实例”
“在Windows中可以通过调用API函数TlsAlloc来分配一个未使用的线程局部存储槽索引(TLS slot index),这个索引实际上是Windows内部线程环境块(TEB)中线程局部存储数组的索引。通过API函数TlsGetValue与TlsSetValue可以获取和设置线程局部存储数组对应于索引元素的值。API函数TlsFree用于释放线程局部存储槽索引。
Linux使用了pthreads(POSIX threads)作为线程接口,在pthreads中我们可以调用pthread_key_create与pthread_key_delete创建与删除一个类型为pthread_key_t的键。利用这个键可以使用pthread_setspecific函数设置线程相关的内存数据,当然,我们随后还能够通过pthread_getspecific函数获取之前设置的内存数据。
在C++11标准确定之前,各个编译器也用了自定义的方法支持线程局部存储。比如gcc和clang添加了关键字__thread来声明线程局部存储变量,而Visual Studio C++则是使用__declspec(thread)。
“C++11标准中正式添加了新的thread_local说明符来声明线程局部存储变量”
25.2 thread_local说明符
“thread_local说明符可以用来声明线程生命周期的对象,它能与static或extern结合,分别指定内部或外部链接,不过额外的static并不影响对象的生命周期。换句话说,static并不影响其线程局部存储的属性”
线程局部存储“能够解决全局变量或者静态变量在多线程操作中存在的问题,一个典型的例子就是errno”
“线程局部存储只是定义了对象的生命周期,而没有定义可访问性。也就是说,我们可以获取线程局部存储变量的地址并将其传递给其他线程,并且其他线程可以在其生命周期内自由使用变量。”
“使用取地址运算符&取到的线程局部存储变量的地址是运行时被计算出来的,它不是一个常量,也就是说无法和constexpr结合”
“在同一个线程中,一个线程局部存储对象只会初始化一次,即使在某个函数中被多次调用。这一点和单线程程序中的静态对象非常相似。相对应的,对象的销毁也只会发生一次,通常发生在线程退出的时刻。”
25.3 总结
第26章 扩展的inline说明符(C++17)
26.1 定义非常量静态成员变量的问题
“在C++17标准之前,定义类的非常量静态成员变量是一件让人头痛的事情,因为变量的声明和定义必须分开进行”

将上面的代码包含到多个CPP文件中会引发一个链接错误,因为include是单纯的宏替换,所以会存在多份X::text的定义导致链接失败。
“对于一些字面量类型,比如整型、浮点类型等,至少对于它们而言常量静态成员变量是可以一边声明一边定义的,但却丢失了修改变量的能力。对于std::string这种非字面量类型,这种方法是无能为力的。”
26.2 使用inline说明符
“C++17标准中增强了inline说明符的能力,它允许我们内联定义静态变量”

“即使将类X的定义作为头文件包含在多个CPP中也不会有任何问题。在这种情况下,编译器会在类 X的定义首次出现时对内联静态成员变量进行定义和初始化。
26.3 总结
第27章 常量表达式(C++11~C++20)
27.1 常量的不确定性
27.2 constexpr值 224
27.3 constexpr函数 225
27.4 constexpr构造函数 228
27.5 对浮点的支持 230
27.6 C++14标准对常量表达式函数的增强 230
27.7 constexpr lambdas表达式 233
27.8 constexpr的内联属性 235
27.9 if constexpr 236
27.10 允许constexpr虚函数 240
27.11 允许在constexpr函数中出现Try-catch 244
27.12 允许在constexpr中进行平凡的默认初始化 244
27.13 允许在constexpr中更改联合类型的有效成员 245
27.14 使用consteval声明立即函数 246
27.15 使用constinit检查常量初始化 247
27.16 判断常量求值环境 248
27.17 总结 252
第28章 确定的表达式求值顺序(C++17)
28.1 表达式求值顺序的不确定性
“一个表达式中的子表达式的求值顺序,在C++17之前是没有具体说明的,所以编译器可以以任何顺序对子表达式进行求值。”
28.2 表达式求值顺序详解
“从C++17开始,函数表达式一定会在函数的参数之前求值。也就是说在foo(a, b, c)中,foo一定会在a、b和c之前求值。但是请注意,参数之间的求值顺序依然没有确定,也就是说a、b和c谁先求值还是没有规定。”
“对于后缀表达式和移位操作符而言,表达式求值总是从左往右”
“对于赋值表达式,这个顺序又正好相反,它的表达式求值总是从右往左”
“对于new表达式,C++17也做了规定。对于new T(E),这里new表达式的内存分配总是优先于T构造函数中参数E的求值。
最后C++17还明确了一条规则:涉及重载运算符的表达式的求值顺序应由与之相应的内置运算符的求值顺序确定,而不是函数调用的顺序规则。
28.3 总结
第29章 字面量优化(C++11~C++17)
29.1 十六进制浮点字面量【c++17】
从C++11开始,标准库中引入了std::hexfloat和std::defaultfloat。其中std::hexfloat可以将浮点数格式化为十六进制的字符串,而std::defaultfloat可以将格式还原到十进制。
但我们并不能在源代码中使用十六进制浮点字面量来表示一个浮点数。幸运的是,这个问题在C++17标准中得到了解决。
“使用十六进制浮点字面量的优势显而易见,它可以更加精准地表示浮点数。劣势也很明显,它不便于代码的阅读理解。”
29.2 二进制整数字面量【c++14】
“在C++14标准中定义了二进制整数字面量,二进制整数字面量也有前缀0b和0B。实际上GCC的扩展早已支持了二进制整数字面量,只不过到了C++14才作为标准引入”
29.3 单引号作为整数分隔符【c++14】
“C++14标准还增加了一个用单引号作为整数分隔符的特性,目的是让比较长的整数阅读起来更加容易。单引号整数分隔符对于十进制、八进制、十六进制、二进制整数都是有效的”
29.4 原生字符串字面量
“包含大量转义字符影响了阅读的流畅性。为了解决这种问题,C++11标准引入原生字符串字面量的概念。”
“使用原生字符串字面量的代码会在编译的时候被编译器直接使用,也就是说保留了字符串里的格式和特殊字符,同时它也会忽略转义字符,概括起来就是所见即所得。”
“声明原生字符串字面量的语法很简单,即prefix R"delimiter(raw_ characters)delimiter",这其中prefix和delimiter是可选部分,我们可以忽略它们,所以最简单的原生字符串字面量声明是R"(raw_characters)"。”
“delimiter可以是由除括号、反斜杠和空格以外的任何源字符构成的字符序列,长度至多为16个字符。通过添加delimiter可以改变编译器对原生字符串字面量范围的判定”
“C++11标准除了让我们能够定义char类型的原生字符串字面量外,对于wchar_t、char8_t(C++20标准开始)、char16_t和char32_t类型的原生字符串字面量也有支持。要支持这4种字符类型,就需要用到另外一个可选元素prefix了。这里的prefix实际上是声明4个类型字符串的前缀L、u、U和u8。”
29.5 用户自定义字面量
“在C++11标准中新引入了一个用户自定义字面量的概念,程序员可以通过自定义后缀将整数、浮点数、字符和字符串转化为特定的对象。”
29.6 总结
第30章 alignas和alignof(C++11 C++17)
30.1 不可忽视的数据对齐问题 268
30.2 C++11标准之前控制数据对齐的方法 270
30.3 使用alignof运算符 272
30.4 使用alignas说明符 273
30.5 其他关于对齐字节长度的支持 276
30.6 C++17中使用new分配指定对齐字节长度的对象 278
30.7 总结 279
第31章 属性说明符和标准属性(C++11~C++20)
31.1 GCC的属性语法 280
31.2 MSVC的属性语法 281
31.3 标准属性说明符语法 282
31.4 使用using打开属性的命名空间 283
31.5 标准属性 283
31.5.1 noreturn 284
31.5.2 carries_dependency 286
31.5.3 deprecated 286
31.5.4 fallthrough 287
31.5.5 nodiscard 288
31.5.6 maybe_unused 290
31.5.7 likely和unlikely 290
31.5.8 no_unique_address 291
31.6 总结 293
第32章 新增预处理器和宏(C++17 C++20)
32.1 预处理器__has_include 294
32.2 特性测试宏 295
32.2.1 属性特性测试宏 295
32.2.2 语言功能特性测试宏 295
32.2.3 标准库功能特性测试宏 297
32.3 新增宏__VA_OPT__ 301
32.4 总结 302
第33章 协程(C++20)
33.1 协程的使用方法 303
33.2 协程的实现原理 308
33.2.1 co_await运算符原理 308
33.2.2 co_yield运算符原理 313
33.2.3 co_return运算符原理 317
33.2.4 promise_type的其他功能 319
33.3 总结 320
第34章 基础特性的其他优化(C++11~C++20)
34.1 显式自定义类型转换运算符(C++11) 321
34.2 关于std::launder()(C++17) 325
34.3 返回值优化(C++11~C++17)
“返回值优化是C++中的一种编译优化技术,它允许编译器将函数返回的对象直接构造到它们本来要存储的变量空间中而不产生临时对象。严格来说返回值优化分为RVO(Return Value Optimization)和NRVO(Named Return Value Optimization),不过在优化方法上的区别并不大,一般来说当返回语句的操作数为临时对象时,我们称之为RVO;而当返回语句的操作数为具名对象时,我们称之为NRVO。在C ++ 11标准中,这种优化技术被称为复制消除(copy elision)。如果使用GCC作为编译器,则这项优化技术是默认开启的,取消优化需要额外的编译参数“-fno-elide- constructors”。”
如果返回的对象无法在编译期决定,则返回值优化就会失效。
“虽然返回值优化技术可以省略创建临时对象和复制构造的过程,但是C++11标准规定复制构造函数必须是存在且可访问的,否则程序是不符合语法规则的”
“C++14标准对返回值优化做了进一步的规定,规定中明确了对于常量表达式和常量初始化而言,编译器应该保证RVO,但是禁止NRVO。”
“在C++17标准中提到了确保复制消除的新特性,它从另一个角度出发对C++进行了性能优化,而且也能达到RVO的效果。该特性指出,在传递临时对象或者从函数返回临时对象的情况下,编译器应该省略对象的复制和移动构造函数,即使这些复制和移动构造还有一些额外的作用,最终还是直接将对象构造到目标的存储变量上,从而避免临时对象的产生。标准还强调,这里的复制和移动构造函数甚至可以是不存在或者不可访问的。也就是说复制和移动构造函数可以被显式删除。”
“应该尽量减少对这些优化的依赖,因为不同的编译器对其的支持可能是不同的。面对传递对象的需求,我们可以尽量通过传递引用参数的方式完成,不要忘了C++11中支持的移动语义,它也能在一定程度上代替返回值优化的工作。”
参考:C++11还规定,如果编译器不能执行copy elision,但copy elision的条件已经满足(即NRVO和RVO),那么编译器必须按照下面的顺序尝试使用复制/移动构造函数返回对象:(注意这里只摘抄了与异常和携程无关的部分)
将返回的表达式看作一个rvalue,进行重载解析(这样就可能调用移动构造函数)
如果重载解析选出的构造函数重载不是移动构造函数(准确来说,是如果解析出的函数的第一个参数的类型不是右值引用,比如选了const T&),那么就将其看作一个lvalue再进行重载解析(这样就可以使用复制构造函数)
注意cppref指出上面的规则截止到C++23,但很明显,这个规则是比较陈旧的,因为如同上文记录的,从C++17开始,C++中的值类已经被进一步细分。因此,C++23的新规定是:
直接将返回的表达式看作一个xvalue进行重载解析(xvalue会首先尝试绑定到右值引用)
可以看到,C++23的规定相当的直截。
34.4 允许按值进行默认比较(C++20) 333
34.5 支持new表达式推导数组长度(C++20) 334
34.6 允许数组转换为未知范围的数组(C++20) 335
34.7 在delete运算符函数中析构对象(C++20) 336
34.8 调用伪析构函数结束对象声明周期(C++20) 337
34.9 修复const和默认复制构造函数不匹配造成无法编译的问题(C++20) 338
34.10 不推荐使用volatile的情况(C++20) 339
34.11 不推荐在下标表达式中使用逗号运算符(C++20) 340
34.12 模块(C++20) 340
34.13 总结 341
第35章 可变参数模板(C++11 C++17 C++20)
35.1 可变参数模板的概念和语法 342
35.2 形参包展开 344
35.3 sizeof…运算符 352
35.4 可变参数模板的递归计算 353
35.5 折叠表达式 354
35.6 一元折叠表达式中空参数包的特殊处理 357
35.7 using声明中的包展开 358
35.8 lambda表达式初始化捕获的包展开 359
35.9 总结 361
第36章 typename优化(C++17 C++20)
36.1 允许使用typename声明模板形参 362
36.2 减少typename使用的必要性 363
36.3 总结 365
第37章 模板参数优化(C++11 C++17 C++20)
37.1 允许常量求值作为所有非类型模板的实参 366
37.2 允许局部和匿名类型作为模板实参 368
37.3 允许函数模板的默认模板参数 369
37.4 函数模板添加到ADL查找规则 370
37.5 允许非类型模板形参中的字面量类类型 371
37.6 扩展的模板参数匹配规则 373
37.7 总结 374
第38章 类模板的模板实参推导(C++17 C++20)
38.1 通过初始化构造推导类模板的模板实参 375
38.2 拷贝初始化优先 377
38.3 lambda类型的用途 378
38.4 别名模板的类模板实参推导 380
38.5 聚合类型的类模板实参推导 380
38.6 总结 382
第39章 用户自定义推导指引(C++17)
39.1 使用自定义推导指引推导模板实例 383
39.2 聚合类型类模板的推导指引 386
39.3 总结 387
第40章 SFINAE(C++11)
40.1 替换失败和编译错误 388
40.2 SFINAE规则详解 389
40.3 总结 394
第41章 概念和约束(C++20)
41.1 使用std::enable_if约束模板 395
41.2 概念的背景介绍 396
41.3 使用concept和约束表达式定义概念 397
41.4 requires子句和约束检查顺序 398
41.5 原子约束 401
41.6 requires表达式 403
41.6.1 简单要求 404
41.6.2 类型要求 405
41.6.3 复合要求 405
41.6.4 嵌套要求 406
41.7 约束可变参数模板 407
41.8 约束类模板特化 408
41.9 约束auto 409
41.10 总结 410
第42章 模板特性的其他优化(C++11 C++14)
42.1 外部模板(C++11) 411
42.2 连续右尖括号的解析优化(C++11) 413
42.3 friend声明模板形参(C++11) 415
42.4 变量模板(C++14) 417
42.5 explicit(bool) 419
42.6 总结 423
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 安全运维:cmd命令大全(108个)
- 小程序系列--3.宿主环境简介
- 智能优化算法应用:基于厨师算法3D无线传感器网络(WSN)覆盖优化 - 附代码
- C //练习 4-5 给计算器程序增加访问sin、exp与pow等库函数的操作。有关这些库函数的详细信息,参见附录B.4节中的头文件<math.h>。
- 小猴编程C++ | 分蛋糕
- 八字命运API接口:探索人生道路,追求幸福
- [笔记] 使用 qemu 创建虚拟磁盘并安装 grub
- Java与前端开发:真相还是焦虑?
- 极智开发 | 解读英伟达软件生态 深度神经网络库cuDNN
- 软件需求规格说明书