mathglm代码调试记录
数据集格式:
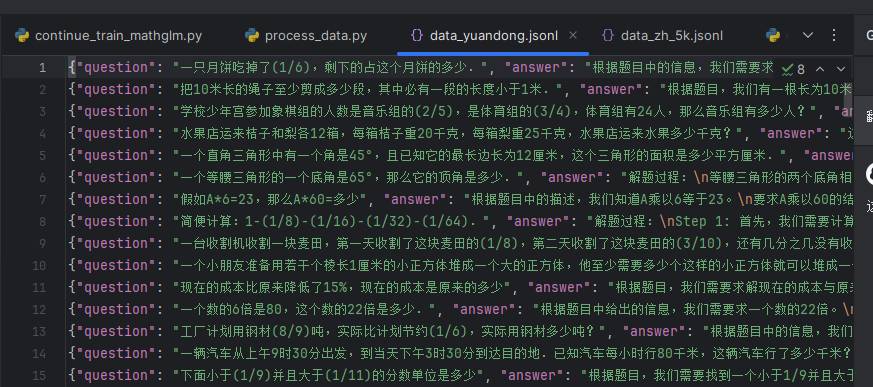
读取数据集代码:
def make_loaders(args, create_dataset_function):
"""makes training/val/test
Args:
args.train_data, args.valid_data, args.test_data: str. Paths to the dataset.
args.split: str. format: "8,1,1". how to split train_data.
args.dataset_type: use to create the right datasets.
"""
make_dataset = partial(make_dataset_full,
create_dataset_function=create_dataset_function)
world_size = torch.distributed.get_world_size(
group=mpu.get_data_parallel_group())
batch_size = args.batch_size * world_size
eval_batch_size = batch_size
if args.eval_batch_size is not None:
eval_batch_size = args.eval_batch_size * world_size
split = get_split(args)
data_set_args = {
'path': args.train_data,
'split': split,
}
eval_set_args = copy.copy(data_set_args)
eval_set_args['split'] = [1.]
# make datasets splits and tokenizer
train = None
valid = None
test = None
if args.train_data is not None:
train = make_dataset(**data_set_args, args=args, dataset_weights=args.train_data_weights, is_train_data=True)
if should_split(split):
train, valid, test = train
# make training and val dataset if necessary
if valid is None and args.valid_data is not None:
eval_set_args['path'] = args.valid_data
valid = make_dataset(**eval_set_args, args=args, random_mapping=not args.strict_eval)
if test is None and args.test_data is not None:
eval_set_args['path'] = args.test_data
test = make_dataset(**eval_set_args, args=args, random_mapping=not args.strict_eval)
# wrap datasets with data loader
if train is not None and args.batch_size > 0:
train = make_data_loader(train, batch_size, args, split='train')
args.do_train = True
else:
args.do_train = False
eval_batch_size = eval_batch_size if eval_batch_size != 0 else batch_size
if valid is not None:
valid = make_data_loader(valid, eval_batch_size, args, split='val')
args.do_valid = True
else:
args.do_valid = False
if test is not None:
test = make_data_loader(test, eval_batch_size, args, split='test')
args.do_test = True
else:
args.do_test = False
return train, valid, test
数据读取后:
/home/user/zjb/SAT/mathglm/continue_train_mathglm.py
get_batch(data_iterator, args, timers):# 传入参数data_iterator
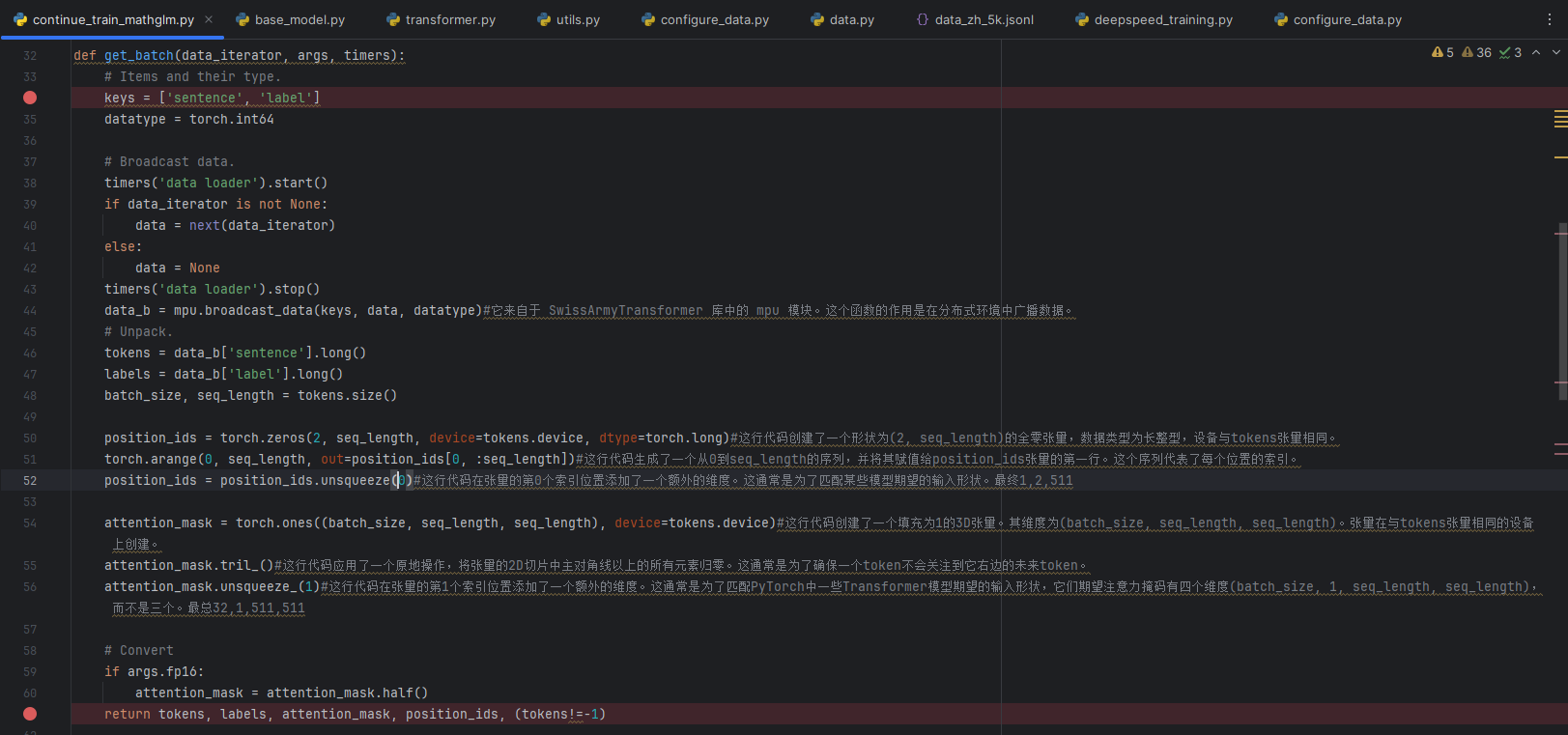
在continue_train_mathglm.py文件中,get_batch函数从data_iterator获取数据,然后将其转换为词向量。这是通过调用get_batch函数中的mpu.broadcast_data函数实现的。
然后,在forward_step函数中,get_batch函数的返回值被传递给模型。模型接收的输入是词向量,而不是原始的字符串。
这种转换是因为模型不能直接处理原始的文本数据。模型需要的是一种数值表示,通常是词向量,这样才能进行数学运算。因此,原始的字符串数据需要被转换为词向量。
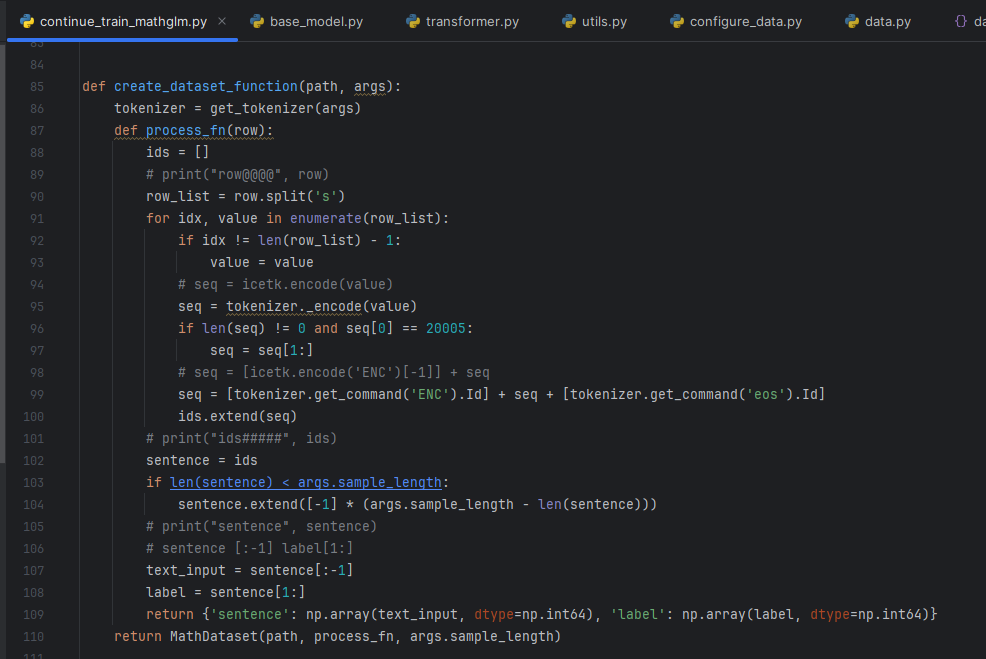
在create_dataset_function函数中,你可以看到这个转换过程。process_fn函数接收一个字符串row,然后使用tokenizer._encode(value)将其转换为词向量。这个词向量然后被添加到ids列表中,最后返回一个包含词向量的字典。
所以,data_iterator中的数据是字符串,因为这是原始的输入数据。然后,这些数据被转换为词向量,以便可以被模型处理。
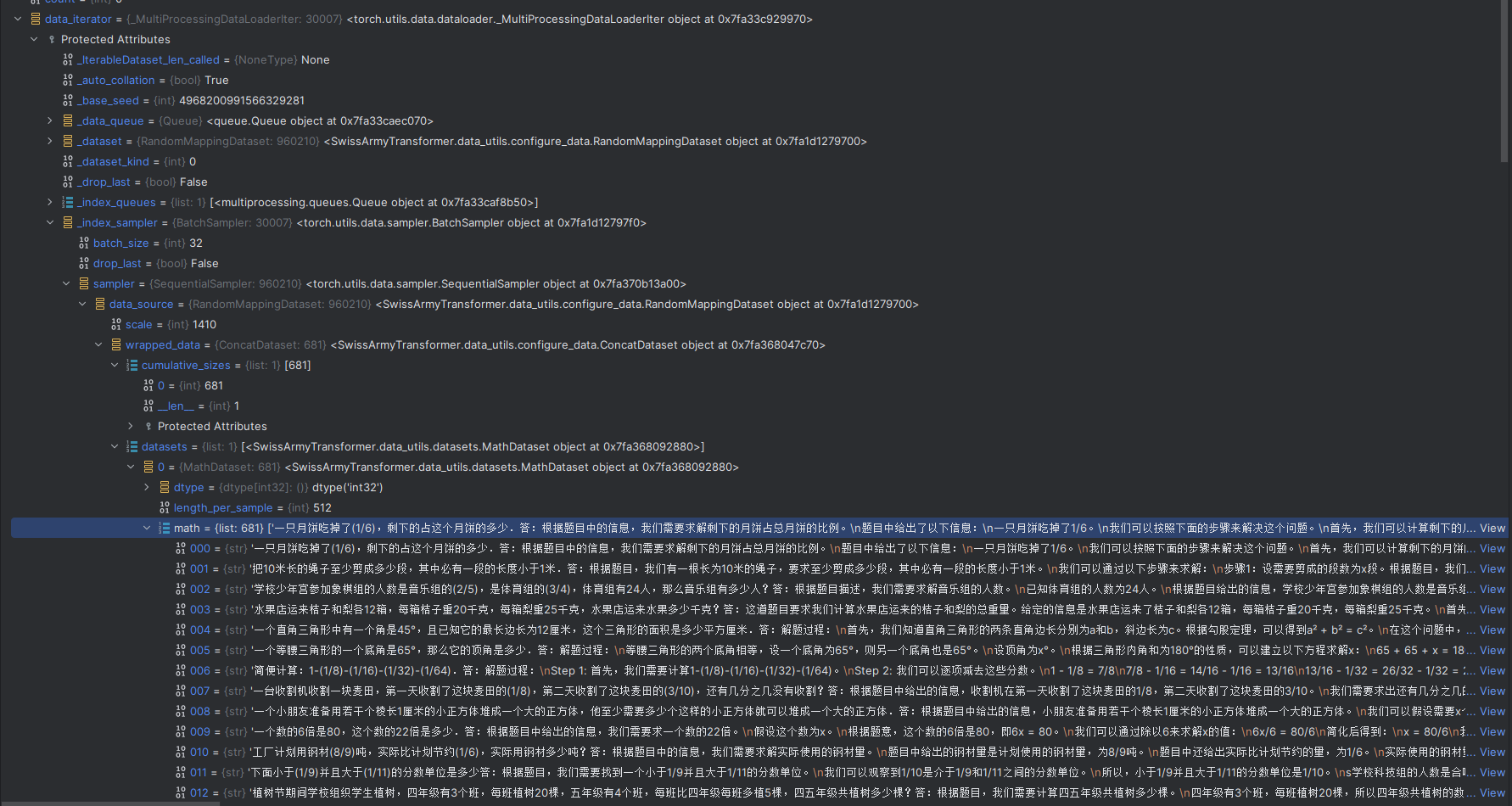
其中data_iterator是dataloaderlter如图所示
data如图所示

data_b

mpu.broadcast_data(keys, data, datatype) 是一个函数调用,它来自于 SwissArmyTransformer 库中的 mpu 模块。这个函数的作用是在分布式环境中广播数据。

create_dataset_function函数在continue_train_mathglm.py文件中。这个函数用于创建一个数据集,它接收一个路径和参数,然后返回一个MathDataset对象。在这个函数中,它定义了一个process_fn函数,这个函数用于处理每一行数据,将其转换为词向量。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【单调栈】LeetCode:1944队列中可以看到的人数
- Golang leetcode242有效字符异位词 哈希表map 排序
- vs code-debug can‘t find file
- 数据库编程简单使用sqlite3——学生信息管理系统(乞丐版)
- java常见面试题:如何使用Java进行Spring Boot框架开发?
- 如何在CentOS8使用宝塔面板本地部署Typecho个人网站并实现公网访问【内网穿透】
- 在CMake中自定义宏 add_definitions(-DDEBUG)
- 研究:同样的C++模板在多个cpp里出现,编译器是否要重复生成?
- C++ 之LeetCode刷题记录(九)
- nestjs调用第三方接口