基于VGG-16+Android+Python的智能车辆驾驶行为分析—深度学习算法应用(含全部工程源码)+数据集+模型(四)
目录

前言
本项目采用VGG-16网络模型,使用Kaggle开源数据集,旨在提取图片中的用户特征,最终在移动端实现对不良驾驶行为的识别功能。
首先,通过使用VGG-16网络模型,本项目能够深入学习和理解驾驶场景图像中的特征。VGG-16是一种深度卷积神经网络,特别适用于图像识别任务,通过多层次的卷积和池化层,能够有效地提取图像中的抽象特征。
其次,项目利用Kaggle提供的开源数据集,包括各种驾驶场景图像,覆盖了不同的驾驶行为和条件。这样的数据集是训练模型所需的关键资源。
接下来,利用训练好的VGG-16模型,项目提取图像中的用户特征。包括驾驶行为的姿势、眼神、手部动作等方面的特征,有助于判断是否存在不良驾驶行为。
最后,通过在移动端实现这个模型,可以将不良驾驶行为的识别功能直接部署到车辆或驾驶辅助系统中。这种实时的、移动端的识别方案有望在驾驶安全和监管方面发挥积极的作用。
总的来说,项目结合了深度学习、图像处理和移动端技术,致力于实现对不良驾驶行为的智能化识别,为提升驾驶安全提供了一种创新的解决方案。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
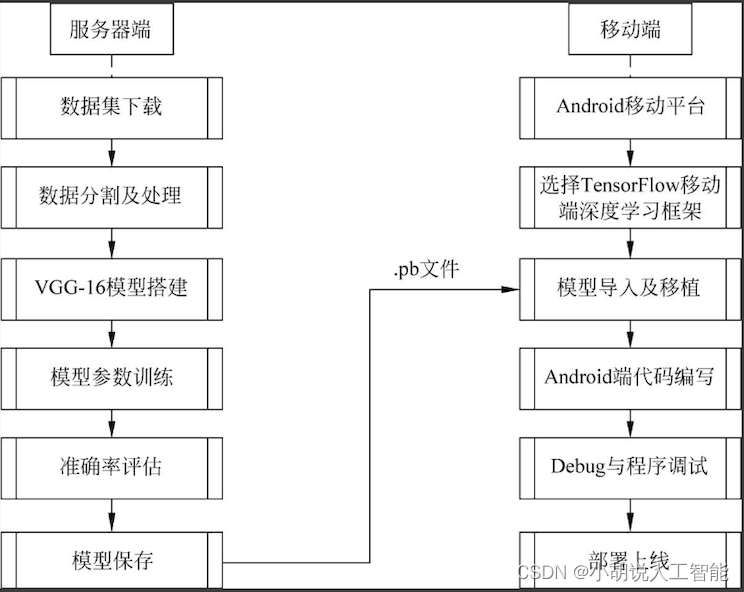
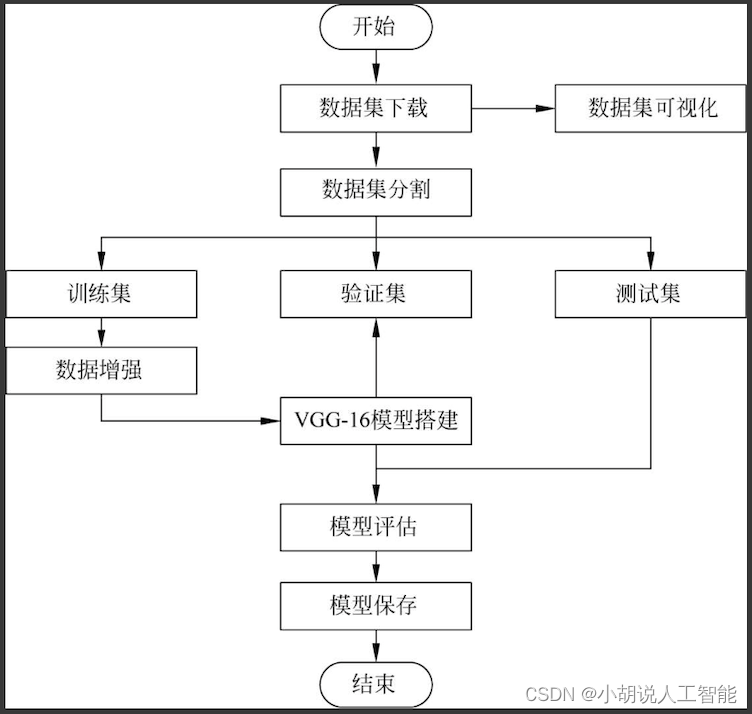
系统流程图
系统流程如图所示。
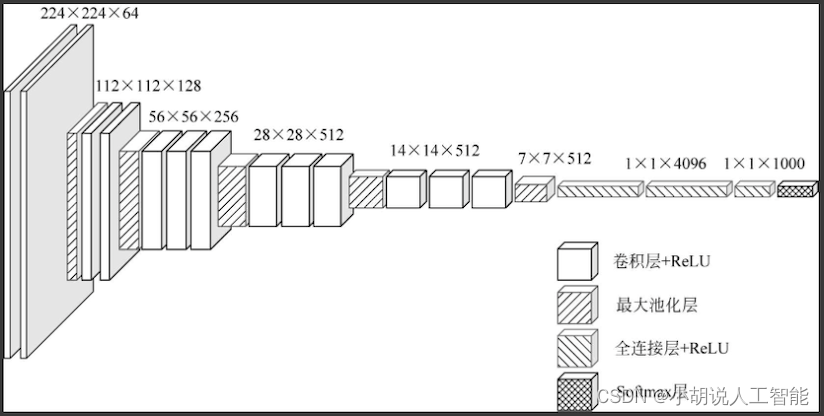
VGG-16网络架构如图所示。
运行环境
本部分包括Python环境、TensorFlow环境、Pycharm环境和Android环境。
详见博客。
模块实现
本项目包括4个模块:数据预处理、模型构建、模型训练及保存、模型生成。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
本部分包括数据集来源、内容和预处理。
详见博客。
2. 模型构建
数据加载进模型之后,需要定义模型结构,并优化损失函数。
详见博客。
3. 模型训练及保存
在定义模型架构和编译后,通过训练集训练,使模型可以识别数据集中图像的特征。
详见博客。
4. 模型生成
将图片转化为数据,输入TensorFlow的模型中并获取输出。
详见博客。
系统测试
本部分包括训练准确率、测试效果及模型应用。
1. 训练准确率
训练准确率在98.2%左右,损失率在10.6%左右,可见整个预测模型的训练比较成功,如图所示。

2. 测试效果
使用OpenCV库读取图片,将测试集中的数据代入模型中进行预测,如图1和图2所示。
img=cv2.imread('img_test.jpg')
img=cv2.resize(img,(150,150,150))
images = [img]
output = model.predict(np.array(images), batch_size=1)
pro= output.max()
index=output.argmax()
print(names[index],pro)
print(output)


3. 模型应用
Android项目编译成功后,建议将项目部署到真机上进行测试。模拟器运行较慢,不建议使用。部署到真机的方法如下:
将手机数据线连接到计算机,开启开发者模式,打开USB调试,单击Android项目的"运行"按钮,出现"连接手机"的选项,单击该选项即可。
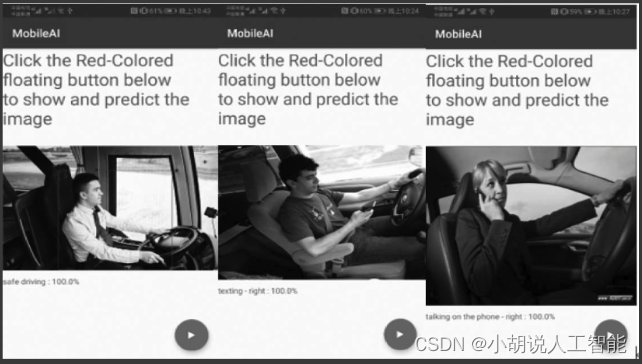
Android Studio生成apk,发送到手机上下载apk,安装即可。打开App,初始界面如图所示。

单击右下角按钮,显示测试照片结果,如图所示。

移动端测试结果如图所示。
相关其它博客
基于VGG-16+Android+Python的智能车辆驾驶行为分析—深度学习算法应用(含全部工程源码)+数据集+模型(一)
基于VGG-16+Android+Python的智能车辆驾驶行为分析—深度学习算法应用(含全部工程源码)+数据集+模型(二)
基于VGG-16+Android+Python的智能车辆驾驶行为分析—深度学习算法应用(含全部工程源码)+数据集+模型(三)
工程源代码下载
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 备份数据用什么存储?有什么要求?
- Android 12.0 recovery页面旋转180度问题的解决方案
- java cc链3TrAXFilter与InstantiateTransformer
- MQTT 介绍与学习 —— 筑梦之路
- 122基于matlab的CSO-SVM,BA-SVM模式识别模型
- Netty-5-线程模型
- vulnhub靶机odin
- 数据输入输出的概念及在C语言中的实现
- 框架=注解+反射+设计模式 & 注解
- 为Windows用户更改账户类型